ElasticSearch
简介
Elasticsearch 是一个分布式文档储存中间件,它不会将信息储存为列数据行,而是储存已序列化为 JSON 文档的复杂数据结构。当在一个集群中有多个节点时,储存的文档分布在整个集群里面,并且立刻可以从任意节点去访问。
ElasticSearch 是一个高可用开源全文检索和分析组件。提供存储服务,搜索服务,大数据准实时分析等。一般用于提供一些提供复杂搜索的应用。
安装
ElasticSearch 安装
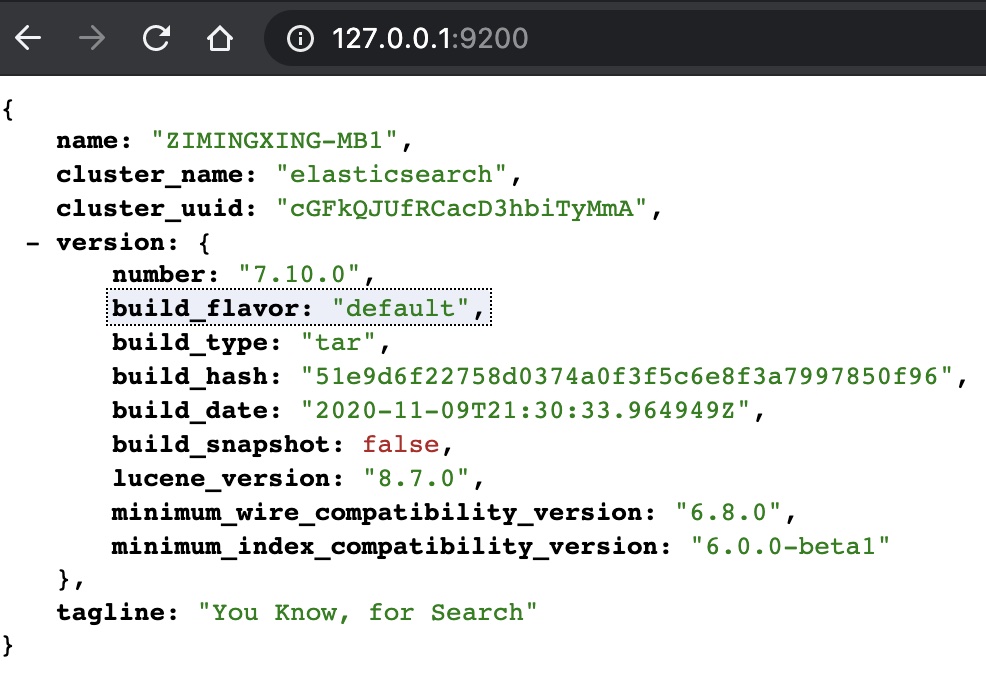
通过 ElasticSearch官网下载压缩包解压后,直接在 bin 目录下的 ./elasticserch 即可启动。启动后默认端口是 9200,页面如下:
ElasticSearch 的目录结构如下:
bin 启动文件
config 配置文件
log4j2 日志配置文件
jvm.options java虚拟机相关的配置
elasticsearch.yml elasticsearch的配置文件,默认 9200 端口;跨域等
lib 相关jar包
logs 日志
modules 功能模块
plugins 插件
ElasticSearch 可视化
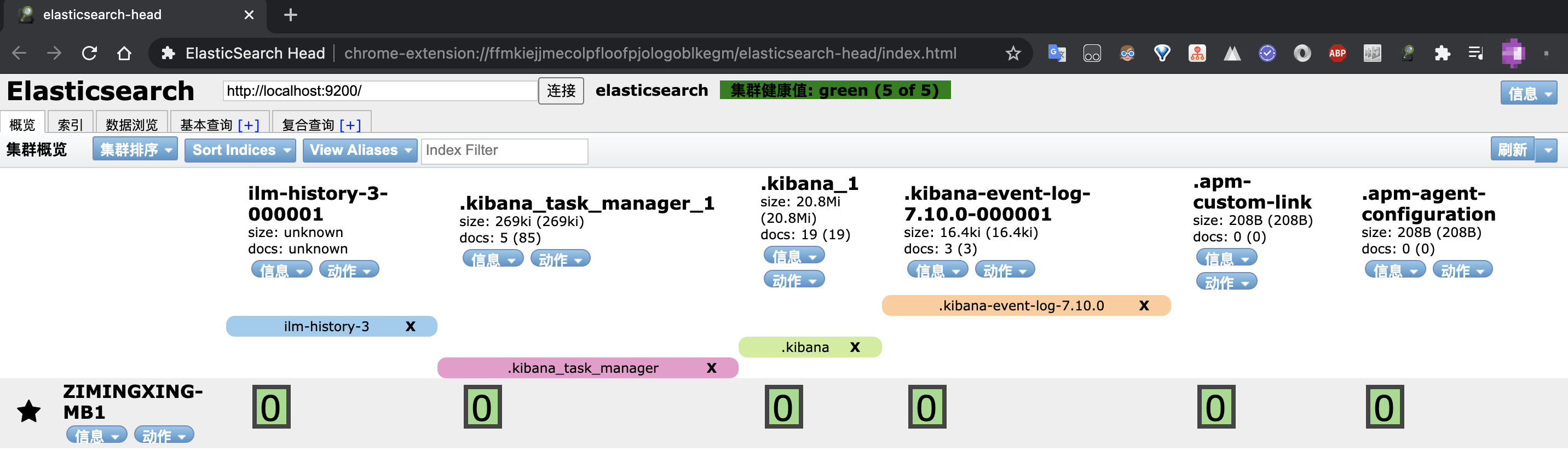
ElasticSearch 可视化有两个工具,一个是 ElasticsearchHead,最简单的方式是直接安装 Chrome浏览器拓展:
另外一个是 Kibana,通过 ElasticSearch官网下载压缩包解压后在 bin 目录下运行 ./kibana 命令即可启动,这里可以对其进行汉化,汉化包在 /x-pack/plugins/translations/translations/zh-CN.json下,通过在 config 目录下修改 kibana.yml 文件,最后一行修改或加入:
i18n.locale: "zh-CN"
重新启动即可看到汉化版的界面:
核心概念
与关系型数据库对比
es时面向文档的, ElasticSearch 一切都是 json
| 关系型数据库 | ElasticSearch |
|---|---|
| 数据库(database) | 索引(indices) |
| 表(tables) | types(8.0可能被淘汰) |
| 行(rows) | documents |
| 字段(columns) | fields |
ElasticSearch(集群)中可以包含多个索引(数据库),每个索引中可以包含多个类型(表),每个类型下又包含多个文档(行),每个文档中又包含多个字段(列)。
相关概念
物理设计
ElasticSearch 在后台把每个索引划分成多个分片,每个分片可以在集群中的不同服务器之间迁移,一个人启动默认就是一个集群。
索引
分片是物理空间概念,索引中的数据都分布在分片上。索引是具有某些相似特征的文档的集合。可以把索引理解为数据库文档中的数据库。事实上,数据被存储和索引在分片(shards)中,索引只是一个把一个或多个分片分组在一起的逻辑空间。
文档
文档是可索引信息的基本单元,以 JSON 表示。在 ElasticSearch 中,文档有几个重要属性:
自我包含,一盘文档同时包含字段和对应的值,也就是同时包含 key-value
可以是层次型的,一个文档中包含自文档,复杂的逻辑实体就是这么来的
灵活的结构,文档不依赖于预先定义的模式,在 ElasticSearch 中,对于字段是非常灵活的,有时候可以忽略该字段,或者动态添加一个新的字段。
一个文档主要的元信息如下:
1. _index: 文档所属的索引名
2. _type: 文档所属的类型名
3. _id: 文档的唯一ID
4. _source: 文档存储的 Json 数据
5. _version:文档的版本信息
6. _score: 相关性打分
可以用文档来定义单个产品信息或是员工信息。可以把文档理解为数据库文档中的行列数据。在索引/类型中,可以存储任意数量的文档。文档有几个共同不可缺的属性,分别为 _index, _type, _id, 针对特定一个或一类文档进行操作时,必须指定这些属性。 最后要注意的是,虽然文档物理上是驻留在索引中,但实际上文档必须索引/分配给索引中的类型。
类型
类型是文档的逻辑容器,就像关系型数据库中,表格是行的容器。在索引中,可以定义一个或多个类型。类型是索引的逻辑类别/分区,其语义完全由开发者决定。通常,为具有一组公共字段的文档定义类型。可以把索引理解成数据库文档中的表。类型中对于字段的定义称为映射,比如 name 映射为字符串类型。
分片与复制
索引可以存储尽可能多的数据,但是这种情况下性能往往不太乐观,或者常见的磁盘容量限制也不能允许。所以 Elasticsearch 提供了类似于 MongoDB 中的分片功能,该功能能将索引细分为多个分片。每个分片本身是一个功能完全和独立的“索引”,可以托管在集群中的任何节点上。一个集群至少有一个节点,而一个节点就是一个 ElasticSearch 进程,如果创建索引,那么索引将会有 5 个分片(primary shard,又称主分片)构成的,每个主分片会有一个副本(replica shard,又称复制副本)。
同样的,有分片技术来处理数据量增长快速的问题,就意味着需要复制技术来应对这种过程中(其实不只是该过程,任何情况下都应该有安全意识)数据安全的问题。Elasticsearch 允许将索引分片的一个或多个副本转换为所谓的副本分片。复制技术提供了数据的高可用性和搜索吞吐的扩展性。不过需要注意的是,副本分片从不分配在与从其复制的原始/主分片相同的节点上,有利于保证一个挂了其他的不至于丢失。
总而言之,每个索引可以拆分为多个分片。索引也可以复制为零(意味着没有副本)或更多次。一旦复制,每个索引将具有主分片(从索引复制的原始分片)和副本分片(主分片的副本)。开发者可以在创建索引时就为每个索引定义分片和副本的数量。创建索引后,可以随时动态更改副本数,但不能在此过程后随即更改分片数。
倒排索引
Elasticsearch 使用一种被称为倒排索引的数据结构,该结构支持快速全文搜索。在倒排索引里列出了所有文档中出现的每一个唯一单词并分别标识了每个单词在哪一个文档中。
索引可以被认为是文档的优化集合,每个文档索引都是字段的集合,这些字段是包含了数据的键值对。默认情况下,Elasticsearch 为每个字段中的所有数据建立倒排索引,并且每个索引字段都有专门的优化数据结构。例如:文本字段在倒排索引里,数值和地理字段被储存在 BKD 树中。正是因为通过使用按字段数据结构组合,才使得 Elasticsearch 拥有如此快速的搜索能力。
IK 分词器插件
当一个文档被存储时,ES 会使用分词器从文档中提取出若干词元(token)来支持索引的存储和搜索。ES 内置了很多分词器,但内置的分词器对中文的处理不好。ElasticSearch 可以安装插件,这里以 IK 分词器为例:
下载地址:https://github.com/medcl/elasticsearch-analysis-ik
安装方式有两种:
直接下载压缩包解压后放到 ElasticSearch 的 plugins 目录下。
利用 ElasticSearch 自带的插件下载工具:
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.3.0/elasticsearch-analysis-ik-6.3.0.zip注意:替换
6.3.0为自己的 elasticsearch 版本
IK 提供了两个分词算法:ik_smart 和 ik_max_word,其中 ik_smart 为最少切分,ik_max_word 为最细粒度划分。
ik_max_word:可以插入文本做最细粒度的细分,替换为“中华人民共和国国歌”分割为“中华人民共和国,中华人民,中华,华人,人民共和国,人民,人,民,共和国,共和,和,国国,国歌”,会穷尽各种可能的组合,适合 Term Query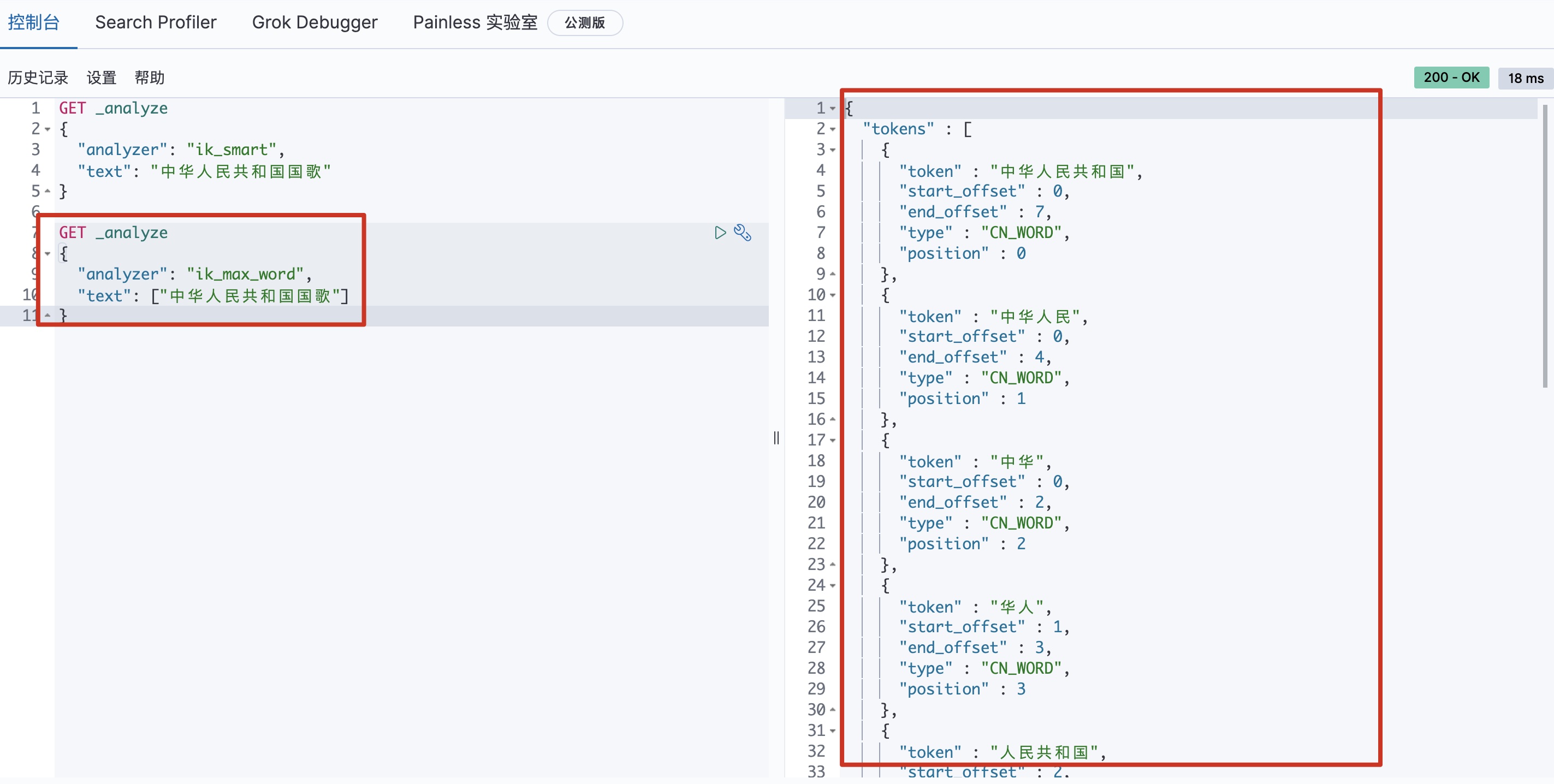
ik_smart:会做最粗粒度的分割,细分为“中华人民共和国国歌”分割为“中华人民共和国,国歌”,适合词组查询。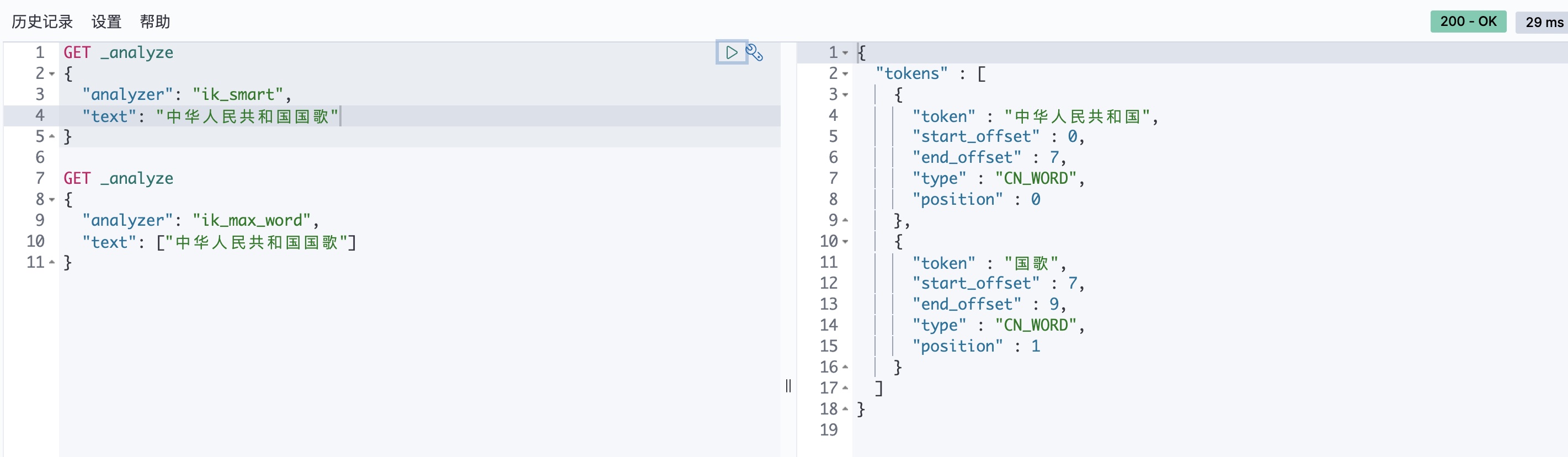
另外,对于一些词语可能分词器没发识别,比如名字,可以自己定义配置文件:
IKAnalyzer.cfg.xml文件存在于 ElasticSearch 的配置文件目录或者插件中 IK 的配置目录中,配置项如下:
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">custom/mydict.dic;custom/single_word_low_freq.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">custom/ext_stopword.dic</entry>
<!--用户可以在这里配置远程扩展字典 -->
<entry key="remote_ext_dict">location</entry>
<!--用户可以在这里配置远程扩展停止词字典-->
<entry key="remote_ext_stopwords">http://xxx.com/xxx.dic</entry>
</properties>
然后只需要自己创建一个 dic文件,直接写入定义的词语即可,比如 study_test.dic:
啊巴啊巴
数据操作
ElasticSearch 的数据操作使用 RestFul 风格的接口设计,可以使用 curl 发送操作请求,也可以直接在 Cabana 操作。
ElasticSearch 主要有以下几种操作:
| method | url地址 | 描述 |
|---|---|---|
| PUT | localhost:9200/索引名称/类型名称/文档id | 创建文档(指定文档id) |
| POST | localhost:9200/索引名称/类型名称/ | 创建文档(随机文档id) |
| POST | localhost:9200/索引名称/类型名称/文档id/_update | 修改文档 |
| DELETE | localhost:9200/索引名称/类型名称/文档id | 删除文档 |
| GET | localhost:9200/索引名称/类型名称/文档id | 通过文档id查询文档 |
| POST | localhost:9200/索引名称/类型名称/_search | 查询所有数据 |
新增操作
// RestFul风格,到哪个url目录就修改哪个级别(索引、类型、文档)
PUT /索引名/类型名(未来删除)/文档id
{请求体}
PUT /test1/type1/1
{
"name":"silverming",
"age":10
}
对于类型名,由于这个其实现在使用的情况不多,渐渐被淘汰,默认采用 _doc 替代,即 PUT /test2/_doc/1
关于映射关系
Mapping 主要用于定义索引的字段名称和数据类型以及倒排索引等相关配置,Mapping 可以系统自动推断生成,也可以由用户自己定义:
PUT /test3
//该索引包含三个字段
//name,类型是 long,不支持索引搜索
//phone,类型是 keyword,对于值为空的情况可以使用"NULL"字符串来搜索
//name,类型是 text,并定义了索引级别,以及自定义的分词器
{
"mappings" : {
"properties" : {
"id" : {
"type" : "long",
"index": false
},
"name" : {
"type" : "text",
"index_options": "positions",
"copy_to": "fullName",
"fields": {
"english_comment":{
"type": "text",
"analyzer": "english",
"search_analyzer": "english"
}
}
},
"phone" : {
"type" : "keyword",
"null_value": "NULL"
}
}
}
}
mapping 具有以下这些字段属性:
- type:字段的数据类型,并没有提供专门数组类型,通过 TEXT 字段实现,Elasticsearch 主要支持以下几种数据类型:
- Text:默认情况下会进行分词,会被分词器解析
- Keyword:不会进行分词,全文本匹配,不会被分词器解析
- Date:日期类型
- Integer/Floating:整数/浮点数
- Boolean:布尔类型
- IPv4 & IPv6
- 特殊类型:geo_point & geo_shape & percolator
- index:表示该字段是否可以被搜索,是否需要建立倒排索引
- index_options 属性:控制倒排索引记录的内容,内容越多,占用空间越大,text 类型默认是 positions,其它默认是 docs
- docs: 记录 docId
- freqs:记录 docId 和 term frequencies
- positions:记录 docId 和 term frequencies 和 term postion
- offsets:记录 docId 和 term frequencies 和 term postion 和 character offsets
- null_value:默认情况下 null 是无法被直接搜索的,如果需要对 Null 值进行搜索,可以设置该属性,表示 null 值被当成什么来搜索
- copy_to:将值拷贝到对应的字段上,多个字段可以同时 copy_to 到同一个字段上,用于对于多个字段同时查询,目标字段不会出现在 mapping 的定义中,但是可以用于搜索
- fields: 多字段特性,可以增加一个 keyword 字段,可以为搜索和索引指定不同的分词器等
删除操作
使用 DELETE 命令。
修改操作
关于修改操作,可以直接使用 PUT 命令,但是有时候如果只需要更新个别字段,需要将原有字段的值也写上,否则原有的会被删除。
更好的办法是使用 POST 命令,在后面加上/_update,就可以直接修改相应的值。
不加
/update会跟 PUT 效果一样
//"doc"要加上
POST /test1/_doc/1/_update
{
"doc":{
"birth":"1998-02-25"
}
}
查询操作
使用 GET 命令或者 POST命令加后缀 /_search 进行查询。url 具体到文档 id 就可以查到数据,到索引只会显示索引的信息。
GET /user/_doc/1
对于搜索可以使用条件搜索:
基础条件查询
对于模糊匹配查询,可以使用 match 查询,_source 可以指定需要查询出来的字段,sort 可以对查询结果进行排序,使用 order 进行排序规则说明(asc、desc),from 和 size 用于范围查找。
# match 会使用分词器解析,先分析分档,然后通过分析的文档进行查询
GET user/_doc/_search
{
"query":{
"match":{
"name":"xxx"
}
},
"_source":["name","dsec","age"],
"sort":[
{
"age":{
"order":"asc"
}
}
],
"from":0,
"size":1
}
# 对于搜索的内容,多个内容可以使用空格隔开,只要满足其中一个结果既可以被查出来,匹配度可以通过score判断
GET user/_search
{
"query": {
"match": {
"tags": "男 技术 猛"
}
}
}
多条件查询
用 bool 查询可以实现多条件组合查询。这种查询将多查询组合在一起,成为用户自己想要的布尔查询。它接收以下参数:
must文档必须匹配这些条件才能被包含进来。
must_not文档 必须不匹配这些条件才能被包含进来。
should如果满足这些语句中的任意语句,将增加
_score,否则,无任何影响。它们主要用于修正每个文档的相关性得分。filter必须匹配,但它以不评分、过滤模式来进行。这些语句对评分没有贡献,只是根据过滤标准来排除或包含文档。
使用
must相当于 AND 条件查询,使用should相当于 OR 条件查询,使用must_not相当于 NOT IN 条件查询。
# AND
GET user/_doc/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "xx"
}
},
{
"match": {
"age": "12"
}
}
]
}
}
}
# OR
GET user/_doc/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"name": "xx"
}
},
{
"match": {
"age": "18"
}
}
]
}
}
}
# NOT IN
GET user/_doc/_search
{
"query": {
"bool": {
"must_not": [
{
"match": {
"name": "xx"
}
}
]
}
}
}
带过滤条件的查询
使用 filter 可以实现过滤查询,range 表示结果集的范围:
- gt :
> - gte:
>= - lt:
< - lte:
<=
# 过滤
GET user/_search
{
"query":{
"bool":{
"must":[
{
"match":{
"name":"xx"
}
}
],
"filter":{
"range":{
"age":{
"gte":12,
"lte":17
}
}
}
}
}
}
精确查询
# 假设 mapping 定义如下:
PUT testdb
{
"mappings": {
"properties": {
"name":{
"type":"text"
},
"desc":{
"type": "keyword"
}
}
}
}
# 精确查询,term 查询是通过倒排索引指定的词条进行精确查找的。
# name 是 text,所以会被拆分,结果可能有多个
GET testdb/_search
{
"query": {
"term": {
"name": "xxx"
}
}
}
# desc 是 keyword,其不会被拆分,有完全一样的才返回
GET testdb/_search
{
"query": {
"term": {
"desc": "梓铭学es"
}
}
}
多个值的精确匹配如下:
# 多个值精确匹配
PUT testdb/_doc/3
{
"t1":"22",
"t2":"2020-11-24"
}
PUT testdb/_doc/3
{
"t1":"23",
"t2":"2021-11-24"
}
GET testdb/_search
{
"query": {
"bool": {
"should": [
{
"term": {
"t1": "22"
}
},
{
"term": {
"t1": "23"
}
}
]
}
}
}
高亮查询
# 高亮查询
GET user/_search
{
"query": {
"match": {
"name": "梓铭"
}
},
"highlight": {
"pre_tags": "<p class='key' style='color:red'>",
"post_tags": "</p>",
"fields": {
"name": {}
}
}
}
其他命令
可以通过 GET _cat/... 命令查看相关状态、数量、健康等很多信息。
参考目录: