go 入门
基础
包
按照约定,包名与导入路径的最后一个元素一致。例如,"math/rand" 包中的源码均以 package rand 语句开始。
导出名
在 Go 中,如果一个名字以大写字母开头,那么它就是已导出的。例如,Pizza 就是个已导出名,Pi 也同样,它导出自 math 包。
pizza 和 pi 并未以大写字母开头,所以它们是未导出的。
在导入一个包时,只能引用其中已导出的名字。任何“未导出”的名字在该包外均无法访问。
变量
var 语句用于声明一个变量列表,跟函数的参数列表一样,类型在最后。
var x int;
变量声明可以包含初始值,每个变量对应一个。如果初始化值已存在,则可以省略类型;变量会从初始值中获得类型。
package main
import "fmt"
var i, j int = 1, 2
func main() {
var c, python, java = true, false, "no!"
fmt.Println(i, j, c, python, java)
}
函数内部的变量(局部变量)可以采用简洁赋值语句 := 在类型明确的地方代替 var 声明变量:(仅限函数内部)
package main
import "fmt"
func main() {
var i, j int = 1, 2
k := 3
c, python, java := true, false, "no!"
fmt.Println(i, j, k, c, python, java)
}
基本变量类型
Go 的基本类型有
bool
string
int int8 int16 int32 int64
uint uint8 uint16 uint32 uint64 uintptr
byte // uint8 的别名
rune // int32 的别名
// 表示一个 Unicode 码点
float32 float64
// 复数使用 re+imI 来表示,其中 re 代表实数部分,im 代表虚数部分,I 代表根号负 1。
complex64 complex128 // 32、64 位实数和虚数
对于有符号整型,范围如下:
int8:表示 8 位有符号整型
大小:8 位
范围:-128~127
int16:表示 16 位有符号整型
大小:16 位
范围:-32768~32767
int32:表示 32 位有符号整型
大小:32 位
范围:-2147483648~2147483647
int64:表示 64 位有符号整型
大小:64 位
范围:-9223372036854775808~9223372036854775807
对于无符号整型,其范围如下:
uint8:表示 8 位无符号整型
大小:8 位
范围:0~255
uint16:表示 16 位无符号整型
大小:16 位
范围:0~65535
uint32:表示 32 位无符号整型
大小:32 位
范围:0~4294967295
uint64:表示 64 位无符号整型
大小:64 位
范围:0~18446744073709551615
同导入语句一样,变量声明也可以“分组”成一个语法块:
var (
ToBe bool = false
MaxInt uint64 = 1<<64 - 1
z complex128 = cmplx.Sqrt(-5 + 12i)
)
int, uint 和 uintptr 在 32 位系统上通常为 32 位宽,在 64 位系统上则为 64 位宽。 当需要一个整数值时应使用 int 类型,除非有特殊的理由使用固定大小或无符号的整数类型。int 型是计算最快的一种类型。
float32 精确到小数点后 7 位,float64 精确到小数点后 15 位。由于精确度的缘故,在使用 == 或者 != 来比较浮点数时应当非常小心。最好在正式使用前测试对于精确度要求较高的运算。
应该尽可能地使用 float64,因为 math 包中所有有关数学运算的函数都会要求接收这个类型。
可以通过增加前缀 0 来表示 8 进制数(如:077),增加前缀 0x 来表示 16 进制数(如:0xFF),以及使用 e 来表示 10 的连乘(如: 1e3 = 1000,或者 6.022e23 = 6.022 x 1e23)。
可以使用 a := uint64(0) 来同时完成类型转换和赋值操作,这样 a 的类型就是 uint64。
当进行类似 a32bitInt = int32(a32Float) 的转换时,小数点后的数字将被丢弃。这种情况一般发生当从取值范围较大的类型转换为取值范围较小的类型时,或者可以写一个专门用于处理类型转换的函数来确保没有发生精度的丢失。
对于虚数,
var c1 complex64 = 5 + 10i
fmt.Printf("The value is: %v", c1)
// 输出: 5 + 10i
如果 re 和 im 的类型均为 float32,那么类型为 complex64 的复数 c 可以通过以下方式来获得:
c = complex(re, im)
函数 real(c) 和 imag(c) 可以分别获得相应的实数和虚数部分。
在使用格式化说明符时,可以使用 %v 来表示复数,但当希望只表示其中的一个部分的时候需要使用 %f。
复数支持和其它数字类型一样的运算。当使用等号 == 或者不等号 != 对复数进行比较运算时,注意对精确度的把握。cmath 包中包含了一些操作复数的公共方法。如果对内存的要求不是特别高,最好使用 complex128 作为计算类型,因为相关函数都使用这个类型的参数。
Go 中不允许不同类型之间的混合使用,但是对于常量的类型限制非常少,因此允许常量之间的混合使用
变量初始值:
- 数值类型为
0 - 布尔类型为
false - 字符串为
""(空字符串) - 指针为
nil
类型转换
表达式 T(v) 将值 v 转换为类型 T。
例子如下:
var i int = 42
var f float64 = float64(i)
var u uint = uint(f)
也可以是这种形式:
i := 42
f := float64(i)
u := uint(f)
Go 在不同类型的项之间赋值时需要显式转换,如:
func main() {
var x, y int = 3, 4
//这一句会报错,因为没有执行 math.Sqrt 的返回类型
var f float64 = math.Sqrt((x*x + y*y))
//正确做法
var f float64 = math.Sqrt(float64(x*x + y*y))
var z uint = uint(f)
fmt.Println(x, y, z)
}
类型推导
在声明一个变量而不指定其类型时(即使用不带类型的 := 语法或 var = 表达式语法),变量的类型由右值推导得出。
当右值声明了类型时,新变量的类型与其相同:
var i int
j := i // j 也是一个 int
不过当右边包含未指明类型的数值常量时,新变量的类型就可能是 int, float64 或 complex128 了,这取决于常量的精度:
i := 42 // int
f := 3.142 // float64
g := 0.867 + 0.5i // complex128
对于能够确定初始值的变量,推荐使用这种方式进行初始化。
时间和日期
time 包提供了一个数据类型 time.Time(作为值使用)以及显示和测量时间和日期的功能函数。
当前时间可以使用 time.Now() 获取,或者使用 t.Day()、t.Minute() 等等来获取时间的一部分;甚至可以自定义时间格式化字符串,例如: fmt.Printf("%02d.%02d.%4d\n", t.Day(), t.Month(), t.Year()) 将会输出 21.07.2011。
Duration 类型表示两个连续时刻所相差的纳秒数,类型为 int64。Location 类型映射某个时区的时间,UTC 表示通用协调世界时间。
包中的一个预定义函数 func (t Time) Format(layout string) string 可以根据一个格式化字符串来将一个时间 t 转换为相应格式的字符串,可以使用一些预定义的格式,如:time.ANSIC 或 time.RFC822。
一般的格式化设计是通过对于一个标准时间的格式化描述来展现的:
fmt.Println(t.Format("02 Jan 2006 15:04"))
输出:
21 Jul 2011 10:31
示例:
package main
import (
"fmt"
"time"
)
var week time.Duration
func main() {
t := time.Now()
fmt.Println(t) // e.g. Wed Dec 21 09:52:14 +0100 RST 2011
fmt.Printf("%02d.%02d.%4d\n", t.Day(), t.Month(), t.Year())
// 21.12.2011
t = time.Now().UTC()
fmt.Println(t) // Wed Dec 21 08:52:14 +0000 UTC 2011
fmt.Println(time.Now()) // Wed Dec 21 09:52:14 +0100 RST 2011
// calculating times:
week = 60 * 60 * 24 * 7 * 1e9 // must be in nanosec
week_from_now := t.Add(week)
fmt.Println(week_from_now) // Wed Dec 28 08:52:14 +0000 UTC 2011
// formatting times:
fmt.Println(t.Format(time.RFC822)) // 21 Dec 11 0852 UTC
fmt.Println(t.Format(time.ANSIC)) // Wed Dec 21 08:56:34 2011
fmt.Println(t.Format("21 Dec 2011 08:52")) // 21 Dec 2011 08:52
s := t.Format("20111221")
fmt.Println(t, "=>", s)
// Wed Dec 21 08:52:14 +0000 UTC 2011 => 20111221
}
输出的结果已经写在每行 // 的后面。
如果需要在应用程序在经过一定时间或周期执行某项任务(事件处理的特例),则可以使用 time.After 或者 time.Ticker。另外,time.Sleep(Duration d) 可以实现对某个进程(实质上是 goroutine)时长为 d 的暂停。
常量
常量的声明与变量类似,只不过是使用 const 关键字。
常量只可以是字符、字符串、布尔值或数值。
常量不能用 := 语法声明。
由于常量已经初始化,所以可以不指定类型。
常量的值必须是能够在编译时就能够确定的。
常量默认是无类型的,如果要创建一个有类型的常量,可以使用下面的语法:
const typedhello string = "Hello World"
package main
import "fmt"
const Pi = 3.14
func main() {
const World = "世界"
fmt.Println("Hello", World)
fmt.Println("Happy", Pi, "Day")
const Truth = true
fmt.Println("Go rules?", Truth)
}
数值常量
数值常量是高精度的值。
一个未指定类型的常量由上下文来决定其类型。
(int 类型最大可以存储一个 64 位的整数,有时会更小。)
(int 可以存放最大64位的整数,根据平台不同有时会更少。)
package main
import "fmt"
const (
// 将 1 左移 100 位来创建一个非常大的数字
// 即这个数的二进制是 1 后面跟着 100 个 0
Big = 1 << 100
// 再往右移 99 位,即 Small = 1 << 1,或者说 Small = 2
Small = Big >> 99
)
func needInt(x int) int { return x*10 + 1 }
func needFloat(x float64) float64 {
return x * 0.1
}
func main() {
fmt.Println(needInt(Small))
fmt.Println(needFloat(Small))
fmt.Println(needFloat(Big))
//超过范围报错
fmt.Println(needInt(Big))
}
数字型的常量是没有大小和符号的,并且可以使用任何精度而不会导致溢出:
const Ln2= 0.693147180559945309417232121458\
176568075500134360255254120680009
const Log2E= 1/Ln2 // this is a precise reciprocal
const Billion = 1e9 // float constant
const hardEight = (1 << 100) >> 97
根据上面的例子可以看到,反斜杠 \ 可以在常量表达式中作为多行的连接符使用。
与各种类型的数字型变量相比,无需担心常量之间的类型转换问题,因为它们都是非常理想的数字。
不过需要注意的是,当常量赋值给一个精度过小的数字型变量时,可能会因为无法正确表达常量所代表的数值而导致溢出,这会在编译期间就引发错误。
常量还可以用作枚举:
const (
Unknown = 0
Female = 1
Male = 2
)
现在,数字 0、1 和 2 分别代表未知性别、女性和男性。这些枚举值可以用于测试某个变量或常量的实际值,比如使用 switch/case 结构
在这个例子中,iota 可以被用作枚举值:
const (
a = iota
b = iota
c = iota
)
第一个 iota 等于 0,每当 iota 在新的一行被使用时,它的值都会自动加 1;所以 a=0, b=1, c=2 可以简写为如下形式:
const (
a = iota
b
c
)
iota 也可以用在表达式中,如:iota + 50。在每遇到一个新的常量块或单个常量声明时, iota 都会重置为 0( 简单地讲,每遇到一次 const 关键字,iota 就重置为 0 )。
当然,常量之所以为常量就是恒定不变的量,因此无法在程序运行过程中修改它的值;如果在代码中试图修改常量的值则会引发编译错误。
引用 time 包中的一段代码作为示例:一周中每天的名称。
const (
Sunday = iota
Monday
Tuesday
Wednesday
Thursday
Friday
Saturday
)
也可以使用某个类型作为枚举常量的类型:
type Color int
const (
RED Color = iota // 0
ORANGE // 1
YELLOW // 2
GREEN // ..
BLUE
INDIGO
VIOLET // 6
)
函数
函数语法
方法名/变量名在前,属性/返回类型在后。
官网解释是可读性更强,现在还没习惯感觉怪怪的
package main
import "fmt"
func add(x int, y int) int {
return x + y
}
//上述方式可以写成:表示 x,y 都是 int
func add(x,y int) int {
//...
}
func main() {
fmt.Println(add(42, 13))
}
返回值
函数可以返回任意数量的返回值。
package main
import "fmt"
func swap(x, y string) (string, string) {
return y, x
}
返回值命名:go 的返回值可以被命名,会将是视为预先在函数里定义的变量,当直接写 return 时表示返回命名的返回值变量:
package main
import "fmt"
func split(sum int) (x, y int) {
//相当于定义了:
// var x int;
// var y int;
x = sum * 4 / 9
y = sum - x
//相当于 return x,y
return
}
函数值
函数也是值。它们可以像其它值一样传递。
函数值可以用作函数的参数或返回值,然后在其它函数内调用执行,一般称之为回调。
package main
import (
"fmt"
"math"
)
func compute(fn func(float64, float64) float64) float64 {
//回调 fn
return fn(3, 4)
}
func main() {
hypot := func(x, y float64) float64 {
return math.Sqrt(x*x + y*y)
}
fmt.Println(hypot(5, 12))
fmt.Println(compute(hypot))
fmt.Println(compute(math.Pow))
}
Go 默认使用按值传递来传递参数,也就是传递参数的副本。函数接收参数副本之后,在使用变量的过程中可能对副本的值进行更改,但不会影响到原来的变量,比如 Function(arg1)。
如果希望函数可以直接修改参数的值,而不是对参数的副本进行操作,需要将参数的地址(变量名前面添加 & 符号,比如 &variable)传递给函数,这就是按引用传递,比如 Function(&arg1),此时传递给函数的是一个指针。如果传递给函数的是一个指针,指针的值(一个地址)会被复制,但指针的值所指向的地址上的值不会被复制;我们可以通过这个指针的值来修改这个值所指向的地址上的值。(译者注:指针也是变量类型,有自己的地址和值,通常指针的值指向一个变量的地址。所以,按引用传递也是按值传递。)
几乎在任何情况下,传递指针(一个 32 位或者 64 位的值)的消耗都比传递副本来得少。
在函数调用时,像切片(slice)、字典(map)、接口(interface)、通道(channel)这样的引用类型都是默认使用引用传递(即使没有显式的指出指针)。
有些函数只是完成一个任务,并没有返回值。我们仅仅是利用了这种函数的副作用,就像输出文本到终端,发送一个邮件或者是记录一个错误等。
但是绝大部分的函数还是带有返回值的。
init 函数
这是一类非常特殊的函数,它不能够被人为调用,而是在每个包完成初始化后自动执行,并且执行优先级比 main 函数高。
每个源文件都只能包含一个 init 函数。初始化总是以单线程执行,并且按照包的依赖关系顺序执行。
一个可能的用途是在开始执行程序之前对数据进行检验或修复,以保证程序状态的正确性。
init 函数也经常被用在当一个程序开始之前调用后台执行的 goroutine,如下面这个例子当中的 backend():
func init() {
// setup preparations
go backend()
}
包的初始化顺序如下:
- 首先初始化包级别(Package Level)的变量
- 紧接着调用 init 函数。包可以有多个 init 函数(在一个文件或分布于多个文件中),它们按照编译器解析它们的顺序进行调用。
如果一个包导入了另一个包,会先初始化被导入的包。
尽管一个包可能会被导入多次,但是它只会被初始化一次。
变长参数
函数的最后一个参数是采用 ...type 的形式,表示这是一个可变长参数,必须放在最后一个参数
func myFunc(a, b, arg ...int) {}
可变参数函数的工作原理是把可变参数转换为一个新的切片。以下面程序为例,find 函数中的可变参数是 89,90,95 。 find 函数接受一个 int 类型的可变参数。因此这三个参数被编译器转换为一个 int 类型切片 int []int{89, 90, 95} 然后被传入 find函数。
package main
import (
"fmt"
)
func find(num int, nums ...int) {
fmt.Printf("type of nums is %T\n", nums)
found := false
for i, v := range nums {
if v == num {
fmt.Println(num, "found at index", i, "in", nums)
found = true
}
}
if !found {
fmt.Println(num, "not found in ", nums)
}
fmt.Printf("\n")
}
func main() {
find(89, 89, 90, 95)
find(45, 56, 67, 45, 90, 109)
find(78, 38, 56, 98)
find(87)
}
因为参数会转化成一个切片,所以对于变长参数,不能直接传递切片,要么一个一个传,要么就需要使用语法糖...:
package main
import "fmt"
func main() {
x := min(1, 3, 2, 0)
fmt.Printf("The minimum is: %d\n", x)
slice := []int{7,9,3,5,1}
x = min(slice...)
fmt.Printf("The minimum in the slice is: %d", x)
}
func min(s ...int) int {
if len(s)==0 {
return 0
}
min := s[0]
for _, v := range s {
if v < min {
min = v
}
}
return min
}
函数的闭包
Go 函数可以是一个闭包。闭包是一个函数值,它引用了其函数体之外的变量。该函数可以访问并赋予其引用的变量的值,换句话说,该函数被这些变量“绑定”在一起。
闭包也叫做匿名函数,当我们不希望给函数起名字的时候,可以使用匿名函数,例如:func(x, y int) int { return x + y }。
这样的一个函数不能够独立存在(编译器会返回错误:non-declaration statement outside function body),但可以被赋值于某个变量,即保存函数的地址到变量中:fplus := func(x, y int) int { return x + y },然后通过变量名对函数进行调用:fplus(3,4)。
当然,也可以直接对匿名函数进行调用:func(x, y int) int { return x + y } (3, 4)。
闭包的应用
将函数作为返回值
例如,函数 Adder 返回一个闭包。每个闭包都被绑定在其各自的 x 变量上。
package main
import "fmt"
func main() {
var f = Adder()
fmt.Print(f(1), " - ")
fmt.Print(f(20), " - ")
fmt.Print(f(300))
}
func Adder() func(int) int {
var x int // 此处 x 的值只声明了一次,值会被保留
return func(delta int) int {
x += delta
return x
}
}
1 - 21 - 321
三次调用函数 f 的过程中函数 Adder () 中变量 delta 的值分别为:1、20 和 300。
我们可以看到,在多次调用中,变量 x 的值是被保留的,即 0 + 1 = 1,然后 1 + 20 = 21,最后 21 + 300 = 321:闭包函数保存并积累其中的变量的值,不管外部函数退出与否,它都能够继续操作外部函数中的局部变量。
这些局部变量同样可以是参数,例如之前例子中的 Adder(as int)。
可以把闭包看成是一个类,一个闭包函数调用就是实例化一个类。闭包在运行时可以有多个实例,它会将同一个作用域里的变量和常量捕获下来,无论闭包在什么地方被调用(实例化)时,都可以使用这些变量和常量。而且,闭包捕获的变量和常量是引用传递,不是值传递。
对于下面的例子:
import "fmt"
func main() {
var a = Accumulator()
fmt.Printf("%d\n", a(1))
fmt.Printf("%d\n", a(10))
fmt.Printf("%d\n", a(100))
fmt.Println("------------------------")
var b = Accumulator()
fmt.Printf("%d\n", b(1))
fmt.Printf("%d\n", b(10))
fmt.Printf("%d\n", b(100))
}
func Accumulator() func(int) int {
var x int
return func(delta int) int {
fmt.Printf("(%+v, %+v) - ", &x, x)
x += delta
return x
}
}
执行结果如下:
(0xc00018c000, 0) - 1
(0xc00018c000, 1) - 11
(0xc00018c000, 11) - 111
------------------------
(0xc00018c020, 0) - 1
(0xc00018c020, 1) - 11
(0xc00018c020, 11) - 111
闭包引用了 x 变量,a,b 可看作 2 个不同的实例,实例之间互不影响。实例内部,x 变量是同一个地址,因此具有“累加效应”。
工厂函数
一个返回值为另一个函数的函数可以被称之为工厂函数,这在需要创建一系列相似的函数的时候非常有用:书写一个工厂函数而不是针对每种情况都书写一个函数。下面的函数演示了如何动态返回追加后缀的函数:
func MakeAddSuffix(suffix string) func(string) string {
return func(name string) string {
if !strings.HasSuffix(name, suffix) {
return name + suffix
}
return name
}
}
现在,可以生成如下函数:
addBmp := MakeAddSuffix(".bmp")
addJpeg := MakeAddSuffix(".jpeg")
然后调用它们:
addBmp("file") // returns: file.bmp
addJpeg("file") // returns: file.jpeg
使用闭包调试(暂时没搞懂)
当在分析和调试复杂的程序时,无数个函数在不同的代码文件中相互调用,如果这时候能够准确地知道哪个文件中的具体哪个函数正在执行,对于调试是十分有帮助的。您可以使用 runtime 或 log 包中的特殊函数来实现这样的功能。包 runtime 中的函数 Caller() 提供了相应的信息,因此可以在需要的时候实现一个 where() 闭包函数来打印函数执行的位置:
where := func() {
_, file, line, _ := runtime.Caller(1)
log.Printf("%s:%d", file, line)
}
where()
// some code
where()
// some more code
where()
也可以设置 log 包中的 flag 参数来实现:
log.SetFlags(log.Llongfile)
log.Print("")
或使用一个更加简短版本的 where 函数:
var where = log.Print
func func1() {
where()
... some code
where()
... some code
where()
}
运算符
只记录不常见的以备查询:
一元运算符
按位补足 ^:该运算符与异或运算符一同使用,即 m^x,对于无符号 x 使用 “全部位设置为 1”,对于有符号 x 时使用 m=-1。例如:
^2 = ^10 = -01 ^ 10 = -11(二进制)
二元运算符
- 位清除
&^:将指定位置上的值设置为 0。
带有
++和--的只能作为语句,而非表达式,因此n = i++这种写法是无效的,其它像f(i++)或者a[i]=b[i++]这些可以用于 C、C++ 和 Java 中的写法在 Go 中也是不允许的。
指针
Go 拥有指针。指针保存了值的内存地址。
一个指针变量可以指向任何一个值的内存地址。它指向那个值的内存地址,在 32 位机器上占用 4 个字节,在 64 位机器上占用 8 个字节,并且与它所指向的值的大小无关。当然,可以声明指针指向任何类型的值来表明它的原始性或结构性;可以在指针类型前面加上 * 号(前缀)来获取指针所指向的内容,这里的 * 号是一个类型更改器。使用一个指针引用一个值被称为间接引用。
当一个指针被定义后没有分配到任何变量时,它的值为 nil。
一个指针变量通常缩写为 ptr。
类型 *T 是指向 T 类型值的指针。其零值为 nil。
var p *int
& 操作符会生成一个指向其操作数的指针。
i := 42
p = &i
* 操作符表示指针指向的底层值。
fmt.Println(*p) // 通过指针 p 读取 i
*p = 21 // 通过指针 p 设置 i
这也就是通常所说的“间接引用”或“重定向”。
go 中指针不能得到一个文字或常量的地址,例如:
const i = 5
ptr := &i //error: cannot take the address of i
ptr2 := &10 //error: cannot take the address of 10
与 C 不同,Go 没有指针运算。
数组
类型 [n]T 表示拥有 n 个 T 类型的值的数组。
表达式
var a [10]int
会将变量 a 声明为拥有 10 个整数的数组。
当数组内容确定时,可以不指定容量,直接赋值:
[]bool{true, true, false}
数组的长度是其类型的一部分,因此数组不能改变大小。这看起来是个限制,不过没关系,Go 提供了更加便利的方式来使用数组。
package main
import "fmt"
func main() {
var a [2]string
a[0] = "Hello"
a[1] = "World"
fmt.Println(a[0], a[1])
//直接打印数组会有 [] 符号
fmt.Println(a)
primes := [6]int{2, 3, 5, 7, 11, 13}
fmt.Println(primes)
}
Go 语言中的数组是一种值类型(不像 C/C++ 中是指向首元素的指针),所以可以通过 new() 来创建: var arr1 = new([5]int)。
那么这种方式和 var arr2 [5]int 的区别是什么呢?
arr1 的类型是 *[5]int,而 arr2 的类型是 [5]int。
此时如果把 arr1 赋值给 arr2 ,需要在做一次数组内存的拷贝操作。例如:
arr2 := *arr1 // 对数组进行一次拷贝
arr2[2] = 100
这样两个数组就有了不同的值,在赋值后修改 arr2 不会对 arr1 生效。
所以在函数中数组作为参数传入时,如 func1(arr2),会产生一次数组拷贝,func1 方法不会修改原始的数组 arr2。
切片
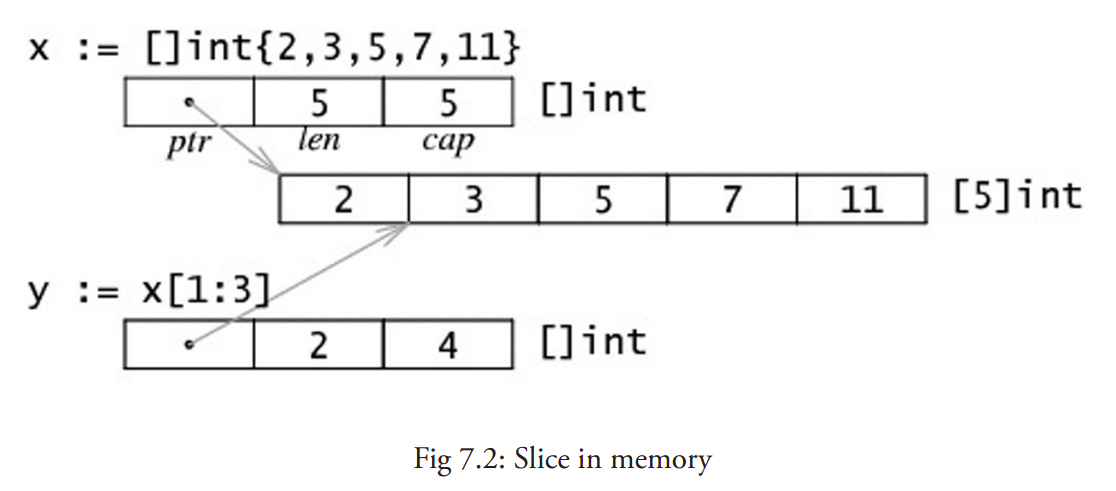
切片(slice)是对数组一个连续片段的引用(该数组称之为相关数组,通常是匿名的),所以切片是一个引用类型(因此更类似于 C/C++ 中的数组类型,或者 Python 中的 list 类型)。这个片段可以是整个数组,或者是由起始和终止索引标识的一些项的子集。需要注意的是,终止索引标识的项不包括在切片内。切片提供了一个相关数组的动态窗口。
每个数组的大小都是固定的。而切片则为数组元素提供动态大小的、灵活的视角。在实践中,切片比数组更常用。
类型 []T 表示一个元素类型为 T 的切片。
注意:切片与数组在语法上的区别在于前面的 [] 有没有指定初始大小
切片通过两个下标来界定,即一个上界和一个下界,二者以冒号分隔:
a[low : high]
它会选择一个半开区间,包括第一个元素,但排除最后一个元素。
以下表达式创建了一个切片,它包含 a 中下标从 1 到 3 的元素:
a[1:4]
package main
import "fmt"
func main() {
primes := [6]int{2, 3, 5, 7, 11, 13}
var s []int = primes[1:4]
fmt.Println(s)
}
切片就像数组的引用切片,并不存储任何数据,它只是描述了底层数组中的一段。更改切片的元素会修改其底层数组中对应的元素。
package main
import "fmt"
func main() {
names := [4]string{
"John",
"Paul",
"George",
"Ringo",
}
//[John Paul George Ringo]
fmt.Println(names)
//[John Paul]
a := names[0:2]
//[Paul George]
b := names[1:3]
fmt.Println(a, b)
b[0] = "XXX"
// a:[John XXX],b:[XXX George]
fmt.Println(a, b)
//[John XXX George Ringo]
fmt.Println(names)
}
在进行切片时,你可以利用它的默认行为来忽略上下界。
切片下界的默认值为 0,上界则是该切片的长度。
var a [10]int
//等价
a[0:10]
a[:10]
a[0:]
a[:]
切片拥有 长度 和 容量。
切片的长度就是它所包含的元素个数。
切片的容量是从它的第一个元素开始数,到其底层数组元素末尾的个数。
切片 s 的长度和容量可通过表达式 len(s) 和 cap(s) 来获取。
可以通过重新切片来扩展一个切片,给它提供足够的容量。
切片在内存中的组织结构:
nil 切片
切片的零值是 nil。
nil 切片的长度和容量为 0 且没有底层数组。
var s []int
len(s) // 0
cap(s) // 0
fmt.Println(s) // []
s == nil // true
创建切片
切片可以用内建函数 make 来创建,这也是你创建动态数组的方式。
make 函数会分配一个元素为零值的数组并返回一个引用了它的切片:
a := make([]int, 5) // len(a)=5
要指定它的容量,需向 make 传入第三个参数:
b := make([]int, 0, 5) // len(b)=0, cap(b)=5,[]
c := make([]int,3,10) // [0,0,0]
b = b[:cap(b)] // len(b)=5, cap(b)=5,[0,0,0,0,0]
b = b[1:] // len(b)=4, cap(b)=4
切片可包含任何类型,甚至包括其它的切片:
package main
import (
"fmt"
"strings"
)
func main() {
// 创建一个井字板(经典游戏)
board := [][]string{
[]string{"_", "_", "_"},
[]string{"_", "_", "_"},
[]string{"_", "_", "_"},
}
// 两个玩家轮流打上 X 和 O
board[0][0] = "X"
board[2][2] = "O"
board[1][2] = "X"
board[1][0] = "O"
board[0][2] = "X"
for i := 0; i < len(board); i++ {
fmt.Printf("%s\n", strings.Join(board[i], " "))
}
}
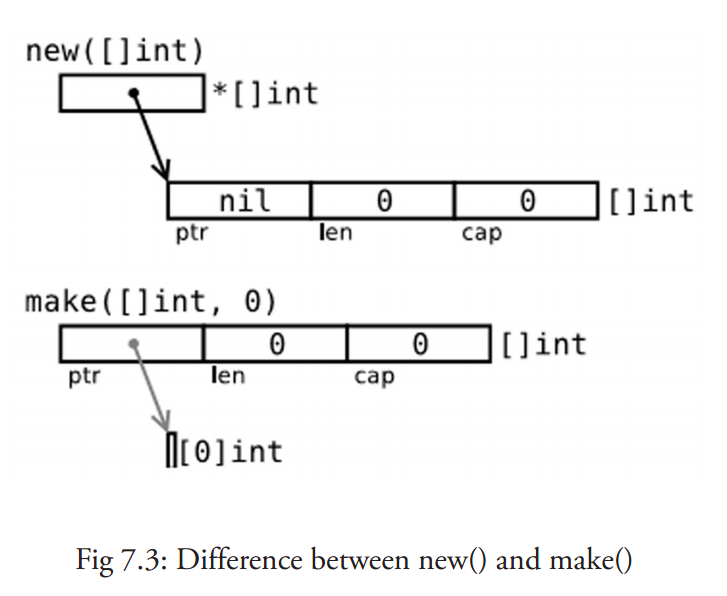
make()和 new()的区别
二者都在堆上分配内存,但是它们的行为不同,适用于不同的类型。
- new (T) 为每个新的类型 T 分配一片内存,初始化为 0 并且返回类型为 * T 的内存地址:这种方法返回一个指向类型为 T,值为 0 的地址的指针,它适用于值类型如数组和结构体;它相当于
&T{}。 - make(T) 返回一个类型为 T 的初始值,它只适用于 3 种内建的引用类型:切片、map 和 channel。
换言之,new 函数分配内存,make 函数初始化;下图给出了区别:
拷贝切片
func copy(dst, src []T) int copy 方法将类型为 T 的切片从源地址 src 拷贝到目标地址 dst,覆盖 dst 的相关元素,并且返回拷贝的元素个数。源地址和目标地址可能会有重叠。拷贝个数是 src 和 dst 的长度最小值。如果 src 是字符串那么元素类型就是 byte。如果你还想继续使用 src,在拷贝结束后执行 src = dst。
向切片追加元素
为切片追加新的元素是种常用的操作,为此 Go 提供了内建的 append 函数。
func append(s []T, vs ...T) []T
append 的第一个参数 s 是一个元素类型为 T 的切片,其余类型为 T 的值将会追加到该切片的末尾。
append 的结果是一个包含原切片所有元素加上新添加元素的切片。
当 s 的底层数组太小,不足以容纳所有给定的值时,它就会分配一个更大的数组。返回的切片会指向这个新分配的数组。
package main
import "fmt"
func main() {
var s []int //[]
// 添加一个空切片
s = append(s, 0) //[0]
// 这个切片会按需增长
s = append(s, 1) //[0 1]
// 可以一次性添加多个元素
s = append(s, 2, 3, 4) //[0 1 2 3 4]
}
append 函数常见操作
将切片 b 的元素追加到切片 a 之后:
a = append(a, b...)复制切片 a 的元素到新的切片 b 上:
b = make([]T, len(a)) copy(b, a)删除位于索引 i 的元素:
a = append(a[:i], a[i+1:]...)切除切片 a 中从索引 i 至 j 位置的元素:
a = append(a[:i], a[j:]...)为切片 a 扩展 j 个元素长度:
a = append(a, make([]T, j)...)在索引 i 的位置插入元素 x:
a = append(a[:i], append([]T{x}, a[i:]...)...)在索引 i 的位置插入长度为 j 的新切片:
a = append(a[:i], append(make([]T, j), a[i:]...)...)在索引 i 的位置插入切片 b 的所有元素:
a = append(a[:i], append(b, a[i:]...)...)取出位于切片 a 最末尾的元素 x:
x, a = a[len(a)-1:], a[:len(a)-1]将元素 x 追加到切片 a:
a = append(a, x)
内存优化
切片持有对底层数组的引用。只要切片在内存中,数组就不能被垃圾回收。只有在没有任何切片指向的时候,底层的数组内存才会被释放,这种特性有时会导致程序占用多余的内存。在内存管理方面,这是需要注意的。假设我们有一个非常大的数组,我们只想处理它的一小部分。然后,我们由这个数组创建一个切片,并开始处理切片。这里需要重点注意的是,在切片引用时数组仍然存在内存中。
一种解决方法是使用 copy 函数 func copy(dst,src[]T)int 来生成一个切片的副本。这样我们可以使用新的切片,原始数组可以被垃圾回收。
package main
import (
"fmt"
)
func countries() []string {
countries := []string{"USA", "Singapore", "Germany", "India", "Australia"}
neededCountries := countries[:len(countries)-2]
countriesCpy := make([]string, len(neededCountries))
copy(countriesCpy, neededCountries) //copies neededCountries to countriesCpy
return countriesCpy
}
func main() {
countriesNeeded := countries()
fmt.Println(countriesNeeded)
}
在上述程序的第 9 行,neededCountries := countries[:len(countries)-2 创建一个去掉尾部 2 个元素的切片 countries,在上述程序的 11 行,将 neededCountries 复制到 countriesCpy 同时在函数的下一行返回 countriesCpy。现在 countries 数组可以被垃圾回收, 因为 neededCountries 不再被引用。
Range
for 循环的 range 形式可遍历切片或映射。
当使用 for 循环遍历切片时,每次迭代都会返回两个值。第一个值为当前元素的下标,第二个值为该下标所对应元素的一份副本。
package main
import "fmt"
var pow = []int{1, 2, 4, 8, 16, 32, 64, 128}
func main() {
for i, v := range pow {
fmt.Printf("2**%d = %d\n", i, v)
}
}
可以将下标或值赋予 _ 来忽略它。
for i, _ := range pow
for _, value := range pow
若你只需要索引,忽略第二个变量即可。
for i := range pow
bytes包
类型 []byte 的切片十分常见,Go 语言有一个 bytes 包专门用来解决这种类型的操作方法。
bytes 包和字符串包十分类似(参见第 4.7 节)。而且它还包含一个十分有用的类型 Buffer:
import "bytes"
type Buffer struct {
...
}
这是一个长度可变的 bytes 的 buffer,提供 Read 和 Write 方法,因为读写长度未知的 bytes 最好使用 buffer。
Buffer 可以这样定义:var buffer bytes.Buffer。
或者使用 new 获得一个指针:var r *bytes.Buffer = new(bytes.Buffer)。
或者通过函数:func NewBuffer(buf []byte) *Buffer,创建一个 Buffer 对象并且用 buf 初始化好;NewBuffer 最好用在从 buf 读取的时候使用。
通过 buffer 串联字符串
类似于 Java 的 StringBuilder 类。
在下面的代码段中,创建一个 buffer,通过 buffer.WriteString(s) 方法将字符串 s 追加到后面,最后再通过 buffer.String() 方法转换为 string:
var buffer bytes.Buffer
for {
if s, ok := getNextString(); ok { //method getNextString() not shown here
buffer.WriteString(s)
} else {
break
}
}
fmt.Print(buffer.String(), "\n")
这种实现方式比使用 += 要更节省内存和 CPU,尤其是要串联的字符串数目特别多的时候。
搜索及排序切片的数组
标准库提供了 sort 包来实现常见的搜索和排序操作。可以使用 sort 包中的函数 func Ints(a []int) 来实现对 int 类型的切片排序。例如 sort.Ints(arri),其中变量 arri 就是需要被升序排序的数组或切片。为了检查某个数组是否已经被排序,可以通过函数 IntsAreSorted(a []int) bool 来检查,如果返回 true 则表示已经被排序。
类似的,可以使用函数 func Float64s(a []float64) 来排序 float64 的元素,或使用函数 func Strings(a []string) 排序字符串元素。
想要在数组或切片中搜索一个元素,该数组或切片必须先被排序(因为标准库的搜索算法使用的是二分法)。然后,就可以使用函数 func SearchInts(a []int, n int) int 进行搜索,并返回对应结果的索引值。
当然,还可以搜索 float64 和字符串:
func SearchFloat64s(a []float64, x float64) int
func SearchStrings(a []string, x string) int
字符串
字符串是一种值类型,且值不可变,即创建某个文本后无法再次修改这个文本的内容;更深入地讲,字符串是字节的定长数组。
Go 语言中的字符串是一个字节切片。把内容放在双引号””之间,可以创建一个字符串。由于字符串是一个字节切片,所以可以获取字符串的每一个字节。
字符串是 UTF-8 字符的一个序列(当字符为 ASCII 码时则占用 1 个字节,其它字符根据需要占用 2-4 个字节)。UTF-8 是被广泛使用的编码格式,是文本文件的标准编码,其它包括 XML 和 JSON 在内,也都使用该编码。由于该编码对占用字节长度的不定性,Go 中的字符串也可能根据需要占用 1 至 4 个字节。
因此,字符串的内容(纯字节)可以通过标准索引法来获取,在中括号 [] 内写入索引,索引从 0 开始计数:
- 字符串 str 的第 1 个字节:
str[0] - 第 i 个字节:
str[i - 1] - 最后 1 个字节:
str[len(str)-1]
但需要注意的是,这种转换方案只对纯 ASCII 码的字符串有效,对于其他编码,由于使用 UTF-8 编码,一些字符可能占用不止一个字节,这会导致获取单个字节打印出来的字符与实际不符,例子如下:
package main
import (
"fmt"
)
func printBytes(s string) {
for i:= 0; i < len(s); i++ {
fmt.Printf("%x ", s[i])
}
}
func printChars(s string) {
for i:= 0; i < len(s); i++ {
fmt.Printf("%c ",s[i])
}
}
func main() {
name := "Hello World"
printBytes(name)
fmt.Printf("\n")
printChars(name)
fmt.Printf("\n")
name = "Señor"
printBytes(name)
fmt.Printf("\n")
printChars(name)
}
上面打印的结果是:
48 65 6c 6c 6f 20 57 6f 72 6c 64
H e l l o W o r l d
53 65 c3 b1 6f 72
S e à ± o r
所以当需要使用遍历字符串的字符时,可以使用 rune ,trune 是Go 语言的内建类型,它也是 int32 的别称。在 Go 语言中,rune 表示一个代码点。代码点无论占用多少个字节,都可以用一个 rune 来表示。用 rune 来打印字符如下:
package main
import (
"fmt"
)
func printBytes(s string) {
for i:= 0; i < len(s); i++ {
fmt.Printf("%x ", s[i])
}
}
func printChars(s string) {
runes := []rune(s)
for i:= 0; i < len(runes); i++ {
fmt.Printf("%c ",runes[i])
}
}
func main() {
name := "Hello World"
printBytes(name)
fmt.Printf("\n")
printChars(name)
fmt.Printf("\n\n")
name = "Señor"
printBytes(name)
fmt.Printf("\n")
printChars(name)
}
另一种比较方便的方式是直接使用 range 遍历字符串。
字符串拼接
字符串拼接符 +
两个字符串 s1 和 s2 可以通过 s := s1 + s2 拼接在一起。
s2 追加在 s1 尾部并生成一个新的字符串 s。
你可以通过以下方式来对代码中多行的字符串进行拼接:
str := "Beginning of the string " +
"second part of the string"
由于编译器行尾自动补全分号的缘故,加号 + 必须放在第一行。
拼接的简写形式 += 也可以用于字符串:
s := "hel" + "lo,"
s += "world!"
fmt.Println(s) //输出 “hello, world!”
在循环中使用加号 + 拼接字符串并不是最高效的做法,更好的办法是使用函数 strings.Join(),最优的方式是使用字节缓冲(bytes.Buffer)拼接
String 操作相关 API
strings 包
strings 包定义了一些对字符串的操作。
前缀和后缀
HasPrefix 判断字符串 s 是否以 prefix 开头:
strings.HasPrefix(s, prefix string) bool
HasSuffix 判断字符串 s 是否以 suffix 结尾:
strings.HasSuffix(s, suffix string) bool
示例:
package main
import (
"fmt"
"strings"
)
func main() {
var str string = "This is an example of a string"
fmt.Printf("T/F? Does the string \"%s\" have prefix %s? ", str, "Th")
fmt.Printf("%t\n", strings.HasPrefix(str, "Th"))
}
输出:
T/F? Does the string "This is an example of a string" have prefix Th? true
这个例子同样演示了转义字符 \ 和格式化字符串的使用。
字符串包含关系
Contains 判断字符串 s 是否包含 substr:
strings.Contains(s, substr string) bool
判断子字符串或字符在父字符串中出现的位置(索引)
Index 返回字符串 str 在字符串 s 中的索引(str 的第一个字符的索引),-1 表示字符串 s 不包含字符串 str:
strings.Index(s, str string) int
LastIndex 返回字符串 str 在字符串 s 中最后出现位置的索引(str 的第一个字符的索引),-1 表示字符串 s 不包含字符串 str:
strings.LastIndex(s, str string) int
如果 ch 是非 ASCII 编码的字符,建议使用以下函数来对字符进行定位:
strings.IndexRune(s string, r rune) int
示例:
package main
import (
"fmt"
"strings"
)
func main() {
var str string = "Hi, I'm Marc, Hi."
fmt.Printf("The position of \"Marc\" is: ")
fmt.Printf("%d\n", strings.Index(str, "Marc"))
fmt.Printf("The position of the first instance of \"Hi\" is: ")
fmt.Printf("%d\n", strings.Index(str, "Hi"))
fmt.Printf("The position of the last instance of \"Hi\" is: ")
fmt.Printf("%d\n", strings.LastIndex(str, "Hi"))
fmt.Printf("The position of \"Burger\" is: ")
fmt.Printf("%d\n", strings.Index(str, "Burger"))
}
输出:
The position of "Marc" is: 8
The position of the first instance of "Hi" is: 0
The position of the last instance of "Hi" is: 14
The position of "Burger" is: -1
字符串替换
Replace 用于将字符串 str 中的前 n 个字符串 old 替换为字符串 new,并返回一个新的字符串,如果 n = -1 则替换所有字符串 old 为字符串 new:
strings.Replace(str, old, new, n) string
统计字符串出现次数
Count 用于计算字符串 str 在字符串 s 中出现的非重叠次数:
strings.Count(s, str string) int
示例:
package main
import (
"fmt"
"strings"
)
func main() {
var str string = "Hello, how is it going, Hugo?"
var manyG = "gggggggggg"
fmt.Printf("Number of H's in %s is: ", str)
fmt.Printf("%d\n", strings.Count(str, "H"))
fmt.Printf("Number of double g's in %s is: ", manyG)
fmt.Printf("%d\n", strings.Count(manyG, "gg"))
}
输出:
Number of H's in Hello, how is it going, Hugo? is: 2
Number of double g’s in gggggggggg is: 5
重复字符串
Repeat 用于重复拼接 count 次字符串 s 并返回一个新的字符串:
strings.Repeat(s, count int) string
示例:
package main
import (
"fmt"
"strings"
)
func main() {
var origS string = "Hi there! "
var newS string
newS = strings.Repeat(origS, 3)
fmt.Printf("The new repeated string is: %s\n", newS)
}
输出:
The new repeated string is: Hi there! Hi there! Hi there!
修改字符串大小写
ToLower 将字符串中的 Unicode 字符全部转换为相应的小写字符:
strings.ToLower(s) string
ToUpper 将字符串中的 Unicode 字符全部转换为相应的大写字符:
strings.ToUpper(s) string
示例:
package main
import (
"fmt"
"strings"
)
func main() {
var orig string = "Hey, how are you George?"
var lower string
var upper string
fmt.Printf("The original string is: %s\n", orig)
lower = strings.ToLower(orig)
fmt.Printf("The lowercase string is: %s\n", lower)
upper = strings.ToUpper(orig)
fmt.Printf("The uppercase string is: %s\n", upper)
}
输出:
The original string is: Hey, how are you George?
The lowercase string is: hey, how are you george?
The uppercase string is: HEY, HOW ARE YOU GEORGE?
修剪字符串
可以使用 strings.TrimSpace(s) 来剔除字符串开头和结尾的空白符号;如果想要剔除指定字符,则可以使用 strings.Trim(s, "cut") 来将开头和结尾的 cut 去除掉。该函数的第二个参数可以包含任何字符,如果只想剔除开头或者结尾的字符串,则可以使用 TrimLeft 或者 TrimRight 来实现。
分割字符串
strings.Fields(s) 利用空白作为分隔符将字符串分割为若干块,并返回一个 slice 。如果字符串只包含空白符号,返回一个长度为 0 的 slice 。
strings.Split(s, sep) 自定义分割符号对字符串分割,返回 slice 。
因为这 2 个函数都会返回 slice,所以习惯使用 for-range 循环来对其进行处理。
拼接 slice 到字符串
Join 用于将元素类型为 string 的 slice 使用分割符号来拼接组成一个字符串:
strings.Join(sl []string, sep string) string
示例:
package main
import (
"fmt"
"strings"
)
func main() {
str := "The quick brown fox jumps over the lazy dog"
sl := strings.Fields(str)
fmt.Printf("Splitted in slice: %v\n", sl)
for _, val := range sl {
fmt.Printf("%s - ", val)
}
fmt.Println()
str2 := "GO1|The ABC of Go|25"
sl2 := strings.Split(str2, "|")
fmt.Printf("Splitted in slice: %v\n", sl2)
for _, val := range sl2 {
fmt.Printf("%s - ", val)
}
fmt.Println()
str3 := strings.Join(sl2,";")
fmt.Printf("sl2 joined by ;: %s\n", str3)
}
输出:
Splitted in slice: [The quick brown fox jumps over the lazy dog]
The - quick - brown - fox - jumps - over - the - lazy - dog -
Splitted in slice: [GO1 The ABC of Go 25]
GO1 - The ABC of Go - 25 -
sl2 joined by ;: GO1;The ABC of Go;25
从字符串中读取内容
函数 strings.NewReader(str) 用于生成一个 Reader 并读取字符串中的内容,然后返回指向该 Reader 的指针,从其它类型读取内容的函数还有:
Read()从 [] byte 中读取内容。ReadByte()和ReadRune()从字符串中读取下一个 byte 或者 rune。
strconv 包
与字符串相关的类型转换都是通过 strconv 包实现的。
该包包含了一些变量用于获取程序运行的操作系统平台下 int 类型所占的位数,如:strconv.IntSize。
任何类型 T 转换为字符串总是成功的。
针对从数字类型转换到字符串,Go 提供了以下函数:
strconv.Itoa(i int) string返回数字 i 所表示的字符串类型的十进制数。strconv.FormatFloat(f float64, fmt byte, prec int, bitSize int) string将 64 位浮点型的数字转换为字符串,其中fmt表示格式(其值可以是'b'、'e'、'f'或'g'),prec表示精度,bitSize则使用 32 表示 float32,用 64 表示 float64。
将字符串转换为其它类型 tp 并不总是可能的,可能会在运行时抛出错误 parsing "…": invalid argument。
针对从字符串类型转换为数字类型,Go 提供了以下函数:
strconv.Atoi(s string) (i int, err error)将字符串转换为 int 型。strconv.ParseFloat(s string, bitSize int) (f float64, err error)将字符串转换为 float64 型。
利用多返回值的特性,这些函数会返回 2 个值,第 1 个是转换后的结果(如果转换成功),第 2 个是可能出现的错误,因此,我们一般使用以下形式来进行从字符串到其它类型的转换:
val, err = strconv.Atoi(s)
在下面这个示例中,忽略可能出现的转换错误:
示例:
package main
import (
"fmt"
"strconv"
)
func main() {
var orig string = "666"
var an int
var newS string
fmt.Printf("The size of ints is: %d\n", strconv.IntSize)
an, _ = strconv.Atoi(orig)
fmt.Printf("The integer is: %d\n", an)
an = an + 5
newS = strconv.Itoa(an)
fmt.Printf("The new string is: %s\n", newS)
}
输出:
64 位系统:
The size of ints is: 64
32 位系统:
The size of ints is: 32
The integer is: 666
The new string is: 671
字符串的内部结构
内存中,一个字符串实际上是一个双字结构,即一个指向实际数据的指针和记录字符串长度的整数。因为指针对用户来说是完全不可见,因此我们可以依旧把字符串看做是一个值类型,也就是一个字符数组。

映射
映射将键映射到值。
映射的零值为 nil 。nil 映射既没有键,也不能添加键。
在声明的时候不需要知道 map 的长度,map 是可以动态增长的。
make 函数会返回给定类型的映射,并将其初始化备用。
映射的文法与结构体相似,不过必须有键名。
若顶级类型只是一个类型名,可以在文法的元素中省略它。
package main
import "fmt"
type Vertex struct {
Lat, Long float64
}
var m = map[string]Vertex{
"Bell Labs": Vertex{
40.68433, -74.39967,
},
"Google": Vertex{
37.42202, -122.08408,
},
//也可以这样
"Bell Labs": {40.68433, -74.39967},
"Google": {37.42202, -122.08408},
}
func main() {
fmt.Println(m)
}
map 的初始化:var map1 = make(map[keytype]valuetype)。
或者简写为:map1 := make(map[keytype]valuetype)。
例如:mapCreated := make(map[string]float32),相当于:mapCreated := map[string]float32{}。
不要使用 new,永远用 make 来构造 map
注意 如果你错误的使用 new () 分配了一个引用对,你会获得一个空引用的指针,相当于声明了一个未初始化的变量并且取了它的地址:
mapCreated := new(map[string]float32)
接下来当调用:mapCreated["key1"] = 4.5 的时候,编译器会报错:
invalid operation: mapCreated["key1"] (index of type *map[string]float32).
map 容量
和数组不同,map 可以根据新增的 key-value 对动态的伸缩,因此它不存在固定长度或者最大限制。但是也可以选择标明 map 的初始容量 capacity,就像这样:make(map[keytype]valuetype, cap)。例如:
map2 := make(map[string]float32, 100)
当 map 增长到容量上限的时候,如果再增加新的 key-value 对,map 的大小会自动加 1。所以出于性能的考虑,对于大的 map 或者会快速扩张的 map,即使只是大概知道容量,也最好先标明。
修改映射
在映射 m 中插入或修改元素:
m[key] = elem
获取元素:
elem = m[key]
删除元素:
delete(m, key)
通过双赋值检测某个键是否存在:
elem, ok = m[key]
若 key 在 m 中,ok 为 true ;否则,ok 为 false。
若 key 不在映射中,那么 elem 是该映射元素类型的零值。
同样的,当从映射中读取某个不存在的键时,结果是映射的元素类型的零值。
注 :若 elem 或 ok 还未声明,你可以使用短变量声明:
elem, ok := m[key]
map 类型的切片
如果希望得到 map 类型的切片,我们必须使用两次 make() 函数,第一次分配切片,第二次分配切片中每个 map 元素
package main
import "fmt"
func main() {
// Version A:
items := make([]map[int]int, 5)
for i:= range items {
items[i] = make(map[int]int, 1)
items[i][1] = 2
}
fmt.Printf("Version A: Value of items: %v\n", items)
// Version B: NOT GOOD!
items2 := make([]map[int]int, 5)
for _, item := range items2 {
item = make(map[int]int, 1) // item is only a copy of the slice element.
item[1] = 2 // This 'item' will be lost on the next iteration.
}
fmt.Printf("Version B: Value of items: %v\n", items2)
}
Version A: Value of items: [map[1:2] map[1:2] map[1:2] map[1:2] map[1:2]]
Version B: Value of items: [map[] map[] map[] map[] map[]]
应当像 A 版本那样通过索引使用切片的 map 元素。在 B 版本中获得的项只是 map 值的一个拷贝而已,所以真正的 map 元素没有得到初始化。
遍历 map
可以使用 for 循环构造 map:
for key, value := range map1 {
...
}
第一个返回值 key 是 map 中的 key 值,第二个返回值则是该 key 对应的 value 值;这两个都是仅 for 循环内部可见的局部变量。其中第一个返回值 key 值是一个可选元素。如果你关心值,可以这么使用:
for _, value := range map1 {
...
}
如果只想获取 key,可以这么使用:
for key := range map1 {
fmt.Printf("key is: %d\n", key)
}
注意 map 不是按照 key 的顺序排列的,也不是按照 value 的序排列的。
结构体
一个结构体(struct)就是一组字段(field)。结构体字段使用点号来访问。
type关键字用于定义别名
package main
import "fmt"
type Vertex struct {
X int
Y int
}
func main() {
v := Vertex{1, 2}
v.X = 4
fmt.Println(v.X)
}
声明结构体有两种方式:
type T struct {a, b int}
//第一种方式
var s T
s.a = 5
s.b = 8
//第二种方式
var t *T
t = new(T)
使用 t := new(T),变量 t 是一个指向 T 的指针,此时结构体字段的值是它们所属类型的零值。
声明 var t T 也会给 t 分配内存,并零值化内存,但是这个时候 t 是类型 T。
在这两种方式中,t 通常被称做类型 T 的一个实例(instance)或对象(object)。
初始化结构体的方式有以下几种:
type Interval struct {
start int
end int
}
//可以在 Interval 前加 &
intr := Interval{0, 3} (A)
intr := Interval{end:5, start:1} (B)
intr := Interval{end:5} (C)
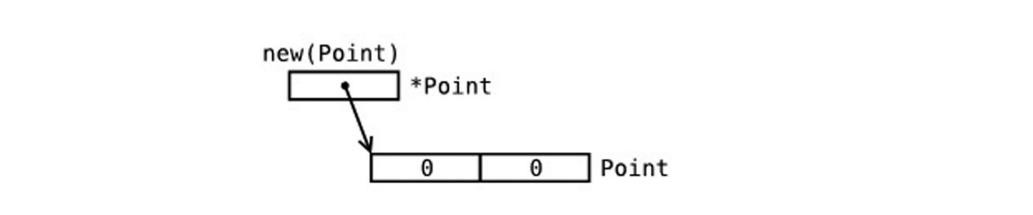
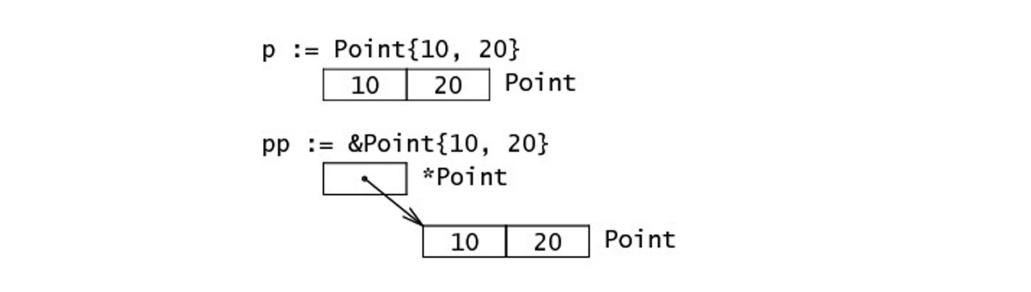
混合字面量语法(composite literal syntax)&struct1{a, b, c} 是一种简写,底层仍然会调用 new (),这里值的顺序必须按照字段顺序来写。表达式 new(Type) 和 &Type{} 是等价的。
使用 new 初始化:
作为结构体字面量初始化:
结构体指针
结构体字段可以通过结构体指针来访问。
如果我们有一个指向结构体的指针 p,那么可以通过 (*p).X 来访问其字段 X。语言也允许使用隐式间接引用,直接写 p.X 就可以。
package main
import "fmt"
type Vertex struct {
X int
Y int
}
func main() {
v := Vertex{1, 2}
p := &v
//表示的是(*p).X
p.X = 1e9
fmt.Println(v)
}
结构体文法
通过直接列出字段的值来新分配一个结构体。
使用 Name: 语法可以仅列出部分字段。(字段名的顺序无关。)
特殊的前缀 & 返回一个指向结构体的指针。
package main
import "fmt"
type Vertex struct {
X, Y int
}
var (
v1 = Vertex{1, 2} // 创建一个 Vertex 类型的结构体
v2 = Vertex{X: 1} // Y:0 被隐式地赋予
v3 = Vertex{} // X:0 Y:0
p = &Vertex{1, 2} // 创建一个 *Vertex 类型的结构体(指针)
)
func main() {
fmt.Println(v1, p, v2, v3)
}
匿名字段
当创建结构体时,字段可以只有类型,而没有字段名。这样的字段称为匿名字段(Anonymous Field)。
以下代码创建一个 Person 结构体,它含有两个匿名字段 string 和 int。
type Person struct {
string
int
}
接下来使用匿名字段来编写一个程序。
package main
import (
"fmt"
)
type Person struct {
string
int
}
func main() {
p := Person{"Naveen", 50}
fmt.Println(p)
}
在上面的程序中,结构体 Person 有两个匿名字段。p := Person{"Naveen", 50} 定义了一个 Person 类型的变量。该程序输出 {Naveen 50}。
虽然匿名字段没有名称,但其实匿名字段的名称就默认为它的类型。比如在上面的 Person 结构体里,虽说字段是匿名的,但 Go 默认这些字段名是它们各自的类型。所以 Person 结构体有两个名为 string 和 int 的字段。
package main
import (
"fmt"
)
type Person struct {
string
int
}
func main() {
var p1 Person
p1.string = "naveen"
p1.int = 50
fmt.Println(p1)
}
在上面程序的第 14 行和第 15 行,我们访问了 Person 结构体的匿名字段,我们把字段类型作为字段名,分别为 “string” 和 “int”。上面程序的输出如下:
{naveen 50}
结构体的内存布局
Go 语言中,结构体和它所包含的数据在内存中是以连续块的形式存在的,即使结构体中嵌套有其他的结构体,这在性能上带来了很大的优势。
type Rect1 struct {Min, Max Point }
type Rect2 struct {Min, Max *Point }
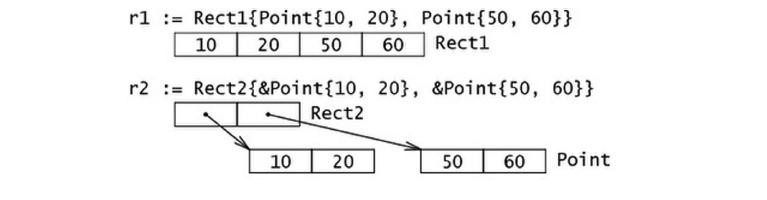
提升字段(Promoted Fields)
如果是结构体中有匿名的结构体类型字段,则该匿名结构体里的字段就称为提升字段。这是因为提升字段就像是属于外部结构体一样,可以用外部结构体直接访问。
type Address struct {
city, state string
}
type Person struct {
name string
age int
Address
}
在上面的代码片段中,Person 结构体有一个匿名字段 Address,而 Address 是一个结构体。现在结构体 Address 有 city 和 state 两个字段,访问这两个字段就像在 Person 里直接声明的一样,因此我们称之为提升字段。
package main
import (
"fmt"
)
type Address struct {
city, state string
}
type Person struct {
name string
age int
Address
}
func main() {
var p Person
p.name = "Naveen"
p.age = 50
p.Address = Address{
city: "Chicago",
state: "Illinois",
}
fmt.Println("Name:", p.name)
fmt.Println("Age:", p.age)
fmt.Println("City:", p.city) //city is promoted field
fmt.Println("State:", p.state) //state is promoted field
}
在上面代码中的第 26 行和第 27 行使用了语法 p.city 和 p.state,访问提升字段 city 和 state 就像它们是在结构体 p 中声明的一样。该程序会输出:
Name: Naveen
Age: 50
City: Chicago
State: Illinois
结构体相等性(Structs Equality)
结构体是值类型。如果它的每一个字段都是可比较的,则该结构体也是可比较的。如果两个结构体变量的对应字段相等,则这两个变量也是相等的。
package main
import (
"fmt"
)
type name struct {
firstName string
lastName string
}
func main() {
name1 := name{"Steve", "Jobs"}
name2 := name{"Steve", "Jobs"}
if name1 == name2 {
fmt.Println("name1 and name2 are equal")
} else {
fmt.Println("name1 and name2 are not equal")
}
name3 := name{firstName:"Steve", lastName:"Jobs"}
name4 := name{}
name4.firstName = "Steve"
if name3 == name4 {
fmt.Println("name3 and name4 are equal")
} else {
fmt.Println("name3 and name4 are not equal")
}
}
在上面的代码中,结构体类型 name 包含两个 string 类型。由于字符串是可比较的,因此可以比较两个 name 类型的结构体变量。
上面代码中 name1 和 name2 相等,而 name3 和 name4 不相等。该程序会输出:
name1 and name2 are equal
name3 and name4 are not equal
如果结构体包含不可比较的字段,则结构体变量也不可比较。
package main
import (
"fmt"
)
type image struct {
data map[int]int
}
func main() {
image1 := image{data: map[int]int{
0: 155,
}}
image2 := image{data: map[int]int{
0: 155,
}}
if image1 == image2 {
fmt.Println("image1 and image2 are equal")
}
}
在上面代码中,结构体类型 image 包含一个 map 类型的字段。由于 map 类型是不可比较的,因此 image1 和 image2 也不可比较。如果运行该程序,编译器会报错:main.go:18: invalid operation: image1 == image2 (struct containing map[int]int cannot be compared)。
递归结构体
结构体类型可以通过引用自身来定义。可以用于实现链表和树的结构。
链表
type Node struct {
data float64
su *Node
}

链表中的第一个元素叫 head,它指向第二个元素;最后一个元素叫 tail,它没有后继元素,所以它的 su 为 nil 值。当然真实的链接会有很多数据节点,并且链表可以动态增长或收缩。
同样地可以定义一个双向链表,它有一个前趋节点 pr 和一个后继节点 su:
type Node struct {
pr *Node
data float64
su *Node
}
二叉树
type Tree strcut {
le *Tree
data float64
ri *Tree
}
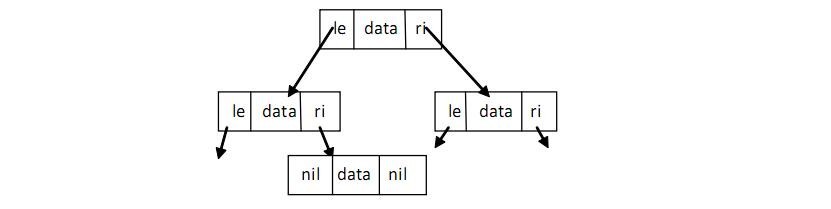
结构体工厂
Go 语言不支持面向对象编程语言中那样的构造子方法,但是可以很容易的在 Go 中实现 “构造子工厂” 方法。为了方便通常会为类型定义一个工厂,按惯例,工厂的名字以 new 或 New 开头。假设定义了如下的 File 结构体类型:
type File struct {
fd int // 文件描述符
name string // 文件名
}
下面是这个结构体类型对应的工厂方法,它返回一个指向结构体实例的指针:
func NewFile(fd int, name string) *File {
if fd < 0 {
return nil
}
return &File{fd, name}
}
然后这样调用它:
f := NewFile(10, "./test.txt")
在 Go 语言中常常像上面这样在工厂方法里使用初始化来简便的实现构造函数。
如果 File 是一个结构体类型,那么表达式 new(File) 和 &File{} 是等价的。
这可以和大多数面向对象编程语言中笨拙的初始化方式做个比较:File f = new File(...)。
可以说是工厂实例化了类型的一个对象,就像在基于类的 OO 语言中那样。
如果想知道结构体类型 T 的一个实例占用了多少内存,可以使用:size := unsafe.Sizeof(T{})。
如何强制使用工厂方法
通过应用可见性规则就可以禁止使用 new 函数,强制用户使用工厂方法,从而使类型变成私有的,就像在面向对象语言中那样。
type matrix struct {
...
}
func NewMatrix(params) *matrix {
m := new(matrix) // 初始化 m
return m
}
在其他包里使用工厂方法:
package main
import "matrix"
...
wrong := new(matrix.matrix) // 编译失败(matrix 是私有的)
right := matrix.NewMatrix(...) // 实例化 matrix 的唯一方式
map 和 struct vs new () 和 make ()
现在为止已经见到了可以使用 make() 的三种类型中的其中两个:
slices / maps / channels(后面)
下面的例子说明了在映射上使用 new 和 make 的区别以及可能发生的错误:
package main
type Foo map[string]string
type Bar struct {
thingOne string
thingTwo int
}
func main() {
// OK
y := new(Bar)
(*y).thingOne = "hello"
(*y).thingTwo = 1
// NOT OK
z := make(Bar) // 编译错误:cannot make type Bar
(*z).thingOne = "hello"
(*z).thingTwo = 1
// OK
x := make(Foo)
x["x"] = "goodbye"
x["y"] = "world"
// NOT OK
u := new(Foo)
(*u)["x"] = "goodbye" // 运行时错误!! panic: assignment to entry in nil map
(*u)["y"] = "world"
}
试图 make() 一个结构体变量,会引发一个编译错误,这还不是太糟糕,但是 new() 一个映射并试图使用数据填充它,将会引发运行时错误! 因为 new(Foo) 返回的是一个指向 nil 的指针,它尚未被分配内存。所以在使用 map 时要特别谨慎。
带标签的结构体
结构体中的字段除了有名字和类型外,还可以有一个可选的标签(tag):它是一个附属于字段的字符串,可以是文档或其他的重要标记。标签的内容不可以在一般的编程中使用,只有包 reflect 能获取它。如果变量是一个结构体类型,就可以通过 Field 来索引结构体的字段,然后就可以使用 Tag 属性。
package main
import (
"fmt"
"reflect"
)
type TagType struct { // tags
field1 bool "An important answer"
field2 string "The name of the thing"
field3 int "How much there are"
}
func main() {
tt := TagType{true, "Barak Obama", 1}
for i := 0; i < 3; i++ {
refTag(tt, i)
}
}
func refTag(tt TagType, ix int) {
ttType := reflect.TypeOf(tt)
ixField := ttType.Field(ix)
fmt.Printf("%v\n", ixField.Tag)
}
输出:
An important answer
The name of the thing
How much there are
流程控制语句
for
Go 只有一种循环结构:for 循环。
基本的 for 循环由三部分组成,它们用分号隔开:
- 初始化语句:在第一次迭代前执行
- 条件表达式:在每次迭代前求值
- 后置语句:在每次迭代的结尾执行
初始化语句通常为一句短变量声明,该变量声明仅在 for 语句的作用域中可见。
一旦条件表达式的布尔值为 false,循环迭代就会终止。
注意:Go 的 for 语句后面的三个构成部分外没有小括号, 大括号 { } 则是必须的。
package main
import "fmt"
func main() {
sum := 0
for i := 0; i < 10; i++ {
sum += i
}
fmt.Println(sum)
}
初始化语句和后置语句是可选的:即相当于 while 循环
package main
import "fmt"
func main() {
sum := 1
for ; sum < 1000; {
sum += sum
}
//可以写成
for sum < 100 {
//...
}
//无限循环
for {
//...
}
fmt.Println(sum)
}
if
同样不需要括号。
package main
import (
"fmt"
"math"
)
func sqrt(x float64) string {
if x < 0 {
return sqrt(-x) + "i"
}
return fmt.Sprint(math.Sqrt(x))
}
func main() {
fmt.Println(sqrt(2), sqrt(-4))
}
同 for 一样, if 语句可以在条件表达式前执行一个简单的语句,但是该语句声明的变量作用域仅在 if 和 else 之内。
package main
import (
"fmt"
"math"
)
func pow(x, n, lim float64) float64 {
//v 局部变量,只在if语句块中使用
if v := math.Pow(x, n); v < lim {
return v
//这一行中 else 与两个括号都必须在同一行,否则非法
} else {
//此处 v 也可以使用
}
//会出错
//return v
return lim;
}
func main() {
fmt.Println(
pow(3, 2, 10),
pow(3, 3, 20),
)
}
switch
switch 是编写一连串 if - else 语句的简便方法。它运行第一个值等于条件表达式的 case 语句。
Go 的 switch 语句类似于 C、C++、Java、JavaScript 和 PHP 中的,不过 Go 只运行选定的 case,而非之后所有的 case。 实际上,Go 自动提供了在这些语言中每个 case 后面所需的 break 语句。 除非以 fallthrough 语句结束,否则分支会自动终止。
package main
import (
"fmt"
"runtime"
)
func main() {
fmt.Print("Go runs on ")
switch os := runtime.GOOS; os {
case "darwin":
fmt.Println("OS X.")
case "linux":
fmt.Println("Linux.")
default:
// freebsd, openbsd,
// plan9, windows...
fmt.Printf("%s.\n", os)
}
}
没有条件的 switch 同 switch true 一样。这种形式能将一长串 if-then-else 写得更加清晰。
func main() {
t := time.Now()
switch {
case t.Hour() < 12:
fmt.Println("Good morning!")
case t.Hour() < 17:
fmt.Println("Good afternoon.")
default:
fmt.Println("Good evening.")
}
}
defer
defer 语句会将函数推迟到外层函数返回之后执行。
package main
import "fmt"
func main() {
defer fmt.Println("world")
fmt.Println("hello")
}
推迟调用的函数其参数会立即求值,但直到外层函数返回前该函数都不会被调用:
package main
import (
"fmt"
)
func printA(a int) {
fmt.Println("value of a in deferred function", a)
}
func main() {
a := 5
defer printA(a)
a = 10
fmt.Println("value of a before deferred function call", a)
}
在上面的程序里,a 的初始值为 5。在执行 defer 语句的时候,由于 a 等于 5,因此延迟函数 printA 的实参也等于 5。接着在将 a 的值修改为 10。下一行会打印出 a 的值。该程序输出:
value of a before deferred function call 10
value of a in deferred function 5
从上面的输出,可以看出,在调用了 defer 语句后,虽然将 a 修改为 10,但调用延迟函数 printA(a)后,仍然打印的是 5。
推迟的函数调用会被压入一个栈中。当外层函数返回时,被推迟的函数会按照后进先出的顺序调用。
package main
import "fmt"
func main() {
fmt.Println("counting")
for i := 0; i < 10; i++ {
defer fmt.Println(i)
}
fmt.Println("done")
}
方法
Go 没有类。不过可以为结构体类型定义方法。
方法就是一类带特殊的 接收者 参数的函数。
接收者类型可以是(几乎)任何类型,不仅仅是结构体类型:任何类型都可以有方法,甚至可以是函数类型,可以是 int、bool、string 或数组的别名类型。但是接收者不能是一个接口类型,因为接口是一个抽象定义,但是方法却是具体实现;如果这样做会引发一个编译错误:invalid receiver type…。
最后接收者不能是一个指针类型,但是它可以是任何其他允许类型的指针。
方法接收者在它自己的参数列表内,位于 func 关键字和方法名之间。
在此例中,Abs 方法拥有一个名为 v,类型为 Vertex 的接收者。
type Vertex struct {
X, Y float64
}
func (v Vertex) Abs() float64 {
return math.Sqrt(v.X*v.X + v.Y*v.Y)
}
func main() {
v := Vertex{3, 4}
fmt.Println(v.Abs())
}
方法只是个带接收者参数的函数。
也可以为非结构体类型声明方法。
在此例中,可以看到了一个带 Abs 方法的数值类型 MyFloat。
只能为在同一包内定义的类型的接收者声明方法,而不能为其它包内定义的类型(包括 int 之类的内建类型)的接收者声明方法。
(译注:就是接收者的类型定义和方法声明必须在同一包内;不能为内建类型声明方法。)
package main
import (
"fmt"
"math"
)
type MyFloat float64
func (f MyFloat) Abs() float64 {
if f < 0 {
return float64(-f)
}
return float64(f)
}
func main() {
f := MyFloat(-math.Sqrt2)
fmt.Println(f.Abs())
}
指针接收者
可以为指针接收者声明方法。
这意味着对于某类型 T,接收者的类型可以用 *T 的文法。(此外,T 不能是像 *int 这样的指针。)
例如,这里为 *Vertex 定义了 Scale 方法。
指针接收者的方法可以修改接收者指向的值(就像 Scale 在这做的)。由于方法经常需要修改它的接收者,指针接收者比值接收者更常用。
若使用值接收者,那么 Scale 方法会对原始 Vertex 值的副本进行操作,不会改变原始 Vertes 的值。(对于函数的其它参数也是如此。)采用指针接收者则会直接对原始数据进行修改。 Scale 方法必须用指针接受者来更改 main 函数中声明的 Vertex 的值。
package main
import (
"fmt"
"math"
)
type Vertex struct {
X, Y float64
}
func (v Vertex) Abs() float64 {
return math.Sqrt(v.X*v.X + v.Y*v.Y)
}
//如果把 * 号去掉则只是修改副本,打印出来还是5
func (v *Vertex) Scale(f float64) {
v.X = v.X * f
v.Y = v.Y * f
}
func main() {
v := Vertex{3, 4}
v.Scale(10)
fmt.Println(v.Abs())
}
带指针参数的函数和指针接收者的方法对比
带指针参数的函数必须接受一个指针:
func Scale(v *Vertex, f float64) {
v.X = v.X * f
v.Y = v.Y * f
}
var v Vertex
ScaleFunc(v, 5) // 编译错误!
ScaleFunc(&v, 5) // OK
而以指针为接收者的方法被调用时,接收者既能为值又能为指针:
func (v *Vertex) Scale(f float64) {
v.X = v.X * f
v.Y = v.Y * f
}
var v Vertex
v.Scale(5) // OK
p := &v
p.Scale(10) // OK
对于语句 v.Scale(5),即便 v 是个值而非指针,带指针接收者的方法也能被直接调用。 也就是说,由于 Scale 方法有一个指针接收者,为方便起见,Go 会将语句 v.Scale(5) 解释为 (&v).Scale(5)(也就是说自动转换)。
package main
import "fmt"
type Vertex struct {
X, Y float64
}
func (v *Vertex) Scale(f float64) {
v.X = v.X * f
v.Y = v.Y * f
}
func ScaleFunc(v *Vertex, f float64) {
v.X = v.X * f
v.Y = v.Y * f
}
func main() {
v := Vertex{3, 4}
v.Scale(2)
ScaleFunc(&v, 10)
//此处已经使用了指针
p := &Vertex{3, 4}
p.Scale(2)
ScaleFunc(p, 10)
fmt.Println(v, p)
}
同样的,对于下面的代码示例:
package main
import (
"fmt"
"math"
)
type Vertex struct {
X, Y float64
}
func (v Vertex) Abs() float64 {
return math.Sqrt(v.X*v.X + v.Y*v.Y)
}
func AbsFunc(v Vertex) float64 {
return math.Sqrt(v.X*v.X + v.Y*v.Y)
}
func main() {
v := Vertex{3, 4}
fmt.Println(v.Abs())
fmt.Println(AbsFunc(v))
p := &Vertex{4, 3}
fmt.Println(p.Abs())
fmt.Println(AbsFunc(*p))
}
接受一个值作为参数的函数必须接受一个指定类型的值:
var v Vertex
fmt.Println(AbsFunc(v)) // OK
fmt.Println(AbsFunc(&v)) // 编译错误!
而以值为接收者的方法被调用时,接收者既能为值又能为指针:
var v Vertex
fmt.Println(v.Abs()) // OK
p := &v
fmt.Println(p.Abs()) // OK
这种情况下,方法调用 p.Abs() 会被解释为 (*p).Abs()。
选择指针作为接受者的好处
使用指针接收者的原因有二:
首先,方法能够修改其接收者指向的值。
其次,这样可以避免在每次调用方法时复制该值。若值的类型为大型结构体时,这样做会更加高效。
通常来说,所有给定类型的方法都应该有值或指针接收者,但并不应该二者混用。
方法的内嵌
当一个匿名类型被内嵌在结构体中时,匿名类型的可见方法也同样被内嵌,这在效果上等同于外层类型继承了这些方法:将父类型放在子类型中来实现亚型。这个机制提供了一种简单的方式来模拟经典面向对象语言中的子类和继承相关的效果,也类似 Ruby 中的混入(mixin)。
假定有一个 Engine 接口类型,一个 Car 结构体类型,它包含一个 Engine 类型的匿名字段:
type Engine interface {
Start()
Stop()
}
type Car struct {
Engine
}
可以构建如下的代码:
func (c *Car) GoToWorkIn() {
// get in car
c.Start()
// drive to work
c.Stop()
// get out of car
}
下面的例子它展示了内嵌结构体上的方法可以直接在外层类型的实例上调用:
package main
import (
"fmt"
"math"
)
type Point struct {
x, y float64
}
func (p *Point) Abs() float64 {
return math.Sqrt(p.x*p.x + p.y*p.y)
}
type NamedPoint struct {
Point
name string
}
func main() {
n := &NamedPoint{Point{3, 4}, "Pythagoras"}
fmt.Println(n.Abs()) // 打印5
}
内嵌将一个已存在类型的字段和方法注入到了另一个类型里:匿名字段上的方法 “晋升” 成为了外层类型的方法。当然类型可以有只作用于本身实例而不作用于内嵌 “父” 类型上的方法,
可以覆写方法(像字段一样):和内嵌类型方法具有同样名字的外层类型的方法会覆写内嵌类型对应的方法。
如下所示:
func (n *NamedPoint) Abs() float64 {
return n.Point.Abs() * 100.
}
现在 fmt.Println(n.Abs()) 会打印 500。
因为一个结构体可以嵌入多个匿名类型,所以实际上我们可以有一个简单版本的多重继承,就像:type Child struct { Father; Mother}。在第 10.6.7 节中会进一步讨论这个问题。
结构体内嵌和自己在同一个包中的结构体时,可以彼此访问对方所有的字段和方法。
类型的 String() 方法和格式化描述符
当定义了一个有很多方法的类型时,可能会使用 String() 方法来定制类型的字符串形式的输出,换句话说:一种可阅读性和打印性的输出。如果类型定义了 String() 方法,它会被用在 fmt.Printf() 中生成默认的输出:等同于使用格式化描述符 %v 产生的输出。还有 fmt.Print() 和 fmt.Println() 也会自动使用 String() 方法。
示例:
package main
import (
"fmt"
"strconv"
)
type TwoInts struct {
a int
b int
}
func main() {
two1 := new(TwoInts)
two1.a = 12
two1.b = 10
fmt.Printf("two1 is: %v\n", two1)
fmt.Println("two1 is:", two1)
fmt.Printf("two1 is: %T\n", two1)
fmt.Printf("two1 is: %#v\n", two1)
}
func (tn *TwoInts) String() string {
return "(" + strconv.Itoa(tn.a) + "/" + strconv.Itoa(tn.b) + ")"
}
输出:
two1 is: (12/10)
two1 is: (12/10)
two1 is: *main.TwoInts
two1 is: &main.TwoInts{a:12, b:10}
当广泛使用一个自定义类型时,最好为它定义 String() 方法。从上面的例子也可以看到,格式化描述符 %T 会给出类型的完全规格,%#v 会给出实例的完整输出,包括它的字段(在程序自动生成 Go 代码时也很有用)。
备注
不要在 String() 方法里面调用涉及 String() 方法的方法,它会导致意料之外的错误,比如下面的例子,它导致了一个无限迭代(递归)调用(TT.String() 调用 fmt.Sprintf,而 fmt.Sprintf 又会反过来调用 TT.String()…),很快就会导致内存溢出:
type TT float64
func (t TT) String() string {
return fmt.Sprintf("%v", t)
}
t. String()
垃圾回收和 SetFinalizer
Go 开发者不需要写代码来释放程序中不再使用的变量和结构占用的内存,在 Go 运行时中有一个独立的进程,即垃圾收集器(GC),会处理这些事情,它搜索不再使用的变量然后释放它们的内存。可以通过 runtime 包访问 GC 进程。
通过调用 runtime.GC() 函数可以显式的触发 GC,但这只在某些罕见的场景下才有用,比如当内存资源不足时调用 runtime.GC(),它会在此函数执行的点上立即释放一大片内存,此时程序可能会有短时的性能下降(因为 GC 进程在执行)。
如果想知道当前的内存状态,可以使用:
// fmt.Printf("%d\n", runtime.MemStats.Alloc/1024)
// 此处代码在 Go 1.5.1下不再有效,更正为
var m runtime.MemStats
runtime.ReadMemStats(&m)
fmt.Printf("%d Kb\n", m.Alloc / 1024)
上面的程序会给出已分配内存的总量,单位是 Kb。
如果需要在一个对象 obj 被从内存移除前执行一些特殊操作,比如写到日志文件中,可以通过如下方式调用函数来实现:
runtime.SetFinalizer(obj, func(obj *typeObj))
func(obj *typeObj) 需要一个 typeObj 类型的指针参数 obj,特殊操作会在它上面执行。func 也可以是一个匿名函数。
在对象被 GC 进程选中并从内存中移除以前,SetFinalizer 都不会执行,即使程序正常结束或者发生错误。
接口
接口类型是由一组方法签名定义的集合。
接口类型的变量可以保存任何实现了这些方法的值。
(按照约定,只包含一个方法的)接口的名字由方法名加 [e]r 后缀组成,例如 Printer、Reader、Writer、Logger、Converter 等等。还有一些不常用的方式(当后缀 er 不合适时),比如 Recoverable,此时接口名以 able 结尾,或者以 I 开头(像 .NET 或 Java 中那样)。
注意: 示例代码存在一个错误。由于 Abs 方法只为 *Vertex (指针类型)定义,因此 Vertex(值类型)并未实现 Abser。
package main
import (
"fmt"
"math"
)
type Abser interface {
Abs() float64
}
func main() {
var a Abser
f := MyFloat(-math.Sqrt2)
v := Vertex{3, 4}
a = f // a MyFloat 实现了 Abser
a = &v // a *Vertex 实现了 Abser
// 下面一行,v 是一个 Vertex(而不是 *Vertex)
// 所以没有实现 Abser,会报错
a = v
fmt.Println(a.Abs())
}
type MyFloat float64
func (f MyFloat) Abs() float64 {
if f < 0 {
return float64(-f)
}
return float64(f)
}
type Vertex struct {
X, Y float64
}
func (v *Vertex) Abs() float64 {
return math.Sqrt(v.X*v.X + v.Y*v.Y)
}
接口的隐式实现
类型通过实现一个接口的所有方法来实现该接口。既然无需专门显式声明,也就没有“implements”关键字。
隐式接口从接口的实现中解耦了定义,这样接口的实现可以出现在任何包中,无需提前准备。
因此,也就无需在每一个实现上增加新的接口名称,这样同时也鼓励了明确的接口定义。
package main
import "fmt"
type I interface {
M()
}
type T struct {
S string
}
// 此方法表示类型 T 实现了接口 I,但我们无需显式声明此事。
func (t T) M() {
fmt.Println(t.S)
}
func main() {
var i I = T{"hello"}
i.M()
}
接口嵌套接口
一个接口可以包含一个或多个其他的接口,这相当于直接将这些内嵌接口的方法列举在外层接口中一样。
比如接口 File 包含了 ReadWrite 和 Lock 的所有方法,它还额外有一个 Close() 方法。
type ReadWrite interface {
Read(b Buffer) bool
Write(b Buffer) bool
}
type Lock interface {
Lock()
Unlock()
}
type File interface {
ReadWrite
Lock
Close()
}
接口值
接口也是值。它们可以像其它值一样传递。
接口值可以用作函数的参数或返回值。
在内部,接口值可以看做包含值和具体类型的元组:
(value, type)
接口值保存了一个具体底层类型的具体值。
接口值调用方法时会执行其底层类型的同名方法。
package main
import (
"fmt"
"math"
)
type I interface {
M()
}
type T struct {
S string
}
func (t *T) M() {
fmt.Println(t.S)
}
type F float64
func (f F) M() {
fmt.Println(f)
}
func main() {
var i I
i = &T{"Hello"}
//(&{Hello}, *main.T)
describe(i)
i.M()
i = F math.Pi
//(3.141592653589793, main.F)
describe(i)
i.M()
}
func describe(i I) {
fmt.Printf("(%v, %T)\n", i, i)
}
底层值(调用接口方法的变量)为 nil 的接口值
即便接口内的具体值为 nil,方法仍然会被 nil 接收者调用。
在一些语言中,这会触发一个空指针异常,但在 Go 中通常会写一些方法来优雅地处理它(如本例中的 M 方法)。
注意: 保存了 nil 具体值的接口其自身并不为 nil。
package main
import "fmt"
type I interface {
M()
}
type T struct {
S string
}
func (t *T) M() {
if t == nil {
fmt.Println("<nil>")
return
}
fmt.Println(t.S)
}
func main() {
var i I
var t *T
i = t
//(<nil>, *main.T)
describe(i)
i.M()
i = &T{"hello"}
//(&{hello}, *main.T)
describe(i)
i.M()
}
func describe(i I) {
fmt.Printf("(%v, %T)\n", i, i)
}
nil 接口值
nil 接口值既不保存值也不保存具体类型。
为 nil 接口调用方法会产生运行时错误,因为接口的元组内并未包含能够指明该调用哪个具体方法的类型。
package main
import "fmt"
type I interface {
M()
}
func main() {
var i I
//(<nil>, <nil>)
describe(i)
//会报错
i.M()
}
func describe(i I) {
fmt.Printf("(%v, %T)\n", i, i)
}
空接口
指定了零个方法的接口值被称为空接口:
interface{}
空接口可保存任何类型的值。(因为每个类型都至少实现了零个方法。)
空接口被用来处理未知类型的值。例如,fmt.Print 可接受类型为 interface{} 的任意数量的参数。
每个 interface {} 变量在内存中占据两个字长:一个用来存储它包含的类型,另一个用来存储它包含的数据或者指向数据的指针。
package main
import "fmt"
func main() {
var i interface{}
describe(i)
i = 42
describe(i)
i = "hello"
describe(i)
}
func describe(i interface{}) {
fmt.Printf("(%v, %T)\n", i, i)
}
类型断言
一个接口类型的变量 varI 中可以包含任何类型的值,必须有一种方式来检测它的动态类型,即运行时在变量中存储的值的实际类型。类型断言提供了访问接口值底层具体值的方式。
t := i.(T)
该语句断言接口值 i 保存了具体类型 T,并将其底层类型为 T 的值赋予变量 t。
若 i 并未保存 T 类型的值,该语句就会触发一个恐慌。
为了判断一个接口值是否保存了一个特定的类型,类型断言可返回两个值:其底层值以及一个报告断言是否成功的布尔值。
t, ok := i.(T)
若 i 保存了一个 T,那么 t 将会是其底层值,而 ok 为 true。
否则,ok 将为 false 而 t 将为 T 类型的零值,程序并不会产生恐慌。
请注意这种语法和读取一个映射时的相同之处。
package main
import "fmt"
func main() {
var i interface{} = "hello"
s := i.(string)
fmt.Println(s)
s, ok := i.(string)
fmt.Println(s, ok)
f, ok := i.(float64)
fmt.Println(f, ok)
f = i.(float64) // 报错(panic)
fmt.Println(f)
}
hello
hello true
0 false
panic: interface conversion: interface {} is string, not float64
类型选择
类型选择是一种按顺序从几个类型断言中选择分支的结构。
类型选择与一般的 switch 语句相似,不过类型选择中的 case 为类型(而非值), 它们针对给定接口值所存储的值的类型进行比较。
switch v := i.(type) {
case T:
// v 的类型为 T
case S:
// v 的类型为 S
default:
// 没有匹配,v 与 i 的类型相同
}
类型选择中的声明与类型断言 i.(T) 的语法相同,只是具体类型 T 被替换成了关键字 type。
此选择语句判断接口值 i 保存的值类型是 T 还是 S。在 T 或 S 的情况下,变量 v 会分别按 T 或 S 类型保存 i 拥有的值。在默认(即没有匹配)的情况下,变量 v 与 i 的接口类型和值相同。
接口实现中的指针接受者与值接受者
package main
import "fmt"
type Describer interface {
Describe()
}
type Person struct {
name string
age int
}
func (p Person) Describe() { // 使用值接受者实现
fmt.Printf("%s is %d years old\n", p.name, p.age)
}
type Address struct {
state string
country string
}
func (a *Address) Describe() { // 使用指针接受者实现
fmt.Printf("State %s Country %s", a.state, a.country)
}
func main() {
var d1 Describer
p1 := Person{"Sam", 25}
d1 = p1
d1.Describe()
p2 := Person{"James", 32}
d1 = &p2
d1.Describe()
var d2 Describer
a := Address{"Washington", "USA"}
/* 如果下面一行取消注释会导致编译错误:
cannot use a (type Address) as type Describer
in assignment: Address does not implement
Describer (Describe method has pointer
receiver)
*/
//d2 = a
d2 = &a // 这是合法的
// 因为在第 22 行,Address 类型的指针实现了 Describer 接口
d2.Describe()
}
对于使用指针接受者的方法,用一个指针或者一个可取得地址的值来调用都是合法的。但接口中存储的具体值(Concrete Value)并不能取到地址,因此在上面的例子中,对于编译器无法自动获取 a 的地址,于是程序报错。
总结
在接口上调用方法时,必须有和方法定义时相同的接收者类型或者是可以从具体类型 P 直接可以辨识的:
- 指针方法可以通过指针调用
- 值方法可以通过值调用
- 接收者是值的方法可以通过指针调用,因为指针会首先被解引用
- 接收者是指针的方法不可以通过值调用,因为存储在接口中的值没有地址
将一个值赋值给一个接口时,编译器会确保所有可能的接口方法都可以在此值上被调用,因此不正确的赋值在编译期就会失败。
译注
Go 语言规范定义了接口方法集的调用规则:
- 类型 *T 的可调用方法集包含接受者为 *T 或 T 的所有方法集
- 类型 T 的可调用方法集包含接受者为 T 的所有方法
- 类型 T 的可调用方法集不包含接受者为 *T 的方法
常用接口方法
Stringer
type Stringer interface {
String() string
}
Stringer 是一个可以用字符串描述自己的类型。fmt 包(还有很多包)都通过此接口来打印值。
package main
import "fmt"
type Person struct {
Name string
Age int
}
func (p Person) String() string {
return fmt.Sprintf("%v (%v years)", p.Name, p.Age)
}
func main() {
a := Person{"Arthur Dent", 42}
z := Person{"Zaphod Beeblebrox", 9001}
fmt.Println(a, z)
}
Error 错误
Go 程序使用 error 值来表示错误状态。
与 fmt.Stringer 类似,error 类型是一个内建接口:
type error interface {
Error() string
}
(与 fmt.Stringer 类似,fmt 包在打印值时也会满足 error。)
通常函数会返回一个 error 值,调用的它的代码应当判断这个错误是否等于 nil 来进行错误处理。
i, err := strconv.Atoi("42")
if err != nil {
fmt.Printf("couldn't convert number: %v\n", err)
returnf
}
fmt.Println("Converted integer:", i)
error 为 nil 时表示成功;非 nil 的 error 表示失败。
Reader 接口
io 包指定了 io.Reader 接口,它表示从数据流的末尾进行读取。
Go 标准库包含了该接口的许多实现,包括文件、网络连接、压缩和加密等等。
io.Reader 接口有一个 Read 方法:
func (T) Read(b []byte) (n int, err error)
Read 用数据填充给定的字节切片并返回填充的字节数和错误值。在遇到数据流的结尾时,它会返回一个 io.EOF 错误。
示例代码创建了一个 strings.Reader 并以每次 8 字节的速度读取它的输出。
package main
import (
"fmt"
"io"
"strings"
)
func main() {
r := strings.NewReader("Hello, Reader!")
b := make([]byte, 8)
for {
n, err := r.Read(b)
fmt.Printf("n = %v err = %v b = %v\n", n, err, b)
fmt.Printf("b[:n] = %q\n", b[:n])
if err == io.EOF {
break
}
}
}
n = 8 err = <nil> b = [72 101 108 108 111 44 32 82]
b[:n] = "Hello, R"
n = 6 err = <nil> b = [101 97 100 101 114 33 32 82]
b[:n] = "eader!"
n = 0 err = EOF b = [101 97 100 101 114 33 32 82]
b[:n] = ""
图像 image
image 包定义了 Image 接口:
package image
type Image interface {
ColorModel() color.Model
Bounds() Rectangle
At(x, y int) color.Color
}
注意: Bounds 方法的返回值 Rectangle 实际上是一个 image.Rectangle,它在 image 包中声明。
color.Color 和 color.Model 类型也是接口,但是通常因为直接使用预定义的实现 image.RGBA 和 image.RGBAModel 而被忽视了。这些接口和类型由 image/color 包定义。
反射
反射是用程序检查其所拥有的结构,尤其是类型的一种能力;反射可以在运行时检查类型和变量,例如它的大小、方法和动态的调用这些方法。这对于没有源代码的包尤其有用。
变量的最基本信息就是类型和值:反射包的 Type 用来表示一个 Go 类型,反射包的 Value 为 Go 值提供了反射接口。
两个简单的函数,reflect.TypeOf 和 reflect.ValueOf,返回被检查对象的类型和值。例如,x 被定义为:var x float64 = 3.4,那么 reflect.TypeOf(x) 返回 float64,reflect.ValueOf(x) 返回 3.4。
实际上,反射是通过检查一个接口的值,变量首先被转换成空接口。这从下面两个函数签名能够很明显的看出来:
func TypeOf(i interface{}) Type
func ValueOf(i interface{}) Value
接口的值包含一个 type 和 value。
反射可以从接口值反射到对象,也可以从对象反射回接口值。
此外,reflect包中还有一个重要的类型:Kind。
package main
import (
"fmt"
"reflect"
)
type order struct {
ordId int
customerId int
}
func createQuery(q interface{}) {
t := reflect.TypeOf(q)
k := t.Kind()
fmt.Println("Type ", t) //Type main.order
fmt.Println("Kind ", k) //Kind struct
}
func main() {
o := order{
ordId: 456,
customerId: 56,
}
createQuery(o)
}
Type 表示 interface{} 的实际类型(在这里是 main.Order),而 Kind 表示该类型的特定类别(在这里是 struct)。
对于 float64 类型的变量 x,如果 v:=reflect.ValueOf(x),那么 v.Kind() 返回 reflect.Float64 ,所以下面的表达式是 truev.Kind() == reflect.Float64
Kind 总是返回底层类型:
type MyInt int
var m MyInt = 5
v := reflect.ValueOf(m)
方法 v.Kind() 返回 reflect.Int。
变量 v 的 Interface() 方法可以得到还原(接口)值,所以可以这样打印 v 的值:fmt.Println(v.Interface())
reflect.Type 和 reflect.Value 都有许多方法用于检查和操作它们。一个重要的例子是 Value 有一个 Type 方法返回 reflect.Value 的 Type。另一个是 Type 和 Value 都有 Kind 方法返回一个常量来表示类型:Uint、Float64、Slice 等等。同样 Value 有叫做 Int 和 Float 的方法可以获取存储在内部的值(跟 int64 和 float64 一样)
const (
Invalid Kind = iota
Bool
Int
Int8
Int16
Int32
Int64
Uint
Uint8
Uint16
Uint32
Uint64
Uintptr
Float32
Float64
Complex64
Complex128
Array
Chan
Func
Interface
Map
Ptr
Slice
String
Struct
UnsafePointer
)
下面的例子使用 Int() 和 String() 将取的 reflect.Value 转换为相应的内部值类型
package main
import (
"fmt"
"reflect"
)
func main() {
a := 56
//reflect.value -> int64
x := reflect.ValueOf(a).Int()
fmt.Printf("type:%T value:%v\n", x, x)
b := "Naveen"
//reflect.value -> string
y := reflect.ValueOf(b).String()
fmt.Printf("type:%T value:%v\n", y, y)
}
示例代码:
// blog: Laws of Reflection
package main
import (
"fmt"
"reflect"
)
func main() {
var x float64 = 3.4
fmt.Println("type:", reflect.TypeOf(x))
v := reflect.ValueOf(x)
fmt.Println("value:", v)
fmt.Println("type:", v.Type())
fmt.Println("kind:", v.Kind())
fmt.Println("value:", v.Float())
fmt.Println(v.Interface())
fmt.Printf("value is %5.2e\n", v.Interface())
y := v.Interface().(float64)
fmt.Println(y)
}
输出:
type: float64
value: 3.4
type: float64
kind: float64
value: 3.4
3.4
value is 3.40e+00
3.4
x 是一个 float64 类型的值,reflect.ValueOf(x).Float() 返回这个 float64 类型的实际值;同样的适用于 Int(), Bool(), Complex(), String()
通过反射修改 (设置) 值
假设要把 x 的值改为 3.1415。Value 有一些方法可以完成这个任务,但是必须小心使用:v.SetFloat(3.1415)。
这将产生一个错误:reflect.Value.SetFloat using unaddressable value。
问题的原因是 v 不是可设置的(这里并不是说值不可寻址)。是否可设置是 Value 的一个属性,并且不是所有的反射值都有这个属性:可以使用 CanSet() 方法测试是否可设置。
在例子中可以看到 v.CanSet() 返回 false: settability of v: false
当 v := reflect.ValueOf(x) 函数通过传递一个 x 拷贝创建了 v,那么 v 的改变并不能更改原始的 x。要想 v 的更改能作用到 x,那就必须传递 x 的地址 v = reflect.ValueOf(&x)。
通过 Type () 我们看到 v 现在的类型是 *float64 并且仍然是不可设置的。
要想让其可设置我们需要使用 Elem() 函数,这间接的使用指针:v = v.Elem()
现在 v.CanSet() 返回 true 并且 v.SetFloat(3.1415) 设置成功了!
示例:
package main
import (
"fmt"
"reflect"
)
func main() {
var x float64 = 3.4
v := reflect.ValueOf(x)
// setting a value:
// v.SetFloat(3.1415) // Error: will panic: reflect.Value.SetFloat using unaddressable value
fmt.Println("settability of v:", v.CanSet())
v = reflect.ValueOf(&x) // Note: take the address of x.
fmt.Println("type of v:", v.Type())
fmt.Println("settability of v:", v.CanSet())
v = v.Elem()
fmt.Println("The Elem of v is: ", v)
fmt.Println("settability of v:", v.CanSet())
v.SetFloat(3.1415) // this works!
fmt.Println(v.Interface())
fmt.Println(v)
}
输出:
settability of v: false
type of v: *float64
settability of v: false
The Elem of v is: <float64 Value>
settability of v: true
3.1415
<float64 Value>
反射中有些内容是需要用地址去改变它的状态的。
反射结构体
有些时候需要反射一个结构体类型。NumField() 方法返回结构体内的字段数量;通过一个 for 循环用索引取得每个字段的值 Field(i)。
同样能够调用签名在结构体上的方法,例如,使用索引 n 来调用:Method(n).Call(nil)。
示例:
package main
import (
"fmt"
"reflect"
)
type NotknownType struct {
s1, s2, s3 string
}
func (n NotknownType) String() string {
return n.s1 + " - " + n.s2 + " - " + n.s3
}
// variable to investigate:
var secret interface{} = NotknownType{"Ada", "Go", "Oberon"}
func main() {
value := reflect.ValueOf(secret) // <main.NotknownType Value>
typ := reflect.TypeOf(secret) // main.NotknownType
// alternative:
//typ := value.Type() // main.NotknownType
fmt.Println(typ)
knd := value.Kind() // struct
fmt.Println(knd)
// iterate through the fields of the struct:
for i := 0; i < value.NumField(); i++ {
fmt.Printf("Field %d: %v\n", i, value.Field(i))
// error: panic: reflect.Value.SetString using value obtained using unexported field
//value.Field(i).SetString("C#")
}
// call the first method, which is String():
results := value.Method(0).Call(nil)
fmt.Println(results) // [Ada - Go - Oberon]
}
输出:
main.NotknownType
struct
Field 0: Ada
Field 1: Go
Field 2: Oberon
[Ada - Go - Oberon]
但是如果尝试更改一个值,会得到一个错误:
panic: reflect.Value.SetString using value obtained using unexported field
这是因为结构体中只有被导出字段(首字母大写)才是可设置的;来看下面的例子:
示例:
package main
import (
"fmt"
"reflect"
)
type T struct {
A int
B string
}
func main() {
t := T{23, "skidoo"}
s := reflect.ValueOf(&t).Elem()
typeOfT := s.Type()
for i := 0; i < s.NumField(); i++ {
f := s.Field(i)
fmt.Printf("%d: %s %s = %v\n", i,
typeOfT.Field(i).Name, f.Type(), f.Interface())
}
s.Field(0).SetInt(77)
s.Field(1).SetString("Sunset Strip")
fmt.Println("t is now", t)
}
输出:
0: A int = 23
1: B string = skidoo
t is now {77 Sunset Strip}
Int() 和 String() 方法
Int 和 String 可以帮助分别取出 reflect.Value 作为 int64 和 string。
package main
import (
"fmt"
"reflect"
)
func main() {
a := 56
x := reflect.ValueOf(a).Int()
fmt.Printf("type:%T value:%v\n", x, x)
b := "Naveen"
y := reflect.ValueOf(b).String()
fmt.Printf("type:%T value:%v\n", y, y)
}
在上面程序中取出 reflect.Value,并转换为 int64,接着取出 reflect.Value 并将其转换为 string。该程序会输出:
type:int64 value:56
type:string value:Naveen
读写数据
读取用户的输入
从键盘和标准输入 os.Stdin 读取输入,最简单的办法是使用 fmt 包提供的 Scan 和 Sscan 开头的函数。
// 从控制台读取输入:
package main
import "fmt"
var (
firstName, lastName, s string
i int
f float32
input = "56.12 / 5212 / Go"
format = "%f / %d / %s"
)
func main() {
fmt.Println("Please enter your full name: ")
fmt.Scanln(&firstName, &lastName)
// fmt.Scanf("%s %s", &firstName, &lastName)
fmt.Printf("Hi %s %s!\n", firstName, lastName) // Hi Chris Naegels
fmt.Sscanf(input, format, &f, &i, &s)
fmt.Println("From the string we read: ", f, i, s)
// 输出结果: From the string we read: 56.12 5212 Go
}
Scanln 扫描来自标准输入的文本,将空格分隔的值依次存放到后续的参数内,直到碰到换行。Scanf 与其类似,除了 Scanf 的第一个参数用作格式字符串,用来决定如何读取。
Sscan 和以 Sscan 开头的函数则是从字符串读取,除此之外,与 Scanf 相同。如果这些函数读取到的结果和预想的不同,可以检查成功读入数据的个数和返回的错误。
也可以使用 bufio 包提供的缓冲读取(buffered reader)来读取数据:
package main
import (
"fmt"
"bufio"
"os"
)
var inputReader *bufio.Reader
var input string
var err error
func main() {
inputReader = bufio.NewReader(os.Stdin)
fmt.Println("Please enter some input: ")
input, err = inputReader.ReadString('\n')
if err == nil {
fmt.Printf("The input was: %s\n", input)
}
}
inputReader 是一个指向 bufio.Reader 的指针。inputReader := bufio.NewReader(os.Stdin) 这行代码,将会创建一个读取器,并将其与标准输入绑定。
bufio.NewReader() 构造函数的签名为:func NewReader(rd io.Reader) *Reader
该函数的实参可以是满足 io.Reader 接口的任意对象(任意包含有适当的 Read() 方法的对象),函数返回一个新的带缓冲的 io.Reader 对象,它将从指定读取器(例如 os.Stdin)读取内容。
返回的读取器对象提供一个方法 ReadString(delim byte),该方法从输入中读取内容,直到碰到 delim 指定的字符,然后将读取到的内容连同 delim 字符一起放到缓冲区。
ReadString 返回读取到的字符串,如果碰到错误则返回 nil。如果它一直读到文件结束,则返回读取到的字符串和 io.EOF。如果读取过程中没有碰到 delim 字符,将返回错误 err != nil。
在上面的例子中,会读取键盘输入,直到回车键(\n)被按下。
屏幕是标准输出 os.Stdout;os.Stderr 用于显示错误信息,大多数情况下等同于 os.Stdout。
一般情况下,会省略变量声明,而使用 :=,例如:
inputReader := bufio.NewReader(os.Stdin)
input, err := inputReader.ReadString('\n')
读文件
在 Go 语言中,文件使用指向 os.File 类型的指针来表示的,也叫做文件句柄。在前面使用到过标准输入 os.Stdin 和标准输出 os.Stdout,他们的类型都是 *os.File。
package main
import (
"bufio"
"fmt"
"io"
"os"
)
func main() {
inputFile, inputError := os.Open("input.dat")
if inputError != nil {
fmt.Printf("An error occurred on opening the inputfile\n" +
"Does the file exist?\n" +
"Have you got acces to it?\n")
return // exit the function on error
}
defer inputFile.Close()
inputReader := bufio.NewReader(inputFile)
for {
inputString, readerError := inputReader.ReadString('\n')
fmt.Printf("The input was: %s", inputString)
if readerError == io.EOF {
return
}
}
}
变量 inputFile 是 *os.File 类型的。该类型是一个结构,表示一个打开文件的描述符(文件句柄)。然后,使用 os 包里的 Open 函数来打开一个文件。该函数的参数是文件名,类型为 string。在上面的程序中,以只读模式打开 input.dat 文件。
如果文件不存在或者程序没有足够的权限打开这个文件,Open 函数会返回一个错误:inputFile, inputError = os.Open("input.dat")。如果文件打开正常,就使用 defer inputFile.Close() 语句确保在程序退出前关闭该文件。然后,使用 bufio.NewReader 来获得一个读取器变量。
通过使用 bufio 包提供的读取器(写入器也类似),如上面程序所示,可以很方便的操作相对高层的 string 对象,而避免了去操作比较底层的字节。
接着,在一个无限循环中使用 ReadString('\n') 或 ReadBytes('\n') 将文件的内容逐行(行结束符 \n)读取出来。
注意:在使用 ReadString 和 ReadBytes 方法的时候,不需要关心操作系统的类型,直接使用 \n 就可以了。另外,也可以使用 ReadLine() 方法来实现相同的功能。
一旦读取到文件末尾,变量 readerError 的值将变成非空(事实上,常量 io.EOF 的值是 true),就会执行 return 语句从而退出循环。
其他读文件方式
将整个文件的内容读取到一个字符串里
可以使用 io/ioutil 包里的 ioutil.ReadFile() 方法,该方法第一个返回值的类型是 []byte,里面存放读取到的内容,第二个返回值是错误,如果没有错误发生,第二个返回值为 nil。
package main
import (
"fmt"
"io/ioutil"
"os"
)
func main() {
inputFile := "products.txt"
outputFile := "products_copy.txt"
buf, err := ioutil.ReadFile(inputFile)
if err != nil {
fmt.Fprintf(os.Stderr, "File Error: %s\n", err)
// panic(err.Error())
}
fmt.Printf("%s\n", string(buf))
err = ioutil.WriteFile(outputFile, buf, 0644) // oct, not hex
if err != nil {
panic(err.Error())
}
}
带缓冲的读取
在很多情况下,文件的内容是不按行划分的,或者干脆就是一个二进制文件。在这种情况下,ReadString() 就无法使用了,可以使用 bufio.Reader 的 Read(),它只接收一个参数:
buf := make([]byte, 1024)
...
n, err := inputReader.Read(buf)
if (n == 0) { break}
变量 n 的值表示读取到的字节数。
按列读取文件中的数据
如果数据是按列排列并用空格分隔的,可以使用 fmt 包提供的以 FScan 开头的一系列函数来读取他们。下面的程序将 3 列的数据分别读入变量 v1、v2 和 v3 内,然后分别把他们添加到切片的尾部。
package main
import (
"fmt"
"os"
)
func main() {
file, err := os.Open("products2.txt")
if err != nil {
panic(err)
}
defer file.Close()
var col1, col2, col3 []string
for {
var v1, v2, v3 string
_, err := fmt.Fscanln(file, &v1, &v2, &v3)
// scans until newline
if err != nil {
break
}
col1 = append(col1, v1)
col2 = append(col2, v2)
col3 = append(col3, v3)
}
fmt.Println(col1)
fmt.Println(col2)
fmt.Println(col3)
}
输出结果:
[ABC FUNC GO]
[40 56 45]
[150 280 356]
注意: path 包里包含一个子包叫 filepath,这个子包提供了跨平台的函数,用于处理文件名和路径。例如 Base () 函数用于获得路径中的最后一个元素(不包含后面的分隔符):
import "path/filepath"
filename := filepath.Base(path)
读取压缩文件
compress 包提供了读取压缩文件的功能,支持的压缩文件格式为:bzip2、flate、gzip、lzw 和 zlib。
package main
import (
"fmt"
"bufio"
"os"
"compress/gzip"
)
func main() {
fName := "MyFile.gz"
var r *bufio.Reader
fi, err := os.Open(fName)
if err != nil {
fmt.Fprintf(os.Stderr, "%v, Can't open %s: error: %s\n", os.Args[0], fName,
err)
os.Exit(1)
}
fz, err := gzip.NewReader(fi)
if err != nil {
r = bufio.NewReader(fi)
} else {
r = bufio.NewReader(fz)
}
for {
line, err := r.ReadString('\n')
if err != nil {
fmt.Println("Done reading file")
os.Exit(0)
}
fmt.Println(line)
}
}
写文件
package main
import (
"os"
"bufio"
"fmt"
)
func main () {
// var outputWriter *bufio.Writer
// var outputFile *os.File
// var outputError os.Error
// var outputString string
outputFile, outputError := os.OpenFile("output.dat", os.O_WRONLY|os.O_CREATE, 0666)
if outputError != nil {
fmt.Printf("An error occurred with file opening or creation\n")
return
}
defer outputFile.Close()
outputWriter := bufio.NewWriter(outputFile)
outputString := "hello world!\n"
for i:=0; i<10; i++ {
outputWriter.WriteString(outputString)
}
outputWriter.Flush()
}
首先以只写模式打开文件 output.dat,如果文件不存在则自动创建:
outputFile, outputError := os.OpenFile(“output.dat”, os.O_WRONLY|os.O_CREATE, 0666)
可以看到,OpenFile 函数有三个参数:文件名、一个或多个标志(使用逻辑运算符 “|” 连接),使用的文件权限。
通常会用到以下标志:
os.O_RDONLY:只读os.O_WRONLY:只写os.O_CREATE:创建:如果指定文件不存在,就创建该文件。os.O_TRUNC:截断:如果指定文件已存在,就将该文件的长度截为 0。
在读文件的时候,文件的权限是被忽略的,所以在使用 OpenFile 时传入的第三个参数可以用 0。而在写文件时,不管是 Unix 还是 Windows,都需要使用 0666。
然后,创建一个写入器(缓冲区)对象:
outputWriter := bufio.NewWriter(outputFile)
接着,使用一个 for 循环,将字符串写入缓冲区,写 10 次:outputWriter.WriteString(outputString)
缓冲区的内容紧接着被完全写入文件:outputWriter.Flush()
如果写入的东西很简单,可以使用 fmt.Fprintf(outputFile, “Some test data.\n”) 直接将内容写入文件。fmt 包里的 F 开头的 Print 函数可以直接写入任何 io.Writer,包括文件。
下面的例子展示了不使用 fmt.FPrintf 函数,使用其他函数如何写文件:
package main
import "os"
func main() {
os.Stdout.WriteString("hello, world\n")
f, _ := os.OpenFile("test", os.O_CREATE|os.O_WRONLY, 0)
defer f.Close()
f.WriteString("hello, world in a file\n")
}
使用 os.Stdout.WriteString(“hello, world\n”),我们可以输出到屏幕。
以只写模式创建或打开文件 “test”,并且忽略了可能发生的错误:f, _ := os.OpenFile(“test”, os.O_CREATE|os.O_WRONLY, 0)
不使用缓冲区,直接将内容写入文件:f.WriteString( )
文件拷贝
// filecopy.go
package main
import (
"fmt"
"io"
"os"
)
func main() {
CopyFile("target.txt", "source.txt")
fmt.Println("Copy done!")
}
func CopyFile(dstName, srcName string) (written int64, err error) {
src, err := os.Open(srcName)
if err != nil {
return
}
defer src.Close()
dst, err := os.OpenFile(dstName, os.O_WRONLY|os.O_CREATE, 0644)
if err != nil {
return
}
defer dst.Close()
return io.Copy(dst, src)
}
注意 defer 的使用:当打开目标文件时发生了错误,那么 defer 仍然能够确保 src.Close() 执行。如果不这么做,文件会一直保持打开状态并占用资源。
fmt.Fprintf
// interfaces being used in the GO-package fmt
package main
import (
"bufio"
"fmt"
"os"
)
func main() {
// unbuffered
fmt.Fprintf(os.Stdout, "%s\n", "hello world! - unbuffered")
// buffered: os.Stdout implements io.Writer
buf := bufio.NewWriter(os.Stdout)
// and now so does buf.
fmt.Fprintf(buf, "%s\n", "hello world! - buffered")
buf.Flush()
}
hello world! - unbuffered
hello world! - buffered
下面是 fmt.Fprintf() 函数的实际签名
func Fprintf(w io.Writer, format string, a ...interface{}) (n int, err error)
其不是写入一个文件,而是写入一个 io.Writer 接口类型的变量,下面是 Writer 接口在 io 包中的定义:
type Writer interface {
Write(p []byte) (n int, err error)
}
fmt.Fprintf() 依据指定的格式向第一个参数内写入字符串,第一参数必须实现了 io.Writer 接口。Fprintf() 能够写入任何类型,只要其实现了 Write 方法,包括 os.Stdout, 文件(例如 os.File),管道,网络连接,通道等等,同样的也可以使用 bufio 包中缓冲写入。bufio 包中定义了 type Writer struct{...}。
bufio.Writer 实现了 Write 方法:
func (b *Writer) Write(p []byte) (nn int, err error)
它还有一个工厂函数:传给它一个 io.Writer 类型的参数,它会返回一个缓冲的 bufio.Writer 类型的 io.Writer:
func NewWriter(wr io.Writer) (b *Writer)
其适合任何形式的缓冲写入。
在缓冲写入的最后要使用 Flush(),否则最后的输出不会被写入。
数据格式处理
数据结构要在网络中传输或保存到文件,就必须对其编码和解码;目前存在很多编码格式:JSON,XML,gob,Google 缓冲协议等等。Go 语言支持所有这些编码格式。
结构可能包含二进制数据,如果将其作为文本打印,那么可读性是很差的。另外结构内部可能包含匿名字段,而不清楚数据的用意。
通过把数据转换成纯文本,使用命名的字段来标注,让其具有可读性。这样的数据格式可以通过网络传输,而且是与平台无关的,任何类型的应用都能够读取和输出,不与操作系统和编程语言的类型相关。
下面是一些术语说明:
- 数据结构 –> 指定格式 =
序列化或编码(传输之前) - 指定格式 –> 数据格式 =
反序列化或解码(传输之后)
序列化是在内存中把数据转换成指定格式(data -> string),反之亦然(string -> data structure)
编码也是一样的,只是输出一个数据流(实现了 io.Writer 接口);解码是从一个数据流(实现了 io.Reader)输出到一个数据结构。
通常 JSON 被用于 web 后端和浏览器之间的通讯,但是在其它场景也同样的有用。
JSON 数据格式
// json.go
package main
import (
"encoding/json"
"fmt"
"log"
"os"
)
type Address struct {
Type string
City string
Country string
}
type VCard struct {
FirstName string
LastName string
Addresses []*Address
Remark string
}
func main() {
pa := &Address{"private", "Aartselaar", "Belgium"}
wa := &Address{"work", "Boom", "Belgium"}
vc := VCard{"Jan", "Kersschot", []*Address{pa, wa}, "none"}
// fmt.Printf("%v: \n", vc) // {Jan Kersschot [0x126d2b80 0x126d2be0] none}:
// JSON format:
js, _ := json.Marshal(vc)
fmt.Printf("JSON format: %s", js)
// using an encoder:
file, _ := os.OpenFile("vcard.json", os.O_CREATE|os.O_WRONLY, 0666)
defer file.Close()
enc := json.NewEncoder(file)
err := enc.Encode(vc)
if err != nil {
log.Println("Error in encoding json")
}
}
json.Marshal() 的函数签名是 func Marshal(v interface{}) ([]byte, error),下面是数据编码后的 JSON 文本(实际上是一个 [] byte):
{
"FirstName": "Jan",
"LastName": "Kersschot",
"Addresses": [{
"Type": "private",
"City": "Aartselaar",
"Country": "Belgium"
}, {
"Type": "work",
"City": "Boom",
"Country": "Belgium"
}],
"Remark": "none"
}
出于安全考虑,在 web 应用中最好使用 json.MarshalforHTML() 函数,其对数据执行 HTML 转码,所以文本可以被安全地嵌在 HTML <script> 标签中。
json.NewEncoder() 的函数签名是 func NewEncoder(w io.Writer) *Encoder,返回的 Encoder 类型的指针可调用方法 Encode(v interface{}),将数据对象 v 的 json 编码写入 io.Writer w 中。
JSON 与 Go 类型对应如下:
- bool 对应 JSON 的 booleans
- float64 对应 JSON 的 numbers
- string 对应 JSON 的 strings
- nil 对应 JSON 的 null
不是所有的数据都可以编码为 JSON 类型:只有验证通过的数据结构才能被编码:
- JSON 对象只支持字符串类型的 key;要编码一个 Go map 类型,map 必须是 map [string] T(T 是
json包中支持的任何类型) - Channel,复杂类型和函数类型不能被编码
- 不支持循环数据结构;它将引起序列化进入一个无限循环
- 指针可以被编码,实际上是对指针指向的值进行编码(或者指针是 nil)
反序列化:
UnMarshal() 的函数签名是 func Unmarshal(data []byte, v interface{}) error 把 JSON 解码为数据结构。
示例中对 vc 编码后的数据为 js ,对其解码时,首先创建结构 VCard 用来保存解码的数据:var v VCard 并调用 json.Unmarshal(js, &v),解析 [] byte 中的 JSON 数据并将结果存入指针 &v 指向的值。
虽然反射能够让 JSON 字段去尝试匹配目标结构字段;但是只有真正匹配上的字段才会填充数据。字段没有匹配不会报错,而是直接忽略掉。
解码任意的数据:
json 包使用 map[string]interface{} 和 []interface{} 储存任意的 JSON 对象和数组;其可以被反序列化为任何的 JSON blob 存储到接口值中。
假设有一个 JSON 数据,被存储在变量 b 中:
b := []byte(`{"Name": "Wednesday", "Age": 6, "Parents": ["Gomez", "Morticia"]}`)
不用理解这个数据的结构,可以直接使用 Unmarshal 把这个数据编码并保存在接口值中:
var f interface{}
err := json.Unmarshal(b, &f)
f 指向的值是一个 map,key 是一个字符串,value 是自身存储作为空接口类型的值:
map[string]interface{} {
"Name": "Wednesday",
"Age": 6,
"Parents": []interface{} {
"Gomez",
"Morticia",
},
}
要访问这个数据,可以使用类型断言
m := f.(map[string]interface{})
可以通过 for range 语法和 type switch 来访问其实际类型:
for k, v := range m {
switch vv := v.(type) {
case string:
fmt.Println(k, "is string", vv)
case int:
fmt.Println(k, "is int", vv)
case []interface{}:
fmt.Println(k, "is an array:")
for i, u := range vv {
fmt.Println(i, u)
}
default:
fmt.Println(k, "is of a type I don’t know how to handle")
}
}
通过这种方式,可以处理未知的 JSON 数据,同时可以确保类型安全。
解码数据到结构
如果事先知道 JSON 数据,可以定义一个适当的结构并对 JSON 数据反序列化。下面的例子中,将定义:
type FamilyMember struct {
Name string
Age int
Parents []string
}
并对其反序列化:
var m FamilyMember
err := json.Unmarshal(b, &m)
程序实际上是分配了一个新的切片。这是一个典型的反序列化引用类型(指针、切片和 map)的例子。
编码和解码流
json 包提供 Decoder 和 Encoder 类型来支持常用 JSON 数据流读写。NewDecoder 和 NewEncoder 函数分别封装了 io.Reader 和 io.Writer 接口。
func NewDecoder(r io.Reader) *Decoder
func NewEncoder(w io.Writer) *Encoder
要想把 JSON 直接写入文件,可以使用 json.NewEncoder 初始化文件(或者任何实现 io.Writer 的类型),并调用 Encode ();反过来与其对应的是使用 json.Decoder 和 Decode () 函数:
func NewDecoder(r io.Reader) *Decoder
func (dec *Decoder) Decode(v interface{}) error
来看下接口是如何对实现进行抽象的:数据结构可以是任何类型,只要其实现了某种接口,目标或源数据要能够被编码就必须实现 io.Writer 或 io.Reader 接口。由于 Go 语言中到处都实现了 Reader 和 Writer,因此 Encoder 和 Decoder 可被应用的场景非常广泛,例如读取或写入 HTTP 连接、websockets 或文件。
XML 数据格式
<Person>
<FirstName>Laura</FirstName>
<LastName>Lynn</LastName>
</Person>
如同 json 包一样,也有 Marshal() 和 UnMarshal() 从 XML 中编码和解码数据;但这个更通用,可以从文件中读取和写入(或者任何实现了 io.Reader 和 io.Writer 接口的类型)
和 JSON 的方式一样,XML 数据可以序列化为结构,或者从结构反序列化为 XML 数据;
encoding/xml 包实现了一个简单的 XML 解析器(SAX),用来解析 XML 数据内容。
// xml.go
package main
import (
"encoding/xml"
"fmt"
"strings"
)
var t, token xml.Token
var err error
func main() {
input := "<Person><FirstName>Laura</FirstName><LastName>Lynn</LastName></Person>"
inputReader := strings.NewReader(input)
p := xml.NewDecoder(inputReader)
for t, err = p.Token(); err == nil; t, err = p.Token() {
switch token := t.(type) {
case xml.StartElement:
name := token.Name.Local
fmt.Printf("Token name: %s\n", name)
for _, attr := range token.Attr {
attrName := attr.Name.Local
attrValue := attr.Value
fmt.Printf("An attribute is: %s %s\n", attrName, attrValue)
// ...
}
case xml.EndElement:
fmt.Println("End of token")
case xml.CharData:
content := string([]byte(token))
fmt.Printf("This is the content: %v\n", content)
// ...
default:
// ...
}
}
}
输出:
Token name: Person
Token name: FirstName
This is the content: Laura
End of token
Token name: LastName
This is the content: Lynn
End of token
End of token
包中定义了若干 XML 标签类型:StartElement,Chardata(这是从开始标签到结束标签之间的实际文本),EndElement,Comment,Directive 或 ProcInst。
包中同样定义了一个结构解析器:NewParser 方法持有一个 io.Reader(这里具体类型是 strings.NewReader)并生成一个解析器类型的对象。还有一个 Token() 方法返回输入流里的下一个 XML token。在输入流的结尾处,会返回(nil,io.EOF)
XML 文本被循环处理直到 Token() 返回一个错误,因为已经到达文件尾部,再没有内容可供处理了。通过一个 type-switch 可以根据一些 XML 标签进一步处理。Chardata 中的内容只是一个 [] byte,通过字符串转换让其变得可读性强一些。
Gob 数据格式
Gob 是 Go 自己的以二进制形式序列化和反序列化程序数据的格式;可以在 encoding 包中找到。这种格式的数据简称为 Gob (即 Go binary 的缩写)。类似于 Python 的 “pickle” 和 Java 的 “Serialization”。
Gob 通常用于远程方法调用参数和结果的传输,以及应用程序和机器之间的数据传输。
它和 JSON 或 XML 有什么不同呢?Gob 特定地用于纯 Go 的环境中,例如,两个用 Go 写的服务之间的通信。这样的话服务可以被实现得更加高效和优化。
Gob 不是可外部定义,语言无关的编码方式。因此它的首选格式是二进制,而不是像 JSON 和 XML 那样的文本格式。
Gob 并不是一种不同于 Go 的语言,而是在编码和解码过程中用到了 Go 的反射。
Gob 文件或流是完全自描述的:里面包含的所有类型都有一个对应的描述,并且总是可以用 Go 解码,而不需要了解文件的内容。
只有可导出的字段会被编码,零值会被忽略。在解码结构体的时候,只有同时匹配名称和可兼容类型的字段才会被解码。当源数据类型增加新字段后,Gob 解码客户端仍然可以以这种方式正常工作:解码客户端会继续识别以前存在的字段。并且还提供了很大的灵活性,比如在发送者看来,整数被编码成没有固定长度的可变长度,而忽略具体的 Go 类型。
假如在发送者这边有一个有结构 T:
type T struct { X, Y, Z int }
var t = T{X: 7, Y: 0, Z: 8}
而在接收者这边可以用一个结构体 U 类型的变量 u 来接收这个值:
type U struct { X, Y *int8 }
var u U
在接收者中,X 的值是 7,Y 的值是 0(Y 的值并没有从 t 中传递过来,因为它是零值)
和 JSON 的使用方式一样,Gob 使用通用的 io.Writer 接口,通过 NewEncoder() 函数创建 Encoder 对象并调用 Encode();相反的过程使用通用的 io.Reader 接口,通过 NewDecoder() 函数创建 Decoder 对象并调用 Decode。
// gob1.go
package main
import (
"bytes"
"fmt"
"encoding/gob"
"log"
)
type P struct {
X, Y, Z int
Name string
}
type Q struct {
X, Y *int32
Name string
}
func main() {
// Initialize the encoder and decoder. Normally enc and dec would be
// bound to network connections and the encoder and decoder would
// run in different processes.
var network bytes.Buffer // Stand-in for a network connection
enc := gob.NewEncoder(&network) // Will write to network.
dec := gob.NewDecoder(&network) // Will read from network.
// Encode (send) the value.
err := enc.Encode(P{3, 4, 5, "Pythagoras"})
if err != nil {
log.Fatal("encode error:", err)
}
// Decode (receive) the value.
var q Q
err = dec.Decode(&q)
if err != nil {
log.Fatal("decode error:", err)
}
fmt.Printf("%q: