go template 库(模板)
模板能够分离数据和逻辑,使得逻辑变得简洁清晰,同时提高复用率。
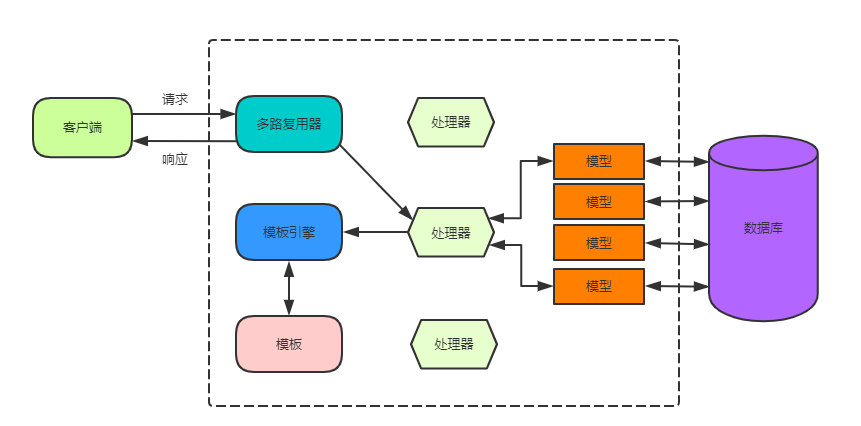
模板引擎按照功能可以划分为两种类型:
- 无逻辑模板引擎:此类模板引擎只进行字符串的替换,无其它逻辑;
- 嵌入逻辑模板引擎:此类模板引擎可以在模板中嵌入逻辑,实现流程控制/循环等。
这两类模板引擎都比较极端。无逻辑模板引擎需要在处理器中额外添加很多逻辑用于生成替换的文本。而嵌入逻辑模板引擎则在模板中混入了大量逻辑,导致维护性较差。实用的模板引擎一般介于这两者之间。
模板能够分离数据和逻辑,使得逻辑变得简洁清晰,同时提高复用率。
模板引擎按照功能可以划分为两种类型:
这两类模板引擎都比较极端。无逻辑模板引擎需要在处理器中额外添加很多逻辑用于生成替换的文本。而嵌入逻辑模板引擎则在模板中混入了大量逻辑,导致维护性较差。实用的模板引擎一般介于这两者之间。
gomock 是 Go 官方的模拟框架,可以与 go 的 test 很好的集成。在实际项目中,当需要进行单元测试时,往往会有很多的依赖项,有些依赖可能还没有办法直接进行创建,例如数据库连接,文件 I/O 等。此时通过使用 go mock 可以模拟依赖项,简化测试。
循环是几乎所有编程语言都具有的控制结构,也是编程语言中常用的控制结构,Go 语言除了使用经典的三段式循环之外,还引入了另一个关键字 range 用于快速遍历数组、哈希表以及 Channel 等元素。
这里主要记录 Go 语言中的两种不同循环,也就是经典的 for 循环和 for…range 循环,分析这两种循环在运行时的结构以及它们的实现原理。
for 循环和 for…range 循环的形式分别如下:
func main() {
// for 循环
for i := 0; i < 10; i++ {
println(i)
}
// for range 循环
arr := []int{1, 2, 3}
for i, _ := range arr {
println(i)
}
}
在汇编语言中,无论是经典的 for 循环还是 for-range 循环都会使用 JMP 等命令跳回循环体的开始位置复用代码,所以使用 for…range 语法的控制结构最终应该也会被 Go 语言的编译器转换成普通的 for 循环。
接下来将逐个分析每一种循环的场景。
该规范来自腾讯开源的代码规范中,项目地址为:https://github.com/Tencent/secguide
该项目涵盖了 Go、Java、JS、nodejs、C/C++、python 等一系列代码规范,这里只记录 Go 部分。
validator 库用于对数据进行校验。在 Web 开发中,对用户传过来的数据我们都需要进行严格校验,防止用户的恶意请求。例如日期格式,用户年龄,性别等必须是正常的值,不能随意设置。使用 validdator 库可以很方便的进行很多的校验,避免自己编写大量的格式检验代码。
因为最近快入职了,正好在公众号看到推广,就在拉勾教育上购买了一套 MySQL 实战教程:《姜承尧的MySQL实战宝典》,重新温习一下 MySQL,这篇文章主要记录通过这个课程学习到的一些 MySQL 使用技巧。
这里附上课程链接:拉勾教育——MySQL实战宝典
Go module 是 Go1.11 版本之后推出的模块管理工具,从1.13开始为默认的依赖管理工具。在没有 Go module 之前,对于导入依赖的管理都是通过 GOPATH 来指定在工程中使用哪些源文件和模块。项目的代码只能放到 GOPATH/src 目录下,依赖的各种源文件也都只能加入到 src 目录下才可以运行使用。
通常,日志的级别分这几种:TRACE,DEBUG,INFO,WARN,ERROR,FATAL。其含义分别如下:
参考文章:
OpenTracing 是一个中立的(厂商无关、平台无关)分布式追踪的 API 规范,提供了统一接口方便开发者在自己的服务中集成一种或者多种分布式追踪的实现。
开发和工程团队因为系统组件水平扩展、开发团队小型化、敏捷开发、CD(持续集成)、解耦等各种需求,开始使用微服务的架构取代以前好的单机系统。 也就是说,当一个生产系统面对真正的高并发,或者解耦成大量微服务时,以前很容易实现的重点任务变得困难了。过程中需要面临一系列问题:用户体验优化、后台真是错误原因分析,分布式系统内各组件的调用情况等。随着服务数量的增多和内部调用链的复杂化,仅凭借日志和性能监控很难做到 “See the Whole Picture”,在进行问题排查或是性能分析的时候,无异于盲人摸象。