go 常用关键字的原理及设计
for 和 range
循环是几乎所有编程语言都具有的控制结构,也是编程语言中常用的控制结构,Go 语言除了使用经典的三段式循环之外,还引入了另一个关键字 range 用于快速遍历数组、哈希表以及 Channel 等元素。
这里主要记录 Go 语言中的两种不同循环,也就是经典的 for 循环和 for…range 循环,分析这两种循环在运行时的结构以及它们的实现原理。
for 循环和 for…range 循环的形式分别如下:
func main() {
// for 循环
for i := 0; i < 10; i++ {
println(i)
}
// for range 循环
arr := []int{1, 2, 3}
for i, _ := range arr {
println(i)
}
}
在汇编语言中,无论是经典的 for 循环还是 for-range 循环都会使用 JMP 等命令跳回循环体的开始位置复用代码,所以使用 for…range 语法的控制结构最终应该也会被 Go 语言的编译器转换成普通的 for 循环。
接下来将逐个分析每一种循环的场景。
for 经典循环
Go 语言中的for 经典循环在编译器看来就是一个 OFOR 类型的节点,这个节点具有以下的结构:
for Ninit; Left; Right {
NBody
}
其中包括初始化循环的 Ninit、循环的中止条件 Left、循环体结束时执行的 Right 表达式以及循环体 NBody。
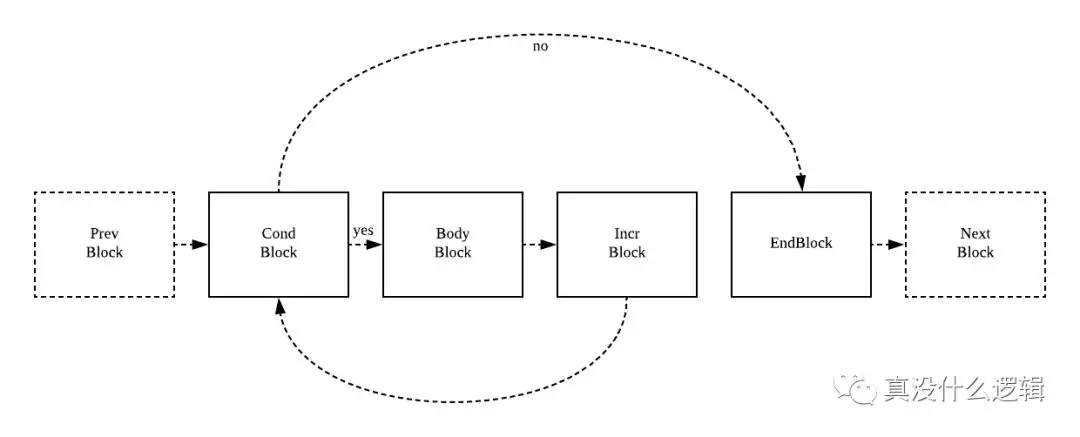
一个常见的 for 循环代码会被 stmt 方法转换成以下的控制结构,其中包含了 4 个不同的块,这些不同的代码块之间会通过边去连接,与我们理解的 for 循环控制结构其实没有太多的差别。
for-range 范围循环
范围循环在 go 中更为常见,它会使用 for 和 range 两个关键字,编译器会在编译期间将带有 range 的循环变成普通的经典循环,也就是将 ORANGE 类型的节点转换成 OFOR 类型。所有的 range 都会被 walkrange 函数转换成只包含基本表达式的语句,不包含任何复杂的结构。
下面分别分析每一种结构下的循环场景。
数组和切片
对于数组和切片来说,for-range 循环有三种不同的遍历方式,这三种不同的遍历方式会在 walkrange 函数中被转换成不同的控制逻辑,这三种不同的逻辑分别对应着代码中的不同条件。
清空数组和切片
当想要清空数组或者哈希表等结构时,通常会使用遍历清除的方式:
func main() {
arr := []int{1, 2, 3}
for i, _ := range arr {
arr[i] = 0
}
}
依次遍历切片和哈希是非常耗费性能的,因为数组、切片和哈希占用的内存空间都是连续的,所以最快的方法是直接清空这片内存中的内容。在 go 的编译器中,针对这种情况,编译器会直接使用 memclrNoHeapPointers 直接清空切片中的数据。
在 walkrange 最开始的逻辑就是数组和切片的清空逻辑:
func walkrange(n *Node) *Node {
switch t.Etype {
case TARRAY, TSLICE:
if arrayClear(n, v1, v2, a) {
return n
}
arrayClear 是一个非常有趣的优化,当在 Go 语言中遍历去删除所有的元素时,其实会在这个函数中被优化成如下的代码:
// 原代码
for i := range a {
a[i] = zero
}
// 优化后
if len(a) != 0 {
hp = &a[0]
hn = len(a)*sizeof(elem(a))
memclrNoHeapPointers(hp, hn)
i = len(a) - 1
}
相比于依次清除数组或者切片中的数据,Go 语言会直接使用 memclrNoHeapPointers 或者 memclrHashPointers 函数直接清除目标数组对应内存空间中的数据并在执行完成后更新用于遍历数组的索引,保证上下文不会出现问题,这也印证了我们在概述一节中观察到的现象。
for range a {} 遍历数组和切片
在处理了上面清空这种特殊的情况之后,继续回到 ORANGE 节点的处理过程了,在这里首先会设置 for 循环的 Left 和 Right 字段,也就是终止的条件和循环体每次执行结束后运行的代码:
ha := a
hv1 := temp(types.Types[TINT])
hn := temp(types.Types[TINT])
init = append(init, nod(OAS, hv1, nil))
init = append(init, nod(OAS, hn, nod(OLEN, ha, nil)))
n.Left = nod(OLT, hv1, hn)
n.Right = nod(OAS, hv1, nod(OADD, hv1, nodintconst(1)))
if v1 == nil {
break
}
如果循环是 for range a {},那么就满足了上述代码中的条件 v1 == nil,即循环不关心数组的索引和数据,在这种情况下只是单纯的遍历,并不关心索引和数据的情况,那么它会被转换成如下所示的代码:
ha := a
hv1 := 0
hn := len(ha)
v1 := hv1
for ; hv1 < hn; hv1++ {
// ...
}
这其实是最简单的 range 结构在编译期间被转换后的形式,由于原代码其实并不需要数组中任何元素的信息,只需要使用数组或者切片的数量执行对应次数的循环。
for i := range a {} 遍历数组和切片
如果我们只需要使用遍历数组时的索引就会执行如下的代码:
if v2 == nil {
body = []*Node{nod(OAS, v1, hv1)}
break
}
它会将类似 for i := range a {} 的结构转换成如下所示的逻辑,与第一种循环相比,这种循环额外地在循环体中添加了 v1 := hv1 用于传递遍历数组时的索引:
ha := a
hv1 := 0
hn := len(ha)
v1 := hv1
for ; hv1 < hn; hv1++ {
v1 := hv1
// ...
}
for i, elem := range a {} 遍历数组和切片
这种场景下需要同时获取索引和值,也是最常用的一种场景,处理这种情况在 walkrange 中使用如下代码:
tmp := nod(OINDEX, ha, hv1)
tmp.SetBounded(true)
a := nod(OAS2, nil, nil)
a.List.Set2(v1, v2)
a.Rlist.Set2(hv1, tmp)
body = []*Node{a}
}
n.Ninit.Append(init...)
n.Nbody.Prepend(body...)
return n
}
这段代码处理的就是类似 for i, elem := range a {} 的逻辑,它不止会在循环体中插入更新索引的表达式,还会插入赋值的操作让循环体内部的代码能够访问数组中的元素:
ha := a
hv1 := 0
hn := len(ha)
v1 := hv1
v2 := nil
for ; hv1 < hn; hv1++ {
tmp := ha[hv1]
v1, v2 = hv1, tmp
...
}
对于所有的 range 循环,Go 语言都会在编译期将原切片或者数组赋值给一个新变量 ha,在赋值的过程中就发生了拷贝,而我们又通过 len 关键字预先获取了切片的长度,所以此时遍历的切片其实已经不是原有的切片变量了。
下面的这个例子中,在每次循环中都往数组中加入的变量,以此试图构建一个永不停止的循环,然而实际上该循环只会循环三次,原因就是编译期间传入循环的是 arr 的一个拷贝,并不是当前实时的 arr,所以在循环中追加新的元素也不会改变循环执行的次数。
func main() {
arr := []int{1, 2, 3}
for _, v := range arr {
arr = append(arr, v)
}
fmt.Println(arr)
}
$ go run main.go
1 2 3 1 2 3
遇到这种同时遍历索引和元素的 range 循环时,从上面的代码中可以看到,Go 语言会额外创建一个新的 v2 变量存储切片中的元素,循环中使用的这个变量 v2 会在每一次迭代中都被重新赋值,在赋值时也发生了拷贝。
在下面的代码中,在一个循环中将 range 返回的变量值的地址赋值给另外一个新数组,当打印这个新数组中变量地址的值的时候,实际上这个新数组中的值都是老数组的最后一个值。
func main() {
arr := []int{1, 2, 3}
newArr := []*int{}
for _, v := range arr {
newArr = append(newArr, &v)
}
for _, v := range newArr {
fmt.Println(*v)
}
}
$ go run main.go
3 3 3
在这种场景下,**正确的做法应该是使用 &arr[i] 替代 &v **。
所以如果想要访问数组中元素所在的地址,不应该直接获取 range 返回的 v2 变量的地址 &v2,想要解决这个问题应该使用 &a[index] 这种方式获取数组中元素对应的地址。
func main() {
arr := []int{1, 2, 3}
newArr := []*int{}
for i, _ := range arr {
newArr = append(newArr, &arr[i])
}
for _, v := range newArr {
fmt.Println(*v)
}
}
在遇到这种问题时,应该使用如上所示的代码来获取数组中元素的地址,而不应该使用编译器生成的、会被复用的临时变量。
map
map 的遍历详细在这里:map 遍历
总的来说,哈希表的遍历会随机选择开始的位置,然后依次遍历桶中的元素,桶中元素如果被遍历完,就会遍历当前桶对应的溢出桶,溢出桶都遍历结束之后才会遍历哈希中的下一个桶,直到所有的桶都被遍历完成。
字符串
字符串的遍历与数组和哈希表非常相似,只是在遍历的过程中会获取字符串中索引对应的字节,然后将字节转换成 rune,我们在遍历字符串时拿到的值都是 rune 类型的变量,其实类似 for i, r := range s {} 的结构都会被转换成如下的形式:
ha := s
for hv1 := 0; hv1 < len(ha); {
hv1t := hv1
hv2 := rune(ha[hv1])
if hv2 < utf8.RuneSelf {
hv1++
} else {
hv2, hv1 = decoderune(h1, hv1)
}
v1, v2 = hv1t, hv2
}
这段代码的框架与上面提到的数组和哈希其实非常相似,只是细节有一些不同。字符串其实就是一个只读的字节数组切片,所以使用下标访问字符串中的元素时其实得到的就是字节,但是这段代码会将当前的字节转换成 rune 类型,如果当前的 rune 是 ASCII 的,那么只会占用一个字节长度,这时只需要将索引加一,但是如果当前的 rune 占用了多个字节就会使用 decoderune 进行解码,具体的过程就不详细介绍了。
通道
在 range 循环中使用 Channel 其实也是比较常见的做法,一个形如 for v := range ch {} 的表达式会最终被转换成如下的格式:
ha := a
hv1, hb := <-ha
for ; hb != false; hv1, hb = <-ha {
v1 := hv1
hv1 = nil
// ...
}
这里的代码可能与编译器生成的稍微有一些出入,但是结构和效果是完全相同的。该循环会使用 <-ch 从管道中取出等待处理的值,这个操作会调用 runtime.chanrecv2 并阻塞当前的协程,当 runtime.chanrecv2 返回时会根据布尔值 hb 判断当前的值是否存在:
- 如果不存在当前值,意味着当前的管道已经被关闭;
- 如果存在当前值,会为
v1赋值并清除hv1变量中的数据,然后重新陷入阻塞等待新数据;
常见现象总结
永不停止的循环
下面的代码中,在每次循环中都往数组中加入的变量,以此试图构建一个永不停止的循环,然而实际上该循环只会循环三次。
func main() {
arr := []int{1, 2, 3}
for _, v := range arr {
arr = append(arr, v)
}
fmt.Println(arr)
}
$ go run main.go
1 2 3 1 2 3
循环中的指针赋值
在下面的代码中,在一个循环中将 range 返回的变量值的地址赋值给另外一个新数组,当打印这个新数组中变量地址的值的时候,实际上这个新数组中的值都是老数组的最后一个值。
func main() {
arr := []int{1, 2, 3}
newArr := []*int{}
for _, v := range arr {
newArr = append(newArr, &v)
}
for _, v := range newArr {
fmt.Println(*v)
}
}
$ go run main.go
3 3 3
在这种场景下,正确的做法应该是使用 &arr[i] 替代 &v。
清空数组
当想要清空数组或者哈希表等结构时,通常会使用遍历清除的方式:
func main() {
arr := []int{1, 2, 3}
for i, _ := range arr {
arr[i] = 0
}
}
依次遍历切片和哈希是非常耗费性能的,因为数组、切片和哈希占用的内存空间都是连续的,所以最快的方法是直接清空这片内存中的内容。在 go 的编译器中,针对这种情况,编译器会直接使用 memclrNoHeapPointers 直接清空切片中的数据。
随机遍历
当遍历 map 结构时,每次遍历出来的结果的顺序都是不确定的,这是 Go 故意设计的,为了提高这种不确定性,go 甚至还做了一些工作,以此告诉所有使用 Go 语言的开发者不要依赖于哈希遍历的稳定。
defer
defer 主要用来做一些收尾的工作,例如关闭文件描述符、关闭数据库连接以及释放资源等。
在defer函数定义时,对外部变量的引用是有两种方式的,分别是作为函数参数和作为闭包引用。作为函数参数,则在 defer 定义时就把值传递给 defer,并被 cache 起来;作为闭包引用的话,则会在 defer 函数真正调用时根据整个上下文确定当前的值。
defer 后面的语句在执行的时候,函数调用的参数会被保存起来,也就是复制了一份。真正执行的时候,实际上用到的是这个复制的变量,因此如果此变量是一个“值”,那么就和定义的时候是一致的。如果此变量是一个“引用”,那么就可能和定义的时候不一致。
defer 的相关使用问题
示例一
func deferFuncParameter() {
var aInt = 1
defer fmt.Println(aInt)
aInt = 2
return
}
输出 1。延迟函数
fmt.Println(aInt)的参数在 defer 语句出现时就已经确定了,所以无论后面如何修改aInt变量都不会影响延迟函数。
示例二
package main
import "fmt"
func printArray(array *[3]int) {
for i := range array {
fmt.Println(array[i])
}
}
func deferFuncParameter() {
var aArray = [3]int{1, 2, 3}
defer printArray(&aArray)
aArray[0] = 10
return
}
func main() {
deferFuncParameter()
}
输出10、2、3三个值。延迟函数printArray()的参数在defer语句出现时就已经确定了,即数组的地址,由于延迟函数执行时机是在return语句之前,所以对数组的最终修改值会被打印出来。
示例三
func deferFuncReturn() (result int) {
i := 1
defer func() {
result++
}()
return i
}
函数输出 2。函数的 return 语句并不是原子的,实际执行分为设置返回值–>ret,defer 语句实际执行在返回前,即拥有 defer 的函数返回过程是:设置返回值–>执行defer–>ret。所以 return 语句先把 result 设置为i的值,即1,defer语句中又把result递增1,所以最终返回2。
示例四
func f() (r int) {
defer func(r int) {
r = r + 5
}(r)
return 1
}
根据上述 return 规则拆解,所以得到的结果是 1
func f() (r int) {
t := 1
// 1. 赋值指令
r = t
// 2. defer 被插入到赋值与返回之间执行,这里 r 是传值
func (r int) {
r = r + 5
}(r)
// 3. 空的 return
return
}
defer使用时的注意事项
defer 的执行时机
func main() {
{
defer fmt.Println("defer runs")
fmt.Println("block ends")
}
fmt.Println("main ends")
}
$ go run main.go
block ends
main ends
defer runs
defer 传入的函数不是在退出代码块的作用域时执行的,它只会在当前函数和方法返回之前被调用。
预计算参数:defer 语句的参数在它出现时就已经确定下来
func main() {
startedAt := time.Now()
defer fmt.Println(time.Since(startedAt))
time.Sleep(time.Second)
}
$ go run main.go
0s
当调用 defer 关键字时,它会立刻拷贝函数中引用的外部参数,所以 time.Since(startedAt) 的结果不是在 main 函数退出之前计算的,而是在 defer 关键字调用时计算的,最终导致上述代码输出 0s。
想要解决这个问题,只需要向 defer 关键字传入匿名函数:
func main() {
startedAt := time.Now()
defer func() { fmt.Println(time.Since(startedAt)) }()
time.Sleep(time.Second)
}
$ go run main.go
1s
虽然调用 defer 关键字时也使用值传递,但是因为拷贝的是函数指针,所以 time.Since(startedAt) 会在 main 函数返回前调用并打印出符合预期的结果。
注意:对于指针类型参数,规则仍然适用,只不过延迟函数的参数是一个地址值,这种情况下,defer 后面的语句对变量的修改可能会影响延迟函数。
延迟函数执行按后进先出的顺序执行
定义 defer 类似于入栈操作,执行 defer 类似于出栈操作。
设计 defer 的初衷是简化函数返回时资源清理的动作,资源往往有依赖顺序,比如先申请 A 资源,再跟据 A 资源申请 B 资源,跟据 B 资源申请 C 资源,即申请顺序是: A–>B–>C,释放时往往又要反向进行。这就是把 deffer 设计成 FIFO 的原因。
每申请到一个用完需要释放的资源时,立即定义一个 defer 来释放资源是个很好的习惯。
defer 可能操作主函数的具名返回值
定义 defer 的函数,即主函数可能有返回值,返回值有没有名字没有关系,defer 所作用的函数可能会影响到返回值。
若要理解延迟函数是如何影响主函数返回值的,需要明白函数是如何返回的。
函数的返回过程
关键字 return 不是一个原子操作,实际上 return 只代理汇编指令 ret,即将跳转程序执行。比如语句return i,实际上分两步进行:
- 将 i 值存入栈中作为返回值
- 然后执行跳转
而 defer 的执行时机正是跳转前,所以说 defer 执行时还是有机会操作返回值的。例如下面这个例子:
func deferFuncReturn() (result int) {
i := 1
defer func() {
result++
}()
return i
}
该函数的 return 语句可以拆分成下面两行:
result = i
return
而延迟函数的执行正是在return之前,即加入defer后的执行过程如下:
result = i
result++
return
所以上面函数实际返回 i++ 值。
关于主函数有不同的返回方式,但返回机制就如上机介绍所说,只要把 return 语句拆开都可以很好的理解。下面还有几个例子。
主函数拥有匿名返回值,返回字面值
一个主函数拥有一个匿名的返回值,返回时使用字面值,比如返回”1”、”2”、”Hello”这样的值,这种情况下 defer 语句是无法操作返回值的。
一个返回字面值的函数,如下所示:
func foo() int {
var i int
defer func() {
i++
}()
return 1
}
上面的 return 语句,直接把 1 写入栈中作为返回值,延迟函数无法操作该返回值,所以就无法影响返回值。
主函数拥有匿名返回值,返回变量
一个主函数拥有一个匿名的返回值,返回使用本地或全局变量,这种情况下 defer 语句可以引用到返回值,但不会改变返回值。
一个返回本地变量的函数,如下所示:
func foo() int {
var i int
defer func() {
i++
}()
return i
}
上面的函数,返回一个局部变量,同时 defer 函数也会操作这个局部变量。对于匿名返回值来说,可以假定仍然有一个变量存储返回值,假定返回值变量为 “anony”,上面的返回语句可以拆分成以下过程:
anony = i
i++
return
由于 i 是整型,会将值拷贝给 anony,所以 defer 语句中修改i值,对函数返回值不造成影响。
主函数拥有具名返回值
主函声明语句中带名字的返回值,会被初始化成一个局部变量,函数内部可以像使用局部变量一样使用该返回值。如果 defer 语句操作该返回值,可能会改变返回结果。
一个影响函返回值的例子:
func foo() (ret int) {
defer func() {
ret++
}()
return 0
}
上面的函数拆解出来,如下所示:
ret = 0
ret++
return
函数真正返回前,在 defer 中对返回值做了+1操作,所以函数最终返回 1。
defer 数据结构
defer 在 Go 语言源代码中的数据结构如下:
type _defer struct {
siz int32 // 参数和结果的内存大小
started bool
openDefer bool // 当前 defer 是否经过开放编码的优化
sp uintptr // 函数栈指针
pc uintptr // 调用方的程序计数器
fn *funcval // defer 关键字中传入的参数,也就是 defer 后面的函数地址
_panic *_panic // 触发延迟调用的结构体,可能为空
link *_defer
}
_defer 结构体是延迟调用链表上的一个节点,所有的结构体都会通过 link 字段串联成链表。
下图展示了一个 goroutine 定义多个 defer 的场景:
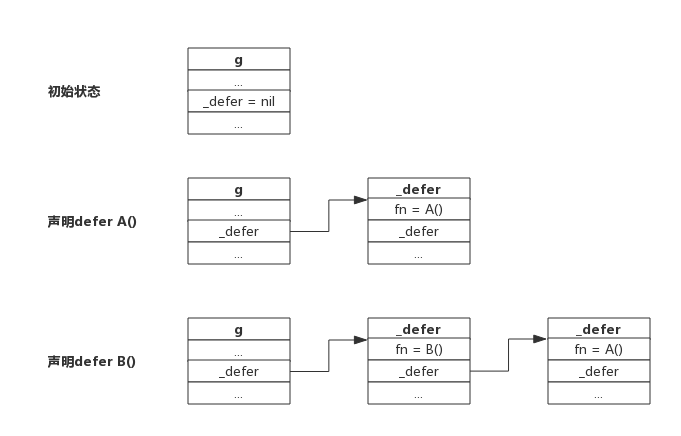
新声明的 defer 总是添加到链表头部,函数返回前执行 defer 则是从链表首部依次取出执行。一个 goroutine 可能连续调用多个函数,defer 添加过程跟上述流程一致,进入函数时添加 defer,离开函数时取出 defer,所以即便调用多个函数,也总是能保证 defer 是按 FIFO 方式执行的。
defer 执行机制
defer 会根据条件的不同,使用三种不同的机制处理该关键字:
func (s *state) stmt(n *Node) {
...
switch n.Op {
case ODEFER:
if s.hasOpenDefers {
s.openDeferRecord(n.Left) // 开放编码
} else {
d := callDefer // 堆分配
if n.Esc == EscNever {
d = callDeferStack // 栈分配
}
s.callResult(n.Left, d)
}
}
}
堆上分配 _defer 结构体是默认的兜底方案,当使用这种方式时,defer 在编译器看来也是函数调用。
当 defer 关键字在函数体中最多执行一次的时候,会将 _defer 结构体分配到栈上,以此节约内存分配带来的开销。
开放编码的方式时在 1.14 引入的使用代码内联优化 defer 关键的额外开销。开放编码作为一种优化 defer 关键字的方法,它不是在所有的场景下都会开启的,开放编码只会在满足以下的条件时启用:
- 函数的
defer数量少于或者等于 8 个; - 函数的
defer关键字不能在循环中执行; - 函数的
return语句与defer语句的乘积小于或者等于 15 个;
panic 和 recover
panic能够改变程序的控制流,调用panic后会立刻停止执行当前函数的剩余代码,并在当前 Goroutine 中递归执行调用方的defer;recover可以中止panic造成的程序崩溃。它是一个只能在defer中发挥作用的函数,在其他作用域中调用不会发挥作用;
使用现象
跨协程失效
panic 只会触发当前 Goroutine 的延迟函数调用,可以通过如下所示的代码了解该现象:
func main() {
defer println("in main")
go func() {
defer println("in goroutine")
panic("")
}()
time.Sleep(1 * time.Second)
}
$ go run main.go
in goroutine
panic:
...
当运行这段代码时会发现 main 函数中的 defer 语句并没有执行,执行的只有当前 Goroutine 中的 defer。
实际上defer 关键字对应的 runtime.deferproc会将延迟调用函数与调用方所在 Goroutine 进行关联。所以当程序发生崩溃时只会调用当前 Goroutine 的延迟调用函数也是非常合理的。
失效的崩溃恢复
下面的代码在主程序中调用 recover 试图中止程序的崩溃,但是从运行的结果中也能看出,下面的程序没有正常退出。
func main() {
defer fmt.Println("in main")
if err := recover(); err != nil {
fmt.Println(err)
}
panic("unknown err")
}
$ go run main.go
in main
panic: unknown err
goroutine 1 [running]:
main.main()
...
exit status 2
仔细分析一下这个过程就能理解这种现象背后的原因,recover 只有在发生 panic 之后调用才会生效。然而在上面的控制流中,recover 是在 panic 之前调用的,并不满足生效的条件,所以需要在 defer 中使用 recover 关键字。
嵌套崩溃
Go 语言中的 panic 是可以多次嵌套调用的。如下所示的代码就展示了如何在 defer 函数中多次调用 panic:
func main() {
defer fmt.Println("in main")
defer func() {
defer func() {
panic("panic again and again")
}()
panic("panic again")
}()
panic("panic once")
}
$ go run main.go
in main
panic: panic once
panic: panic again
panic: panic again and again
goroutine 1 [running]:
...
exit status 2
从上述程序输出的结果,可以确定程序多次调用 panic 也不会影响 defer 函数的正常执行,所以使用 defer 进行收尾工作一般来说都是安全的。
panic 数据结构
panic 关键字在 Go 语言的源代码是由数据结构 runtime._panic 表示的。每当调用 panic 都会创建一个如下所示的数据结构存储相关信息:
type _panic struct {
argp unsafe.Pointer
arg interface{}
link *_panic
recovered bool
aborted bool
pc uintptr
sp unsafe.Pointer
goexit bool
}
argp是指向defer调用时参数的指针;arg是调用panic时传入的参数;link指向了更早调用的runtime._panic结构;recovered表示当前runtime._panic是否被recover恢复;aborted表示当前的panic是否被强行终止;
从数据结构中的 link 字段就可以推测出以下的结论:panic 函数可以被连续多次调用,它们之间通过 link 可以组成链表。
结构体中的 pc、sp 和 goexit 三个字段都是为了修复 runtime.Goexit 带来的问题引入的。
runtime.Goexit 能够只结束调用该函数的 Goroutine 而不影响其他的 Goroutine,但是该函数会被 defer 中的 panic 和 recover 取消,引入这三个字段就是为了保证该函数的一定会生效。
panic 实现原理
编译器会将关键字 panic 转换成 runtime.gopanic,该函数的执行过程包含以下几个步骤:
- 创建新的
runtime._panic并添加到所在 Goroutine 的_panic链表的最前面; - 在循环中不断从当前 Goroutine 的
_defer中链表获取runtime._defer并调用runtime.reflectcall运行延迟调用函数; - 调用
runtime.fatalpanic中止整个程序;
func gopanic(e interface{}) {
gp := getg()
...
var p _panic
p.arg = e
p.link = gp._panic
gp._panic = (*_panic)(noescape(unsafe.Pointer(&p)))
for {
d := gp._defer
if d == nil {
break
}
d._panic = (*_panic)(noescape(unsafe.Pointer(&p)))
reflectcall(nil, unsafe.Pointer(d.fn), deferArgs(d), uint32(d.siz), uint32(d.siz))
d._panic = nil
d.fn = nil
gp._defer = d.link
freedefer(d)
if p.recovered {
...
}
}
// 这种 panic 没法 defer
fatalpanic(gp._panic)
*(*int)(nil) = 0
}
需要注意的是,在上述函数中省略了三部分比较重要的代码:
- 恢复程序的
recover分支中的代码; - 通过内联优化 defer 调用性能的代码
- 修复
runtime.Goexit异常情况的代码;
runtime.fatalpanic实现了无法被恢复的程序崩溃,它在中止程序之前会通过 runtime.printpanics打印出全部的 panic 消息以及调用时传入的参数:
func fatalpanic(msgs *_panic) {
pc := getcallerpc()
sp := getcallersp()
gp := getg()
if startpanic_m() && msgs != nil {
atomic.Xadd(&runningPanicDefers, -1)
printpanics(msgs)
}
if dopanic_m(gp, pc, sp) {
crash()
}
exit(2)
}
打印崩溃消息后会调用 runtime.exit 退出当前程序并返回错误码 2,程序的正常退出也是通过 runtime.exit实现的。
recover 实现原理
编译器会将关键字 recover 转换成 runtime.gorecover
func gorecover(argp uintptr) interface{} {
gp := getg()
p := gp._panic
if p != nil && !p.recovered && argp == uintptr(p.argp) {
p.recovered = true
return p.arg
}
return nil
}
该函数的实现很简单,如果当前 Goroutine 没有调用 panic,那么该函数会直接返回 nil,这也是崩溃恢复在非 defer 中调用会失效的原因。
在正常情况下,它会修改 runtime._panic的 recovered 字段,runtime.gorecover 函数中并不包含恢复程序的逻辑,程序的恢复是由 runtime.gopanic 函数负责的:
func gopanic(e interface{}) {
...
for {
// 执行延迟调用函数,可能会设置 p.recovered = true
...
pc := d.pc
sp := unsafe.Pointer(d.sp)
...
if p.recovered {
gp._panic = p.link
for gp._panic != nil && gp._panic.aborted {
gp._panic = gp._panic.link
}
if gp._panic == nil {
gp.sig = 0
}
gp.sigcode0 = uintptr(sp)
gp.sigcode1 = pc
mcall(recovery)
throw("recovery failed")
}
}
...
}
上述这段代码也省略了 defer 的内联优化,它从 runtime._defer 中取出了程序计数器 pc 和栈指针 sp 并调用 runtime.recovery函数触发 Goroutine 的调度,调度之前会准备好 sp、pc 以及函数的返回值:
func recovery(gp *g) {
sp := gp.sigcode0
pc := gp.sigcode1
gp.sched.sp = sp
gp.sched.pc = pc
gp.sched.lr = 0
gp.sched.ret = 1
gogo(&gp.sched)
}
当我们在调用 defer 关键字时,调用时的栈指针 sp 和程序计数器 pc 就已经存储到了 runtime._defer 结构体中,这里的 runtime.gogo 函数会跳回 defer 关键字调用的位置。
runtime.recovery在调度过程中会将函数的返回值设置成 1。从 runtime.deferproc 的注释中会发现,当 runtime.deferproc 函数的返回值是 1 时,编译器生成的代码会直接跳转到调用方函数返回之前并执行 runtime.deferreturn:
func deferproc(siz int32, fn *funcval) {
...
return0()
}
跳转到 runtime.deferreturn 函数之后,程序就已经从 panic 中恢复了并执行正常的逻辑,而 runtime.gorecover 函数也能从 runtime._panic结构中取出了调用 panic 时传入的 arg 参数并返回给调用方。
make 和 new
make 的作用是初始化内置的数据结构,也就是切片、哈希表和 Channel
在代码中往往都会使用如下所示的语句初始化这三类基本类型,这三个语句分别返回了不同类型的数据结构:
slice := make([]int, 0, 100)
hash := make(map[int]bool, 10)
ch := make(chan int, 5)
slice是一个包含data、cap和len的结构体reflect.SliceHeaderhash是一个指向runtime.hmap结构体的指针;ch是一个指向runtime.hchan结构体的指针;
new 的作用是根据传入的类型分配一片内存空间并返回指向这片内存空间的指针
i := new(int)
var v int
i := &v
上述代码片段中的两种不同初始化方法是等价的,它们都会创建一个指向 int 零值的指针。
make 实现
make 的实现在go 常用基本类型源码设计分析中已经分析过了,具体总结如下:在编译期间的类型检查阶段,Go 语言会将代表 make 关键字的 OMAKE 节点根据参数类型的不同转换成了 OMAKESLICE、OMAKEMAP 和 OMAKECHAN 三种不同类型的节点,这些节点会调用不同的运行时函数来初始化相应的数据结构。
new 实现
编译器会在中间代码生成阶段通过以下两个函数处理该关键字:
cmd/compile/internal/gc.callnew会将关键字转换成ONEWOBJ类型的节点;cmd/compile/internal/gc.state.expr会根据申请空间的大小分两种情况处理:- 如果申请的空间为 0,就会返回一个表示空指针的
zerobase变量; - 在遇到其他情况时会将关键字转换成
runtime.newobject函数:
func callnew(t *types.Type) *Node { ... n := nod(ONEWOBJ, typename(t), nil) ... return n } func (s *state) expr(n *Node) *ssa.Value { switch n.Op { case ONEWOBJ: if n.Type.Elem().Size() == 0 { return s.newValue1A(ssa.OpAddr, n.Type, zerobaseSym, s.sb) } typ := s.expr(n.Left) vv := s.rtcall(newobject, true, []*types.Type{n.Type}, typ) return vv[0] } }- 如果申请的空间为 0,就会返回一个表示空指针的
需要注意的是,无论是直接使用 new,还是使用 var 初始化变量,它们在编译器看来都是 ONEW 和 ODCL 节点。如果变量会逃逸到堆上,这些节点在这一阶段都会被 cmd/compile/internal/gc.walkstmt 转换成通过 runtime.newobject 函数并在堆上申请内存。不过这也不是绝对的,如果通过 var 或者 new 创建的变量不需要在当前作用域外生存,例如不用作为返回值返回给调用方,那么就不需要初始化在堆上。
func walkstmt(n *Node) *Node {
switch n.Op {
case ODCL:
v := n.Left
if v.Class() == PAUTOHEAP {
if prealloc[v] == nil {
prealloc[v] = callnew(v.Type)
}
nn := nod(OAS, v.Name.Param.Heapaddr, prealloc[v])
nn.SetColas(true)
nn = typecheck(nn, ctxStmt)
return walkstmt(nn)
}
case ONEW:
// 如果没有逃逸,直接在栈上分配内存
if n.Esc == EscNone {
r := temp(n.Type.Elem())
r = nod(OAS, r, nil)
r = typecheck(r, ctxStmt)
init.Append(r)
r = nod(OADDR, r.Left, nil)
r = typecheck(r, ctxExpr)
n = r
} else {
// 逃逸了就在堆上分配内存
n = callnew(n.Type.Elem())
}
}
}
runtime.newobject 函数会获取传入类型占用空间的大小,调用 runtime.mallocgc 在堆上申请一片内存空间并返回指向这片内存空间的指针:
func newobject(typ *_type) unsafe.Pointer {
return mallocgc(typ.size, typ, true)
}
参考文章