一次内存泄漏的排查
业务背景
我们有一款产品跟海外某个国家的客户有业务合作,因此,我们在这个国家的服务器上单独部署了一整套的服务(大概有八九个微服务),这些服务的宿主机大概都集中在三、四台宿主机上。这些服务日复一日,年复一年的并肩作战着,直到有一天……
初见端倪
前阵子,我们在一个服务进行扩容、重启的时候,总是概率性的出现如下错误导致的 panic:

Google 的结果是说由于 Linux 分配的客户端连接端口用尽,无法建立 socket 连接导致的。
这时候还有点懵逼,单纯以为是容器的宿主机有问题,于是,我重新在另外一台机器进行了节点扩容,这次很幸运,服务启动成功了,于是乎以为问题已经顺利解决,可以美美的下班了。
渐露头角
过了一周,我们发现线上的另一个服务在疯狂报错,上去查看日志,发现:
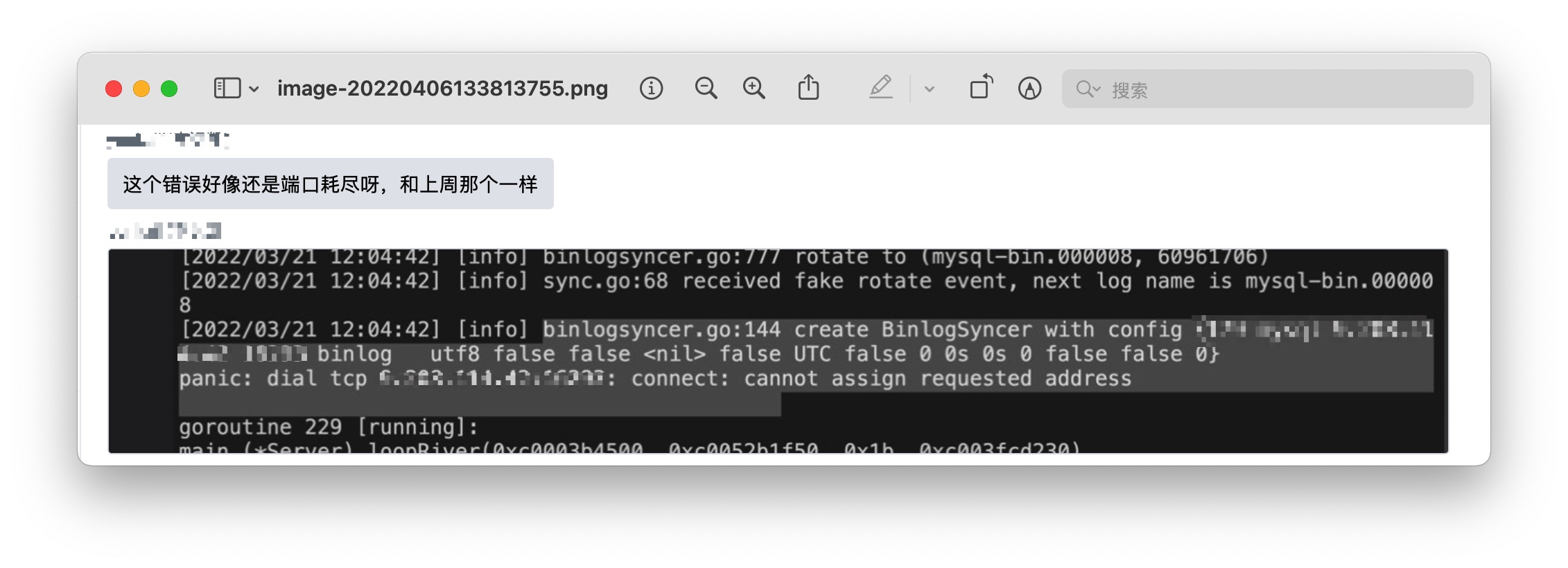
同样的错误又出现了,而且这次是在另外一个服务上,这时候开始觉得哪里不对劲了,另一个服务怎么也出现这种错误?难道又是宿主机有问题?接着仔细一看,诶,这个机器 ip 怎么看着有点眼熟,这时候脑子里有了一个不好的想法……
于是,我把剩下的几个服务都上去看了一遍日志,果不其然,基本上每个服务都有这种错误存在。
难道线上流量有这么大?
到这里,感觉有必要弄清楚,到底端口号都哪去了,怎么就都被占了呢,不然再下去可能整套微服务都要挂了(人可能也要没了)。
于是,一次线上问题的排查战开始展开。。。
号角吹响
作为一个还没见过的错误,第一反应很自然就是谷歌,搜索结果显示,很多人都是因为请求完成后连接不是立即释放,而是处于 TIME_WAIT 状态导致的:
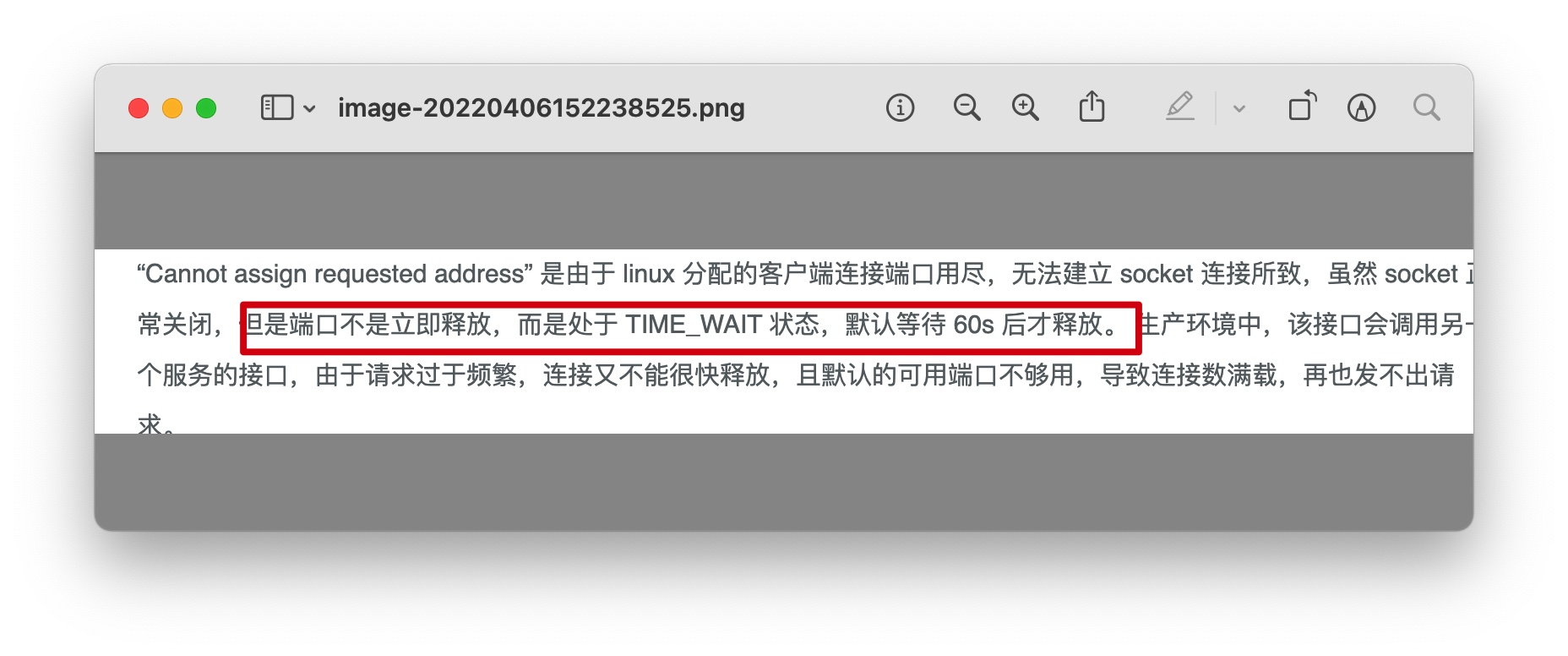
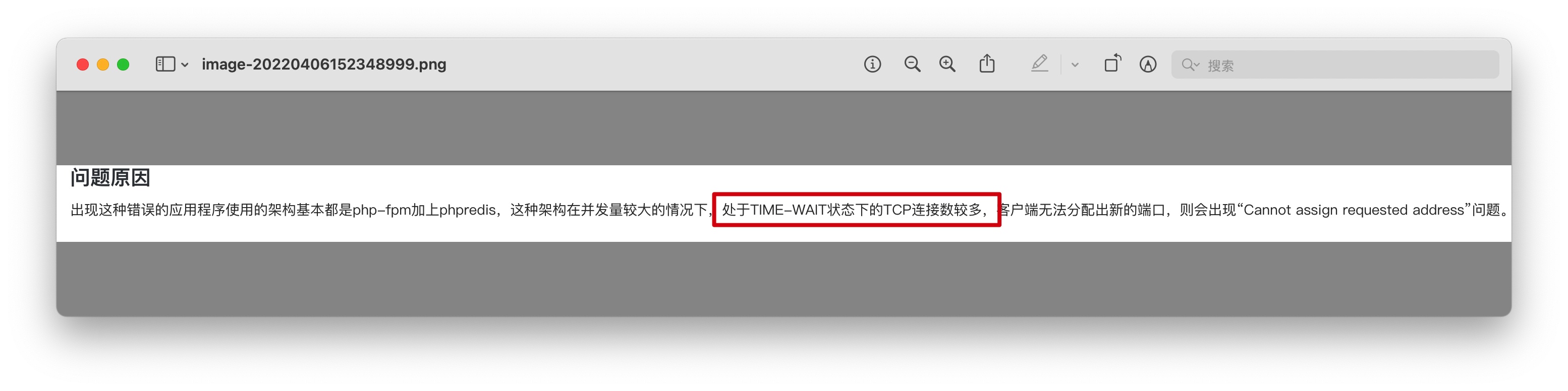
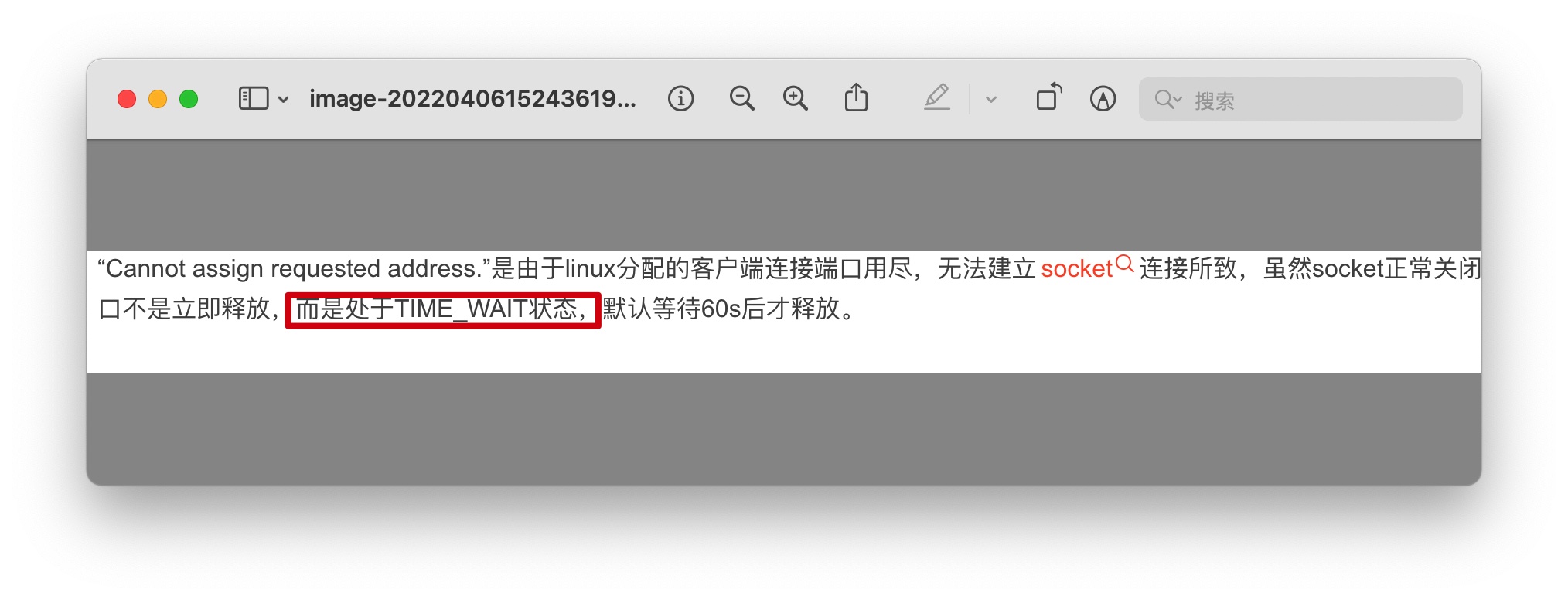
解决的办法也很简单,只需要对 Linux 的相关参数进行优化,缩短 TIME_WAIT 的时间,增加可提供的端口范围即可:
// 表示开启重用。允许将 TIME-WAIT sockets 重新用于新的 TCP 连接,默认为 0,表示关闭
net.ipv4.tcp_tw_reuse=1
//修改系默认的 TIMEOUT 时间,默认为60s
net.ipv4.tcp_fin_timeout=15
// 表示用于向外连接的端口范围。设置为 1024 到 65535
net.ipv4.ip_local_port_range=1024 65535
看起来似乎这个问题很容易解决嘛,看来今天又可以美美的下班了。
出师未捷
在上手开始操作之前,我打算先看看现在的 TIME_WAIT 数量到底有多少,于是,Google 一条显示当前连接状态的命令(真的记不住。。。),熟练的按下 command+C,command+V:
netstat -an | awk '/^tcp/ {++y[$NF]} END {for(w in y) print w, y[w]}'
LISTEN 54
ESTABLISHED 142640
SYN_SENT 2
TIME_WAIT 216
。。。
。。。
。。。
一般来说,处于网络连接中的状态主要有以下几个:
CLOSED:无连接是活动的或正在进行LISTEN:服务器在等待进入呼叫SYN_RECV:一个连接请求已经到达,等待确认SYN_SENT:应用已经开始,打开一个连接ESTABLISHED:正常数据传输状态FIN_WAIT1:应用说它已经完成FIN_WAIT2:另一边已同意释放ITMED_WAIT:等待所有分组死掉CLOSING:两边同时尝试关闭TIME_WAIT:表示处理完毕,等待超时结束的请求数。LAST_ACK:等待所有分组死掉
当看到打印出来的结果是,我整个人是有点懵的,这怎么跟书上说的好像不太一样啊,说好的是 TIME_WAIT 数量太多了呢?另外,ESTABLISHED 的数量未免也太多了,为什么机器上建立起了这么多的连接?
为了进一步分析问题,我又到其他的容器节点上查看网络连接情况,基本上每台机器的 ESTABLISHED 数量都高达十几万。
于是乎,Google 搜索框的内容变成了:
这时,组里的大佬提点了一句,一直这样查也查不出什么,不如先看看这些连接是从哪里来的。
确实,马克思主义教导我们,脱离实践的理论都是空洞的理论,一切还得从实际出发,那不如先来看看这些连接都是从哪里来的。
渐入佳境
于是我在容器上,用 netstat 命令统计了本机发起的链接,过滤出处于 ESTABLISHED 链接状态的连接,看看大部分是来自于本机哪个端口:
netstat -na | grep ESTABLISHED | awk '{print $4}' | sort | uniq -c|sort -n
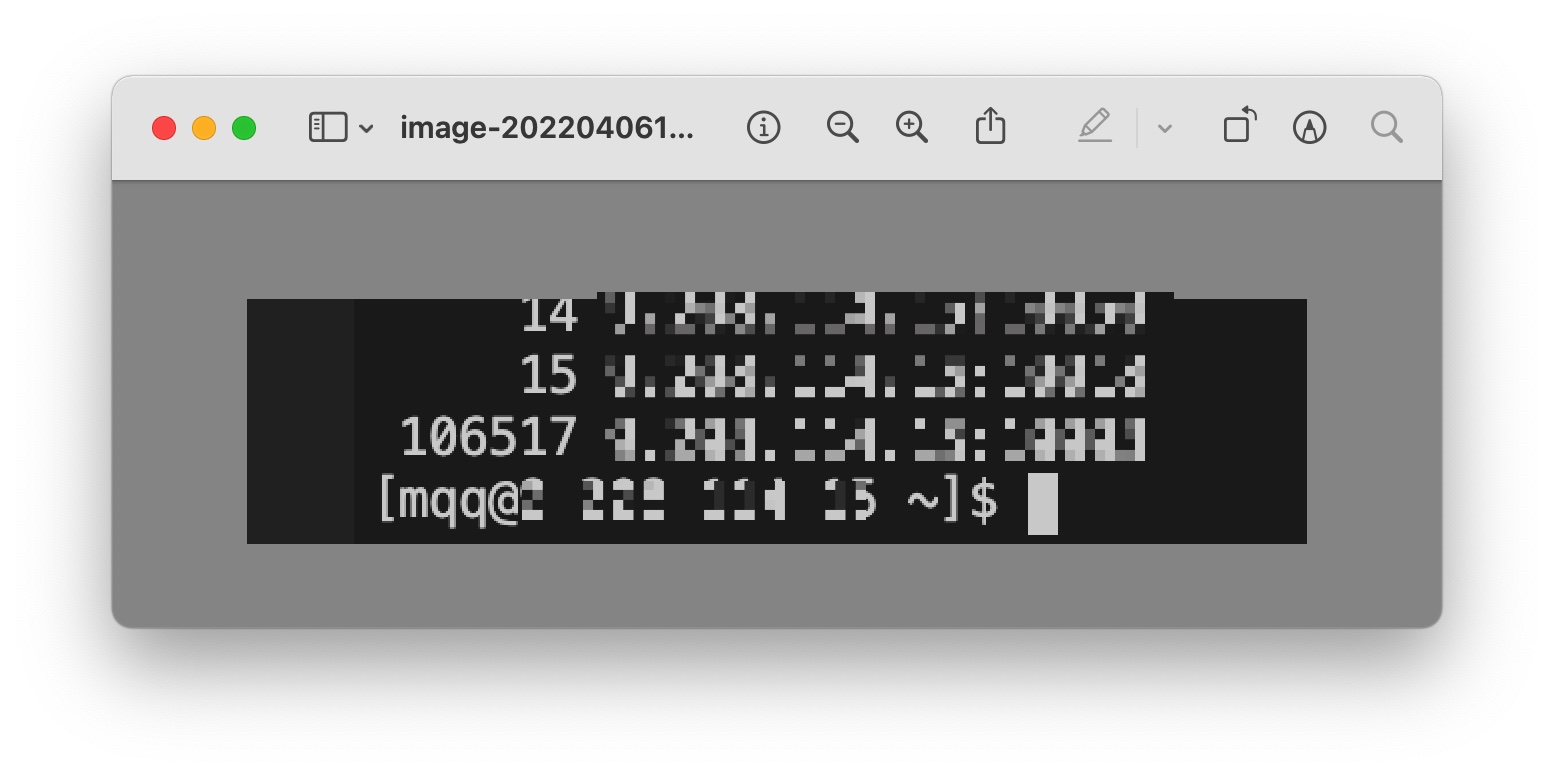
结果很让我意外,某一个 ipport 的连接居然高达 10w+,更让我意外的是,这个地址,竟然是我们部署的某一个微服务!
到这里,问题的根源就呼之欲出了。。。
是它!就是它!内存泄漏!!!而且很有可能就是 http 请求导致的内存泄漏。
为了进一步验证是不是由于 http 的内存泄漏所导致的问题,决定用 pprof 神器进行进一步的分析:
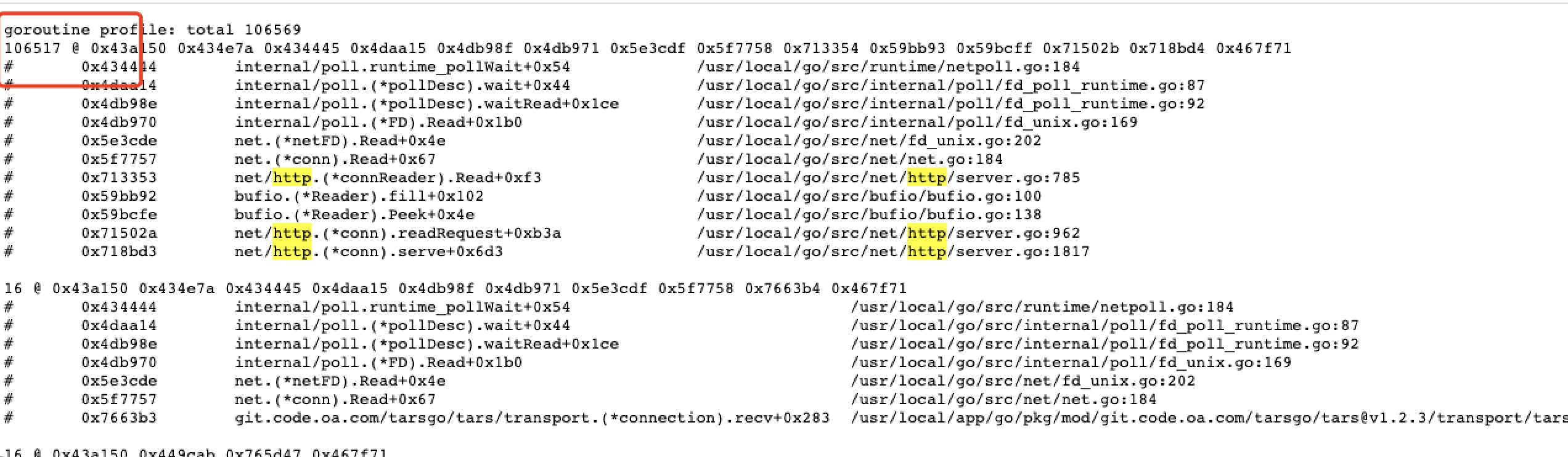
果然,从打印的 goroutine 信息来看,无疑是发生了 http 的内存泄漏,那很可能就是代码里对于发送 http 请求后的 body 没有进行处理(读取 body 内容或者 close)导致的,定位我们自身的业务代码,果然找到了其中一段内容:
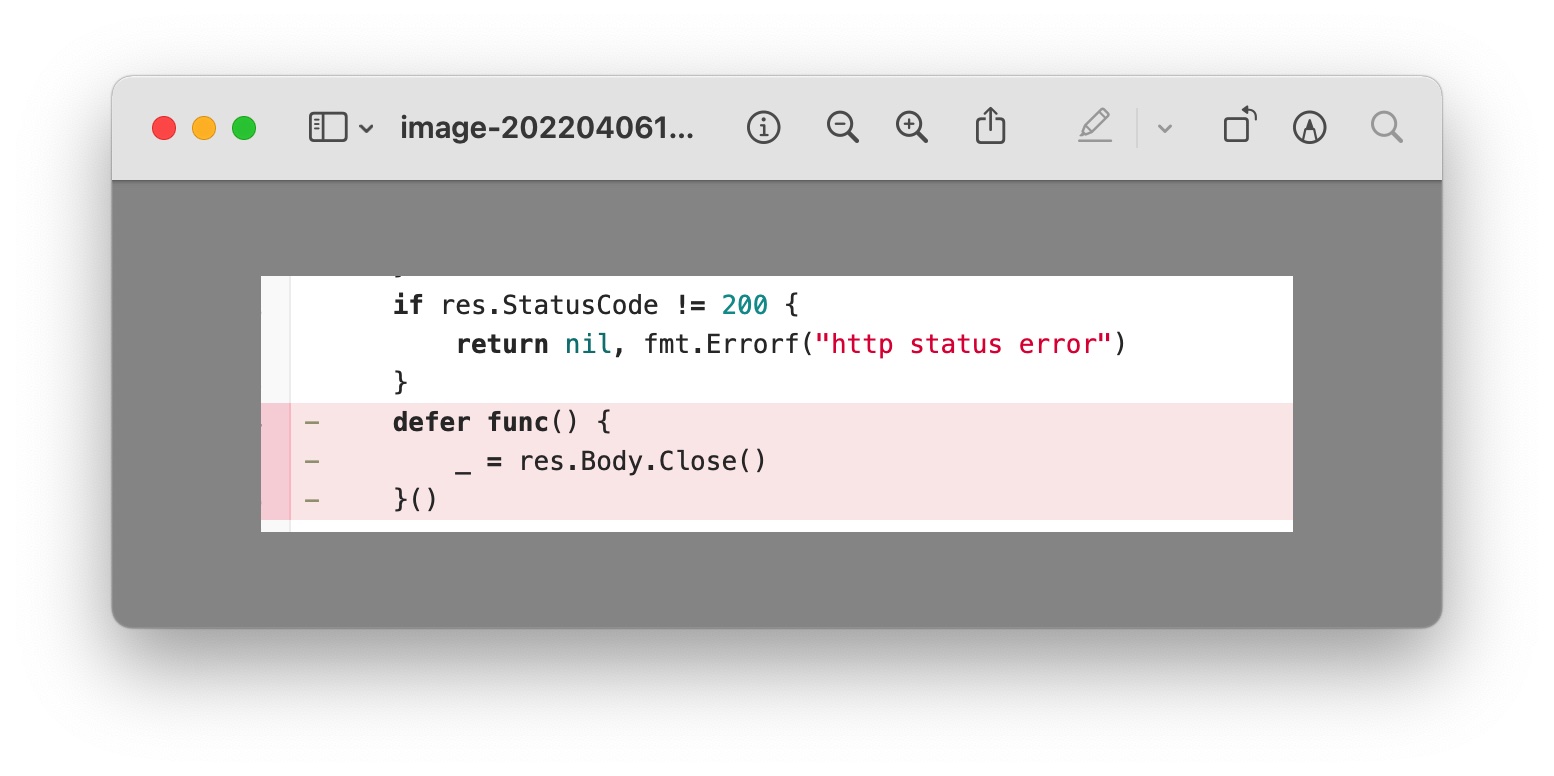
而在其调用的下游 http 服务中,存在返回 404 的场景:
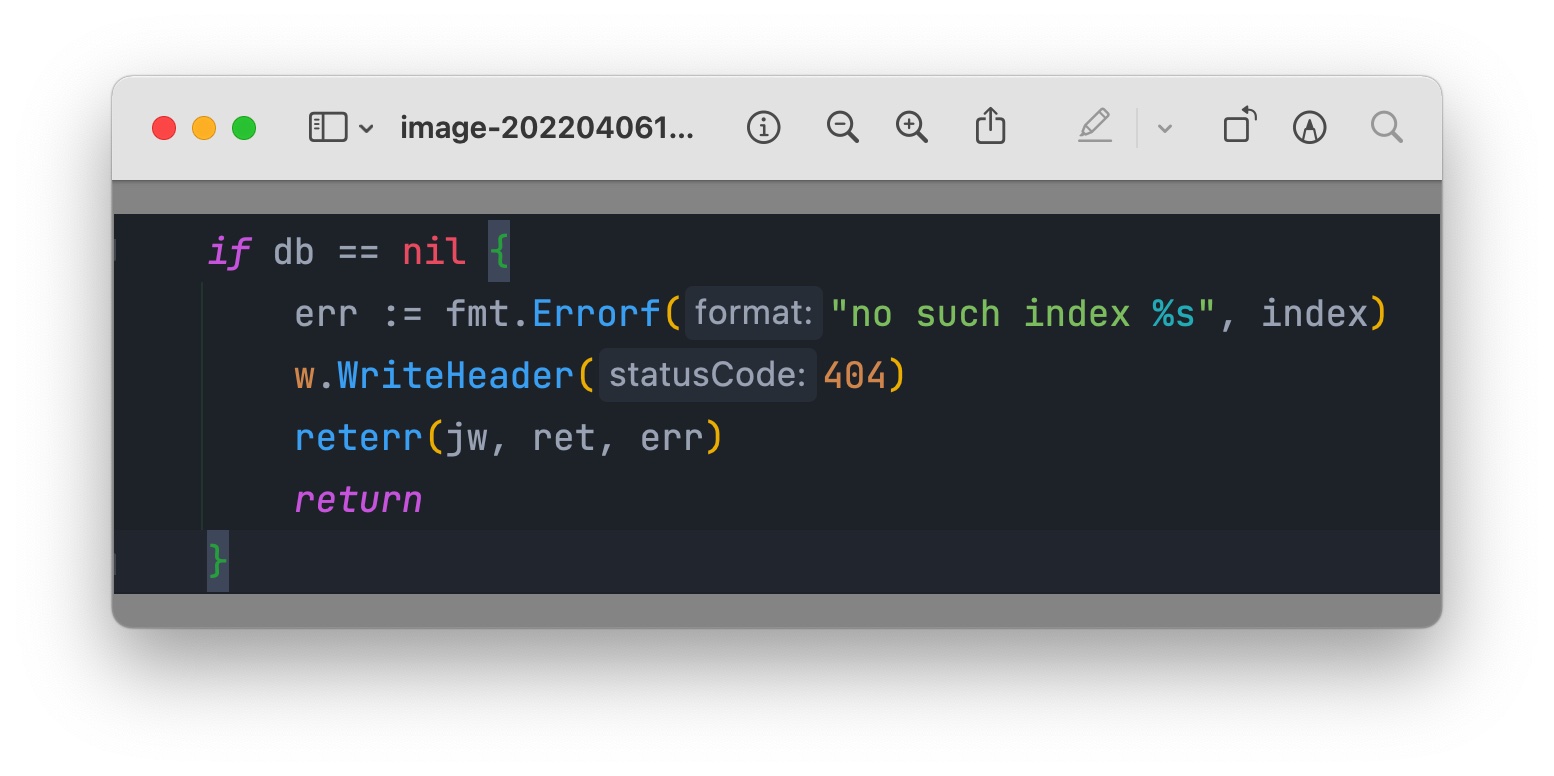
所以,当下游服务返回 404 时,上游服务直接进行了 return,既没有把 rsp body 的内容读取出来,也没有执行下面的 Close 操作,这就导致了连接即没有办法进行复用,也无法进行回收的尴尬处境,导致连接一直无法释放,造成内存泄漏。
而在我们的业务中,下游服务返回 404 在某些场景下是比较常见的,这就导致了大量的 goroutine 泄漏,出现了上面的问题。
于是,赶紧一顿输出,赶在节前把 bug 解决掉,美美下班回家过节。
知其然,知其所以然
书接上文提到的,在进行 http 请求后,如果没有把 rsp body 的内容读取出来,或者执行 body 的 Close 操作,就会导致连接无法被复用,也无法进行回收,那这里是为什么呢?
欲知此事如何,请听下文源码分析。(内容相对枯燥,谨慎入内。。。)
以 http.Get 方法为例:
es, err := client.Do(req)
func (c *Client) Do(req *Request) (*Response, error) {
return c.do(req)
}
func (c *Client) do(req *Request) (retres *Response, reterr error) {
//...
if resp, didTimeout, err = c.send(req, deadline); err != nil {
//...
}
//...
}
func (c *Client) send(req *Request, deadline time.Time) (resp *Response, didTimeoutfunc() bool, err error) {
//...
// 这里关注下 c.transport 和 send 方法
resp, didTimeout, err = send(req, c.transport(), deadline)
//...
}
// 可以看到,http 的请求采用 DefaultTransport 进行连接管理
func (c *Client) transport() RoundTripper {
if c.Transport != nil {
return c.Transport
}
return DefaultTransport
}
func send(ireq *Request, rt RoundTripper, deadline time.Time) (resp *Response, didTimeout func() bool, err error) {
//...
resp, err = rt.RoundTrip(req)
//...
}
// 这里开始进入 RoundTrip 逻辑
// src/net/http/roundtrip.go
func (t *Transport) RoundTrip(req *Request) (*Response, error) {
return t.roundTrip(req)
}
func (t *Transport) roundTrip(req *Request) (*Response, error) {
//...
// 这里会获取一个空闲链接,该链接有可能是连接池里的,也有可能是新创建出来的
pconn, err := t.getConn(treq, cm)
//...
}
// 这个函数是重点,返回一个长连接
func (t *Transport) getConn(treq *transportRequest, cm connectMethod) (pc *persistConn, err error) {
//...
// 这里尝试从空闲连接中获取一个连接
if delivered := t.queueForIdleConn(w); delivered {
//...
return w.pc,nil
}
//...
// 如果上面没有获取到连接,在这个函数里创建连接
t.queueForDial(w)
//...
}
// 使用空闲连接
func (t *Transport) queueForIdleConn(w *wantConn) (delivered bool) {
//...
if list, ok := t.idleConn[w.key]; ok {
//...
}
//...
}
// 创建连接
func (t *Transport) queueForDial(w *wantConn) {
//...
// 如果没有限制最大连接数,则直接创建新的连接
if t.MaxConnsPerHost <= 0 {
go t.dialConnFor(w)
return
}
//...
// 如果有最大连接数限制就判断是否已经超过了最大连接,没超过直接创建
if n := t.connsPerHost[w.key]; n < t.MaxConnsPerHost {
if t.connsPerHost == nil {
t.connsPerHost = make(map[connectMethodKey]int)
}
t.connsPerHost[w.key] = n + 1
go t.dialConnFor(w)
return
}
//...
// 超过了放到等待队列里
q := t.connsPerHostWait[w.key]
//...
}
// 创建新的连接都会走到这个方法
func (t *Transport) dialConnFor(w *wantConn) {
//...
// 在这里创建连接
pc, err := t.dialConn(w.ctx, w.cm)
//...
}
func (t *Transport) dialConn(ctx context.Context, cm connectMethod) (pconn *persistConn, err error) {
//...
conn, err := t.dial(ctx, "tcp", cm.addr())
//...
// 创建两个协程,一个读一个写
go pconn.readLoop()
go pconn.writeLoop()
//...
}
首先,Get 方法一路会走到 Transport 的 getConn 方法里(前面还有很长的流程,这里就忽略了),这个方法会优先尝试从没有释放的空闲连接中获取一个连接,如果没有则执行连接创建。
/ 这个函数是重点,返回一个长连接
func (t *Transport) getConn(treq *transportRequest, cm connectMethod) (pc *persistConn, err error) {
//...
// 这里尝试从空闲连接中获取一个连接
if delivered := t.queueForIdleConn(w); delivered {
//...
return w.pc,nil
}
//...
// 如果上面没有获取到连接,在这个函数里创建连接
t.queueForDial(w)
//...
}
创建新连接的方法是 dialConn,这个方法也很长,但是这里的重点在方法结尾处的两行:
func (t *Transport) dialConn(ctx context.Context, cm connectMethod) (pconn *persistConn, err error) {
// ...
go pconn.readLoop()
go pconn.writeLoop()
return pconn, nil
}
可以看到,一旦创建一个新连接,就会启动一个读 goroutine 和一个写 goroutine。这两个 goroutine 内部都是一个 for 循环,只有在满足特定的条件下,才会退出循环。
那么,这两个 goroutine 在什么时候释放呢?
先看看 writeLoop:
func (pc *persistConn) writeLoop() {
defer close(pc.writeLoopDone)
for {
select {
case wr := <-pc.writech:
startBytesWritten := pc.nwrite
err := wr.req.Request.write(pc.bw, pc.isProxy, wr.req.extra, pc.waitForContinue(wr.continueCh))
// ...
if err != nil {
pc.close(err)
return
}
case <-pc.closech:
return
}
}
}
writeLoop 退出循环的场景,一个是执行 request 的写入失败,另外一个就是当前连接被关闭。
readLoop 的代码则相对复杂一些:
func (pc *persistConn) readLoop() {
//...
alive := true
for alive {
//...
if resp.Close || rc.req.Close || resp.StatusCode <= 199 || bodyWritable {
// Don't do keep-alive on error if either party requested a close
// or we get an unexpected informational (1xx) response.
// StatusCode 100 is already handled above.
alive = false
}
//...
if !hasBody || bodyWritable {
replaced := pc.t.replaceReqCanceler(rc.cancelKey, nil)
// Put the idle conn back into the pool before we send the response
// so if they process it quickly and make another request, they'll
// get this same conn. But we use the unbuffered channel 'rc'
// to guarantee that persistConn.roundTrip got out of its select
// potentially waiting for this persistConn to close.
// 这里判断如果请求的 body 没有内容并且 response 的 body 可写,会直接把连接放回空闲连接池
// 在上面的注释中表示,golang 会避免一个连接在短时间内刚被放回连接池又被取出来使用,导致两次拿到同一个连接
alive = alive &&
!pc.sawEOF &&
pc.wroteRequest() &&
replaced && tryPutIdleConn(trace)
//...
}
//...
// Before looping back to the top of this function and peeking on
// the bufio.Reader, wait for the caller goroutine to finish
// reading the response body. (or for cancellation or death)
select {
case bodyEOF := <-waitForBodyRead:
replaced := pc.t.replaceReqCanceler(rc.cancelKey, nil) // before pc might return to idle pool
alive = alive &&
bodyEOF &&
!pc.sawEOF &&
pc.wroteRequest() &&
replaced && tryPutIdleConn(trace)
if bodyEOF {
eofc <- struct{}{}
}
case <-rc.req.Cancel:
alive = false
pc.t.CancelRequest(rc.req)
case <-rc.req.Context().Done():
alive = false
pc.t.cancelRequest(rc.cancelKey, rc.req.Context().Err())
case <-pc.closech:
alive = false
}
//...
}
}
readLoop 函数同样也是一个 for 循环,而退出循环的条件是 alive 的值是 false ,那么 alive 什么时候会是 false 呢?
从上面的代码中可以看到,只有在以下几种场景中,存在 alive 是 false ,使得 goroutine 退出的可能:
- request 或者 respone 任何一方请求关闭连接,或者收到 1xx 的状态码。
body被读取完毕或者body被关闭。request主动cancel。request的context Done状态为true。- 当前连接被关闭。
这里来分析一下第二种场景(body 被读取完毕或者 body 被关闭),其对应的代码段为:
case bodyEOF := <-waitForBodyRead:
alive = alive &&
bodyEOF &&
!pc.sawEOF &&
pc.wroteRequest() &&
replaced && tryPutIdleConn(trace)
这里 alive 是否为 true 便取决于 bodyEOF 的值,bodyEOF 来源于一个通道 waitForBodyRead,这个通道的值则来自:
waitForBodyRead := make(chan bool, 2)
body := &bodyEOFSignal{
body: resp.Body,
earlyCloseFn: func() error {
waitForBodyRead <- false
<-eofc // will be closed by deferred call at the end of the function
return nil
},
fn: func(err error) error {
isEOF := err == io.EOF
waitForBodyRead <- isEOF
if isEOF {
<-eofc // see comment above eofc declaration
} else if err != nil {
if cerr := pc.canceled(); cerr != nil {
return cerr
}
}
return err
},
}
在上面的代码中,如果执行了 earlyCloseFn,那么 waitForBodyRead 就会输入 false,alive 也就会是 false,此时会退出 readLoop 这个循环。
如果执行了 fn,其中包括正常情况下 body 读完数据抛出 io.EOF 时的 case,此时 waitForBodyRead 通道输入时 true,alive 也会是 true, 它会接着往下执行 tryPutIdleConn(trace),将 pconn 连接放回到空闲队列中等待新的请求,也就是该连接会被复用。
那接下来就是看看 earlyCloseFn 和 fn 这两个方法分别是在什么场景下执行了。
还记得我们上面说的两种场景吗?再帮大家回忆一下,要使连接能够被回收复用,有两个方式是可以做到的:
- 把 rsp body 的内容全部读取出来;
- 执行 body 的
Close操作。
首先来看看读取 rsp body 的场景:
body, err := ioutil.ReadAll(rsp.Body)
func ReadAll(r io.Reader) ([]byte, error) {
return io.ReadAll(r)
}
func ReadAll(r Reader) ([]byte, error) {
//...
n, err := r.Read(b[len(b):cap(b)])
//...
}
func (es *bodyEOFSignal) Read(p []byte) (n int, err error) {
//...
n, err = es.body.Read(p)
if err != nil {
es.mu.Lock()
defer es.mu.Unlock()
if es.rerr == nil {
es.rerr = err
}
// 这里会有一个 io.EOF 的报错,因为 ReadAll 读取完了全部的数据
err = es.condfn(err)
}
return
}
func (es *bodyEOFSignal) condfn(err error) error {
if es.fn == nil {
return err
}
// 这里就执行了 fn
err = es.fn(err)
es.fn = nil
return err
}
可以看到,在最后读取完毕之后,会执行 fn ,而这里的入参 err 因为已经读取完了所有内容,所以是一个 io.EOF,所以此时 waitForBodyRead 输入 true,alive 继续会 true,此时 readLoop 继续存在,并不会退出,此时会执行 tryPutIdleConn(trace) 把连接放回池子里复用。
再看看 Close 的场景:
func (es *bodyEOFSignal) Close() error {
es.mu.Lock()
defer es.mu.Unlock()
if es.closed {
return nil
}
es.closed = true
if es.earlyCloseFn != nil && es.rerr != io.EOF {
return es.earlyCloseFn()
}
err := es.body.Close()
return es.condfn(err)
}
可以看到,如果在读取到了非 io.EOF 错误时(也就是 rsp.Body 的内容没有被读取完毕的场景下)会执行会执行 earlyCloseFn,此时 waitForBodyRead 会输入 false,那么 alive 就会是 false 从而使得 readLoop 退出。
而如果 body 内容已经被读取完毕,则同样调用 fn ,此时连接不会退出,但是可以在下次有需要新连接时被复用。
到了这里,再回顾一下上面 raedLoop 退出的几个条件:
case bodyEOF := <-waitForBodyRead:
replaced := pc.t.replaceReqCanceler(rc.cancelKey, nil) // before pc might return to idle pool
alive = alive &&
bodyEOF &&
!pc.sawEOF &&
pc.wroteRequest() &&
replaced && tryPutIdleConn(trace)
if bodyEOF {
eofc <- struct{}{}
}
case <-rc.req.Cancel:
alive = false
pc.t.CancelRequest(rc.req)
case <-rc.req.Context().Done():
alive = false
pc.t.cancelRequest(rc.cancelKey, rc.req.Context().Err())
case <-pc.closech:
alive = false
}
- request 或者 respone 任何一方请求关闭连接,或者收到 1xx 的状态码。
body被读取完毕或者body被关闭。request主动cancel。request的context Done状态为true。- 当前连接被关闭。
所以,经过上面花里胡哨的分析,可以知道,如果一个请求拿到响应后,既没有读取 body 的所有内容,也没有对 body 执行 Close 操作,将导致两个 goroutine 一直没法被回收,造成内存泄漏。
而如果读取了 body 的所有内容或者把 body close 掉,则可以使连接得以释放复用。
当然,这两种场景导致的结果也不相同。对于只读取 body 的场景,连接并不会被释放掉,而是作为空闲链接等待下一次的复用。而对于关闭 body 的场景,则分为两种情况,当 body 内容被读取完毕时,连接能够进行复用;而当 body 内容没有被读取完毕时,连接会被释放掉,下一次请求会重新建立连接。
理论实践相结合
前面逼逼赖赖说了那么多,但是事实到底是不是如此呢?
都说实践是检验真理的唯一标准,那么下面我们就来验证一下上面的观点。
正常读取和关闭
func main() {
num := 10
for index := 0; index < num; index++ {
rsp, err := http.Get("https://www.baidu.com")
if err != nil {
continue
}
io.Copy(ioutil.Discard, rsp.Body)
rsp.Body.Close()
}
fmt.Printf("此时goroutine个数= %d\n", runtime.NumGoroutine())
time.Sleep(time.Second * 90) // 一段时间连接空闲,自动关闭,默认值是 90s
fmt.Printf("此时goroutine个数= %d\n", runtime.NumGoroutine())
}
执行结果:
此时goroutine个数= 3
此时goroutine个数= 1
只读取不关闭
func main() {
num := 10
for index := 0; index < num; index++ {
rsp, err := http.Get("https://www.baidu.com")
if err != nil {
continue
}
io.Copy(ioutil.Discard, rsp.Body)
//rsp.Body.Close()
}
fmt.Printf("此时goroutine个数= %d\n", runtime.NumGoroutine())
time.Sleep(time.Second * 10) // 一段时间连接空闲,看看连接是否释放
fmt.Printf("此时goroutine个数= %d\n", runtime.NumGoroutine())
time.Sleep(time.Second * 90) // 一段时间连接空闲,自动关闭,默认值是 90s
fmt.Printf("此时goroutine个数= %d\n", runtime.NumGoroutine())
}
执行结果:
此时goroutine个数= 3
此时goroutine个数= 3
此时goroutine个数= 1
只关闭不读取
func main() {
num := 10
for index := 0; index < num; index++ {
rsp, err := http.Get("https://www.baidu.com")
if err != nil {
continue
}
//io.Copy(ioutil.Discard, rsp.Body)
rsp.Body.Close()
}
fmt.Printf("此时goroutine个数= %d\n", runtime.NumGoroutine())
time.Sleep(time.Second * 10) // 一段时间连接空闲,看看连接是否关闭
fmt.Printf("此时goroutine个数= %d\n", runtime.NumGoroutine())
time.Sleep(time.Second * 90) // 一段时间连接空闲,自动关闭,默认值是 90s
fmt.Printf("此时goroutine个数= %d\n", runtime.NumGoroutine())
}
执行结果:
此时goroutine个数= 3
此时goroutine个数= 1
此时goroutine个数= 1
既不关闭也不读取
func main() {
num := 10
for index := 0; index < num; index++ {
_, err := http.Get("https://www.baidu.com")
if err != nil {
continue
}
//io.Copy(ioutil.Discard, rsp.Body)
//rsp.Body.Close()
}
fmt.Printf("此时goroutine个数= %d\n", runtime.NumGoroutine())
time.Sleep(time.Second * 10) // 一段时间连接空闲,看看连接是否关闭
fmt.Printf("此时goroutine个数= %d\n", runtime.NumGoroutine())
time.Sleep(time.Second * 90) // 一段时间连接空闲,自动关闭,默认值是 90s
fmt.Printf("此时goroutine个数= %d\n", runtime.NumGoroutine())
}
执行结果:
此时goroutine个数= 21
此时goroutine个数= 21
此时goroutine个数= 21
可以看到,在最后一种场景下,会造成 goroutine 的泄漏。
综上,我们日常在写代码的过程中,对于需要执行 HTTP 请求的场景,一定记得 resp.Body.Close,这也是一个良好的代码习惯:
res, err := http.Get(url)
if err != nil {
log.Printf("Error: %s\n", err)
return
}
defer res.Body.Close()
多提一些题外话,在网上查看的时候,发现有很多博客上认为应该采用下面的写法:
res, err := http.Get(url)
defer func() {
if res != nil && res.Body != nil {
res.Body.Close()
}
}()
if err != nil {
log.Printf("Error: %s\n", err)
return
}
上面的代码为什么不是在 err != nil 的场景下才执行 Close 呢?原因是在于存在一种特殊的场景:当请求得到一个重定向的错误时,此时返回的 body 内容并非空的。
初看上面的代码总感觉很奇怪,而且感觉这似乎不属于 Golang 的风格,于是去搜刮了一下 Golang 的官方仓库,发现之前确实存在这种问题,但是在后续的版本其实已经做了处理。
现有的版本下,如果出现重定向的错误,其返回的 body 虽然不为空,但是其实已经对其进行了 Close 操作,这一步主要在上面的 do 方法中执行:
func (c *Client) do(req *Request) (retres *Response, reterr error) {
//...
// Sentinel error to let users select the
// previous response, without closing its
// body. See Issue 10069.
if err == ErrUseLastResponse {
return resp, nil
}
// Close the previous response's body. But
// read at least some of the body so if it's
// small the underlying TCP connection will be
// re-used. No need to check for errors: if it
// fails, the Transport won't reuse it anyway.
const maxBodySlurpSize = 2 << 10
if resp.ContentLength == -1 || resp.ContentLength <= maxBodySlurpSize {
io.CopyN(io.Discard, resp.Body, maxBodySlurpSize)
}
resp.Body.Close()
if err != nil {
// Special case for Go 1 compatibility: return both the response
// and an error if the CheckRedirect function failed.
// See https://golang.org/issue/3795
// The resp.Body has already been closed.
ue := uerr(err)
ue.(*url.Error).URL = loc
return resp, ue
}
// ...
}
有兴趣的可以看看下面的两个 Issue 和 commit 记录:
- net/http has broken compatibility on redirection handler #3795
- net/http: redirection response has closed body #10069
- net/http: clean up the Client redirect code, document Body.Close rule…
后记
通过这次内存泄漏的排查,也学到不少新技能,从发现问题,到问题分析,定位问题,再到源码了解,一步一步走过来,积累了很多知识,也很感谢组里大佬们的帮助,让自己从中学到了很多实用的经验。
以上分析内容如果有不正确的地方,欢迎各位大佬们批评指正!下次线上问题,再会!(希望没有下次了~)
给大家丢脸了,用了三年golang,我还是没答对这道内存泄漏题