pprof 实战-服务性能分析与优化
背景
最近重构了我们业务上的一个服务,该服务的功能是为终端提供一些版本文件信息和素材数据信息。
具体到代码逻辑上也非常简单,就是把配置在数据库表里的数据都捞到本地缓存,每次请求的时候,根据终端的版本信息做一些过滤判断,然后把本地缓存的所有文件数据都下发下去。
由于终端请求机制等等历史原因,该服务存在两个问题:一个是每天0点的时候请求流量会暴涨,工作日会涨1倍流量,而节假日有时候可能会3-4倍;另一个是每次请求时,会把数据库中的所有数据全部下发下去,也就导致每次请求返回的包体都很大。
在实际线上监控中发现,每到0点的时候,就会出现耗时猛涨一波的情况,而此时CPU和内存使用率虽然也有上涨,但基本也不会到很高的级别,所以对这里出现的原因进行了具体的分析。
而要说 Go 服务的性能分析,那就不得不提到 pprof 这个性能分析利器,本文也借着本次性能分析优化记录一下使用 pprof 的实战经验。
pprof 介绍
pprof 有一说一,确实是一项分析 Go 程序的利器,它提供了对 Go 程序进行 CPU、内存使用分析,goroutine 分析以及 GC 分析等。
pprof 提供了两种分析方式,一种是通过自带的 go tool pprof 工具,一种则是通过在服务内注册端口,通过 web 页面查看。
一般来说,对于线上的服务,一般都是部署在容器上,想直接通过 web 页面访问会比较麻烦,所以个人推荐的方式是通过 go tool 工具获取文件后下载到本地进行,此时可以利用下载的文件直接通过 go tool 分析,也可以生成本地的 web 页面,比较灵活。
下面聊一聊 pprof 的使用方式。
CPU 性能分析(profile)
先说下 profile 是如何进行采样的:
- 采样频率是每秒100次
- 一个样本包含goroutine栈的程序计数器(program counters)
- 每次只会采样调用栈的前100行
再来看下具体的我们要怎么进行 profile 分析。首先我们需要有一台能够 ping 通线上服务容器的机器,之后在机器上安装 golang 开发环境。之后,我们可以通过运行下面的命令进行 profile 性能分析:
go tool pprof http://ip:port/debug/pprof/profile
如果有必要,还可以指定采样时间:
go tool pprof http://ip:port/debug/pprof/profile?seconds=30
此时就会直接进入到 pprof 分析页面,同时,机器上会生成一个类似 pprof.xxx.samples.cpu.002.pb.gz的文件:
我们可以直接将文件下载到本地目录,之后在本地目录通过命令打开文件。
这里打开文件的方式有两种:
命令行模式
一种是直接在本地运行 go tool 命令:
go tool pprof pprof.xxx.samples.cpu.002.pb.gz
此时就可以进入命令行模式:
命令行模式下,可以通过几个指令来观察服务的使用情况,简单说几个常用的:
top
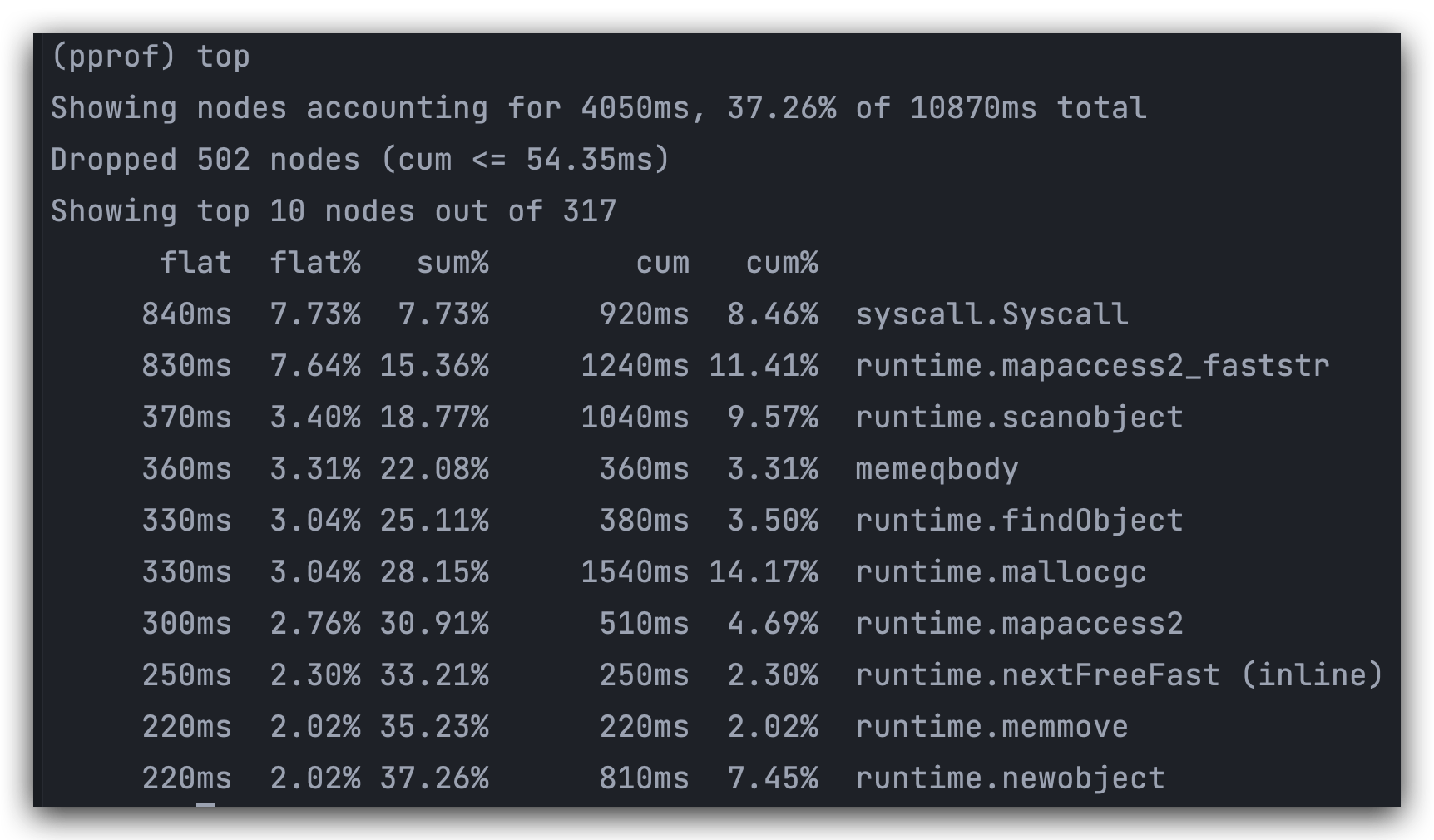
指标含义:
| 指标 | 含义 |
|---|---|
| flat | 函数自身占用 CPU 的运行耗时 |
| flat% | 函数自身在 CPU 运行耗时总比例。 |
| sum% | 函数自身累积使用 CPU 总比例 |
| cum | 函数自身及其调用函数的运行总耗时。 |
| cum% | 函数自身及其调用函数的运行耗时总比例。 |
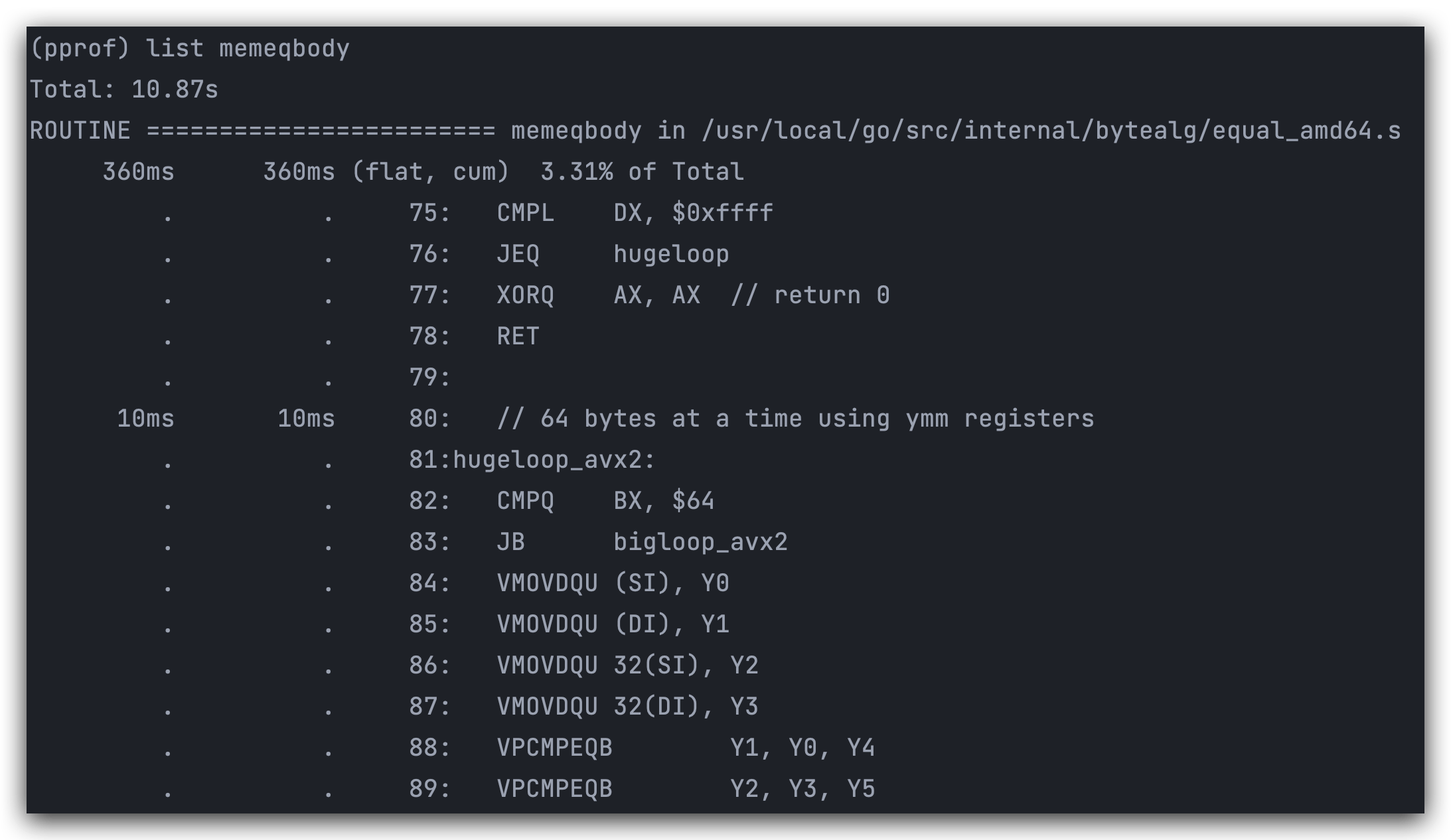
list
list 用来展示一个函数的具体情况,例如对上面的 memqbody 执行 list 命令,可以看到其具体所处的位置和函数实现,还有每个范围对应的耗时:
web 模式
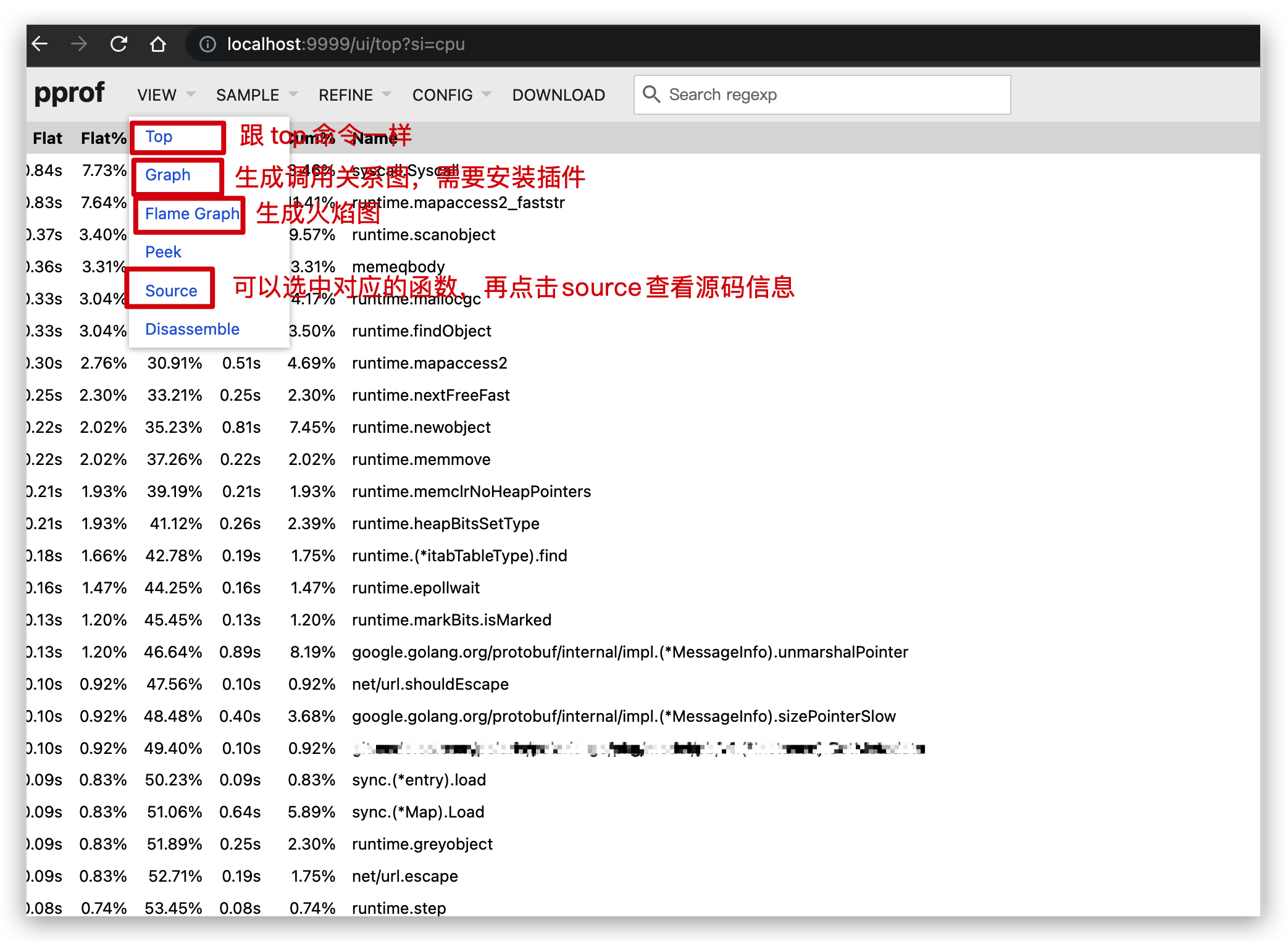
另一种则是直接通过在运行时指定一个端口,从而生成一个 web 页面:
go tool pprof -http=:9999 /pprof.xxxx.samples.cpu.001.pb.gz
此时会在本地打开一个网页,可以很直观的看到分析数据:
内存使用分析(heap)
分析服务的内存使用情况,可以使用 heap 模式进行分析,执行的命令如下(如有必要,同样可以指定时间):
go tool pprof http://ip:port/debug/pprof/heap
该命令同样会在机器上生成一个类似 pprof.xxx.alloc_objects.alloc_space.inuse_objects.inuse_space.001.pb.gz 的文件。

这里内存占用的情况有四种:
| 内存占用类型 | 含义 |
|---|---|
| inuse_space | 展示的是现在正在使用的内存,被分配但是还没有被释放,这个是默认参数 |
| inuse_objects | 显示正在使用的对象数量 (即已分配但未释放的对象数) |
| alloc_space | 展示的是程序启动到现在的分配内存,包括那些已经被释放的内存,如果系统GC负担大,我们一般用这个来定位代码中创建临时变量的大户。 |
| alloc_objects | 显示程序启动到现在分配的对象数量 |
一般情况下,我们使用第一种或者第二种就可以了。
同样的,把文件下载到本机后,就可以通过命令行和 web 两种模式来解析文件,分析服务的内存占用情况了。
命令行模式
通过以下命令进入命令行,可以指定使用的内存占用情况进行分析:
go tool pprof [-inuse_space|inuse_objects|alloc_space|alloc_objects] /pprof.xxx.alloc_objects.alloc_space.inuse_objects.inuse_space.006.pb.gz
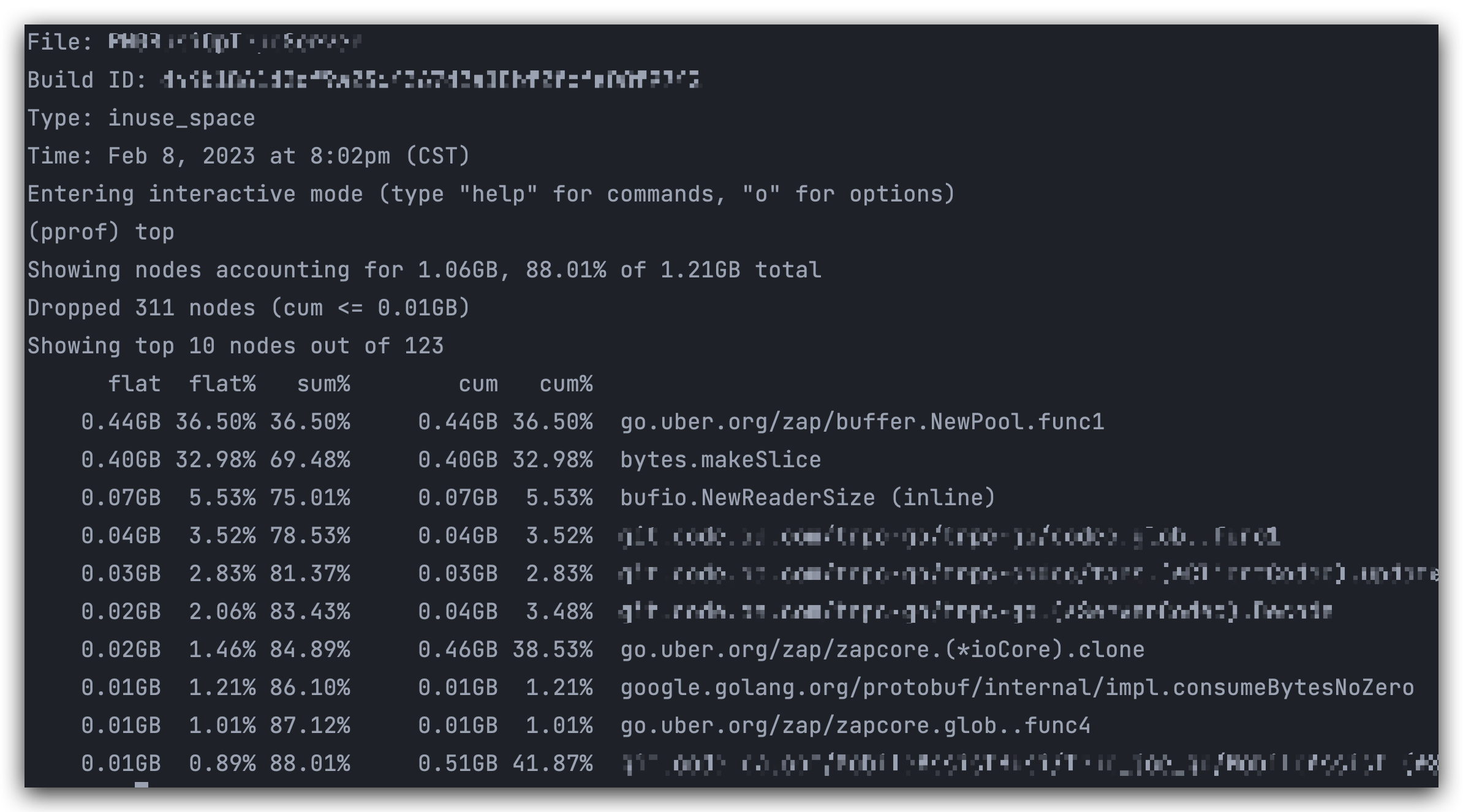
指标含义:
| 指标 | 含义 |
|---|---|
| flat | 函数自身占用的内存 |
| flat% | 函数自身占用统计内存的比例 |
| sum% | 函数自身累积占用内存的总比例 |
| cum | 函数自身及其调用函数占用的内存 |
| cum% | 函数自身及其调用函数占用统计内存的比例 |
同样可以通过 list 命令查看每个函数的内存分配情况。
在使用 go tool 命令时,还可以指定 -base 参数,从而对比两份不同时间段的样本数据,来分析程序的内存分配情况。
go tool pprof -base pprof.xxx.alloc_objects.alloc_space.inuse_objects.inuse_space.001.pb.gz pprof.xxx.alloc_objects.alloc_space.inuse_objects.inuse_space.002.pb.gz
web 模式
web 模式和 profile 提供的功能基本一致,这里就不赘述了。
trace 分析
trace 分析可以用来分析程序的 Goroutine 情况和 GC 情况。
trace 文件数据可以通过以下命令,指定获取某个机器上的程序的数据:
curl http://ip:port/debug/pprof/trace?seconds=30 > trace.out
同样的,将 trace 文件下载到本地后,可以通过下面的命令启动可视化界面:
go tool trace trace.out
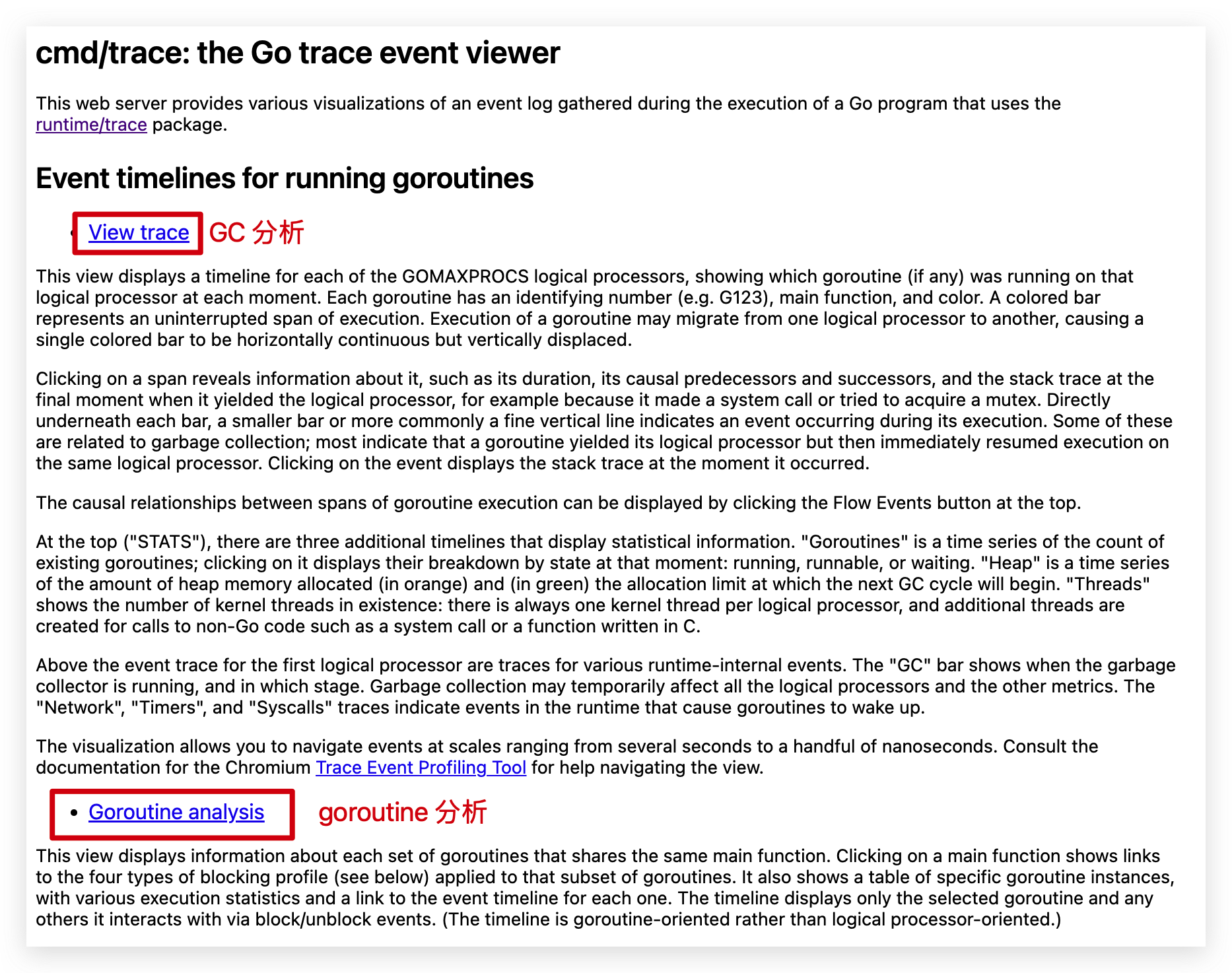
View trace
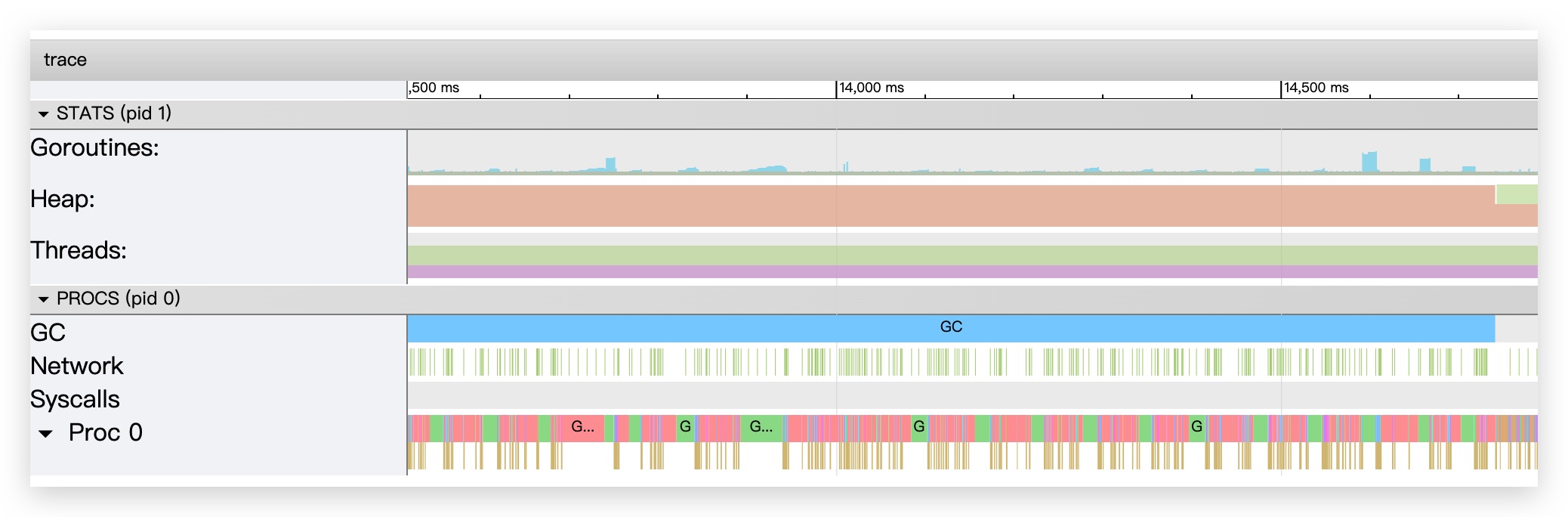
这里从上到下分别是:
- 协程:显示协程的数量和状态
- 堆内存:显示堆内存占用
- 线程:显示操作系统线程数量和状态
- GC 事件:显示 GC 的开始和结束
- 网络事件:网络 IO 相关片段
- 系统调用事件:显示系统调用片段
- Processor 事件:显示执行器在执行哪个协程和函数
Garbage collection metrics
trace 还提供了一个图标,用来表示垃圾收集的指标。
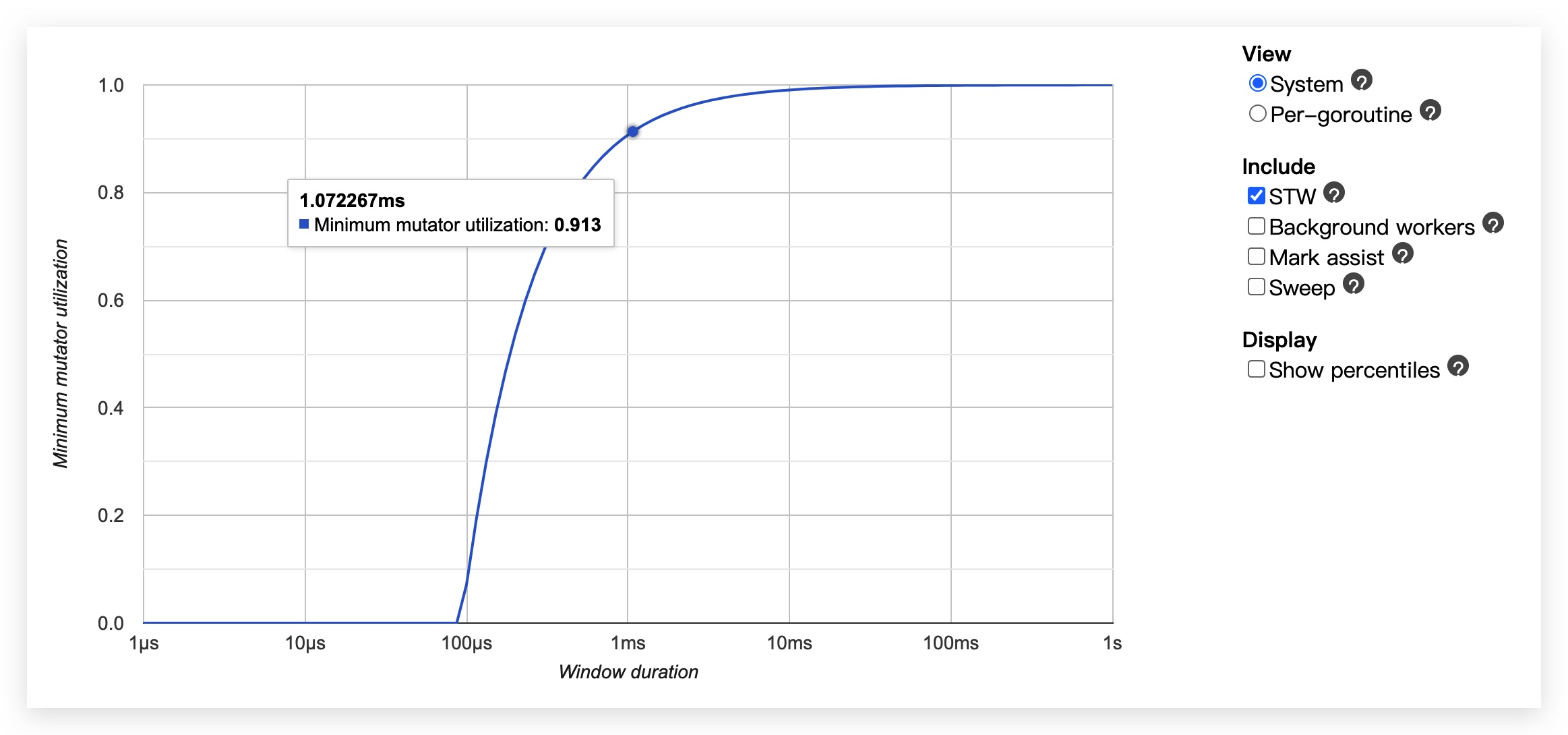
该图标识了GC最大的暂停时间(y=0时x的最大值,图示为接近100us)。
图示的含义:
- X 轴表示我们取一个多长的时间窗口
- Y 轴表示这个时间窗口里,最差情况下有多少比例的 CPU 时间可供业务代码使用
所以从上图中可以看出,STW(y=0,表示无业务使用)的时间大概是100us。如果取1ms的时间窗口,可以看到此时业务使用时间大概占了91.3%。
服务优化
现象
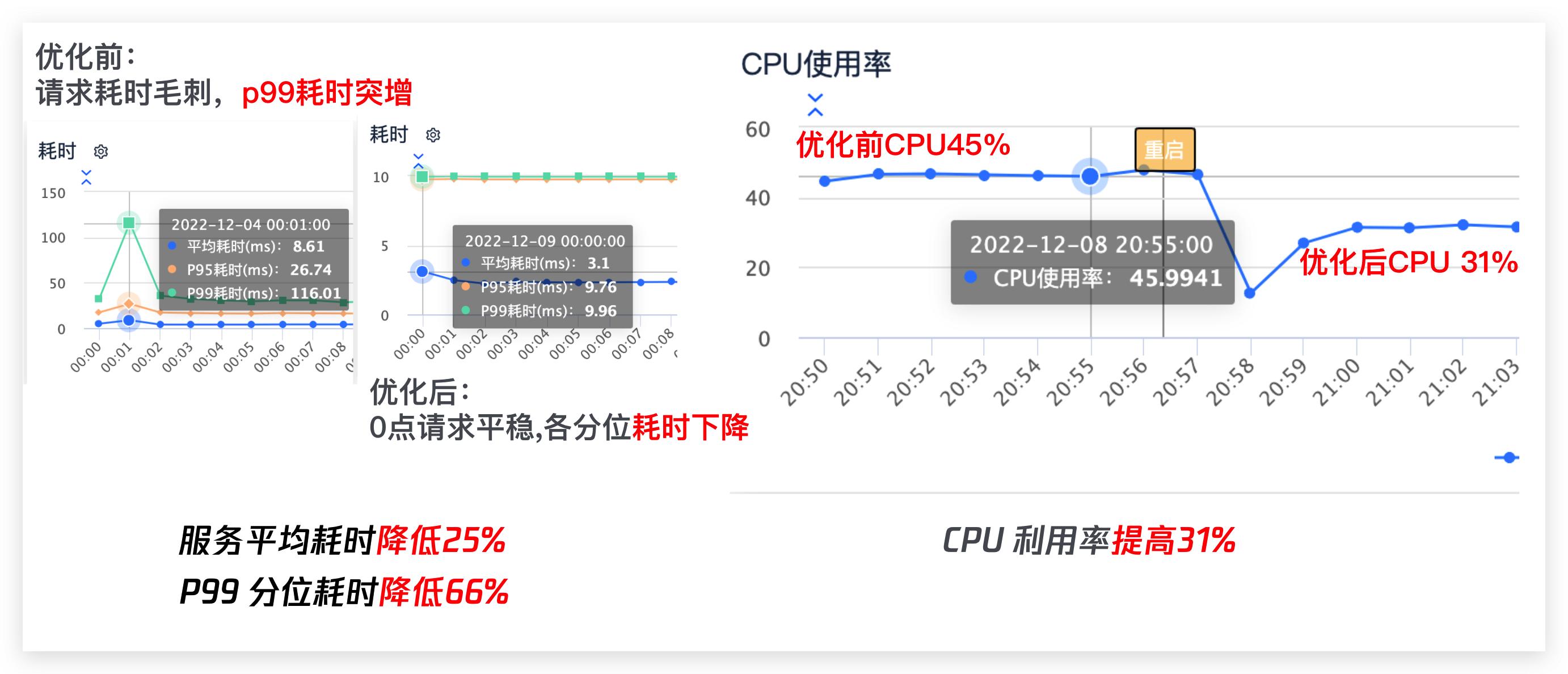
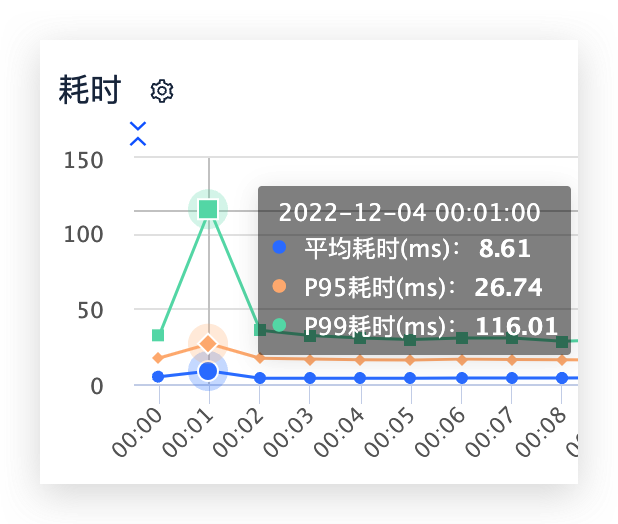
前面说过,我们的服务在每到0点的时候,就会出现耗时猛涨一波的情况,而此时CPU和内存使用率虽然也有上涨,但基本也不会到很高的级别。
先看下服务的在每天零点的耗时情况,可以看到,由于流量的突增,服务在零点耗时,尤其是在p99耗时上增加的比较明显。
问题排查
通过在测试环境模拟实际流量请求,之后通过 pprof 分析 cpu 使用率,发现服务在 cpu 利用率这块上,GC 标记占用了比较多的时间。
下图标记的几个函数都是在 GC 中使用的函数。
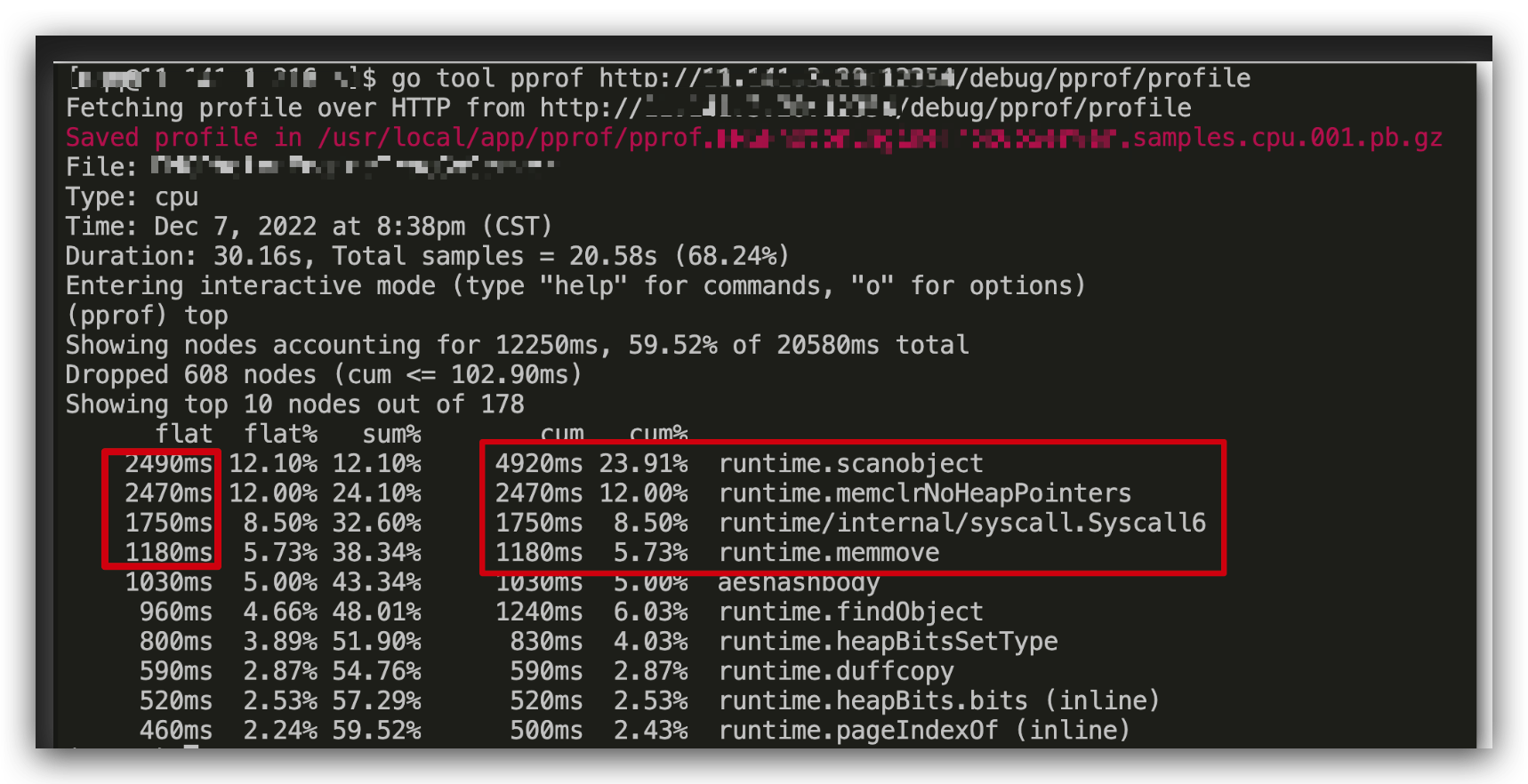
由此,可以大致推测可能跟服务在高负载时候引发的频繁 GC 有关。为了进一步验证猜测,可以通过 trace 再看看服务的 GC 情况:
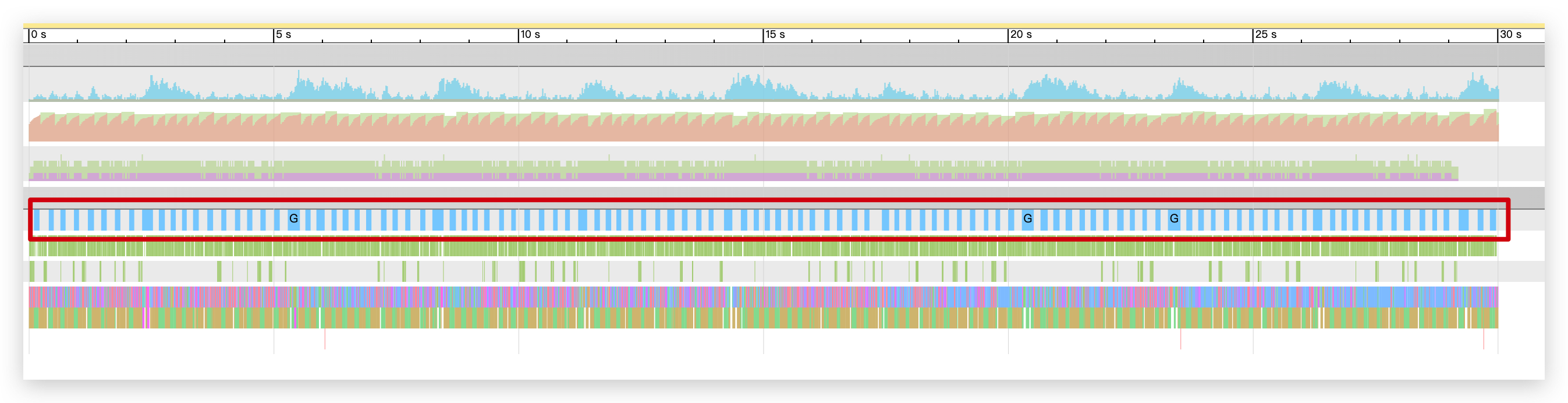

可以看到,服务引发了较为频繁的 GC,而到具体每一次 GC 上,可以发现每次 GC 都触发了多次的 Mark Assit,这意味着 Go 收集器认为当前 GC 协程来不及进行标记任务,而抢占了程序额外的 CPU 协助进行 GC 扫描。(这里涉及到 GO 的垃圾回收机制,有兴趣可以看看Go 内存管理与垃圾回收)
这里还可以进一步通过 heap 分析,看看服务到底在哪个地方进行了频繁的内存分配和释放,还可以通过 list 函数名,查看具体对应的是哪一段代码。
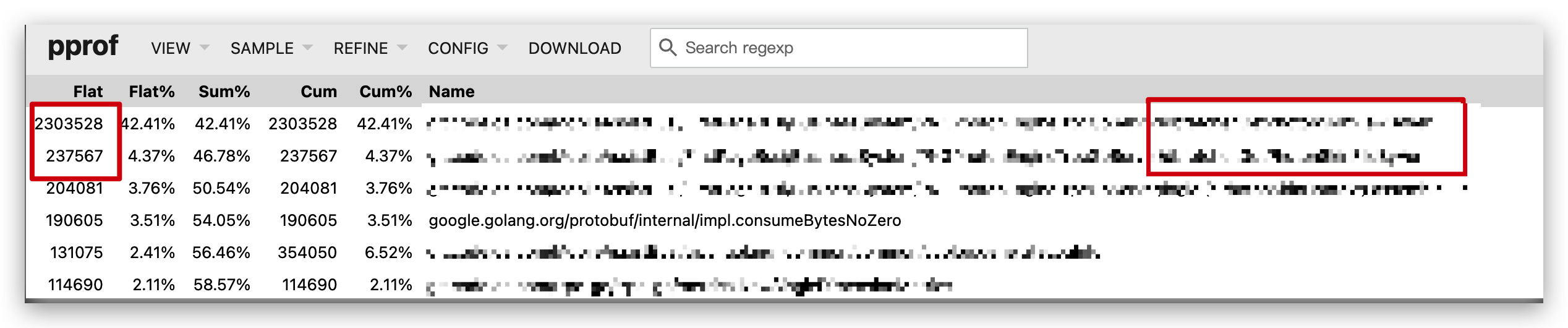
这里我们业务会出现这里频繁申请和释放内存的原因,和我们的业务逻辑有关,前面说过,该服务的功能是为终端提供一些版本文件信息和素材数据信息,而这里会获取全量数据信息,导致了内存频繁的申请和释放。
服务优化
通过上面的排查,可以大致发现服务存在的问题:内存的频繁申请释放,导致服务的频繁 GC。
那我们大致可以推断出优化的方向主要有两个,一个是怎么减少内存的频繁申请回收;另一个就是对 GC 的触发时机进行调整。
sync.Pool 对象分配池化
针对上述提到的内存的频繁申请和释放,优化的常见方式就是采用池化的方式来对内存进行复用,也就是采用 Go 的 sync.Pool 来对对象的分配进行池化,复用内存,以此减少内存的申请和回收频率。
这里我对上述提到的 top2 的两个函数中的实现进行了调整,采用 sync.Pool 来实现后,再次进行 heap 分析,可以看到此时的内存分配情况:
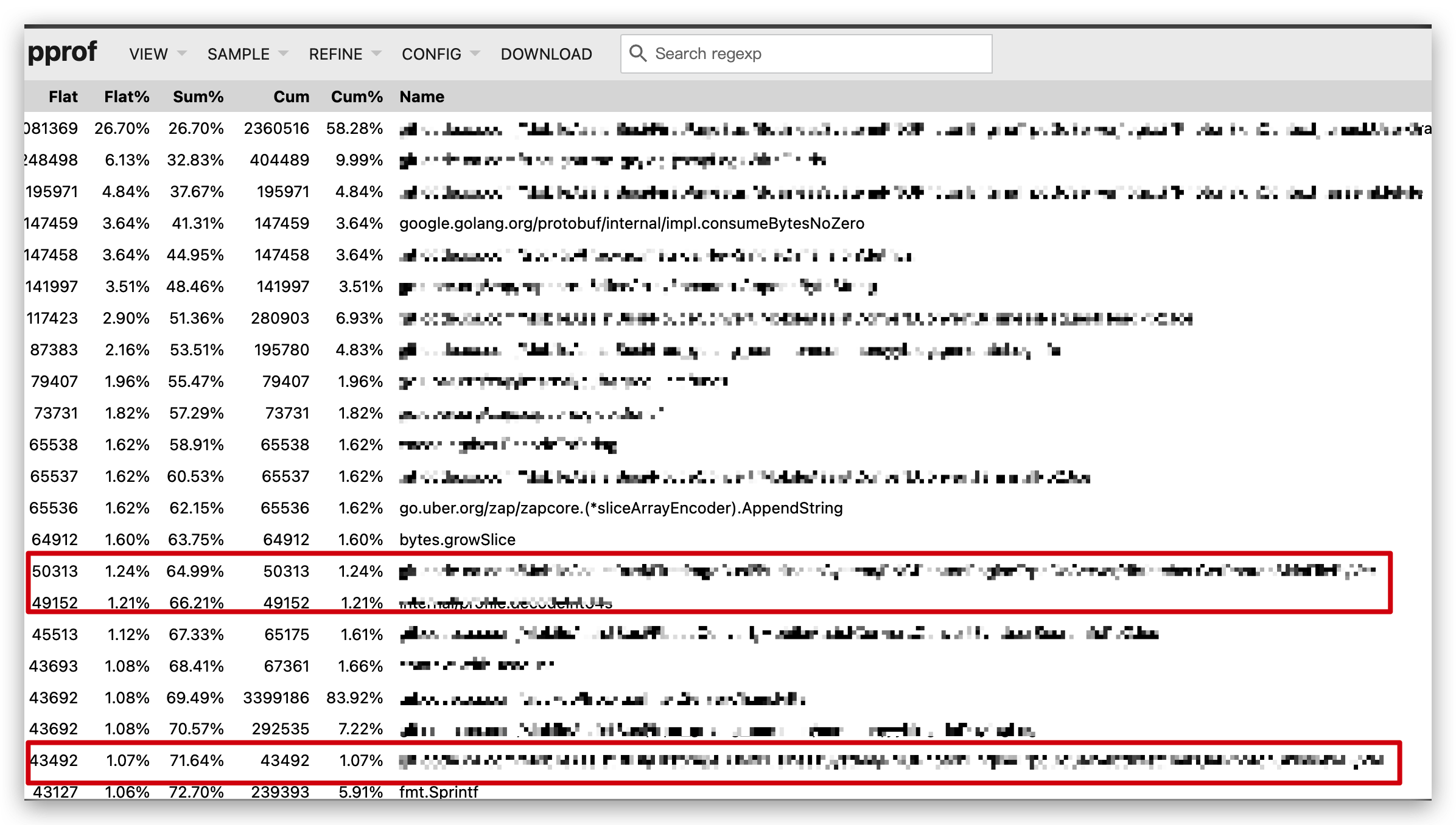
可以看出,在同等流量的条件下,服务内存分配的热点已经不在原来的业务代码中,红色框的为原来代码的内存分配,相比原来的分配也已经降低了很多。
GC 调优
除了采用对象池化的技术,我们还可以进一步通过 GC 调优来调整 GC 的频率。Go 提供了 GOGC 这一个参数来对 GC 进行干涉。当然,一般来说,在 GC 影响不是很大的时候,是不推荐对 GC 参数进行调整的。
当然,这里我出于好奇效果到底怎么样,还是做了参数的调整来验证效果。在使用 GOGC 参数时,一般有两种方式:
- 一种是直接手动设置 GOGC,在程序启动前将其设置成一个固定值,这种方案实现起来非常简单,但是对于设置的具体值并不好把控,设置的太高,容易导致 OOM;设置的过低又容易引起频繁的GC,反而影响性能
- 而另外一种方案则是在程序运行过程中根据内存情况以动态调整的方式进行,这种方式的优点是比较灵活,可以动态调整,但是实现起来相对复杂。
而在我们公司内存,有一个内部的组件,可以动态调整 GC,该组件提供了两种动态调整的方法:
- 一种叫做ballast(镇流器),其原理是通过在程序初始化时,在堆中申请一块大内存,由 main 协程持有,以此提高整个 GC 的 base,来达到减少GC的效果,初始化内存的大小可以根据容器大小进行调整
- 另外一种是auto的方式,原理是会根据当前进程使用的内存百分比和配置的目标内存使用百分比,计算出一个合适的 GCPercent,接着对循环引用的对象设置 runtime.SetFinalizer 钩子方法,使得每次GC后都回调自定义的函数来设置新的 GC percent值
可以看下当我在程序中引入了 GC 组件后,服务的 GC 情况:

优化后的效果
最后,再贴一张图看看这对骚操作后的效果: