分布式链路追踪(OpenTracing标准)和 Jaeger 实现
OpenTracing 简介
OpenTracing 是一个中立的(厂商无关、平台无关)分布式追踪的 API 规范,提供了统一接口方便开发者在自己的服务中集成一种或者多种分布式追踪的实现。
OpenTracing 诞生的背景
开发和工程团队因为系统组件水平扩展、开发团队小型化、敏捷开发、CD(持续集成)、解耦等各种需求,开始使用微服务的架构取代以前好的单机系统。 也就是说,当一个生产系统面对真正的高并发,或者解耦成大量微服务时,以前很容易实现的重点任务变得困难了。过程中需要面临一系列问题:用户体验优化、后台真是错误原因分析,分布式系统内各组件的调用情况等。随着服务数量的增多和内部调用链的复杂化,仅凭借日志和性能监控很难做到 “See the Whole Picture”,在进行问题排查或是性能分析的时候,无异于盲人摸象。
分布式追踪能够帮助开发者直观分析请求链路,快速定位性能瓶颈,逐渐优化服务间依赖,也有助于开发者从更宏观的角度更好地理解整个分布式系统。已有的分布式跟踪系统(例如,Zipkin, Dapper, HTrace, X-Trace等)旨在解决这些问题,但是他们使用不兼容的 API 来实现各自的应用需求。尽管这些分布式追踪系统有着相似的 API 语法,但各种语言的开发人员依然很难将他们各自的系统(使用不同的语言和技术)和特定的分布式追踪系统进行整合。
在这种情况下,OpenTracing 通过提供平台无关、厂商无关的API,使得开发人员能够方便的添加(或更换)追踪系统的实现。OpenTracing 定义了一套通用的数据上报接口,要求各个分布式追踪系统都来实现这套接口。这样一来,应用程序只需要对接 OpenTracing,而无需关心后端采用的到底什么分布式追踪系统,因此开发者可以无缝切换分布式追踪系统,也使得在通用代码库增加对分布式追踪的支持成为可能。
目前,主流的分布式追踪实现基本上都已经支持 OpenTracing,包括 Jaeger,Zipkin,Appdash 等。
分布式追踪的相关概念
Tracing
Wikipedia 中,对 Tracing 的定义是,在软件工程中,Tracing 指使用特定的日志记录程序的执行信息,与之相近的还有两个概念,它们分别是 Logging 和 Metrics。
- Logging:用于记录离散的事件,包含程序执行到某一点或某一阶段的详细信息。例如,应用程序的调试信息或错误信息。它是我们诊断问题的依据。
- Metrics:可聚合的数据,且通常是固定类型的时序数据。例如,队列的当前深度可被定义为一个度量值,在元素入队或出队时被更新;HTTP 请求个数可被定义为一个计数器,新请求到来时进行累加。
- Tracing:记录单个请求的处理流程,其中包括服务调用和处理时长等信息。
这三者也有相交重叠的部门:
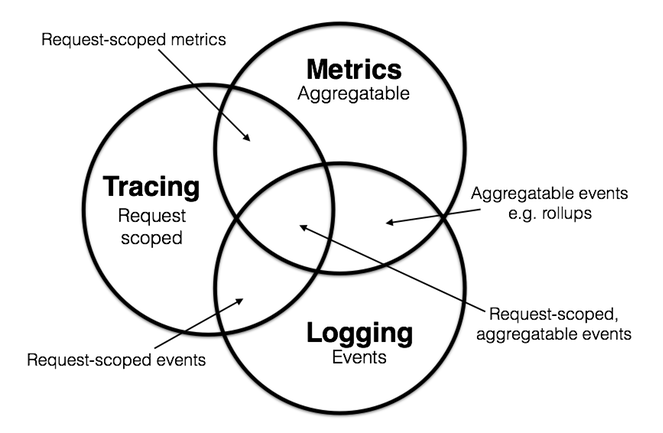
- Logging & Metrics:可聚合的事件。例如分析某对象存储的 Nginx 日志,统计某段时间内 GET、PUT、DELETE、OPTIONS 操作的总数。
- Metrics & Tracing:单个请求中的可计量数据。例如 SQL 执行总时长、gRPC 调用总次数。
- Tracing & Logging:请求阶段的标签数据。例如在 Tracing 的信息中标记详细的错误原因。
针对每种分析需求,都有非常强大的集中式分析工具。
- Logging:ELK,近几年势头最猛的日志分析服务。
- Metrics:Prometheus,第二个加入 CNCF 的开源项目,非常好用。
- Tracing:OpenTracing 和 Jaeger,Jaeger 是 Uber 开源的一个兼容 OpenTracing 标准的分布式追踪服务。目前 Jaeger 也加入了 CNCF。
分布式追踪的核心步骤
分布式追踪系统大体分为三个部分,数据采集、数据持久化、数据展示。
数据采集是指在代码中埋点,设置请求中要上报的阶段,以及设置当前记录的阶段隶属于哪个上级阶段。数据持久化则是指将上报的数据落盘存储,例如 Jaeger 就支持多种存储后端,可选用 Cassandra 或者 Elasticsearch。数据展示则是前端根据 Trace ID 查询与之关联的请求阶段,并在界面上呈现。
一个典型的 Trace 案例如下:
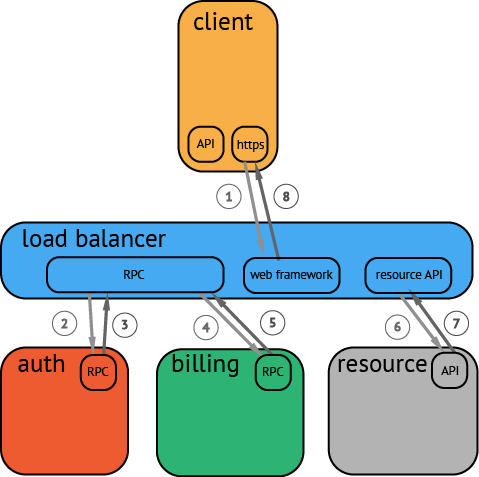
请求从客户端发出,请求首先到达负载均衡,接着进行认证服务,计费服务,然后请求资源,最后返回结果。
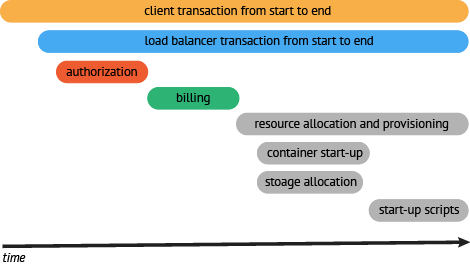
当数据被采集存储之后,分布式追踪系统会采用包含时间轴的的时序图来呈现这个 Trace:
OpenTracing 数据模型
Traces
一个 trace 代表一个潜在的,分布式的,存在并行数据或并行执行轨迹(潜在的分布式、并行)的系统。也可以理解成一个调用链,一个 trace 可以认为是多个 span 的有向无环图(DAG)。
Spans
一个 span 代表系统中具有开始时间和执行时长的逻辑运行单元,可以理解成某个处理阶段,一次方法调用,一个程序块的调用,或者一次 RPC/数据库访问。只要是一个具有完整时间周期的程序访问,都可以被认为是一个 span。span 之间通过嵌套或者顺序排列建立逻辑因果关系。
每个 Span 包含以下的状态:
- 操作名称(An operation name)
- 起始时间(A start timestamp)
- 结束时间(A finish timestamp)
- Span Tag:一组 KV 值,作为阶段的标签集合。键值对中,键必须为 string,值可以是字符串,布尔,或者数字类型。
- 阶段日志(Span Logs):一组 span 的日志集合。 每次 log 操作包含一个键值对,以及一个时间戳。 键值对中,键必须为 string,值可以是任意类型。 但是需要注意,不是所有的支持 OpenTracing 的 Tracer,都需要支持所有的值类型。
- 阶段上下文(SpanContext),其中包含 TraceID 和 SpanID
- 引用关系(Reference):Span 和 Span 之间的关系被命名 Reference,Span 之间通过 SpanContext 建立这种关系。
Span Reference
一个 span 可以和一个或者多个 span 间存在因果关系。OpenTracing 定义了两种关系:ChildOf 和 FollowsFrom。这两种引用类型代表了子节点和父节点间的直接因果关系。未来,OpenTracing将支持非因果关系的span引用关系。(例如:多个span被批量处理,span在同一个队列中,等等)
ChildOf 引用: 一个 span 可能是一个父级 span 的孩子,即 “ChildOf” 关系。在” ChildOf” 引用关系下,父级 span 某种程度上取决于子 span。下面这些情况会构成 “ChildOf” 关系:
- 一个 RPC 调用的服务端的 span,和 RPC 服务客户端的 span 构成 ChildOf 关系
- 一个 sql insert 操作的 span,和 ORM 的 save 方法的 span 构成 ChildOf 关系
- 很多 span 可以并行工作(或者分布式工作)都可能是一个父级的 span 的子项,他会合并所有子span的执行结果,并在指定期限内返回
一个具有 ChildOf 父子节点关系的时序图如下:
[-Parent Span---------]
[-Child Span----]
[-Parent Span--------------]
[-Child Span A----]
[-Child Span B----]
[-Child Span C----]
[-Child Span D---------------]
[-Child Span E----]
FollowsFrom 引用: 一些父级节点不以任何方式依赖他们子节点的执行结果,这种情况下,就说这些子 span 和父 span 之间是 “FollowsFrom” 的因果关系。”FollowsFrom” 关系可以被分为很多不同的子类型,未来版本的 OpenTracing 中将正式的区分这些类型。
一个具有 FollowsFrom 父子节点关系的时序图如下:
[-Parent Span-] [-Child Span-]
[-Parent Span--]
[-Child Span-]
[-Parent Span-]
[-Child Span-]
综上,在一个 tracer 过程中,各 span 可以有如下关系:
[Span A] ←←←(the root span)
|
+------+------+
| |
[Span B] [Span C] ←←←(Span C 是 Span A 的孩子节点, ChildOf)
| |
[Span D] +---+-------+
| |
[Span E] [Span F] >>> [Span G] >>> [Span H]
↑
↑
↑
(Span G 在 Span F 后被调用, FollowsFrom)
上述 tracer 与 span 的时间轴关系如下:
––|–––––––|–––––––|–––––––|–––––––|–––––––|–––––––|–––––––|–> time
[Span A···················································]
[Span B··············································]
[Span D··········································]
[Span C········································]
[Span E·······] [Span F··] [Span G··] [Span H··]
SpanContext
每个 span 必须提供方法访问 SpanContext。SpanContext 代表跨越进程边界,传递到下级 span 的状态。(例如,包含 <trace_id, span_id, sampled> 元组),并用于封装 Baggage 。SpanContext 在跨越进程边界和追踪图中创建边界的时候会被使用。
每一个 SpanContext 包含以下特点:
- 任何一个 OpenTracing 的实现,都需要将当前调用链的状态(例如:trace 和 span 的 id),依赖一个独特的 Span 去跨进程边界传输。
- Baggage Items,Trace 的随行数据,是一个键值对集合,它存在于 trace 中,也需要跨进程边界传输
Inject 和 Extract
SpanContexts 可以通过 Injected 操作向载体( Carrier)增加,或者通过 Extracted 从 Carrier 中获取,跨进程通讯数据(例如:将 HTTP 头作为 Carrier 携带 SpanContexts)。通过这种方式,SpanContexts 可以跨越进程边界,并提供足够的信息来建立跨进程的 span 间关系(因此可以实现跨进程连续追踪)。
Baggage
**Baggage **是存储在 SpanContext 中的一个键值对( SpanContext )集合。它会在一条追踪链路上的所有 span 当中传输,包含这些 span 对应的 SpanContexts。在这种情况下,”Baggage” 会随着 trace 一同传播,他因此得名(Baggage 可理解为随着 trace 运行过程传送的行李)。鉴于全栈 OpenTracing 集成的需要,Baggage 通过透明化的传输任意应用程序的数据,实现强大的功能。例如:可以在最终用户的手机端添加一个 Baggage 元素,并通过分布式追踪系统传递到存储层,然后再通过反向构建调用栈,定位过程中消耗很大的 SQL 查询语句。
Baggage 拥有强大功能,也会有很大的消耗。由于 Baggage 的全局传输,如果包含的数量量太大,或者元素太多,它将降低系统的吞吐量或增加 RPC 的延迟。
Baggage 与 Span Tags 的区别
- Baggage 在全局范围内,伴随业务系统的调用跨进城传输数据。而 Span 的 tag 不会进行传输,因为它们不会被子级的 span 继承。
- span 的 tag 可以用来记录业务相关的数据,并存储与追踪系统中。而在实现 OpenTracing 时,可以选择是否存储 Baggage 中的非业务数据,OpenTracing 标准不强制要求实现此特性。
OpenTracing 定义的 API
各平台 API 支持
目前来说,下面这些平台都支持了 OpenTracing 规范定义的 API:
- Go - https://github.com/opentracing/opentracing-go
- Python - https://github.com/opentracing/opentracing-python
- Javascript - https://github.com/opentracing/opentracing-javascript
- Objective-C - https://github.com/opentracing/opentracing-objc
- Java - https://github.com/opentracing/opentracing-java
- C++ - https://github.com/opentracing/opentracing-cpp
PHP 和 Ruby 的 API 目前也正在研发当中。
相关 API
OpenTracing 标准中有三个重要的相互关联的类型,分别是 Tracer, Span 和 SpanContext。一般来说,每个行为都会在各语言实现层面上,会演变成一个方法,而实际上由于方法重载,很可能演变成一系列相似的方法。
当讨论“可选”参数时,需要强调的是,不同的语言针对可选参数有不同理解,概念和实现方式 。例如,在Go中,习惯使用 ”functional Options”,而在 Java 中,可能使用 builder 模式。
Tracer
Tracer 接口用来创建 Span,以及处理如何处理 Inject(serialize) 和 Extract (deserialize),用于跨进程边界传递。它具有如下官方能力:
创建一个新 Span
必填参数
- operation name, 操作名, 一个具有可读性的字符串,代表这个span所做的工作(例如:RPC 方法名,方法名,或者一个大型计算中的某个阶段或子任务)。操作名应该是一个抽象、通用,明确、具有统计意义的名称。因此,
"get_user"作为操作名,比"get_user/314159"更好。
例如,假设一个获取账户信息的span会有如下可能的名称:
| 操作名 | 指导意见 |
|---|---|
get |
太抽象 |
get_account/792 |
太明确 |
get_account |
正确的操作名,关于account_id=792 的信息应该使用 Tag 操作 |
可选参数
- 零个或者多个关联(references)的
SpanContext,如果可能,同时快速指定关系类型,ChildOf还是FollowsFrom。 - 一个可选的显性传递的开始时间;如果忽略,当前时间被用作开始时间。
- 零个或者多个tag。
返回值,返回一个已经启动 Span 实例(已启动,但未结束)
将 SpanContext 上下文 Inject(注入)到 carrier
必填参数:
SpanContext实例- format(格式化)描述,一般会是一个字符串常量,但不做强制要求。通过此描述,通知
Tracer,如何对SpanContext进行编码放入到 carrier 中。 - carrier,根据 format 确定。
Tracer根据 format 声明的格式,将SpanContext序列化到 carrier 对象中。
将 SpanContext 上下文从 carrier 中 Extract(提取)
必填参数
- format(格式化)描述,一般会是一个字符串常量,但不做强制要求。通过此描述,通知
Tracer,如何从 carrier 中解码SpanContext。 - carrier,根据format确定。
Tracer根据 format 声明的格式,从 carrier 中解码SpanContext。
返回值,返回一个 SpanContext 实例,可以使用这个 SpanContext 实例,通过 Tracer 创建新的 Span。
注意,对于Inject(注入)和Extract(提取),format 是必须的。
Inject(注入)和 Extract(提取)依赖于可扩展的 format 参数。format 参数规定了另一个参数 ”carrier” 的类型,同时约束了 ”carrier” 中 SpanContext 是如何编码的。所有的 Tracer 实现,都必须支持下面的 format:
- Text Map: 基于字符串:字符串的 map,对于 key 和 value,不约束字符集。
- HTTP Headers: 适合作为 HTTP 头信息的,基于字符串:字符串的map。(RFC 7230.在工程实践中,如何处理 HTTP 头具有多样性,强烈建议 trace r的使用者谨慎使用 HTTP 头的键值空间和转义符)
- Binary: 一个简单的二进制大对象,记录
SpanContext的信息。
Span
获取 Span 的 SpanContext
不需要任何参数。
返回值,Span 构建时传入的 SpanContext。这个返回值在 Span 结束后(span.finish()),依然可以使用。
复写操作名(operation name)
必填参数
- 新的操作名 operation name,覆盖构建
Span时,传入的操作名。
结束Span
可选参数
- 一个明确的完成时间;如果省略此参数,使用当前时间作为完成时间。当
Span结束后(span.finish()),除了通过Span获取SpanContext外,他所有方法都不允许被调用。
为Span设置tag
必填参数
- tag key,必须是 string 类型
- tag value,类型为字符串,布尔或者数字
Log结构化数据
必填参数
- 一个或者多个键值对,其中键必须是字符串类型,值可以是任意类型。某些 OpenTracing 实现,可能支持更多的log值类型。
可选参数
- 一个明确的时间戳。如果指定时间戳,那么它必须在 span 的开始和结束时间之内。
设置一个baggage(随行数据)元素
Baggage 元素是一个键值对集合,将这些值设置给给定的 Span,Span 的 SpanContext,以及所有和此 Span 有直接或者间接关系的本地 Span。 也就是说,baggage 元素随 trace 一起保持在带内传递。
带内传递,在这里指随应用程序调用过程一起传递
Baggage 元素具有强大的功能,使得 OpenTracing 能够实现全栈集成(例如:任意的应用程序数据,可以在移动端创建它,显然的,它会一直传递了系统最底层的存储系统),同时他也会产生巨大的开销,每一个键值都会被拷贝到每一个本地和远程的下级相关的 span 中,因此,总体上,他会有明显的网络和CPU开销。
必填参数
- baggage key, 字符串类型
- baggage value, 字符串类型
获取一个 baggage 元素
必填参数
- baggage key, 字符串类型
返回值,相应的 baggage value ,或者可以标识元素值不存在的返回值。
SpanContext
相对于 OpenTracing 中其他的功能,SpanContext 更多的是一个“概念”。也就是说,OpenTracing 实现中,需要重点考虑,并提供一套自己的 API。 OpenTracing 的使用者仅仅需要,在创建s pan、向传输协议 Inject(注入)和从传输协议中 Extract(提取)时,使用SpanContext 和 Reference。
OpenTracing 要求,SpanContext 是不可变的,目的是防止由于 Span 的结束和相互关系,造成的复杂生命周期问题。
遍历所有的 baggage 元素
遍历模型依赖于语言,实现方式可能不一致。在语义上,要求调用者可以通过给定的 SpanContext 实例,高效的遍历所有的 baggage 元素
NoopTracer
所有的 OpenTracing API 实现,必须提供某种方式的 NoopTracer 实现。NoopTracer 可以被用作控制或者测试时,进行无害的 inject 注入(等等)。例如,在 OpenTracing-Java 实现中,NoopTracer 在他自己的模块中。
可选 API 元素
有些语言的 OpenTracing 实现,为了在串行处理中,传递活跃的 Span 或 SpanContext,提供了一些工具类。例如,opentracing-go中,通过 context.Context 机制,可以设置和获取活跃的 Span。
OpenTracing 入门实践
这里以官方一个简单 demo 记录如何 OpenTracing:
server.go
在 server.go 当中,首先定义了几个调用点 handler,这些调用点共同组成了一个 server。
接着,为了监控这个程序,在入口处(HomeHandler)中设置了一个 span,这个 span 记录了 HomeHandler 方法完成所需要的时间,同时通过判断 homeHandler 方法是否正确返回,决定是否通过 tags 和 logs 记录方法调用的错误信息。
另一方面,为了构建真正的端到端追踪,还需要包含调用HTTP请求的客户端的span信息。所以需要在端到端过程中传递 span 的上下文信息,使得各端中的 span 可以合并到一个追踪过程中。这就是API中 Inject/Extract 的职责。homeHandler方法在第一次被调用时,创建一个根span,将关于本地追踪调用的 span 的元信息,设置到 http 的头上,并传递出去。
在 ServiceHandler 中,通过 http头获取到前面注入的元数据,并根据获取情况,还可以指定 span 之间的关系。
具体的代码实例如下:
package server
import (
"fmt"
"github.com/opentracing/opentracing-go"
"log"
"math/rand"
"net/http"
"time"
)
func IndexHandler(w http.ResponseWriter, r *http.Request) {
_, _ = w.Write([]byte(`<a href = "/home"> Click here to start a request </a>`))
}
// HomeHandler "/home" 路径下
func HomeHandler(w http.ResponseWriter, r *http.Request) {
_, _ = w.Write([]byte("Request started\n"))
// 在入口处设置一个 span
span := opentracing.StartSpan("GET /home")
defer span.Finish()
// 创建请求
asyncReq, _ := http.NewRequest("GET", "http://localhost:8888/async", nil)
// 将关于本地追踪调用的 span 的元信息,设置到 http 的头上,并准备传递出去
err := span.Tracer().Inject(span.Context(),
opentracing.TextMap,
opentracing.HTTPHeadersCarrier(asyncReq.Header))
if err != nil {
log.Fatalf("%s: Could not inject span context into async request header: %v", r.URL.Path, err)
}
// 为 span 设置 tags 和 logs
go func() {
sleepMilli(50)
// 通过判断 homeHandler 方法是否正确返回,决定是否记录方法调用的错误信息
if _, err = http.DefaultClient.Do(asyncReq); err != nil {
// 方法调用出错,为期设置 tag 和 log
span.SetTag("error", true)
span.LogKV(fmt.Sprintf("%s: Async call failed (%v)", r.URL.Path, err))
}
}()
sleepMilli(10)
syncReq, _ := http.NewRequest("GET", "http://localhost:8888/service", nil)
err = span.Tracer().Inject(span.Context(),
opentracing.TextMap,
opentracing.HTTPHeadersCarrier(syncReq.Header))
if err != nil {
log.Fatalf("%s: Could not inject span context into service request header: %v", r.URL.Path, err)
}
if _, err = http.DefaultClient.Do(syncReq); err != nil {
span.SetTag("error", true)
span.LogKV(fmt.Sprintf("%s: GET /service error: %v", r.URL.Path, err))
}
_, _ = w.Write([]byte("Request done!\n"))
}
// ServiceHandler "/service" 路径下
func ServiceHandler(w http.ResponseWriter, r *http.Request) {
// 在 ServiceHandler 服务中提取上面的元数据信息
var sp opentracing.Span
opName := fmt.Sprintf("%s %s", r.Method, r.URL.Path)
// 尝试通过请求头获取 span 的上下文信息
wireContext, err := opentracing.GlobalTracer().Extract(
opentracing.TextMap,
opentracing.HTTPHeadersCarrier(r.Header))
if err != nil {
// 如果由于某种原因导致无法获取信息,则继续启动一个新的根路径下的 span
sp = opentracing.StartSpan(opName)
log.Printf("err: %v for the wireContext: %v", err, wireContext)
} else {
// 没有出错则可以指定 span 之间的关系
sp = opentracing.StartSpan(opName, opentracing.ChildOf(wireContext))
log.Printf("the wireContext: %v", wireContext)
}
defer sp.Finish()
sleepMilli(50)
dbReq, _ := http.NewRequest("GET", "http://localhost:8888/db", nil)
err = sp.Tracer().Inject(sp.Context(),
opentracing.TextMap,
opentracing.HTTPHeadersCarrier(dbReq.Header))
if err != nil {
log.Fatalf("%s: Couldn't inject headers (%v)", r.URL.Path, err)
}
if _, err = http.DefaultClient.Do(dbReq); err != nil {
sp.LogKV("da request error", err)
}
}
// DbHandler "/db"路径下
func DbHandler(w http.ResponseWriter, r *http.Request) {
var sp opentracing.Span
spanCtx, err := opentracing.GlobalTracer().Extract(opentracing.TextMap,
opentracing.HTTPHeadersCarrier(r.Header))
if err != nil {
sp = opentracing.StartSpan("GET /db")
log.Printf("%s: Coule not join trace (%v)\n", r.URL.Path, err)
return
} else {
sp = opentracing.StartSpan("GET /db", opentracing.ChildOf(spanCtx))
}
defer sp.Finish()
sleepMilli(25)
}
func sleepMilli(min int) {
time.Sleep(time.Millisecond * time.Duration(min+rand.Intn(100)))
}
连接到追踪系统
当系统按照 OpenTracing 标准被监控之后,增加一个追踪系统便变得非常简单,只需要在启动之前,指定所连接的链路追踪系统即可,下面使用 appdash 追踪系统,通过在 main 函数中添加一小段代码来启动 Appdash 实例,不需要修改任何监控代码就可以实现追踪:
package main
import (
"flag"
"fmt"
"github.com/opentracing/opentracing-go"
"log"
"net"
"net/http"
"net/url"
"opentracing-demo/server"
"sourcegraph.com/sourcegraph/appdash"
appdashot "sourcegraph.com/sourcegraph/appdash/opentracing"
"sourcegraph.com/sourcegraph/appdash/traceapp"
)
var (
port = flag.Int("port", 8888, "Example app port.")
appdashPort = flag.Int("appdash.port", 8700, "Run appdash locally on this port.")
)
func main() {
flag.Parse()
// 连接到追踪系统(Appdash)
addr := startAppdashServer(*appdashPort)
tracer := appdashot.NewTracer(appdash.NewRemoteCollector(addr))
opentracing.InitGlobalTracer(tracer)
addr = fmt.Sprintf(":%d", *port)
mux := http.NewServeMux()
mux.HandleFunc("/", server.IndexHandler)
mux.HandleFunc("/home", server.HomeHandler)
mux.HandleFunc("/async", server.ServiceHandler)
mux.HandleFunc("/service", server.ServiceHandler)
mux.HandleFunc("/db", server.DbHandler)
fmt.Printf("Go to http://localhost:%d/home to start arequest!\n", *port)
log.Fatal(http.ListenAndServe(addr, mux))
}
// startAppdashServer 连接到 Appdash 链路追踪系统
func startAppdashServer(appdashPort int) (collectorPortStr string) {
store := appdash.NewMemoryStore()
// 在本地侦听任何可用的 TCP 端口
l, err := net.ListenTCP("tcp", &net.TCPAddr{IP: net.IPv4(127, 0, 0, 1), Port: 0})
if err != nil {
log.Fatal(err)
}
collectorPort := l.Addr().(*net.TCPAddr).Port
collectorPortStr = fmt.Sprintf(":%d", collectorPort)
// 启动一个 Appdash 收集服务器,该服务器将侦听 span 和批注并将其添加到本地收集器(存储在内存中)
cs := appdash.NewServer(l, appdash.NewLocalCollector(store))
go cs.Start()
// 打印将运行 web 界面的 URL
appdashURLStr := fmt.Sprintf("http://localhost:%d", appdashPort)
appdashURL, err := url.Parse(appdashURLStr)
if err != nil {
log.Fatalf("Error parsing %s: %s", appdashURLStr, err)
}
fmt.Printf("To see your traces,go to %s/traces\n", appdashURL)
// 在单独的 goroutine 中启动 web UI 界面
tapp, err := traceapp.New(nil, appdashURL)
if err != nil {
log.Fatalf("Error creating traceapp: %v", err)
}
tapp.Store = store
tapp.Queryer = store
go func() {
log.Fatal(http.ListenAndServe(fmt.Sprintf(":%d", appdashPort), tapp))
}()
return
}
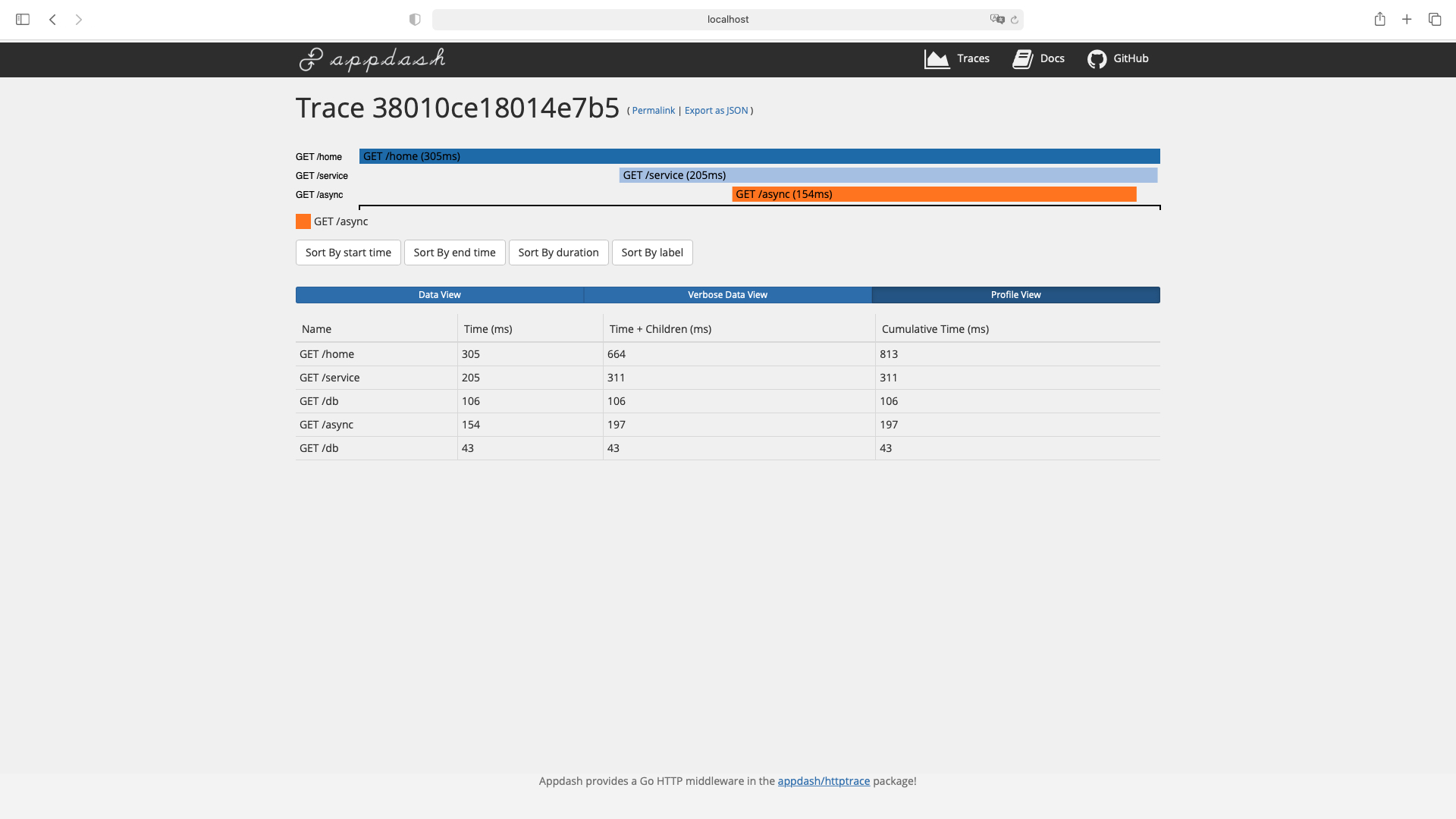
运行之后,就可以通过 UI 界面观察到本地程序的请求链路,耗时情况等:
OpenTracing 最佳实践
针对准备使用 OpenTracing API 的实践
追踪 Function(函数)
假设现在最顶层的函数如下:
def top_level_function():
span1 = tracer.start_span('top_level_function')
try:
. . . # business logic,业务逻辑
finally:
span1.finish()
在后面的流程中,作为业务逻辑的一部分,我们调用的 function2 方法,也希望能够被追踪。为了让这个追踪附着在正在进行的追踪上(和上述的追踪形成一根调用链),需要获取到正在进行的追踪。
现在,假设一个 get_current_span 函数可以完成这个功能:
def function2():
span2 = get_current_span().start_child('function2')
if get_current_span() else None
try:
. . . # business logic
finally:
if span2:
span2.finish()
假设如果这个追踪还未被启动,无论什么原因,开发者都不想在这个函数内启动一个新的追踪,所以 get_current_span 函数可能返回 None。
服务端追踪
当一个应用服务器要追踪一个请求的执行情况,一般需要以下几步:
- 试图从请求中获取传输过来的 SpanContext(防止调用链在客户端已经开启),如果无法获取 SpanContext,则新开启一个追踪。
- 在
request context中存储最新创建的 span,request context会通过应用程序代码或者 RPC 框架进行传输 - 最终,当服务端完成请求处理后,使用
span.finish()关闭 span。
从请求中获取(Extracting)SpanContext
假设,有一个HTTP服务器,SpanContext 通过 HTTP 头从客户端传递到服务端,可通过 request.headers 访问到:
extracted_context = tracer.extract(
format=opentracing.HTTP_HEADER_FORMAT,
carrier=request.headers
)
这里,使用 headers 中的 map 作为 carrier。追踪程序知道需要 hearder 的哪些内容,用来重新构建 tracer 的状态和 Baggage。
从请求中获取一个已经存在的追踪,或者开启一个新的追踪
如果无法在请求的相关的头信息中获取所需的值,上文中的 extracted_context 可能为None:此时假设客户端没有发送他们。
在这种情况下,服务端需要新创建一个追踪(新调用链)。
extracted_context = tracer.extract(
format=opentracing.HTTP_HEADER_FORMAT,
carrier=request.headers
)
if extracted_context is None:
span = tracer.start_span(operation_name=operation)
else:
span = tracer.start_span(operation_name=operation, child_of=extracted_context)
span.set_tag('http.method', request.method)
span.set_tag('http.url', request.full_url)
可以通过调用 set_tag,是在Span中记录请求的附加信息。
上面提到的 operation 是通过提供的服务名指定 Span 的名称。例如,如果HTTP请求到 /save_user/123,那么 operation 名称应该被设置为 post:/save_user/。OpenTracing API 不会强制要求应用程序如何给 span 命名。
进程内请求上下文传输
请求的上下文传输是指,对于一个请求,所有处理这个请求的层都需要可以访问到同一个 context(上下文)。可以通过特定值,例如:用户id、token、请求的截止时间等,获取到这个 context(上下文)。也可以通过这种方法获取正在追踪的 Span。
下面有两种常用的上下文传输技术:
隐式传输
隐式传输技术要求 context(上下文)需要被存储到平台特定的位置,允许从应用程序的任何地方获取这个值。常用的 RPC 框架会利用 thread-local 或 continuation-local 存储机制,或者全局变量(如果是单线程处理)。
这种方式的缺点在于,有明显的性能损耗,有些平台比如 Go 不知道基于 thread-local 的存储,隐式传输将几乎不可能实现。
显示传输
显示传输技术要求应用程序代码,包装并传递 context(上下文)对象:
func HandleHttp(w http.ResponseWriter, req *http.Request) {
ctx := context.Background()
...
BusinessFunction1(ctx, arg1, ...)
}
func BusinessFunction1(ctx context.Context, arg1...) {
...
BusinessFunction2(ctx, arg1, ...)
}
func BusinessFunction2(ctx context.Context, arg1...) {
parentSpan := opentracing.SpanFromContext(ctx)
childSpan := opentracing.StartSpan(
"...", opentracing.ChildOf(parentSpan.Context()), ...)
...
}
显示传输的缺点在于,它向应用程序代码,暴露了底层的实现。
追踪客户端调用
当一个应用程序作为一个 RPC 客户端时,它可能希望在发起调用之前,启动一个新的追踪的 span,并将这个新的 span 随请求一起传输。下面,通过一个HTTP请求的实例,展现如何做到这点。
def traced_request(request, operation, http_client):
# retrieve current span from propagated request context
parent_span = get_current_span()
# start a new span to represent the RPC
span = tracer.start_span(
operation_name=operation,
child_of=parent_span.context,
tags={'http.url': request.full_url}
)
# propagate the Span via HTTP request headers
tracer.inject(
span.context,
format=opentracing.HTTP_HEADER_FORMAT,
carrier=request.headers)
# define a callback where we can finish the span
def on_done(future):
if future.exception():
span.log(event='rpc exception', payload=exception)
span.set_tag('http.status_code', future.result().status_code)
span.finish()
try:
future = http_client.execute(request)
future.add_done_callback(on_done)
return future
except Exception e:
span.log(event='general exception', payload=e)
span.finish()
raise
get_current_span()函数不是 OpenTracing API 的一部分。它仅仅代表一个工具类的方法,通过当前的请求上下文获取当前的span。(在Python一般会这样用)。- 假定 HTTP 请求是异步的,所以他会返回一个 Future。我们为这次调用增加的成功回调函数,在回调函数内部完成当前的 span。
- 如果 HTTP 客户端返回一个异常,则通过 log 方法将异常记录到 span 中。
- 因为 HTTP 请求可以在返回 Future 后发生异常,则使用 try/catch 块,在任何情况下都会完成 span,保证这个 span 会被上报,并避免内存溢出。
使用 Baggage / 分布式上下文传输
上面通过网络在客户端和服务端间传输的 Span 和 Trace,包含了任意的 Baggage。客户端可以使用 Baggage 将一些额外的数据传递到服务端,以及这个服务端的下游其他服务器。
# client side
span.context.set_baggage_item('auth-token', '.....')
# server side (one or more levels down from the client)
token = span.context.get_baggage_item('auth-token')
Logging 事件
在客户端 span 的示例代码中,已经使用过 log。事件被记录不会有额外的负载,也不一定必须在 span 创建或完成时进行操作。例如,应用通过可以在执行过程中,通过获取当前请求的当前 span,记录一个缓存未命中事件:
span = get_current_span()
span.log(event='cache-miss')
tracer 会为事件自动增加一个时间戳,这点和 Span 的 tag 操作时不同的。也可以将外部的时间戳和事件相关联。
使用外部的时间戳,记录Span
因为多种多样的原因,有些场景下,会将 OpenTracing 兼容的 tracer 集成到一个服务中。例如,一个用户有一个日志文件,其中包含大量的来自黑盒进程(如:HAProxy)产生的 span。为了让这些数据接入 OpenTracing 兼容的系统,API 需要提供一种方法通过外部的时间戳记录 span 的信息。
explicit_span = tracer.start_span(
operation_name=external_format.operation,
start_time=external_format.start,
tags=external_format.tags
)
explicit_span.finish(
finish_time=external_format.finish,
bulk_logs=map(..., external_format.logs)
)
在追踪开始之前,设置采样优先级
很多分布式追踪系统,通过采样来降低追踪数据的数量。有时,开发者想有一种方式,确保这 trace 一定会被记录(采样),例如:HTTP 请求中包含特定的参数,如 debug=true。OpenTracing API 标准化了一些有用的 tag,其中一个被叫做 “sampling priority”(采样优先级):精确的语义是由追踪系统的实现者决定的,但是任何值大于0(默认)代表一条 trace 的高优先级。为了将 debug 属性传递给追踪系统,需要在追踪前进行预处理,如下面所写的这样:
if request.get('debug'):
span = tracer.start_span(
operation_name=operation,
tags={tags.SAMPLING_PRIORITY: 1}
)
针对准备将 OpenTracing 集成到 web,RPC 或者其他框架的实践
总体来说,集成 OpenTracing 需要做两件事情:
服务端框架修改需求:
- 过滤器、拦截器、中间件或其他处理输入请求的组件
- span 的存储,存储一个 request context 或者 request 到 span 的映射表
- 通过某种方式对 tracer 进行配置
客户端框架修改需求:
- 过滤器、拦截器、中间件或其他处理对外调用的请求的组件
- 通过某种方式对 tracer 进行配置
服务端追踪
服务端追踪的目的是追踪请求在这个服务器内部的全生命周期的情况,并保证能够和前置的客户端追踪信息连接起来。可以在服务器收到请求时,创建 span,并在服务器完成请求处理后,关闭这些 span。追踪一个服务端请求的流程如下:
- 服务器接收到请求
- 从网络请求(跨进程的调用:HTTP等)获取当前的追踪链状态
- 创建一个新的 span
- 保存当前的追踪状态
- 服务器完成请求处理 / 返回响应
- 结束上面创建的 span
由于调用流程决定于请求的处理情况,所以需要知道如果修改框架的请求和响应处理——是否需要通过修改过滤器、中间件、配置栈或者其他机制。
获取当前的追踪链的状态
为了在分布式系统中,跨进程边界追踪调用情况,RPC 服务需要能够衔接每一个服务请求的服务端和客户端。OpenTracing 允许通过 inject 和 extract 方法,将 span 的上下文信息编码到 carrier 中。
如果客户端发起一个请求时,span 的上下文就已经被加到了请求内容中。需要做的工作是使用 io.opentracing.Tracer.extract 方法,从请求中获取 span 的上下文。carrier 判断使用哪种服务,决定使用哪种方法从请求中获取上下文;例如,web 服务通过 HTTP 头作为 carrier,从 HTTP 请求中获 span 上下文(如下所示):
Python:
span_ctx = tracer.extract(opentracing.Format.HTTP_HEADERS, request.headers)
Java:
import io.opentracing.propagation.Format;
import io.opentracing.propagation.TextMap;
Map<String, String> headers = request.getHeaders();
SpanContext parentSpan = tracer.getTracer().extract(Format.Builtin.HTTP_HEADERS,
new TextMapExtractAdapter(headers));
OpenTracing 当提取失败时,可以选择抛出异常,所以确保会捕获异常,防止异常造成服务器宕机。这种情况通常意味着请求来自于第三方应用(没有被追踪的应用),此时应该开启一个新的追踪。
保存当前的span上下文
在处理请求期间,让用户可以访问 span 上下文是十分重要的。只有获取上下文,才能为服务端,进行自定义的 tag 设置,记录事件(log event),创建子级的 span,用于最终展现服务内部的工作情况。为了满足这个目标,必须决定如何让用户访问当前的 span。这将由框架的架构决定。这里有两个常见用例:
使用请求上下文
如果使用的框架有一个请求上下文,上下文可以存储任意值,这样可以在请求处理过程中,一直把现在的 span 存储到上下文中。如果框架中有过滤器(Filter),这种实现方式是一种很好的方式。例如有一个请求上下文叫做 ctx,那么可以这样实现一个过滤器(Filter):
def filter(request):
span = # extract / start span from request
with (ctx.active_span = span):
process_request(request)
span.finish()
现在,在请求处理的任何时候,用户都可以通过 ctx.active_span 获取当前的 span。注意,一旦请求被处理,ctx.active_span 的值就不应该被改变。
建立请求和 span 的映射关系
如果存在这种情况:如有可能没有一个可用的请求上下文,或者针对请求的预处理和后处理有不同的过滤器方法, 可以选择建立一个请求和 span 的映射表。其中一种实现方式是创建一个框架特有的 tracer 的包装器(tracer wrapper),存储这个映射表,例如:
class MyFrameworkTracer:
def __init__(opentracing_tracer):
self.internal_tracer = opentracing_tracer
self.active_spans = {}
def add_span(request, span):
self.active_spans[request] = span
def get_span(request):
return self.active_spans[request]
def finish_span(request):
span = self.active_spans[request]
span.finish()
del self.active_spans[request]
- 如果服务器可以并行的处理请求,需要确保 span 的映射表是线程安全的。
- 过滤器处理示例代码如下:
def process_request(request):
span = # extract / start span from request
tracer.add_span(request, span)
def process_response(request, response):
tracer.finish_span(request)
注意:用户在处理 reponse 时,调用 tracer.get_span(request) 获取当前的 span,请确保用户依然能获取 request 实例。(也可以不使用 request 对象,而使用其他可以标识当前请求的参数)
客户端追踪
当框架有一个客户端组件的时候,需要在初始化 request 的时候,开启客户端的追踪。这样做是为了将生成的 span 放到请求头中,这样 span 才能请求随着请求,传递到服务端。
类似于服务端追踪,需要知道如何修改客户端代码,来发送请求,和接收相应。当客户端完成修改,就可以完成端到端的追踪了。
追踪一个客户端请求的流程如下:
- 准备请求对象
- 读取现在的追踪状态
- 新建一个 span
- 将 span 注入(Inject)到请求中
- 发送请求
- 接收响应
- 完成并关闭 span
读取现在的追踪状态 / 新建一个span
正如服务端一样,必须知道是应该开启一个新的追踪或者和一个已有的追踪连接上。例如,一个基于微服务架构分布式架构中,一个应用可能即是服务端又是客户端。一个服务的提供方同时又是另一个服务的发起方,这个东西需要被联系起来。如果存在一个活跃的调用链,需要将它的活跃 span 作为父级 span,并在客户端请求出开启一个新的 span。否则,需要新建没有没有父级节点的 span。
如何判断是否存在一个活跃的追踪,取决于如何存储的活跃的 span。如果使用一个请求上下文,你可以这样处理:
if hasattr(ctx, active_span):
parent_span = getattr(ctx, active_span)
span = tracer.start_span(operation_name=operation_name,
child_of=parent_span)
else:
span = tracer.start_span(operation_name=operation_name)
如果使用 request 到 span 的映射机制,可以这样处理:
parent_span = tracer.get_span(request)
span = tracer.start_span(
operation_name=operation_name,
child_of=parent_span)
注入(Inject) Span
注入 span 的时候,会把当前追踪的上下文信息放到客户端的请求中,这样当调用发生时,追踪可以在服务端被还原,并继续进行。如果是使用HTTP请求,可以使用HTTP头作为上下文数据的carrier(载体)。
span = # 从请求头中获取当前的追踪状态 `tracer.inject(span, opentracing.Format.HTTP_HEADERS, request.headers)`
完成并关闭span
当收到相应后,完成并关闭 span,标志着客户端调用结束。和服务端一样,如果完成这个操作取决于在客户端如何处理请求和响应。如果存在过滤器(filter),可以这样处理:
def filter(request, response):
span = # start span from the current trace state
tracer.inject(span, opentracing.Format.HTTP_HEADERS, request.headers)
response = send_request(request)
if response.error:
span.set_tag(opentracing., true)
span.finish()
否则,如果请求和相应是分开处理的,可能需要扩展 tracer,包含请求和 span 的映射关系。参考实现如下:
def process_request(request):
span = # start span from the current trace state
tracer.inject(span. opentracing.Format.HTTP_HEADERS, request.headers)
tracer.add_client_span(request, span)
def process_response(request, response):
tracer.finish_client_span(request)
跟踪大规模分布式系统的实践
Spans 和它们之间的关系
实现 OpenTracing 完成分布式追踪的两个基本概念就是 Spans和 Relationships (span 间关系):
Spans 是系统中的一个逻辑工作单元,包含这个工作单元启动时间和执行时间。在一条追踪链路中,各个 span 与系统中的不同组件有关,并体现这些组件的执行路径。
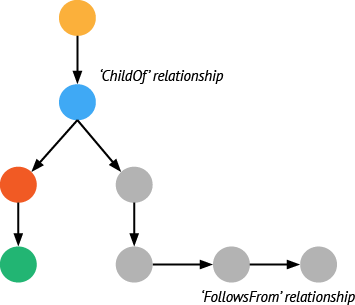
Relationships 是 span 间的连接关系。一个span可以和 0-n 个组件存在因果关系。这种关系是的各个 span 被串接起来,并用来帮助定位追踪链路的关键路径。
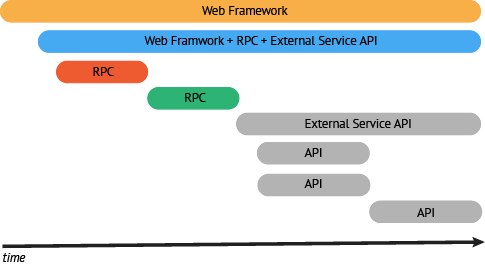
专注高价值区域
从 RPC 层和 web 框架开始构建追踪,是一个好方法。这两部分将包含事务路径中的大部分内容。
下一步,应该着手在没有被服务框架覆盖的事务路径上。为足够多的组件增加监控,为高价值的事务创建一条关键链路的追踪轨迹。
监控的首要目标,是基于关键路径上的 span,寻找最耗时的操作,为可量化的优化操作提供最重要的数据支持。例如,对于只占用事务时间 1% 的操作(一个大粒度的 span)增加更细粒度的监控,对于理解端到端的延迟(性能问题)不会有太大意义。
先走再跑,逐步提高
如果你正在构建你的跨应用追踪系统实现,使用这套系统建立高价值的关键事务与平衡关键事务和代码覆盖率的概念。最大的价值,在于为关键事务生成端到端的追踪。可视化展现追踪结果是非常重要的。它可能帮助你确定那块区域(代码块/系统模块)需要更细粒度的追踪。
一旦有了端到端的监控,很容易评估在哪些区域增加投入,进行更细粒度的追踪,并能确定事情的优先级。如果开始深入处理监控问题,可以考虑哪些部分能够复用。通过这些复用建立一套可以在多个服务间服用的监控类库。
这种方法可以提供广泛的覆盖(如:RPC,web 框架等),也能为关键业务的事务增加高价值的埋点。即使有些埋点(生成 span)的代码是一次性工作,也能通过这种模式发现未来工作的优先级,优化工作效率。
示例实例
下面的例子让上述的概念更具体一些:
在这个例子中,我们想追踪一个,由手机端发起,调用了多个服务的调用链。
首先,必须说明这个事务的大体情况。在例子中,事务如下所示:
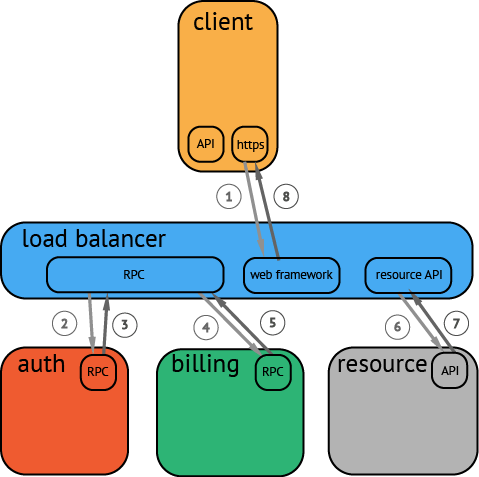
一个客户通过手机客户端向 web 发起了一个HTTP请求,产生一个复杂的调用流程:mobile client (HTTP) → web tier (RPC) → auth service (RPC) → billing service (RPC) → resource request (API) → response to web tier (API) → response to client (HTTP)
现在,对事务的大概情况了解了之后,需要去监控一些通用的协议和框架。最好的选择是从 RPC 服务框架开始,这将是收集 web 请求背后发生的调用情况的最好方式。(或者说,任何在分布式过程中发生的问题,都会在直接体现在 RPC 服务中)
下一个重点监控的组件应该是 web 框架。通过增加 web 框架的监控,能够得到一个端到端的追踪链路。虽然这点追踪链路有点粗,但是至少,追踪系统获取到了完整的调用栈。
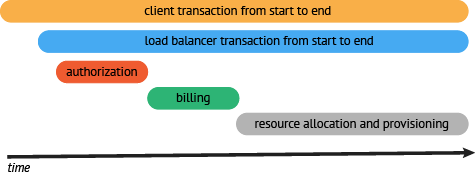
通过上面的工作,可以看到所需的调用链,并评估我们细化哪一块的追踪。在例子中可以看到,请求中最耗时的操作时获取资源的操作。所以,应该细化这块的监控粒度,监控资源定位内部的组件。一旦完成资源请求的监控,可以看到资源请求被分解成下图所示的情况:

*resource request (API) → container startup (API) → storage allocation (API) → startup scripts (API) → resource ready response (API)*
一旦完成资源组件的追踪,可以看到大量的时间消耗在提供上,下一步,深入分析,如果可能,优化资源获取程序,使用并行处理替代串行处理。
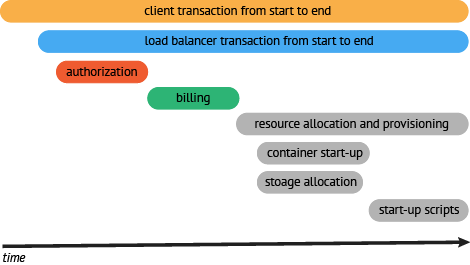
现在有了一条基于端到端调用流程的可视化展现以及基线,可以为这个服务建立明确的 SLO。另外,为内部服务建立 SLO,可以成为对服务正常和错误运行的时间的讨论的基础。
下一次迭代,回到最顶层的追踪,去寻找下一个长耗时的任务,但是没有明细展现,这时需要更细粒度的追踪。如果展现的粒度已经足够,可以进行下一个关键事务的追踪和调优处理了。
重复上述步骤。
Jaeger 链路追踪系统
Jaeger 是 Uber 开源的分布式追踪系统,兼容 OpenTracing 标准。其功能包括
- 分布式上下文传播
- 分布式交易监控
- 根本原因分析
- 服务依赖性分析
- 性能/延迟优化
Jaeger 的系统架构
Jaeger 的架构图如下:
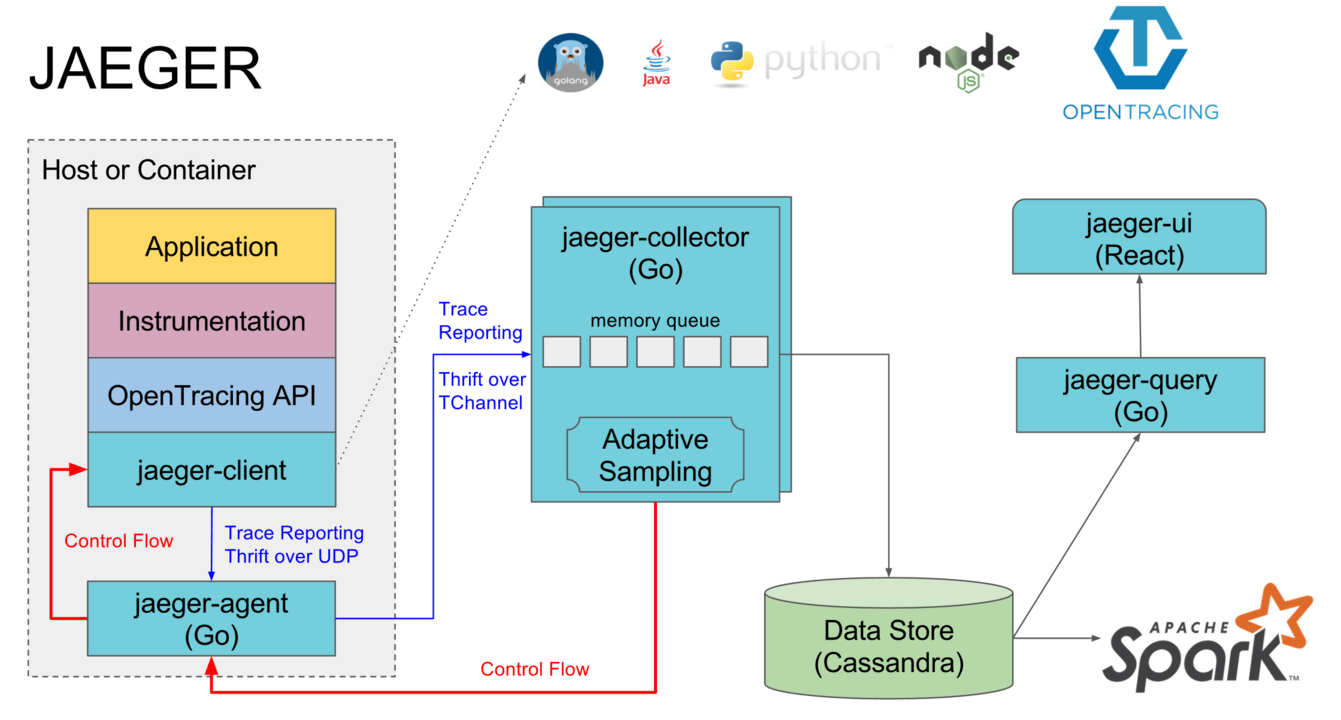
Jaeger 主要包括以下这些组件:(每一个组件都支持单独部署)
- jaeger-client:Jaeger 的客户端,实现了 OpenTracing 的 API,支持主流编程语言。客户端直接集成在目标 Application 中,其作用是记录和发送 Span 到 Jaeger Agent。在 Application 中调用 Jaeger Client Library 记录 Span 的过程通常被称为埋点。
- jaeger-agent:暂存 Jaeger Client 发来的 Span,并批量向 Jaeger Collector 发送 Span,一般每台机器上都会部署一个 Jaeger Agent。官方的介绍中还强调了 Jaeger Agent 可以将服务发现的功能从 Client 中抽离出来,不过从架构角度讲,如果是部署在 Kubernetes 或者是 Nomad 中,Jaeger Agent 存在的意义并不大。
- jaeger-collector:接受 Jaeger Agent 发来的数据,并将其写入存储后端,目前支持采用 Cassandra 和 Elasticsearch 作为存储后端。比较推荐用 Elasticsearch,既可以和日志服务共用同一个 ES,又可以使用 Kibana 对 Trace 数据进行额外的分析。架构图中的存储后端是 Cassandra,旁边还有一个 Spark,讲的就是可以用 Spark 等其他工具对存储后端中的 Span 进行直接分析。
- jaeger-query & jaeger-ui:读取存储后端中的数据,以直观的形式呈现。
jaeger-client 库
Jaeger客户端是 OpenTracing API 的特定于语言的实现。 它们可用于手动或通过与 OpenTracing 集成的各种现有开源框架(例如 Flask,Dropwizard,gRPC 等)来检测应用程序以进行分布式跟踪。
接收请求的服务会在接收到新请求时创建 spans,并将上下文信息(spans,id,span id 和 baggage) 附加到传出的请求。 只有各种 id 和 baggage 随请求一起传播;而其他的 Spans 信息,例如操作名称,日志等不会被进行传播。取而代之的是,采样的 spans 会在后台异步传输到 Jaeger Agents。
该架构的开销很小,并且设计为始终在生产中启用。为了最大程度的减少开销,Jaeger-client 采用了各种采样策略。当对 trace 进行采样时,对 span 的分析数据将被捕获并将其传输到 Jeager 后端。如果没有对 trace 进行采样,则不会采集任何性能分析数据,并且对 OpenTracing API 的调用会被短路,以产生最小的开销。默认情况下,Jaeger client 对 0.1% 的 traces 进行采样(每1000个中的1个),并且能够从代理中检索采样策略。
jaeger-agent
jaeger-agent 是一个网络守护程序,它侦听通过 UDP 发送的spans,然后将其分批发送给 Collector 收集器。它旨在作为基础结构组件部署到所有主机。jaeger-agent 将 Collector 的路由和发现从 jaeger-client 抽象出来。
jaeger-collector
Jaeger-collector 从 Jaeger-agent 接收跟踪,并通过处理管道运行它们。当前,管道会验证跟踪,为其建立索引, 执行任何转换并最终存储它们。Jaeger 的存储设备是可插拔组件,目前支持 Cassandra,Elasticsearch 和 Kafka。
jaeger-query
查询是一项从存储中检索 traces 并通过 UI 来显示的服务。
Jaeger 采样
Jaeger 库实现了一致的前期(或基于头)的采样。例如,假设有一个简单的调用图,其中服务 A 调用服务 B,服务 B 调用服务C:A-> B-> C。当服务 A 收到不包含跟踪信息的请求时,Jaeger 跟踪器将启动一个新的 trace,为其分配一个随机跟踪 ID,并根据当前安装的采样策略做出采样决定。 采样决策将与请求一起传播到 B 和 C,因此那些服务将不再做出采样决策,而是会尊重顶级服务 A 的决策。 这种方法保证了,如果对跟踪进行了采样,则所有其 spans 将记录在后端。 如果每个服务都做出自己的抽样决定,那么就很难在后端获得完整的跟踪。
支持设置采样率是 Jaeger 的一个亮点,在生产环境中,如果对每个请求都开启 Trace,必然会对系统性能带来一定压力,除此之外,数量庞大的 Span 也会占用大量的存储空间。为了尽量消除分布式追踪采样对系统带来的影响,设置采样率是一个很好的办法。
客户端采样策略配置
当使用配置对象来实例化 tracer 时,可以通过 sampler.type 和 sampler.param 属性选择采样类型。Jaeger 支持下面四种采样策略:
- Constant(
sampler.type=const):const 意为常量,采样器始终对所有 traces 做出相同的决定。sample.param=1则采样所有 tracer,sample.param=0则都不采样。 - Probabilistic (
sampler.type=probabilistic):概率采样,采样概率介于0-1之间,通过sample.param属性进行配置,例如,在sampler.param=0.1的情况下,将在10条 traces 中大约采样1条。 - Rate Limiting (
sampler.type=ratelimiting):设置每秒的采样次数上限。当sampler.param=2的时候,将以每秒 2 条 traces 的速率对请求进行采样。 - Remote (
sampler.type=remote):默认配置,client 将从 jaeger-agent 中获取当前服务使用的采样策略,这允许 Client 从 Jaeger Agent 中动态获取采样率设置。
自适应采样器
自适应采样器是一个组合了两个功能的复合采样器:
- 它基于每个操作(即基于 span 操作名称)做出抽样决策。这在API服务中特别有用,这些 API 服务的端点的流量可能非常不同,并且对整个服务使用单个概率采样器可能会使某些低 QPS 端点饿死(从不采样)。
- 它支持最低的保证采样率,例如始终允许每秒最多 N 条 traces,然后以一定的概率采样所有高于此值的采样率(一切都是针对每个操作,而不是针对每个服务)。
可以静态配置每个操作参数,也可以在远程采样器的帮助下从 Jaeger 后端定期提取每个操作参数。自适应采样器旨在与 Jaeger 后端即将推出的自适应采样功能一起使用。
Jaeger 采样配置示例
收集器可以通过 --sampling.strategies-file 选项通过静态采样策略实例化(如果使用 Remote sample r配置, 则将传播到相应的服务)。该选项需要一个已定义采样策略的 json 文件的路径。
如果未提供任何配置,则收集器将为所有服务返回默认概率抽样策略,概率为 0.001(0.1%)
{
"service_strategies": [
{
"service": "foo",
"type": "probabilistic",
"param": 0.8,
"operation_strategies": [
{
"operation": "op1",
"type": "probabilistic",
"param": 0.2
},
{
"operation": "op2",
"type": "probabilistic",
"param": 0.4
}
]
},
{
"service": "bar",
"type": "ratelimiting",
"param": 5
}
],
"default_strategy": {
"type": "probabilistic",
"param": 0.5,
"operation_strategies": [
{
"operation": "/health",
"type": "probabilistic",
"param": 0.0
},
{
"operation": "/metrics",
"type": "probabilistic",
"param": 0.0
}
]
}
}
service_strategies 元素定义特定于服务的采样策略,而 operation_strategies 元素定义特定于操作的采样策略。可能有两种策略:概率策略和速率限制,如上所述(注意:operation_strategies 不支持速率限制)。如果服务不是 service_strategies 定义在内的操作,则采用 default_strategy 定义的采样策略。
在上面的例子中,
服务 foo 的所有操作均以概率 0.8 进行采样,操作 op1和 op2 分别以概率 0.2 和 0.4 概率进行采样。 服务栏的所有操作均以每秒 5 条 traces 的速率进行速率限制。 任何其他服务都将以 default_strategy 定义的概率 0.5 进行采样。
default_strategy 还包括共享的按操作策略。在此示例中,使用概率 0 禁用了对所有服务的 /health 和 /metrics 端点的跟踪。这些操作策略将适用于配置中未列出的任何新服务,以及 foo 和 bar 服务,除非它们定义了自己针对这两个操作的策略。
Jaeger 部署
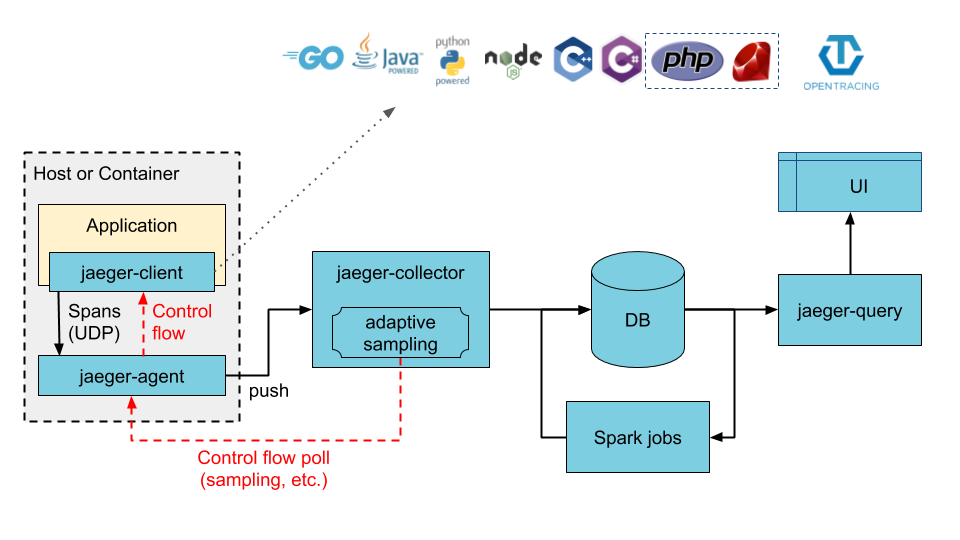
以上这些组件,官方提供了 all-in-one 镜像和二进制文件进行一键部署,很方便用于本地测试,当然也可以作为分布式系统运行。部署 Jaeger 有两个主要的选项:
收集器直接写入数据库
收集器将数据写入 kafka 作为初步缓冲区
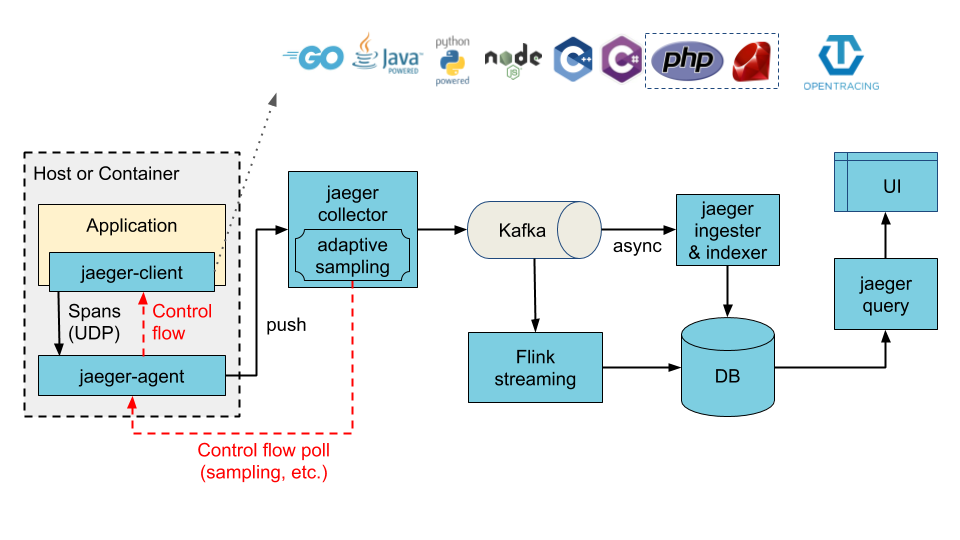
图示中的 Ingester 是一项从 Kafka topic 读取并写入另一个存储后端(Cassandra,Elasticsearch)的服务。
使用示例
以上面 OpenTracing 的例子,对其改用 Jaeger 追踪系统,由于 Jaeger 遵循 OpenTracing 规范,并不需要修改服务端代码,只需要修改启动的 main 代码内容。
jaeger 支持以下的客户端库:
| Language | GitHub Repo |
|---|---|
| Go | jaegertracing/jaeger-client-go |
| Java | jaegertracing/jaeger-client-java |
| Node.js | jaegertracing/jaeger-client-node |
| Python | jaegertracing/jaeger-client-python |
| C++ | jaegertracing/jaeger-client-cpp |
| C# | jaegertracing/jaeger-client-csharp |
修改后的 main.go 如下:
var (
port = flag.Int("port", 8888, "Example app port.")
appdashPort = flag.Int("appdash.port", 8700, "Run appdash locally on this port.")
)
func main() {
flag.Parse()
// 连接到追踪系统(Appdash)
//addr := startAppdashServer(*appdashPort)
//tracer := appdashot.NewTracer(appdash.NewRemoteCollector(addr))
//opentracing.InitGlobalTracer(tracer)
// 连接到追踪系统(Jaeger)
cfg := jaegercfg.Configuration{
Sampler: &jaegercfg.SamplerConfig{
Type: jaeger.SamplerTypeConst,
Param: 1,
},
Reporter: &jaegercfg.ReporterConfig{
LogSpans: true,
},
}
jLogger := jaegerlog.StdLogger
jMetricsFactory := metrics.NullFactory
closer, err := cfg.InitGlobalTracer(
"serviceName",
jaegercfg.Logger(jLogger),
jaegercfg.Metrics(jMetricsFactory),
)
if err != nil {
log.Printf("Could not initialize jaeger trace: %s",err.Error())
return
}
defer closer.Close()
addr := fmt.Sprintf(":%d", *port)
mux := http.NewServeMux()
mux.HandleFunc("/", server.IndexHandler)
mux.HandleFunc("/home", server.HomeHandler)
mux.HandleFunc("/async", server.ServiceHandler)
mux.HandleFunc("/service", server.ServiceHandler)
mux.HandleFunc("/db", server.DbHandler)
fmt.Printf("Go to http://localhost:%d/home to start arequest!\n", *port)
log.Fatal(http.ListenAndServe(addr, mux))
}
运行之前,需要先将 Jaeger 的各个组件都跑起来,官方提供了 all-in-one 支持一键部署,可以下载可执行文件先执行,或者运行 docker 镜像。
之后,运行 main 函数,就可以通过 http://localhost:16686 UI 界面直观的看到链路追踪的详细内容:
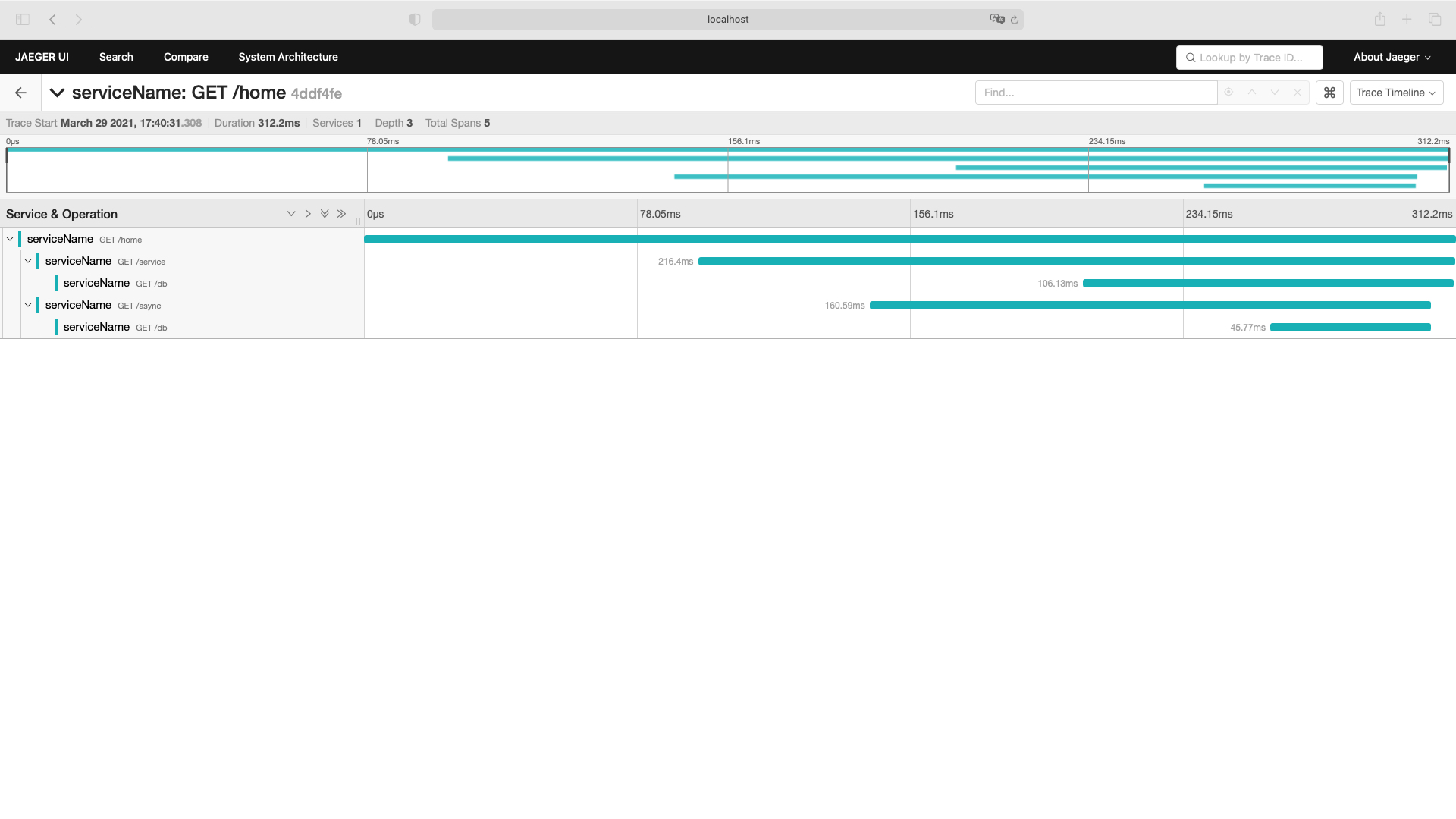
关于 Jeager 在 go 语言中的更多使用细则,可以查看 jaeger-client-go官方仓库 以及仓库下的 config/example_test.go 目录。
参考链接: