go 实用代码片段和注意事项
常用代码段
new() 和 make() 选择
切片、映射和通道,使用 make
数组、结构体和所有的值类型,使用 new
new 出来的是一个指针
字符串相关操作
修改字符串的一个字符
str:="hello"
c:=[]byte(str)
c[0]='c'
s2:= string(c) // s2 == "cello"
获取字符串的字串
substr := str[n:m]
使用 for 或者 for-range 遍历一个字符串
// gives only the bytes:
for i:=0; i < len(str); i++ {
… = str[i]
}
// gives the Unicode characters:
for ix, ch := range str {
…
}
获取一个字符串的字节数
len(str)
获取一个字符串的字符数:
最快速:utf8.RuneCountInString(str)
len([]int(str))
字符串拼接
当需要对一个字符串进行频繁的操作时,谨记在 go 语言中字符串是不可变的(类似 java 和 c#)。使用诸如 a += b 形式连接字符串效率低下,尤其在一个循环内部使用这种形式。这会导致大量的内存开销和拷贝。应该使用一个字符数组代替字符串,将字符串内容写入一个缓存中。
// builder 方式
var builder strings.Builder
builder.WriteString("asong")
builder.String()
// buffer 方式,性能次于 string builder
var b bytes.Buffer
...
for condition {
b.WriteString(str) // 将字符串str写入缓存buffer
}
return b.String()
打印字符串
函数 Printf 主要用于打印输出到控制台。通常使用的格式化字符串作为第一个参数:
func Printf(format string, list of variables to be printed)
这个格式化字符串可以含有一个或多个的格式化标识符,例如:%..,其中 .. 可以被不同类型所对应的标识符替换,如 %s 代表字符串标识符、%v 代表使用类型的默认输出格式的标识符。这些标识符所对应的值从格式化字符串后的第一个逗号开始按照相同顺序添加,如果参数超过 1 个则需要使用逗号分隔。使用这些占位符可以很好地控制格式化输出的文本。
函数 fmt.Sprintf 与 Printf 的作用是完全相同的,不过前者将格式化后的字符串以返回值的形式返回给调用者,因此可以在程序中使用包含变量的字符串。
函数 fmt.Print 和 fmt.Println 会自动使用格式化标识符 %v 对字符串进行格式化,两者都会在每个参数之间自动增加空格,而后者还会在字符串的最后加上一个换行符。例如:
fmt.Print("Hello:", 23)
将输出:Hello: 23。
格式化说明符
在格式化字符串里,%d 用于格式化整数(%x 和 %X 用于格式化 16 进制表示的数字),%g 用于格式化浮点型(%f 输出浮点数,%e 输出科学计数表示法),%0d 用于规定输出定长的整数,其中开头的数字 0 是必须的。
%n.mg 用于表示数字 n 并精确到小数点后 m 位,除了使用 g 之外,还可以使用 e 或者 f,例如:使用格式化字符串 %5.2e 来输出 3.4 的结果为 3.40e+00。
%b 是用于表示位的格式化标识符。
格式化说明符 %c 用于表示字符;当和字符配合使用时,%v 或 %d 会输出用于表示该字符的整数;%U 输出格式为 U+hhhh 的字符串
指针的格式化标识符为 %p
优雅实现存储单位的常量枚举
使用位左移与 iota 计数配合可优雅地实现存储单位的常量枚举:
type ByteSize float64
const (
_ = iota // 通过赋值给空白标识符来忽略值
KB ByteSize = 1<<(10*iota)
MB
GB
TB
PB
EB
ZB
YB
)
优雅的进行错误检测和处理
避免写出这样的代码:
... err1 := api.Func1()
if err1 != nil {
fmt.Println("err: " + err.Error())
return
}
err2 := api.Func2()
if err2 != nil {
...
return
}
首先,包括在一个初始化的 if 语句中对函数的调用。但即使代码中到处都是以 if 语句的形式通知错误(通过打印错误信息)。通过这种方式,很难分辨什么是正常的程序逻辑,什么是错误检测或错误通知。还需注意的是,大部分代码都是致力于错误的检测。通常解决此问题的好办法是尽可能以闭包的形式封装你的错误检测,例如下面的代码:
func httpRequestHandler(w http.ResponseWriter, req *http.Request) {
err := func () error {
if req.Method != "GET" {
return errors.New("expected GET")
}
if input := parseInput(req); input != "command" {
return errors.New("malformed command")
}
// 可以在此进行其他的错误检测
} ()
if err != nil {
w.WriteHeader(400)
io.WriteString(w, err)
return
}
doSomething() ...
这种方法可以很容易分辨出错误检测、错误通知和正常的程序逻辑
反射常用示例
type Child struct {
Name string
Grade int
Handsome bool
}
type Adult struct {
ID string `qson:"Name"`
Occupation string
Handsome bool
}
// 如果输入参数 i 是 Slice,元素是结构体,有一个字段名为 `Handsome`,
// 并且有一个字段的 tag 或者字段名是 `Name` ,
// 如果该 `Name` 字段的值是 `qcrao`,
// 就把结构体中名为 `Handsome` 的字段值设置为 true。
func handsome(i interface{}) {
// 获取 i 的反射变量 Value
v := reflect.ValueOf(i)
// 确定 v 是一个 Slice
if v.Kind() != reflect.Slice {
return
}
// 确定 v 是的元素为结构体
if e := v.Type().Elem(); e.Kind() != reflect.Struct {
return
}
// 确定结构体的字段名含有 "ID" 或者 json tag 标签为 `name`
// 确定结构体的字段名 "Handsome"
st := v.Type().Elem()
// 寻找字段名为 Name 或者 tag 的值为 Name 的字段
foundName := false
for i := 0; i < st.NumField(); i++ {
f := st.Field(i)
tag := f.Tag.Get("qson")
if (tag == "Name" || f.Name == "Name") && f.Type.Kind() == reflect.String {
foundName = true
break
}
}
if !foundName {
return
}
if niceField, foundHandsome := st.FieldByName("Handsome"); foundHandsome == false || niceField.Type.Kind() != reflect.Bool {
return
}
// 设置名字为 "qcrao" 的对象的 "Handsome" 字段为 true
for i := 0; i < v.Len(); i++ {
e := v.Index(i)
handsome := e.FieldByName("Handsome")
// 寻找字段名为 Name 或者 tag 的值为 Name 的字段
var name reflect.Value
for j := 0; j < st.NumField(); j++ {
f := st.Field(j)
tag := f.Tag.Get("qson")
if tag == "Name" || f.Name == "Name" {
name = v.Index(i).Field(j)
}
}
if name.String() == "qcrao" {
handsome.SetBool(true)
}
}
}
func main() {
children := []Child{
{Name: "Ava", Grade: 3, Handsome: true},
{Name: "qcrao", Grade: 6, Handsome: false},
}
adults := []Adult{
{ID: "Steve", Occupation: "Clerk", Handsome: true},
{ID: "qcrao", Occupation: "Go Programmer", Handsome: false},
}
fmt.Printf("adults before handsome: %v\n", adults)
handsome(adults)
fmt.Printf("adults after handsome: %v\n", adults)
fmt.Println("-------------")
fmt.Printf("children before handsome: %v\n", children)
handsome(children)
fmt.Printf("children after handsome: %v\n", children)
}
代码运行结果:
adults before handsome: [{Steve Clerk true} {qcrao Go Programmer false}]
adults after handsome: [{Steve Clerk true} {qcrao Go Programmer true}]
-------------
children before handsome: [{Ava 3 true} {qcrao 6 false}]
children after handsome: [{Ava 3 true} {qcrao 6 true}]
代码主要做的事情是:找出传入的参数为 Slice,并且 Slice 的元素为结构体,如果其中有一个字段名是 Name 或者是 标签名称为 Name,并且还有一个字段名是 Handsome 的情形。如果找到,并且字段名称为 Name 的实际值是 qcrao 的话,就把另一个字段 Handsome 的值置为 true。
程序并不关心传入的结构体到底是什么,只要它的字段名包含 Name 和 Handsome,都是 handsome 函数要工作的对象。
注意一点,Adult 结构体的标签 qson:"Name",中间是没有空格的,否则 Tag.Get("qson") 识别不出来。
写单测相关
构造带 body 的 http Response
{Values: gomonkey.Params{&http.Response{Body: io.NopCloser(strings.NewReader(""))}, nil}},
构造 http ResponseWriter
w := new(httptest.ResponseRecorder)
time 的时区设置
对于需要使用时间的场景,默认情况下会从当前系统中找时区信息,如果需要手动设置时区,最好所有的解析和格式化的操作都指定时区信息:
t,_ := time.ParseInLocation(layout,inputTime,location)
dateTime := time.Unix(t.Unix(),0).In(loacation).Format(layout)
常用的 Parse 方法在解析时间模板时会使用读取参数中的时区信息,没有的话就采用 UTC 时间,此时如果再调用 time.Unix(t.Unix(),0).In(loacation).Format(layout) ,生成的时间会加上时区时间,所以最好采用上述方式,在解析的时候就把时区信息通过 ParseInLocation 传入,避免时区问题。
空结构体的应用
在Go中,每一个基本类型都有对应的字节宽度,声明一个变量后即使不赋值,也需要占用一定的内存。但是对于空结构体来说,其字节宽度为0,因此可以用在某些场景下作为占位符而不占用存储空间。其使用场景主要有:
- 实现方法接收者
- 实现集合类型
- 实现空通道
实现方法接收者
在某些业务场景下,需要将方法组合起来,代表一个分组,便于后续的拓展和维护。这时候就会使用空结构体,即节省内存,也便于未来针对该类型进行公共字段等的增加。
type T struct{}
func (s *T) Call() {
fmt.Println("脑子进煎鱼了")
}
func main() {
var s T
s.Call()
}
在该场景下,使用空结构体从多维度来考量是最合适的,易拓展,省空间,最结构化。
实现集合类型
由于 Go 中并没有提供集合(Set)的相关支持,当需要自己实现时,可以使用 map 来替代,对于其 value,使用空结构作为占位符,不会额外增加不必要的内存开销:
type Set map[string]struct{}
func (s Set) Append(k string) {
s[k] = struct{}{}
}
func (s Set) Remove(k string) {
delete(s, k)
}
func (s Set) Exist(k string) bool {
_, ok := s[k]
return ok
}
func main() {
set := Set{}
set.Append("煎鱼")
set.Append("咸鱼")
set.Append("蒸鱼")
set.Remove("煎鱼")
fmt.Println(set.Exist("煎鱼"))
}
实现空通道
在 Go channel 的使用场景中,常常会遇到通知型 channel,其不需要发送任何数据,只要用于协调 Goroutine 的运行,用于流转各类状态或是控制并发情况。
func main() {
ch := make(chan struct{})
go func() {
time.Sleep(1 * time.Second)
close(ch)
}()
fmt.Println("脑子好像进...")
<-ch
fmt.Println("煎鱼了!")
}
该程序会先输出 ”脑子好像进…“ 后,再睡眠一段时间再输出 “煎鱼了!”,达到间断控制 channel 的效果。
由于该 channel 使用的是空结构体,因此也不会带来额外的内存开销。
go 中常用的包
regexp包
主要用于正则匹配。
如果是简单模式,使用 Match 方法便可:
ok, _ := regexp.Match(pat, []byte(searchIn))
变量 ok 将返回 true 或者 false, 也可以使用 MatchString:
ok, _ := regexp.MatchString(pat, searchIn)
更多方法中,必须先将正则通过 Compile 方法返回一个 Regexp 对象。然后我们将掌握一些匹配,查找,替换相关的功能。如下:
package main
import (
"fmt"
"regexp"
"strconv"
)
func main() {
//目标字符串
searchIn := "John: 2578.34 William: 4567.23 Steve: 5632.18"
pat := "[0-9]+.[0-9]+" //正则
f := func(s string) string{
v, _ := strconv.ParseFloat(s, 32)
return strconv.FormatFloat(v * 2, 'f', 2, 32)
}
if ok, _ := regexp.Match(pat, []byte(searchIn)); ok {
fmt.Println("Match Found!")
}
re, _ := regexp.Compile(pat)
//将匹配到的部分替换为"##.#"
str := re.ReplaceAllString(searchIn, "##.#")
fmt.Println(str)
//参数为函数时
str2 := re.ReplaceAllStringFunc(searchIn, f)
fmt.Println(str2)
}
结果如下:
Match Found!
John: ##.# William: ##.# Steve: ##.#
John: 5156.68 William: 9134.46 Steve: 11264.36
sync 包
sync.Mutex 是一个互斥锁,它的作用是守护在临界区入口来确保同一时间只能有一个线程进入临界区。
假设 info 是一个需要上锁的放在共享内存中的变量。通过包含 Mutex 来实现的一个典型例子如下:
import "sync"
type Info struct {
mu sync.Mutex
// ... other fields, e.g.: Str string
}
如果一个函数想要改变这个变量可以这样写:
func Update(info *Info) {
info.mu.Lock()
// critical section:
info.Str = // new value
// end critical section
info.mu.Unlock()
}
还有一个很有用的例子是通过 Mutex 来实现一个可以上锁的共享缓冲器:
type SyncedBuffer struct {
lock sync.Mutex
buffer bytes.Buffer
}
在 sync 包中还有一个 RWMutex 锁:他能通过 RLock() 来允许同一时间多个线程对变量进行读操作,但是只能一个线程进行写操作。如果使用 Lock() 将和普通的 Mutex 作用相同。包中还有一个方便的 Once 类型变量的方法 once.Do(call),这个方法确保被调用函数只能被调用一次。
精密计算和big包
对于整数的高精度计算 Go 语言中提供了 big 包。其中包含了 math 包:有用来表示大整数的 big.Int 和表示大有理数的 big.Rat 类型(可以表示为 2/5 或 3.1416 这样的分数,而不是无理数或 π)。这些类型可以实现任意位类型的数字,只要内存足够大。缺点是更大的内存和处理开销使它们使用起来要比内置的数字类型慢很多。
大的整型数字是通过 big.NewInt(n) 来构造的,其中 n 为 int64 类型整数。而大有理数是通过 big.NewRat(N,D) 方法构造。N(分子)和 D(分母)都是 int64 型整数。因为 Go 语言不支持运算符重载,所以所有大数字类型都有像是 Add() 和 Mul() 这样的方法。它们作用于作为reciver 的整数和有理数,大多数情况下它们修改 receiver 并以 receiver 作为返回结果。因为没有必要创建 big.Int 类型的临时变量来存放中间结果,所以这样的运算可通过内存链式存储。
// big.go
package main
import (
"fmt"
"math"
"math/big"
)
func main() {
// Here are some calculations with bigInts:
im := big.NewInt(math.MaxInt64)
in := im
io := big.NewInt(1956)
ip := big.NewInt(1)
ip.Mul(im, in).Add(ip, im).Div(ip, io)
fmt.Printf("Big Int: %v\n", ip)
// Here are some calculations with bigRat:
rm := big.NewRat(math.MaxInt64, 1956)
rn := big.NewRat(-1956, math.MaxInt64)
ro := big.NewRat(19, 56)
rp := big.NewRat(1111, 2222)
rq := big.NewRat(1, 1)
rq.Mul(rm, rn).Add(rq, ro).Mul(rq, rp)
fmt.Printf("Big Rat: %v\n", rq)
}
/* Output:
Big Int: 43492122561469640008497075573153004
Big Rat: -37/112
*/
结果如下:
Big Int: 43492122561469640008497075573153004
Big Rat: -37/112
常见错误
短变量声明导致变量覆盖
var remember bool = false
if something {
remember := true //错误
}
// 使用remember
在此代码段中,remember 变量永远不会在 if 语句外面变成 true,如果 something 为 true,由于使用了短声明 :=,if 语句内部的新变量 remember 将覆盖外面的 remember 变量,并且该变量的值为 true,但是在 if 语句外面,变量 remember 的值变成了 false,所以正确的写法应该是:
if something {
remember = true
}
此类错误也容易在 for 循环中出现,尤其当函数返回一个具名变量时难于察觉,例如以下的代码段:
func shadow() (err error) {
x, err := check1() // x是新创建变量,err是被赋值
if err != nil {
return // 正确返回err
}
if y, err := check2(x); err != nil { // y和if语句中err被创建
return // if语句中的err被外面的err覆盖,所以错误的返回nil!
} else {
fmt.Println(y)
}
return
}
不要对需要 append 的空切片使用 make 声明变量
当初始化一个数组的时候,如果需要调用 append 操作往空变量里塞数据,不要在声明变量的时候,使用带 len 声明的 make(除非 len = 0),因为这会导致 append 操作直接往数组后面添加,最后的结果是数组前面的都是空,append 往后添加数据:
func main() {
attr1 := make([]string, 4)
fmt.Println("len0:", len(attr1)) //len0: 4
attr1 = append(attr1, "hello")
fmt.Println("len1:", len(attr1)) //len1: 5
attr1 = append(attr1, "hello")
fmt.Println("len2:", len(attr1)) //len2: 6
attr1 = append(attr1, "hello")
fmt.Println("len3:", len(attr1)) //len3: 7
var attr2 []string
attr2 = append(attr2, "hello")
attr2 = append(attr2, "hello")
attr2 = append(attr2, "hello")
fmt.Println(len(attr2)) // 3
}
可以直接声明一个变量,或者 make 的 len 参数为 0,append 会在追加的时候自己进行初始化容量的操作。
误用 defer 关闭一个文件
如果在一个 for 循环内部处理一系列文件,需要使用 defer 确保文件在处理完毕后被关闭,例如:
for _, file := range files {
if f, err = os.Open(file); err != nil {
return
}
// 这是错误的方式,当循环结束时文件没有关闭,要等到整个方法执行完了才会调用
defer f.Close()
// 对文件进行操作
f.Process(data)
}
但是在循环结尾处的 defer 没有执行,所以文件一直没有关闭!垃圾回收机制可能会自动关闭文件,但是这会产生一个错误,更好的做法是:
for _, file := range files {
if f, err = os.Open(file); err != nil {
return
}
// 对文件进行操作
f.Process(data)
// 关闭文件
f.Close()
}
defer 仅在函数返回时才会执行,在循环的结尾或其他一些有限范围的代码内不会执行。
不需要将一个指向切片的指针传递给函数
切片实际是一个指向潜在数组的指针。我们常常需要把切片作为一个参数传递给函数是因为:实际就是传递一个指向变量的指针,在函数内可以改变这个变量,而不是传递数据的拷贝。
因此应该这样做:
func findBiggest( listOfNumbers []int ) int {}
而不是:
func findBiggest( listOfNumbers *[]int ) int {}
当切片作为参数传递时,切记不要解引用切片。
append 数组时,忽略对底层数组的修改
append 操作时,有如下需要注意的事项:
- slice本身并非指针,append追加元素后,意味着底层数组数据(或数组)、len、cap会发生变化,因此append后需要返回新的slice。
- append在追加元素时,当前cap足够容纳元素,则直接存入数据,否则需要扩容后重新创建新的底层数组,拷贝原数组元素后,再存入追加元素。
- cap的扩容意味着内存的重新分配,数据的拷贝等操作,为了提高append的效率,若是能预估cap的大小的话,尽量提前声明cap,避免后期的扩容操作。
看下面的例子:
func main() {
var ret [][]int
var val = make([]int, 0, 100)
fmt.Printf("%p\n", val)
deal(&ret, val)
fmt.Println(ret)
}
func deal(ret *[][]int, val []int) {
fmt.Printf("%p\n", val) // 此时与外面的 val 指定同一个地址(都还未初始化)
val = append(val, 1)
val = append(val, 1)
val = append(val, 1)
fmt.Printf("%p\n", val) // 此时由于底层数组扩容,地址发生改变,跟原来地址不一样了
*ret = append(*ret, val)
//val[2] = 2
// 此时由于为发生扩容,以及修改的是范围里的值,修改会影响原来的
val = val[:len(val)-1]
val = append(val, 2)
fmt.Printf("%p\n", val)
// 继续 append,发生扩容,不会影响原来的
val = append(val, 4, 5, 6, 7, 8)
val = val[:3]
fmt.Printf("%p\n", val)
}
不要将切片作为入参在函数内 append
观察下面的代码:
package main
import "fmt"
func main() {
arr := make([]int, 3, 4)
arr[0] = 0
arr[1] = 1
arr[2] = 2
fmt.Printf("main before: len: %d cap:%d data:%+v\n", len(arr), cap(arr), arr)
ap1(arr)
fmt.Printf("main ap1 after: len: %d cap:%d data:%+v\n\n", len(arr), cap(arr), arr)
}
func ap1(arr []int) {
fmt.Printf("ap1 before: len: %d cap:%d data:%+v\n", len(arr), cap(arr), arr)
arr[0] = 11
arr = append(arr, 111)
fmt.Printf("ap1 after: len: %d cap:%d data:%+v\n", len(arr), cap(arr), arr)
}
输出:
main before: len: 3 cap:4 data:[0 1 2]
ap1 before: len: 3 cap:4 data:[0 1 2]
ap1 after: len: 4 cap:4 data:[11 1 2 111]
main ap1 after: len: 3 cap:4 data:[11 1 2]
可以发现,函数内 append 之后,外部实参切片的值没改变,但到底是没改变,还是 “看不到” 呢?
首先,slice 是值传递,但是 slice 本身是一个结构体,包含一个指针,指向底层数组,将 slice 按值传递给函数,在函数内对其修改,影响将会传递到函数外,因为底层的数组被修改了,但是,slice 只能感知到 len 范围内的内容,之外的感知不到的。
由于值传递,外层的 slice 的 len 变量实际上并没有改变,此时还是只能读取到前 3 个值。
不要使用指针指向接口类型
在下面的程序中:nexter 是一个接口类型,并且定义了一个 next() 方法读取下一字节。函数 nextFew1 将 nexter 接口作为参数并读取接下来的 num 个字节,并返回一个切片:这是正确做法。但是 nextFew2 使用一个指向 nexter 接口类型的指针作为参数传递给函数:当使用 next() 函数时,系统会给出一个编译错误:
n.next undefined (type \*nexter has no field or method next) (n.next 未定义(*nexter 类型没有 next 成员或 next 方法))
package main
import (
“fmt”
)
type nexter interface {
next() byte
}
func nextFew1(n nexter, num int) []byte {
var b []byte
for i:=0; i < num; i++ {
b[i] = n.next()
}
return b
}
func nextFew2(n *nexter, num int) []byte {
var b []byte
for i:=0; i < num; i++ {
b[i] = n.next() // 编译错误:n.next未定义(*nexter类型没有next成员或next方法)
}
return b
}
func main() {
fmt.Println("Hello World!")
}
永远不要使用一个指针指向一个接口类型,因为它已经是一个指针。
注意循环中的协程使用
对于下面的代码:
package main
import (
"fmt"
"time"
)
var values = [5]int{10, 11, 12, 13, 14}
func main() {
// 版本A:
for ix := range values { // ix是索引值
func() {
fmt.Print(ix, " ")
}() // 调用闭包打印每个索引值
}
fmt.Println()
// 版本B: 和A版本类似,但是通过调用闭包作为一个协程
for ix := range values {
go func() {
fmt.Print(ix, " ")
}()
}
fmt.Println()
time.Sleep(5e9)
// 版本C: 正确的处理方式
for ix := range values {
go func(ix interface{}) {
fmt.Print(ix, " ")
}(ix)
}
fmt.Println()
time.Sleep(5e9)
// 版本C的另外一种正确的处理方式
//for ix := range values {
// ix := ix
// go func() {
// fmt.Print(ix, " ")
// }()
//}
//fmt.Println()
//time.Sleep(5e9)
// 版本D: 输出值:
for ix := range values {
val := values[ix]
go func() {
fmt.Print(val, " ")
}()
}
time.Sleep(1e9)
}
输出:
0 1 2 3 4
4 4 4 4 4
1 0 3 4 2
10 11 12 13 14
版本 A 调用闭包 5 次打印每个索引值,版本 B 也做相同的事,但是通过协程调用每个闭包。按理说这将执行得更快,因为闭包是并发执行的。
如果阻塞足够多的时间,让所有协程执行完毕,版本 B 的输出是:4 4 4 4 4。在版本 B 的循环中,ix 变量实际是一个单变量,表示每个数组元素的索引值。因为这些闭包都只绑定到一个变量,这是一个比较好的方式,当运行这段代码时,将看见每次循环都打印最后一个索引值 4,而不是每个元素的索引值。因为协程可能在循环结束后还没有开始执行,而此时 ix 值是 4。
版本 C 的循环写法才是正确的:调用每个闭包是将 ix 作为参数传递给闭包。ix 在每次循环时都被重新赋值,并将每个协程的 ix 放置在栈中,所以当协程最终被执行时,每个索引值对协程都是可用的。注意这里的输出可能是 0 2 1 3 4 或者 0 3 1 2 4 或者其他类似的序列,这主要取决于每个协程何时开始被执行。
版本 C 的另一个处理方法,ix := ix 可能看起来有点奇怪,但它完全有效。因为处于循环中意味着处于另一个作用域内,所以 ix := ix 相当于创建了另一个名为 ix 的变量实例。
用 大括号
{}包围的一个代码块相当于一个新的作用域,可以定义同名变量
在版本 D 中,能够正确输出这个数组的值,因为版本 D 中的变量声明是在循环体内部,所以在每次循环时,这些变量相互之间是不共享的,所以这些变量可以单独的被每个闭包使用。
不要在生产环境使用默认的 HTTP Client
Go 默认的 HTTP 客户端没有指定请求超时时间,允许服务劫持 goroutine。当请求外部服务时,请始终使用自定义的 http.Client。
Go 的 HTTP 包使用 Client 结构体来管理 HTTP(S) 通信的内部过程。Clients 是并发安全的对象,包含配置、管理 TCP 状态、处理 cookies 等。当使用 http.Get(url) 时,就会调用 http.DefaultClient,走的是 HTTP 默认配置,声明如下:
var DefaultClient = &Client{}
除其他配置项外,http.Client 有一个超时时间的配置,当请求时间超过这个数值时,请求就会自动断开。该数值默认值是 0,即没有超时时间。该默认值对于 HTTP 包来说挺合理的,同时这也是一个容易让人掉进去的坑,如果请求的对象宕机或者因为其他原因一直没有响应,就会导致发起请求的 groutine 挂起,只要发生故障的服务器没有恢复,进程就会一直挂着。因为进行 API 调用是为了服务用户请求,所以这也会导致服务用户请求的 goroutine 也挂起。一旦有足够的人发起这个 http 请求,很有可能就因为系统资源达到了极限导致应用挂掉。
解决办法
解决这个问题的办法就是使用 http.Client 时定义一个合理的超时时间,比如下面这样的:
var netClient = &http.Client{
Timeout: time.Second * 10,
}
response, _ := netClient.Get(url)
设置了 10s 的超时时间,如果超时 Get() 将会返回错误:
&httpError{
err: err.Error() + " (Client.Timeout exceeded while awaiting headers)",
timeout: true,
}
如果需要对请求生命周期进行更细粒度的控制,还可以另外指定自定义 net.Transport 和 net.Dialer。
Transport 结构体用来管理底层 TCP 连接,Dialer 是用来管理连接建立的结构体。Go 的 net 包使用默认的 Transport 和 Dialer。下面是一个自定义的例子:
var netTransport = &http.Transport{
Dial: (&net.Dialer{
Timeout: 5 * time.Second,
}).Dial,
TLSHandshakeTimeout: 5 * time.Second,
}
var netClient = &http.Client{
Timeout: time.Second * 10,
Transport: netTransport,
}
response, _ := netClient.Get(url)
上面代码设置了 TCP 拨号时间、TLS 握手时间和请求超时时间。如果有需要还可以设置其他选项,例如 keep-alive 超时时间。
总结
Go 语言的 net/http 包是经过深思熟虑的产物,可以非常便捷地用于 HTTP(S) 通信。然而,缺少请求超时时间是一个非常容易掉进去的坑,因为这个包提供了很多诸如 http.Get(url) 等便捷的方法。请求远程服务时不设置超时时间会使应用程序依赖于该服务,如果远程服务发生故障或者有恶意程序,请求将会永远挂起,从而有可能使系统资源耗尽导致宕机。
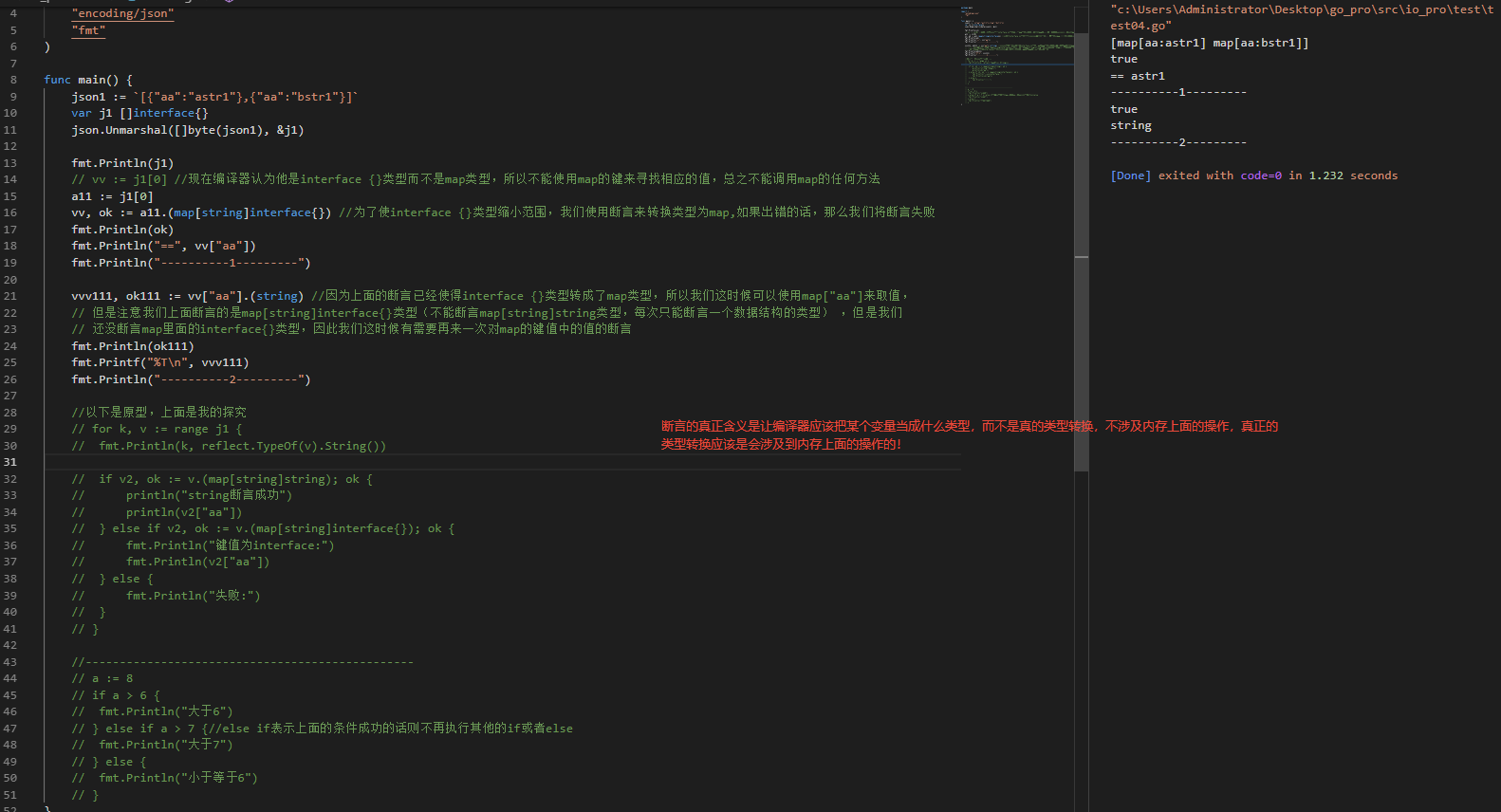
map的key,value不能同时断言
对于一个类型为 interface 的变量,当其实际的值为一个 map 值,例如 map[string]string,此时如果要对该变量进行类型断言,不可以直接使用如下格式:
// v:{"aa":"vv"}
var v interface{}
v2,ok := v.(map[string]string) // ok==false
对于 map 的 key 和 value 进行断言时,一次只能断言一个数据结构的类型,因此需要分开进行断言:
v2,ok := v.(map[string]interface{}) // ok==true
v3,ok := v2["aa"].(string) // ok==true
断言的真正含义是让编译器应该把某个变量当成什么类型,而不是真的类型转换,不涉及内存上面的操作,真正的类型转换应该是会涉及内存上面的操作的。
具体的实例见下图:
未知枚举值
type Status uint32
const (
StatusOpen Status = iota
StatusClosed
StatusUnknown
)
在这里,我们使用 iota 创建了一个枚举:
StatusOpen = 0
StatusClosed = 1
StatusUnknown = 2
现在,假设这个 Status 类型是 JSON 请求的一部分,将被 marshalled/unmarshalled。
设计了以下结构:
type Request struct {
ID int `json:"Id"`
Timestamp int `json:"Timestamp"`
Status Status `json:"Status"`
}
然后,接收这样的请求:
{
"Id": 1234,
"Timestamp": 1563362390,
"Status": 0
}
这样子不会有任何问题,状态会被unmarshalled为StatusOpen。
然而,让我们以另一个未设置状态值的请求为例:
{
"Id": 1235,
"Timestamp": 1563362390
}
在这种情况下,请求结构的 Status 字段将初始化为它的零值(对于uint32类型:0),因此结果将是 StatusOpen 而不是 StatusUnknown。所以在这种场景下,最好的做法是将枚举的未知值设置为 0:
type Status uint32
const (
StatusUnknown Status = iota
StatusOpen
StatusClosed
)
如果状态不是 JSON 请求的一部分,它将被初始化为StatusUnknown,这才符合期望。
基准测试自动优化
基准测试主要就是测试代码整体的吞吐量,性能等,如果编写的测试代码由于被编译器所优化,会导致测试结果不准确。
例如下面的函数:
func clear(n uint64, i, j uint8) uint64 {
return (math.MaxUint64<<j | ((1 << i) - 1)) & n
}
此函数清除给定范围内的位。为了测试它,可能如下这样做:
func BenchmarkWrong(b *testing.B) {
for i := 0; i < b.N; i++ {
clear(1221892080809121, 10, 63)
}
}
在这个基准测试中,clear 不调用任何其他函数,没有副作用。所以编译器将会把 clear 优化成内联函数。一旦内联,将会导致不准确的测试结果。
一个解决方案是将函数结果设置为全局变量,如下所示:
var result uint64
func BenchmarkCorrect(b *testing.B) {
var r uint64
for i := 0; i < b.N; i++ {
r = clear(1221892080809121, 10, 63)
}
result = r
}
如此一来,编译器将不知道clear是否会产生副作用。
因此,不会将clear优化成内联函数。
指针迁移到堆上导致指针传递比按值传递更慢
在函数调用中,按值传递的变量将创建该变量的副本,而通过指针传递只会传递该变量的内存地址。
那么,指针传递会比按值传递更快吗?
对于下面这里例子:
package main
import (
"encoding/json"
"testing"
)
type foo struct {
ID string `json:"_id"`
Index int `json:"index"`
GUID string `json:"guid"`
IsActive bool `json:"isActive"`
Balance string `json:"balance"`
Picture string `json:"picture"`
Age int `json:"age"`
EyeColor string `json:"eyeColor"`
Name string `json:"name"`
Gender string `json:"gender"`
Company string `json:"company"`
Email string `json:"email"`
Phone string `json:"phone"`
Address string `json:"address"`
About string `json:"about"`
Registered string `json:"registered"`
Latitude float64 `json:"latitude"`
Longitude float64 `json:"longitude"`
Greeting string `json:"greeting"`
FavoriteFruit string `json:"favoriteFruit"`
}
type bar struct {
ID string
Index int
GUID string
IsActive bool
Balance string
Picture string
Age int
EyeColor string
Name string
Gender string
Company string
Email string
Phone string
Address string
About string
Registered string
Latitude float64
Longitude float64
Greeting string
FavoriteFruit string
}
var input foo
func init() {
err := json.Unmarshal([]byte(`{
"_id": "5d2f4fcf76c35513af00d47e",
"index": 1,
"guid": "ed687a14-590b-4d81-b0cb-ddaa857874ee",
"isActive": true,
"balance": "$3,837.19",
"picture": "https://placehold.it/32x32",
"age": 28,
"eyeColor": "green",
"name": "Rochelle Espinoza",
"gender": "female",
"company": "PARLEYNET",
"email": "rochelleespinoza@parleynet.com",
"phone": "+1 (969) 445-3766",
"address": "956 Little Street, Jugtown, District Of Columbia, 6396",
"about": "Excepteur exercitation labore ut cupidatat laboris mollit ad qui minim aliquip nostrud anim adipisicing est. Nisi sunt duis occaecat aliquip est irure Lorem irure nulla tempor sit sunt. Eiusmod laboris ex est velit minim ut cillum sunt laborum labore ad sunt.\r\n",
"registered": "2016-03-20T12:07:25 -00:00",
"latitude": 61.471517,
"longitude": 54.01596,
"greeting": "Hello, Rochelle Espinoza!You have 9 unread messages.",
"favoriteFruit": "banana"
}`), &input)
if err != nil {
panic(err)
}
}
func byPointer(in *foo) *bar {
return &bar{
ID: in.ID,
Address: in.Address,
Email: in.Email,
Index: in.Index,
Name: in.Name,
About: in.About,
Age: in.Age,
Balance: in.Balance,
Company: in.Company,
EyeColor: in.EyeColor,
FavoriteFruit: in.FavoriteFruit,
Gender: in.Gender,
Greeting: in.Greeting,
GUID: in.GUID,
IsActive: in.IsActive,
Latitude: in.Latitude,
Longitude: in.Longitude,
Phone: in.Phone,
Picture: in.Picture,
Registered: in.Registered,
}
}
func byValue(in foo) bar {
return bar{
ID: in.ID,
Address: in.Address,
Email: in.Email,
Index: in.Index,
Name: in.Name,
About: in.About,
Age: in.Age,
Balance: in.Balance,
Company: in.Company,
EyeColor: in.EyeColor,
FavoriteFruit: in.FavoriteFruit,
Gender: in.Gender,
Greeting: in.Greeting,
GUID: in.GUID,
IsActive: in.IsActive,
Latitude: in.Latitude,
Longitude: in.Longitude,
Phone: in.Phone,
Picture: in.Picture,
Registered: in.Registered,
}
}
var pointerResult *bar
var valueResult bar
func BenchmarkByPointer(b *testing.B) {
var r *bar
b.ResetTimer()
for i := 0; i < b.N; i++ {
r = byPointer(&input)
}
pointerResult = r
}
func BenchmarkByValue(b *testing.B) {
var r bar
b.ResetTimer()
for i := 0; i < b.N; i++ {
r = byValue(input)
}
valueResult = r
}
通过基准测试分别测试了按值传递和指针传递的速度。
结果显示,按值传递比指针传递快3-4倍以上:
goos: darwin
goarch: amd64
cpu: Intel(R) Core(TM) i5-7360U CPU @ 2.30GHz
BenchmarkByPointer
BenchmarkByPointer-4 11838573 91.03 ns/op
BenchmarkByValue
BenchmarkByValue-4 38128300 31.21 ns/op
PASS
测试结果与 Go 中如何管理内存有关,主要原因如下:
下面是来自 Go 语言圣经的介绍:
一个 goroutine 会以一个很小的栈开始其生命周期,一般只需要 2KB。
一个 goroutine 的栈,和操作系统线程一样,会保存其活跃或挂起的函数调用的本地变量,但是和 OS 线程不太一样的是,一个 goroutine 的栈大小并不是固定的;栈的大小会根据需要动态地伸缩。
而 goroutine 的栈的最大值有 1GB,比传统的固定大小的线程栈要大得多,尽管一般情况下,大多 goroutine 都不需要这么大的栈。
通俗的理解:
- 栈:每个 Goruntine 开始的时候都有独立的栈来存储数据。(Goruntine 分为主 Goruntine 和其他 Goruntine,差异就在于起始栈的大小)
- 堆: 而需要被多个 Goruntine 共享的数据,存储在堆上面。
众所周知,可以在堆或栈上分配变量。
- 栈储存当前
Goroutine的正在使用的变量(可理解为局部变量)。一旦函数返回,变量就会从栈中弹出。 - 堆储存共享变量(全局变量等)。
看一个简单的例子,返回单一的值:
func getFooValue() foo {
var result foo
// Do something
return result
}
当调用函数时,result 变量会在当前 Goruntine 栈创建,当函数返回时,会传递给接收者一份值的拷贝。而 result 变量自身会从当前 Goruntine 栈出栈。
虽然它仍然存在于内存中,但它不能再被访问。并且还有可能被其他数据变量所擦除。
现在,在看一个返回指针的例子:
func getFooPointer() *foo {
var result foo
// Do something
return &result
}
当调用函数时,result 变量会在当前 Goruntine 栈创建,当函数返回时,会传递给接收者一个指针(变量地址的副本)。如果 result 变量从当前 Goruntine 栈出栈,则接收者将无法再访问它。(此情况称为“内存逃逸”)
在这个场景中,Go 编译器将把 result 变量转义到一个可以共享变量的地方:堆。
不过,传递指针是另一种情况。例如:
func main() {
p := &foo{}
f(p)
}
因为我们在同一个 Goroutine 中调用f,所以 p 变量不需要转义。它只是被推送到堆栈,子功能可以访问它。(不需要其他 Goruntine 共享的变量就存储在栈上即可)
比如,io.Reader 中的 Read 方法签名,接收切片参数,将内容读取到切片中,返回读取的字节数。而不是返回读取后的切片。(如果返回切片,会将切片转义到堆中。)
type Reader interface {
Read(p []byte) (n int, err error)
}
为什么栈如此之快? 主要有两个原因:
- **堆栈不需要垃圾收集器。**就像我们说的,变量一旦创建就会被入栈,一旦函数返回就会从出栈。不需要一个复杂的进程来回收未使用的变量。
- **储存变量不需要考虑同步。**栈属于一个 Goroutine,因此与在堆上存储变量相比,存储变量不需要同步。
总之,当创建一个函数时,默认行为应该是使用值而不是指针。只有在我们想要共享变量时才应使用指针。
如果遇到性能问题,可以使用 go build -gcflags "-m -m" 命令,来显示编译器将变量转义到堆的具体操作。
再次重申,对于大多数日常用例来说,值传递是最合适的。
break 逻辑不符合预期
for {
switch f() {
case true:
break
case false:
// Do something
}
}
如果 f 返回 true,将调用 break 语句。然而,将会 break 出 switch 语句,而不是 for 循环。
同样的问题:
for {
select {
case <-ch:
// Do something
case <-ctx.Done():
break
}
}
break 与 select 语句有关,与 for 循环无关。
break 出 for/switch 或 for/select 的一种解决方案是使用带标签的 break,如下所示:
loop:
for {
select {
case <-ch:
// Do something
case <-ctx.Done():
break loop
}
}
缺失上下文的错误
Go 在错误处理方面仍然有待提高,以至于现在错误处理是 Go2 中最令人期待的需求。
当前的标准库(在 Go 1.13 之前)只提供 error 的构造函数,自然而然就会缺失其他信息。
看一下 pkg/errors 库中错误处理的思想:
An error should be handled only once. Logging an error is handling an error. So an error should either be logged or propagated.
错误应该只处理一次。记录 log 错误就是在处理错误。所以,错误应该记录或者传播
对于当前的标准库,很难做到这一点,因为我们希望向错误中添加一些上下文信息,使其具有层次结构。
例如: 所期望的REST调用导致数据库问题的示例:
COPYunable to server HTTP POST request for customer 1234
|_ unable to insert customer contract abcd
|_ unable to commit transaction
如果我们使用 pkg/errors,可以这样做:
COPYfunc postHandler(customer Customer) Status {
err := insert(customer.Contract)
if err != nil {
log.WithError(err).Errorf("unable to server HTTP POST request for customer %s", customer.ID)
return Status{ok: false}
}
return Status{ok: true}
}
func insert(contract Contract) error {
err := dbQuery(contract)
if err != nil {
return errors.Wrapf(err, "unable to insert customer contract %s", contract.ID)
}
return nil
}
func dbQuery(contract Contract) error {
// Do something then fail
return errors.New("unable to commit transaction")
}
如果不是由外部库返回的初始 error 可以使用 error.New 创建。中间层 insert 对此错误添加更多上下文信息。最终通过 log 错误来处理错误。每个级别要么返回错误,要么处理错误。
我们可能还想检查错误原因来判读是否应该重试。假设我们有一个来自外部库的 db 包来处理数据库访问。 该库可能会返回一个名为 db.DBError 的临时错误。要确定是否需要重试,我们必须检查错误原因:
使用 pkg/errors 中提供的 errors.Cause 可以判断错误原因。
COPYfunc postHandler(customer Customer) Status {
err := insert(customer.Contract)
if err != nil {
switch errors.Cause(err).(type) {
default:
log.WithError(err).Errorf("unable to server HTTP POST request for customer %s", customer.ID)
return Status{ok: false}
case *db.DBError:
return retry(customer)
}
}
return Status{ok: true}
}
func insert(contract Contract) error {
err := db.dbQuery(contract)
if err != nil {
return errors.Wrapf(err, "unable to insert customer contract %s", contract.ID)
}
return nil
}
一个常见错误是部分使用 pkg/errors。 例如,通过这种方式检查错误:
COPYswitch err.(type) {
default:
log.WithError(err).Errorf("unable to server HTTP POST request for customer %s", customer.ID)
return Status{ok: false}
case *db.DBError:
return retry(customer)
}
在此示例中,如果 db.DBError 被 wrapped,它将永远不会执行 retry。
传递文件名给函数
假设实现一个函数来计算文件中的空行数。最初的实现是这样的:
COPYfunc count(filename string) (int, error) {
file, err := os.Open(filename)
if err != nil {
return 0, errors.Wrapf(err, "unable to open %s", filename)
}
defer file.Close()
scanner := bufio.NewScanner(file)
count := 0
for scanner.Scan() {
if scanner.Text() == "" {
count++
}
}
return count, nil
}
filename 作为给定的参数,然后打开该文件,再实现读空白行的逻辑,嗯,没有问题。
假设希望在此函数之上实现单元测试,并使用普通文件,空文件,具有不同编码类型的文件等进行测试。代码很容易变得非常难以维护。
此外,如果我们想对于 HTTP Body 实现相同的逻辑,将不得不为此创建另一个函数。
Go 设计了两个很棒的接口:io.Reader 和 io.Writer (常见 IO 命令行,文件,网络等)
所以可以传递一个抽象数据源的io.Reader,而不是传递文件名。
仔细想一想统计的只是文件吗?一个 HTTP 正文?字节缓冲区?
答案并不重要,重要的是无论 Reader 读取的是什么类型的数据,都会使用相同的 Read 方法。
在例子中,甚至可以缓冲输入以逐行读取它(使用 bufio.Reader 及其 ReadLine 方法):
COPYfunc count(reader *bufio.Reader) (int, error) {
count := 0
for {
line, _, err := reader.ReadLine()
if err != nil {
switch err {
default:
return 0, errors.Wrapf(err, "unable to read")
case io.EOF:
return count, nil
}
}
if len(line) == 0 {
count++
}
}
}
打开文件的逻辑现在交给调用 count 方:
COPYfile, err := os.Open(filename)
if err != nil {
return errors.Wrapf(err, "unable to open %s", filename)
}
defer file.Close()
count, err := count(bufio.NewReader(file))
无论数据源如何,都可以调用 count。并且,还将促进单元测试,因为可以从字符串创建一个 bufio.Reader,这大大提高了效率。
COPYcount, err := count(bufio.NewReader(strings.NewReader("input")))
int32 转 string 时,直接使用 string 强转输出为 ASCII 码
对于 int32 类型的变量,转换为 string 时,不能直接 string 强转,应该使用 strconv 包来进行转换:
func main() {
var num int32 = 88
fmt.Println(string(num)) // 输出为 'X'
fmt.Println(strconv.Itoa(int(num))) // 输出为 "88"
}
Go 变量并发赋值的安全性
结构体并发赋值的不安全性
以下代码,在多协程的情况下,并发使用两个不同的值对结构体变量进行赋值:
type Test struct {
X int
Y int
}
func main() {
var g Test
for i := 0; i < 1000000; i++ {
var wg sync.WaitGroup
// 协程 1
wg.Add(1)
go func() {
defer wg.Done()
g = Test{1,2}
}()
// 协程 2
wg.Add(1)
go func(){
defer wg.Done()
g = Test{3,4}
}()
wg.Wait()
// 赋值异常判断
if !((g.X == 1 && g.Y == 2) || (g.X == 3 && g.Y == 4)) {
fmt.Printf("concurrent assignment error, i=%v g=%+v", i, g)
break
}
}
}
运行一次或多次,将出现赋值异常。
concurrent assignment error, i=48714 g={X:1 Y:4}
结构体中有多个字段,协程 1 赋值了字段 X,协程 2 赋值了字段 Y,此时整个结构体既不是协程 1 想要的结果,也不是协程 2 想要的结果。
可见 struct 赋值时,并不是原子操作,各个字段的赋值是独立的,在并发操作的情况下可能会出现异常。
哪些类型并发赋值是安全的
Golang 中数据类型可以分类两大类:基本数据类型和复合数据类型。
基本数据类型有:字节型,布尔型、整型、浮点型、字符型、复数型、字符串。
复合数据类型包括:指针、数组、切片、结构体、字典、通道、函数、接口。
复合数据类又可细分为如下三类: (1)非引用类型:数组、结构体; (2)引用类型:指针、切片、字典、通道、函数; (3)接口。
基本类型的并发赋值
字节型、布尔型、整型、浮点型、字符型(安全)
由于字节型、布尔型、整型、浮点型、字符型的位宽不会超过 64 位,在 64 位的指令集架构中可以由一条机器指令完成,不存在被细分为更小的操作单位,所以这些类型的并发赋值是安全的。
复数型(不安全)
因为复数型分为实部和虚部,两者的赋值是分开进行的,所以复数类型并发赋值是不安全的。
func main() {
var g complex64
for i := 0; i < 1000000; i++ {
var wg sync.WaitGroup
// 协程 1
wg.Add(1)
go func() {
defer wg.Done()
g = complex(1,2)
}()
// 协程 2
wg.Add(1)
go func(){
defer wg.Done()
g = complex(3,4)
}()
wg.Wait()
// 赋值异常判断
if g != complex(1,2) && g != complex(3,4) {
fmt.Printf("concurrent assignment error, i=%v g=%+v", i, g)
break
}
}
}
运行输出:
concurrent assignment error, i=131512 g=(1+4i)
注意:如果复数并发赋值时,有相同的虚部或实部,那么两个字段赋值就退化成一个字段,这种情况下时并发安全的。
字符串(不安全)
字符串在 Go 中是一个只读字节切片。
字符串有两个重要特点:
- string 可以为空(长度为 0),但不会是 nil
- string对象不可以修改。
在源码包 src/runtime/string.go 可以找到 string 的底层数据结构:
type stringStruct struct {
str unsafe.Pointer
len int
}
其数据结构很简单: str 为字符串的首地址; len 为字符串的长度(单位字节); string 数据结构跟切片有些类似,只不过切片还有一个表示容量的成员,事实上 string 和字节切片间经常强制互转。
因为 string 底层结构是个 struct,前面已经讨论过 struct 并发赋值是不安全的,所以 string 的并发赋值同样是不安全。
可以说,只要底层结构是 struct 的类型,那么并发赋值都是不安全的。
不安全不代表一定发生错误。因为是两个字段,字节指针 str 和字符串长度 len,只要保证并发赋值情况下,两个字段的赋值正确就行。前面也说了,因为 struct 多个字段的赋值是独立,所以如果两个字段中只有一个字段是不同的,那么并发赋值就变成了一个字段的并发赋值,这样就不会出现问题。
比如并发赋值两个等长度但内容不同的字符串,就不会有问题。验证如下:
func main() {
var s string
for i := 0; i < 1000000; i++ {
var wg sync.WaitGroup
// 协程 1
wg.Add(1)
go func() {
defer wg.Done()
s = "123"
}()
// 协程 2
wg.Add(1)
go func() {
defer wg.Done()
s = "abc"
}()
wg.Wait()
// 赋值异常判断
if s != "123" && s != "abc" {
fmt.Printf("concurrent assignment error, i=%v s=%v", i, s)
break
}
}
}
上面的代码,因为字符串 123 和 abc 是等长的,所以并发赋值不管循环多少次都是绝对的安全。因为 struct 赋值蜕变成了一个数值型指针的赋值。
复合数据类型的并发赋值
指针(安全)
指针是保存另一个变量的内存地址的变量。指针的零值为 nil。
因为是内存地址,所以位宽为 32位(x86平台)或 64位(x64平台),赋值操作由一个机器指令即可完成,不能被中断,所以也不会出现并发赋值不安全的情况。
函数(安全)
Go 函数可以像值一样传递。
Go 函数定义形式如下:
func some_func_name(arguments) return_values
定义函数类型时去掉函数名:
type TypeName func(arguments) return_values
复制
其中 TypeName 是自定义的类型名称。
函数类型的变量赋值时,实际上赋的是函数地址,一条机器指令便可以完成,所以并发赋值是安全的。
数组、切片、字典、通道、接口(不安全)
数组、切片、字典、通道、接口,这些复合类型,除了数组,其他底层数据结构都是 struct,所以并发都不是安全的,当然数组并发赋值也是不安全的。
数组
array 是相同类型值的集合,数组的长度是其类型的一部分。
数组赋值和传参都会拷贝整个数组的数据,所以数组不是引用类型。
数组的底层数据结构就是其本身,是一个相同类型不同值的顺序排列。所以如果数组位宽不大于 64 位且是 2 的整数次幂(8,16,32,64),那么其并发赋值其实也是安全的,只不过这个大部分情况并非如此,所以其并发赋值是不安全的。
下面以字节数组为例,看下位宽不大于 64 位的并发赋值安全的情况。
func main() {
var g [4]byte
var i int
for ; i < 10000000; i++ {
var wg sync.WaitGroup
// 协程 1
wg.Add(1)
go func() {
defer wg.Done()
g = [...]byte{1, 2, 3, 4}
}()
// 协程 2
wg.Add(1)
go func() {
defer wg.Done()
g = [...]byte{3, 4, 5, 6}
}()
wg.Wait()
// 赋值异常判断
if !(g == [...]byte{1, 2, 3, 4} || g == [...]byte{3, 4, 5, 6}) {
fmt.Printf("concurrent assignment error, i=%v g=%+v", i, g)
break
}
}
if i == 10000000 {
fmt.Println("no error")
}
}
运行输出:
no error
可以看到,位宽为 32 位的数组 [4]byte,虽然有四个元素,但是赋值时由一条机器指令完成,所以也是原子操作。
如果把字节数组的长度换成下面这样子,即使没有超过 64 位,也需要多条指令完成赋值,因为 CPU 中并没有这样位宽的寄存器,需要拆分为多条指令来完成。
[3]byte
[5]byte
[7]byte
切片
slice 也是相同类型值的集合,只不过切片是动态调整大小的,内部是对数组的引用,相当于动态数组。如上所述,数组的大小是固定的,因此切片为数组提供了更灵活的接口。
切片是一种引用类型,它内部由三个字段表示:
- 数组地址
- 数组长度
- 容量大小
在源码包src/runtime/slice.go可以找到切片的底层数据结构:
type slice struct {
array unsafe.Pointer
len int
cap int
}
因为其是一个 struct,所以并发赋值是不安全的。
字典
map 是经常被使用的内置 key-value 型容器,是一个同类型元素的无序组,元素通过另一类型唯一键进行索引。
map 的底层结构也是一个 struct,定义于src/runtime/map.go:
// A header for a Go map.
type hmap struct {
// Note: the format of the hmap is also encoded in cmd/compile/internal/gc/reflect.go.
// Make sure this stays in sync with the compiler's definition.
count int // # live cells == size of map. Must be first (used by len() builtin)
flags uint8
B uint8 // log_2 of # of buckets (can hold up to loadFactor * 2^B items)
noverflow uint16 // approximate number of overflow buckets; see incrnoverflow for details
hash0 uint32 // hash seed
buckets unsafe.Pointer // array of 2^B Buckets. may be nil if count==0.
oldbuckets unsafe.Pointer // previous bucket array of half the size, non-nil only when growing
nevacuate uintptr // progress counter for evacuation (buckets less than this have been evacuated)
extra *mapextra // optional fields
}
map 并发读写会引发 panic,一般使用读写锁 sync.RWMutex 来保证安全。
通道
channel 在 goroutine 之间提供同步和通信。可以将其视为 goroutines 通过其发送值和接收值的管道。操作符<-用于发送或接收数据,箭头方向指定数据流的方向。
ch <- val // Sending a value present in var variable to channel
val := <-cha // Receive a value from the channel and assign it to val variable
因为 channel 通常用法是初始化后作为共享变量在 goroutine 之间提供同步和通信,很少会发生赋值,就是把一个 channel 赋给另一个 channel,所以这里就不过多讨论其并发赋值的安全性。
如果真的有这种情况,那么只要知道其底层数据结构是个 struct,并发赋值时不安全的即可。
关于 channel 的底层数据接口可在 Go 源码src\runtime\chan.go。
type hchan struct {
qcount uint // total data in the queue
dataqsiz uint // size of the circular queue
buf unsafe.Pointer // points to an array of dataqsiz elements
elemsize uint16
closed uint32
elemtype *_type // element type
sendx uint // send index
recvx uint // receive index
recvq waitq // list of recv waiters
sendq waitq // list of send waiters
// lock protects all fields in hchan, as well as several
// fields in sudogs blocked on this channel.
//
// Do not change another G's status while holding this lock
// (in particular, do not ready a G), as this can deadlock
// with stack shrinking.
lock mutex
}
接口
接口是 Go 中的一个类型,它是方法的集合。实现接口的所有方法的任何类型都属于该接口类型。接口的零值为 nil。
定义一个接口类型的变量后,如果具体类型实现了接口的所有方法,可以将任何具体类型的值赋给这个变量。
实际上 Go 中的接口有个特殊情况,就是空接口,其不包含任何方法。因此,默认情况下,所有具体类型都实现空接口。
如果编写的函数接受空接口,则可以向该函数传递任何类型。
package main
import "fmt"
func main() {
test("thisisstring")
test("10")
test(true)
}
func test(a interface{}) {
fmt.Printf("(%v, %T)\n", a, a)
}
运行输出:
(thisisstring, string)
(10, string)
(true, bool)
因为存在两种类型的接口,包含方法的非空接口和不包含任何方法的空接口,所以在底层实现上使用runtime.iface表示非空接口,使用runtime.eface表示空接口 interface{}。
在 Go 源码中 runtime 包下,可以找到 runtime.iface 和 runtime.eface 的定义。
type iface struct { // 16 字节
tab *itab
data unsafe.Pointer
}
这个结构体中有指向原始数据的指针 data 和 runtime.itab。
runtime.itab 结构体是接口类型的核心组成部分,每一个 runtime.itab 都占 32 字节,可以将其看成接口类型和具体类型的组合,它们分别用 inter 和 _type 两个字段表示:
type itab struct { // 32 字节
inter *interfacetype
_type *_type
hash uint32
_ [4]byte
fun [1]uintptr
}
除了 inter 和 _type 两个用于表示类型的字段之外,上述结构体中的另外两个字段也有自己的作用: hash 是对 _type.hash 的拷贝,当想将 interface 类型转换成具体类型时,可以使用该字段快速判断目标类型和具体类型 runtime._type 是否一致; fun 是一个动态大小的数组,它是一个用于动态派发的虚函数表,存储了一组函数指针。虽然该变量被声明成大小固定的数组,但是在使用时会通过原始指针获取其中的数据,所以 fun 数组中保存的元素数量是不确定的。
type eface struct { // 16 字节
_type *_type
data unsafe.Pointer
}
由于 interface{} 类型不包含任何方法,所以它的结构也相对来说比较简单,只包含指向底层数据和类型的两个指针。从上述结构也能推断出 Go 语言的任意类型都可以转换成 interface{}。
其中runtime._type是 Go 语言类型的运行时表示。下面是运行时包中的结构体,其中包含了很多类型的元信息,例如:类型的大小、哈希、对齐以及种类等。
type _type struct {
size uintptr
ptrdata uintptr
hash uint32
tflag tflag
align uint8
fieldAlign uint8
kind uint8
equal func(unsafe.Pointer, unsafe.Pointer) bool
gcdata *byte
str nameOff
ptrToThis typeOff
}
size 字段存储了类型占用的内存空间,为内存空间的分配提供信息;
hash 字段能够帮助快速确定类型是否相等;
equal 字段用于判断当前类型的多个对象是否相等,该字段是为了减少 Go 语言二进制包大小从 typeAlg 结构体中迁移过来的。
根据上面对接口底层结构的分析,可以得出如下结论:
接口底层数据结构包含两个字段,相互赋值时如果是相同具体类型不同值并发赋给一个接口,那么只有一个字段 data 的值是不同的,此时退化成指针的并发赋值,所以是安全的。但如果是不同具体类型的值并发赋给一个接口,那么会引发 panic。
不同具体类型并发赋值接口非安全验证如下:
func main() {
var g interface{}
var i int
for ; i < 10000000; i++ {
var wg sync.WaitGroup
// 协程 1
wg.Add(1)
go func() {
defer wg.Done()
g = "a"
}()
// 协程 2
wg.Add(1)
go func() {
defer wg.Done()
g = 1
}()
wg.Wait()
// 赋值异常判断
v1, _ := g.(string)
v2, _ := g.(int)
if !(v1 == "a" || v2 == 1) {
fmt.Printf("concurrent assignment error, i=%v g=%v ", i, g)
break
}
}
if i == 10000000 {
fmt.Println("no error")
}
}
运行输出:
unexpected fault address 0x1fffffa8
fatal error: fault
[signal 0xc0000005 code=0x0 addr=0x1fffffa8 pc=0x5f5585]
...
把上面的示例代码中协议 1 中的字符串换成一个 int 值,那么并发是安全的。
func main() {
var g interface{}
var i int
for ; i < 10000000; i++ {
var wg sync.WaitGroup
// 协程 1
wg.Add(1)
go func() {
defer wg.Done()
g = 0
}()
// 协程 2
wg.Add(1)
go func() {
defer wg.Done()
g = 1
}()
wg.Wait()
// 赋值异常判断
v1, _ := g.(int)
v2, _ := g.(int)
if !(v1 == 0 || v2 == 1) {
fmt.Printf("concurrent assignment error, i=%v g=%v ", i, g)
break
}
}
if i == 10000000 {
fmt.Println("no error")
}
}
运行输出:
no error
如何保证并发赋值的安全性
使用 Go 提供的 atomic 包来保证原子操作。
错误使用随机数
func IsInInvisibleProbability() bool {
rand.Seed(time.Now().UnixNano())
randNum := rand.Uint64() % 100
return randNum <= config.MyCustomConfig.MyConfig.InvisibleProbability
}
以上代码意在生成随机数,但是存在三个问题:
- 频繁 seed,每次 seed 出来都是独立的随机序列,同一个纳秒访问的出来的值也是同一个,另外会带来 lock contention 的问题。 建议通过init 函数来 seed。
- rand.Uint64() % 100 出来的概率不均等。必须采用 rand.Intn(100) 的方式。
<写成了<=,导致有 1% 的偏移。 例如,即使配置为 0 的时候,其实还是有 1% 的概率。
频繁 Seed
平时使用的大部分随机数是伪随机数,即算术生成随机数。它的原理是通过算术运算,迭代地生成一系列统计上均匀分布的结果。即, 随机数的序列是:
rand(Seed), rand(rand(Seed)), rand(rand(rand(Seed))), ...
当调用 rand 后,生成的随机数会作为新的种子。因此,正常情况下,不需要每次调用 rand 前都初始化种子。样例的代码使用时间作为初始化种子,这样做会有几个可能的问题:
- time.Now() 并不廉价。频繁获取时间是无谓的性能损耗。
- 重置随机数种子并没有必要。本质上,这相当于不再使用 rand 生成的随机数,而是使用时间作为随机数。如果在同一纳秒内调用这个方法,会产生完全一样的随机数。
因此,只要在 main() 或者 在 init() 函数中初始化一次即可。如果不介意每次的随机数序列提确定性的,也可以跳过初始化 Seed。
rand.Seed 和取随机数的方法是线程安全的,但是这可能会导致性能问题。当需要高频大量生成随机数时,可能会造成大量的锁竞争。因此,应该使用新的 Source,如:
rand.New(rand.NewSource(seed)) // Caution: not thread-safe!
但是要注意,NewSource 默认是并发不安全的,因此,不要在协程/线程之间共享 NewSource 所产生的 Source。
另外,注意 rand 包是密码学不安全的。换言之,可能会被攻击者利用,即攻击者可能会根据生成的随机数的特征预测随机数。因此永远不要使用 rand 进行一些敏感随机数的生成。如果需要防攻击的随机数生成器,使用 crypto.rand
通过取余操作对离散一致分布间做映射时,因为不能除尽导致偏移,不构成一致分布。
业务场景通常需要获取 [0, M) 的一致分布。但大部分随机数生成器都是在 2 的整数次幂上,即 [0, 1 << x) 的一致分布。我们通常希望通过某些简单的算术规则将 [0, 1 << x) 的一致分布映射至 [0, M) 的一致分布。
非常常见的做法是样例中的取余,如 rand() % 100, 获得 [0, 100) 的一致分布。这样非常简单直观,但是,有缺陷。
简单的数论知识告诉我们 2 的幂永远无法被 100 除尽,因此,rand() 的一致分布的所有值无法被均匀分配到 [0, 100) 这 100 个桶中。这使得前几个桶被分配的概率会比后面的桶高。当 rand() 的取值范围很大,如 [0, 1 << 64) 时,影响较小。但是这仍然是一个 bug,尤其在原分布的桶较小时,如原分布是 [0, 32767) 时,影响更大。
因此,当我们希望从 [0, M) 的一致分布生成 [0, N) 的一致分布时,要小心概率偏移。一个正确的处理方案是:
当 M > N 时:
- 截取
[0, M)中的部分分布[0, M'),M’ 是小于 M 且能被 N 除尽的最大值。它仍然是一个一致分布。 - 就
[0, M')的生成随机数对 N 取模,即可保证生成[0, N)的一致分0905布。 - 当 M 能被 N 整除时,可以直接取余。
当 M < N 时,一个可选的方案是:
- 通过取 t 次 M 值,直到
M * t > N,以此生成一个[0, M * t)的一致分布 - 以下处理同
M > N
边界处理失误,导致实际阈值比预期大 1%
注意返回的一致性分布是 [-0, 100),也就是 0, 1, 2, …, 99 的均匀分布。例如,当使用
return randNum <= 80
实际上有 81 个值 (0, 1, …, 80)会被包含。这使得实际的概率为 81%。
一定要注意 off-by-one error。这种错误在线上难以察觉,但是在统计意义上会对业务造成明显影响。
Off-By-One 是隐蔽又容易出错的问题,在离散分布里,一定要注意区间的开闭。
当需要一个 [a, b] 的离散一致性分布时,其与 [a, b+1) 等价。
因此,使用标准库时,应该先获取一个 [0, b - a + 1) 的一致分布,然后映射到 [a, b]。即:
Uniform [a, b] ==Uniform [a, b + 1) ==Uniform [0, b + 1 - a) + a
出于性能考虑的最佳实践和建议
(1)尽可能的使用 := 去初始化声明一个变量(在函数内部);
(2)尽可能的使用字符代替字符串;
(3)尽可能的使用切片代替数组;
(4)尽可能的使用数组和切片代替映射(详见参考文献 15);
(5)如果只想获取切片中某项值,不需要值的索引,尽可能的使用 for range 去遍历切片,这比必须查询切片中的每个元素要快一些;
(6)当数组元素是稀疏的(例如有很多 0 值或者空值 nil),使用映射会降低内存消耗;
(7)初始化映射时指定其容量;
(8)当定义一个方法时,使用指针类型作为方法的接受者;
(9)在代码中使用常量或者标志提取常量的值;
(10)尽可能在需要分配大量内存时使用缓存;
(11)使用缓存模板
参考文档:
Don’t use Go’s default HTTP client (in production)
Golang Block 到底是什么? 怎么就能解决闭包变量冲突了?