go 常用基本类型源码设计分析
数组类型
数组作为一种基本的数据类型,通常会从两个维度描述数组,也就是数组中存储的元素类型和数组最大能存储的元素个数,在 Go 语言中会使用如下所示的方式来表示数组类型:
[10]int
[200]interface{}
Go 语言数组在初始化之后大小就无法改变,存储元素类型相同、但是大小不同的数组类型在 Go 语言看来也是完全不同的,只有两个条件都相同才是同一类型。
创建数组
创建数组时由以下函数进行创建,当前数组是否应该在堆栈中初始化也在编译期就确定了:
// elem 为元素类型,bound 为数组大小
func NewArray(elem *Type, bound int64) *Type {
if bound < 0 {
Fatalf("NewArray: invalid bound %v", bound)
}
t := New(TARRAY)
t.Extra = &Array{Elem: elem, Bound: bound}
// 判断当前数组是否要在堆栈中初始化
t.SetNotInHeap(elem.NotInHeap())
return t
}
数组的初始化
Go 语言的数组有两种不同的创建方式,一种是显式的指定数组大小,另一种是使用 [...]T 声明数组,Go 语言会在编译期间通过源代码推导数组的大小:
arr1 := [3]int{1, 2, 3}
arr2 := [...]int{1, 2, 3}
上述两种声明方式在运行期间得到的结果是完全相同的,后一种声明方式在编译期间就会被转换成前一种,这也就是编译器对数组大小的推导。
语句转换
对于一个由字面量组成的数组,根据数组元素数量的不同,编译器会在负责初始化字面量的 cmd/compile/internal/gc.anylit 函数中做两种不同的优化:
- 当元素数量小于或者等于 4 个时,会直接将数组中的元素放置在栈上;
- 当元素数量大于 4 个时,会将数组中的元素放置到静态区并在运行时取出;
当数组中元素的个数小于或者等于四个时,会将原有的初始化语句 [3]int{1, 2, 3} 拆分成一个声明变量的表达式和几个赋值表达式,这些表达式会完成对数组的初始化:
var arr [3]int
arr[0] = 1
arr[1] = 2
arr[2] = 3
但是如果当前数组的元素大于四个,会先获取一个唯一的 staticname,然后调用 cmd/compile/internal/gc.fixedlit 函数在静态存储区初始化数组中的元素并将临时变量赋值给数组:
假设代码需要初始化 [5]int{1, 2, 3, 4, 5},那么可以将过程理解成以下的伪代码:
var arr [5]int
statictmp_0[0] = 1
statictmp_0[1] = 2
statictmp_0[2] = 3
statictmp_0[3] = 4
statictmp_0[4] = 5
arr = statictmp_0
总结起来,在不考虑逃逸分析的情况下,如果数组中元素的个数小于或者等于 4 个,那么所有的变量会直接在栈上初始化,如果数组元素大于 4 个,变量就会在静态存储区初始化然后拷贝到栈上,这些转换后的代码才会继续进入中间代码生成和机器码生成两个阶段,最后生成可以执行的二进制文件。
访问数组
在访问数组的时候,会先检测下标是否越界,其实现如下:
func typecheck1(n *Node, top int) (res *Node) {
switch n.Op {
case OINDEX:
ok |= ctxExpr
l := n.Left // array
r := n.Right // index
switch n.Left.Type.Etype {
case TSTRING, TARRAY, TSLICE:
...
if n.Right.Type != nil && !n.Right.Type.IsInteger() {
yyerror("non-integer %s index %v", why, n.Right)
break
}
if !n.Bounded() && Isconst(n.Right, CTINT) {
x := n.Right.Int64()
if x < 0 {
yyerror("invalid %s index %v (index must be non-negative)", why, n.Right)
} else if t.IsArray() && x >= t.NumElem() {
yyerror("invalid array index %v (out of bounds for %d-element array)", n.Right, t.NumElem())
} else if Isconst(n.Left, CTSTR) && x >= int64(len(strlit(n.Left))) {
yyerror("invalid string index %v (out of bounds for %d-byte string)", n.Right, len(strlit(n.Left)))
} else if n.Right.Val().U.(*Mpint).Cmp(maxintval[TINT]) > 0 {
yyerror("invalid %s index %v (index too large)", why, n.Right)
}
}
}
...
}
}
- 访问数组的索引是非整数时,报错
“non-integer %s index %v”; - 访问数组的索引是负数时,报错
"invalid %s index %v (index must be non-negative)"; - 访问数组的索引越界时,报错
"invalid array index %v (out of bounds for %d-element array)";
数组和字符串的一些简单越界错误都会在编译期间发现,例如:直接使用整数或者常量访问数组。但是如果使用变量去访问数组或者字符串时,编译器就无法提前发现错误,这时需要 Go 语言运行时阻止不合法的访问。例如下面这种越界访问:
package check
func outOfRange() int {
arr := [3]int{1, 2, 3}
i := 4
elem := arr[i]
return elem
}
Go 语言运行时在发现数组、切片和字符串的越界操作会由运行时的 runtime.panicIndex 和 runtime.goPanicIndex 触发程序的运行时错误并导致崩溃退出。
因此,Go 语言对于数组的访问有着比较多的检查的,它不仅会在编译期间提前发现一些简单的越界错误并插入用于检测数组上限的函数调用,还会在运行期间通过插入的函数保证不会发生越界。
数组赋值
数组的赋值和更新操作 a[i] = 2 也会计算出数组当前元素的内存地址,然后修改当前内存地址的内容。赋值的过程中会先确定目标数组的地址,再获取目标元素的地址,最后使用 Store 指令将数据存入地址中。无论是数组的寻址还是赋值都是在编译阶段完成的,没有运行时的参与。
切片
创建切片
在 Go 中,声明切片的方式为:
[]int
[]interface
切片在编译期间的生成的类型只会包含切片中的元素类型,即 int 或者 interface{} 等。
cmd/compile/internal/types.NewSlice就是编译期间用于创建切片类型的函数:
// NewSlice returns the slice Type with element type elem.
func NewSlice(elem *Type) *Type {
if t := elem.Cache.slice; t != nil {
if t.Elem() != elem {
Fatalf("elem mismatch")
}
return t
}
t := New(TSLICE)
t.Extra = Slice{Elem: elem}
elem.Cache.slice = t
return t
}
上面方法返回结构体中的 Extra 字段是一个只包含切片内元素类型的结构,也就是说切片内元素的类型都是在编译期间确定的,编译器确定了类型之后,会将类型存储在 Extra 字段中帮助程序在运行时动态获取。
切片的数据结构
切片在运行时的数据结构由 reflect.SliceHeader 结构体表示:
Data是指向数组的指针;Len是当前切片的长度;Cap是当前切片的容量,即Data数组的大小:
type SliceHeader struct {
Data uintptr
Len int
Cap int
}
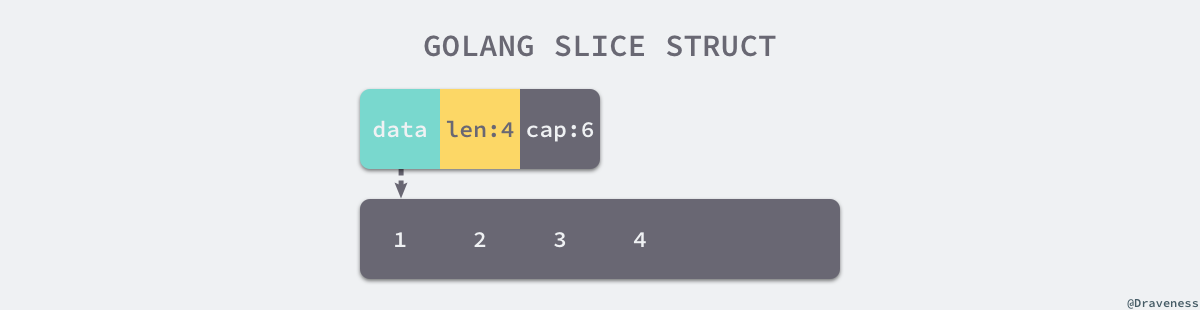
Data 是一片连续的内存空间,用于存储切片中的全部元素,从逻辑上来说,它就是一个数组。切片引入了一个抽象层,提供了对数组中部分连续片段的引用。作为数组的引用,可以在运行区间可以修改它的长度和范围。当切片底层的数组长度不足时就会触发扩容,切片指向的数组可能会发生变化。
切片的初始化
Go 语言中包含三种初始化切片的方式:
- 通过下标的方式获得数组或者切片的一部分;
- 使用字面量初始化新的切片;
- 使用关键字
make创建切片:
arr[0:3] or slice[0:3]
slice := []int{1, 2, 3}
slice := make([]int, 10)
使用下标
使用下标创建切片是最原始也最接近汇编语言的方式,它是所有方法中最为底层的一种,编译器会将 arr[0:3] 或者 slice[0:3] 等语句转换成 OpSliceMake 操作,例如对于下面的代码:
func newSlice() []int {
arr := [3]int{1, 2, 3}
slice := arr[0:1]
return slice
}
其编译过程中 slice := arr[0:1] 会有如下代码生成:
v27 (+5) = SliceMake <[]int> v11 v14 v17
name &arr[*[3]int]: v11
name slice.ptr[*int]: v11
name slice.len[int]: v14
name slice.cap[int]: v17
SliceMake 操作会接受四个参数创建新的切片,元素类型、数组指针、切片大小和容量,对应切片的数据结构。
使用下标初始化切片不会拷贝原数组或者原切片中的数据,它只会创建一个指向原数组的切片结构体,所以修改新切片的数据也会修改原切片。
字面量
当使用字面量 []int{1, 2, 3} 创建新的切片时,cmd/compile/internal/gc.slicelit 函数会在编译期间将它展开成如下所示的代码片段:
var vstat [3]int
vstat[0] = 1
vstat[1] = 2
vstat[2] = 3
var vauto *[3]int = new([3]int)
*vauto = vstat
slice := vauto[:]
上面代码的流程如下:
- 根据切片中的元素数量对底层数组的大小进行推断并创建一个数组;
- 将这些字面量元素存储到初始化的数组中;
- 创建一个同样指向
[3]int类型的数组指针; - 将静态存储区的数组
vstat赋值给vauto指针所在的地址; - 通过
[:]操作获取一个底层使用vauto的切片;
第 5 步中的 [:] 就是使用下标创建切片的方法,从这一点能看出 [:] 操作是创建切片最底层的一种方法。
使用下标和字面量的方式创建切片时,很多的工作都是在编译期间完成的。
关键字
当使用 make 关键字创建切片时,很多工作都需要运行时的参与;调用方必须向 make 函数传入切片的大小以及可选的容量。go 不仅会检查 len 是否传入,还会保证传入的容量 cap 一定大于或者等于 len。除了校验参数之外,还会根据条件决定切片的分配:
- 切片的大小和容量是否足够小
- 切片是否发生了逃逸
当切片发生逃逸或者非常大时,运行时需要通过 runtime.makeslice 在堆上初始化切片,如果当前的切片不会发生逃逸并且切片非常小的时候,make([]int, 3, 4) 会被直接转换成如下所示的代码:
var arr [4]int
n := arr[:3]
上述代码会初始化数组并通过下标 [:3] 得到数组对应的切片,这两部分操作都会在编译阶段完成,编译器会在栈上或者静态存储区创建数组并将 [:3] 同样转换成使用下标方式中的 OpSliceMake 操作。
对于 runtime.makeslice 函数,其实现如下:
func makeslice(et *_type, len, cap int) unsafe.Pointer {
mem, overflow := math.MulUintptr(et.size, uintptr(cap))
if overflow || mem > maxAlloc || len < 0 || len > cap {
// NOTE: Produce a 'len out of range' error instead of a
// 'cap out of range' error when someone does make([]T, bignumber).
// 'cap out of range' is true too, but since the cap is only being
// supplied implicitly, saying len is clearer.
// See golang.org/issue/4085.
mem, overflow := math.MulUintptr(et.size, uintptr(len))
if overflow || mem > maxAlloc || len < 0 {
panicmakeslicelen()
}
panicmakeslicecap()
}
return mallocgc(mem, et, true)
}
上述函数的主要工作是计算切片占用的内存空间并在堆上申请一片连续的内存,它使用如下的方式计算占用的内存:
$$
内存空间 = 切片中元素大小 \times 切片容量
$$
同时,创建切片的过程中如果发生了以下错误会直接触发运行时错误并崩溃:
- 内存空间的大小发生了溢出;
- 申请的内存大于最大可分配的内存;
- 传入的长度小于 0 或者长度大于容量;
runtime.makeslice 在最后调用的 runtime.mallocgc 是用于申请内存的函数,如果遇到了比较小的对象会直接初始化在 Go 语言调度器里面的 P 结构中,而大于 32KB 的对象会在堆上初始化。
访问切片
切片的操作基本都是在编译期间完成的,除了访问切片的长度、容量或者其中的元素之外,编译期间也会将包含 range 关键字的遍历转换成形式更简单的循环。
使用 len 和 cap 获取长度或者容量是切片最常见的操作,编译器将这它们看成两种特殊操作,即 OLEN 和 OCAP。len(slice) 或者 cap(slice) 在一些情况下会直接替换成切片的长度或者容量,不需要在运行时获取。
除了获取切片的长度和容量之外,访问切片中元素使用的 OINDEX 操作也会在中间代码生成期间转换成对地址的直接访问。
切片的追加和扩容
追加元素
使用 append 关键字向切片中追加元素也是常见的切片操作,会根据返回值是否会覆盖原变量,选择进入两种流程。
如果 append 返回的新切片不需要赋值回原有的变量,就会先通过切片获取它的的数组指针、大小和容量,如果在追加元素后切片的大小大于容量,那么就会调用 runtime.growslice 对切片进行扩容并将新的元素依次加入切片。
如果使用 slice = append(slice, 1, 2, 3) 语句,那么 append 后的切片会覆盖原切片,此时 go 会调用另一个方式展开关键字,会获取数组的指针,之后直接在数组中追加元素,避免发生拷贝影响性能。
切片扩容
当切片的容量不足时,会调用 runtime.growslice 函数为切片扩容,扩容是为切片分配新的内存空间并拷贝原切片中元素的过程。在该函数中,首先会确认新切片的容量:
func growslice(et *_type, old slice, cap int) slice {
//...
newcap := old.cap
doublecap := newcap + newcap
if cap > doublecap {
newcap = cap
} else {
if old.len < 1024 {
newcap = doublecap
} else {
// Check 0 < newcap to detect overflow
// and prevent an infinite loop.
for 0 < newcap && newcap < cap {
newcap += newcap / 4
}
// Set newcap to the requested cap when
// the newcap calculation overflowed.
if newcap <= 0 {
newcap = cap
}
}
}
//...
}
在分配内存空间之前需要先确定新的切片容量,运行时根据切片的当前容量选择不同的策略进行扩容:
- 如果期望容量大于当前容量的两倍就会使用期望容量;
- 如果当前切片的长度小于 1024 就会将容量翻倍;
- 如果当前切片的长度大于 1024 就会每次增加 25% 的容量,直到新容量大于期望容量;
上述代码片段仅会确定切片的大致容量,还需要根据切片中的元素大小对齐内存,当数组中元素所占的字节大小为 1、8 或者 2 的倍数时,运行时会通过 roundupsize 进行对齐内存,内存对齐主要是为了适应 go 的内存分配,可以提高内存的分配效率并减少碎片。
实现如下:
var overflow bool
var lenmem, newlenmem, capmem uintptr
// Specialize for common values of et.size.
// For 1 we don't need any division/multiplication.
// For sys.PtrSize, compiler will optimize division/multiplication into a shift by a constant.
// For powers of 2, use a variable shift.
switch {
case et.size == 1:
lenmem = uintptr(old.len)
newlenmem = uintptr(cap)
capmem = roundupsize(uintptr(newcap))
overflow = uintptr(newcap) > maxAlloc
newcap = int(capmem)
case et.size == sys.PtrSize:
lenmem = uintptr(old.len) * sys.PtrSize
newlenmem = uintptr(cap) * sys.PtrSize
capmem = roundupsize(uintptr(newcap) * sys.PtrSize)
overflow = uintptr(newcap) > maxAlloc/sys.PtrSize
newcap = int(capmem / sys.PtrSize)
//...
default:
//...
roundupsize 则会使用 runtime.size_to_class 和 runtime.class_to_size 数组对申请的内存向上取整:
func roundupsize(size uintptr) uintptr {
if size < _MaxSmallSize {
// 首先通过 size_to_class 确认 size 的级别,再通过 class_to_size 取整为该 class 的上限大小
if size <= smallSizeMax-8 {
return uintptr(class_to_size[size_to_class8[(size+smallSizeDiv-1)/smallSizeDiv]])
} else {
return uintptr(class_to_size[size_to_class128[(size-smallSizeMax+largeSizeDiv-1)/largeSizeDiv]])
}
}
if size+_PageSize < size {
return size
}
return alignUp(size, _PageSize)
}
拷贝切片
当使用 copy(a, b) 的形式对切片进行拷贝时,编译期间的 cmd/compile/internal/gc.copyany 也会分两种情况进行处理拷贝操作,如果当前 copy 不是在运行时调用的,copy(a, b) 会被直接转换成下面的代码:
n := len(a)
if n > len(b) {
n = len(b)
}
if a.ptr != b.ptr {
memmove(a.ptr, b.ptr, n*sizeof(elem(a)))
}
runtime.memmove 会负责拷贝内存。而如果拷贝是在运行时发生的,例如:go copy(a, b),编译器会使用 runtime.slicecopy 替换运行期间调用的 copy,该函数的实现如下:
func slicecopy(to, fm slice, width uintptr) int {
if fm.len == 0 || to.len == 0 {
return 0
}
n := fm.len
if to.len < n {
n = to.len
}
if width == 0 {
return n
}
...
size := uintptr(n) * width
if size == 1 {
*(*byte)(to.array) = *(*byte)(fm.array)
} else {
memmove(to.array, fm.array, size)
}
return n
}
无论是编译期间拷贝还是运行时拷贝,两种拷贝方式都会通过 runtime.memmove 将整块内存的内容拷贝到目标的内存区域中:
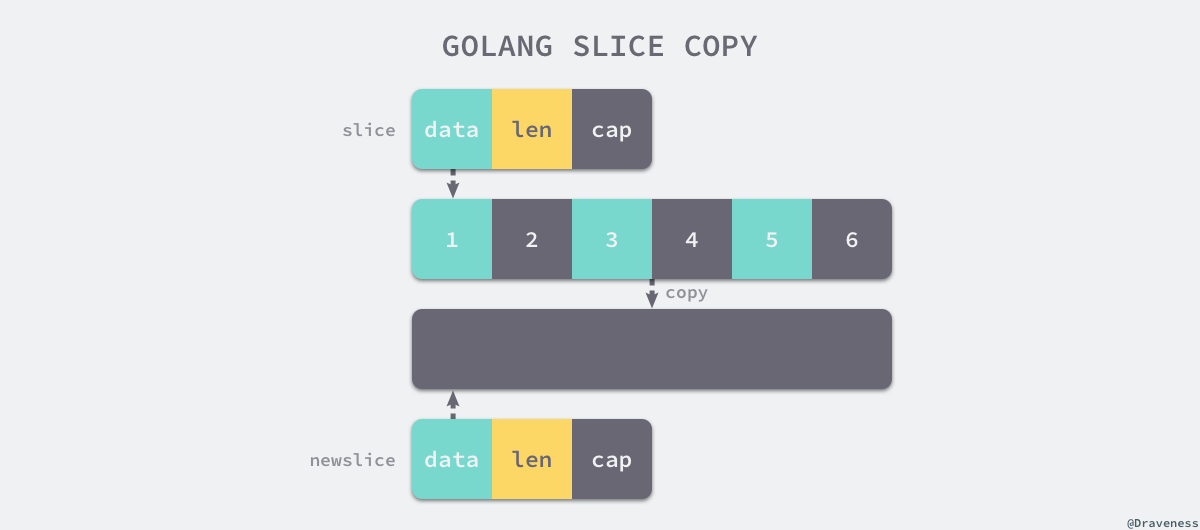
相比于依次拷贝元素,runtime.memmove 能够提供更好的性能。需要注意的是,成块拷贝内存仍然会占用非常多的资源,在大切片上执行拷贝操作时一定要注意对性能的影响。
字符串
字符串实际上是由字符组成的数组,C 语言中的字符串使用字符数组 char[] 表示。数组会占用一片连续的内存空间,而内存空间存储的字节共同组成了字符串,Go 语言中的字符串只是一个只读的字节数组,下图展示了 "hello" 字符串在内存中的存储方式:

如果是代码中存在的字符串,编译器会将其标记成只读数据 SRODATA,假设有以下代码,其中包含了一个字符串,当将这段代码编译成汇编语言时,就能够看到 hello 字符串有一个 SRODATA 的标记:
$ cat main.go
package main
func main() {
str := "hello"
println([]byte(str))
}
$ GOOS=linux GOARCH=amd64 go tool compile -S main.go
...
go.string."hello" SRODATA dupok size=5
0x0000 68 65 6c 6c 6f hello
...
只读只意味着字符串会分配到只读的内存空间,但是 Go 语言只是不支持直接修改 string 类型变量的内存空间,仍然可以通过在 string 和 []byte 类型之间反复转换实现修改这一目的:
- 先将这段内存拷贝到堆或者栈上;
- 将变量的类型转换成
[]byte后并修改字节数据; - 将修改后的字节数组转换回
string;
数据结构
字符串在 Go 中的接口是 reflect.StringHeader ,其中包含指向字节数组的指针和数组的大小:
type StringHeader struct {
Data uintptr
Len int
}
字符串解析过程
解析器在词法分析阶段会解析字符串,词法分析阶段会对源文件中的字符串进行切片和分组,将原有无意义的字符流转换成 Token 序列。在 Go 中,声明字符串的方式有两种,即双引号和反引号:
str1 := "this is a string"
str2 := `this is another string`
使用双引号声明的字符串和其他语言中的字符串没有太多的区别,它只能用于单行字符串的初始化,如果字符串内部出现双引号,需要使用 \ 符号避免编译器的解析错误,而反引号声明的字符串可以摆脱单行的限制。
当使用反引号时,因为双引号不再负责标记字符串的开始和结束,所以可以在字符串内部直接使用 ",在遇到需要手写 JSON 或者其他复杂数据格式的场景下非常方便。
json := `{"author": "draven", "tags": ["golang"]}`
解析字符串使用的扫描器 cmd/compile/internal/syntax.scanner 会将输入的字符串转换成 Token 流。
stdString 方法是它用来解析使用双引号的标准字符串:
func (s *scanner) stdString() {
s.startLit()
s.bad = false
for {
r := s.getr()
if r == '"' {
break
}
if r == '\\' {
s.escape('"')
continue
}
if r == '\n' {
// 如果存在隐式换行\n,则报错
s.ungetr() // assume newline is not part of literal
s.errorf("newline in string")
break
}
if r < 0 {
s.errorAtf(0, "string not terminated")
break
}
}
s.nlsemi = true
s.lit = string(s.stopLit())
s.kind = StringLit
s.tok = _Literal
}
该方法的逻辑如下:
标准字符串使用双引号表示开头和结尾;
标准字符串需要使用反斜杠
\来逃逸双引号;标准字符串不能出现例如下面这样的隐式换行
\n:str := "start end"
rawString 方法是用来解析反引号声明的字符串,它会将非反引号的所有字符都划分到当前字符串的范围中,所以可以使用它支持复杂的多行字符串,实现如下:
func (s *scanner) rawString() {
s.startLit()
s.bad = false
for {
r := s.getr()
if r == '`' {
break
}
if r < 0 {
s.errorAtf(0, "string not terminated")
break
}
}
// We leave CRs in the string since they are part of the
// literal (even though they are not part of the literal
// value).
s.nlsemi = true
s.lit = string(s.stopLit())
s.kind = StringLit
s.tok = _Literal
}
无论是标准字符串还是原始字符串都会被标记成 StringLit 并传递到语法分析阶段。在语法分析阶段,与字符串相关的表达式都会由 basicLit 方法处理:
func (p *noder) basicLit(lit *syntax.BasicLit) Val {
// We don't use the errors of the conversion routines to determine
// if a literal string is valid because the conversion routines may
// accept a wider syntax than the language permits. Rely on lit.Bad
// instead.
switch s := lit.Value; lit.Kind {
case syntax.IntLit:
checkLangCompat(lit)
x := new(Mpint)
if !lit.Bad {
x.SetString(s)
}
return Val{U: x}
case syntax.FloatLit:
checkLangCompat(lit)
x := newMpflt()
if !lit.Bad {
x.SetString(s)
}
return Val{U: x}
case syntax.ImagLit:
checkLangCompat(lit)
x := newMpcmplx()
if !lit.Bad {
x.Imag.SetString(strings.TrimSuffix(s, "i"))
}
return Val{U: x}
case syntax.RuneLit:
x := new(Mpint)
x.Rune = true
if !lit.Bad {
u, _ := strconv.Unquote(s)
var r rune
if len(u) == 1 {
r = rune(u[0])
} else {
r, _ = utf8.DecodeRuneInString(u)
}
x.SetInt64(int64(r))
}
return Val{U: x}
// 字符串的处理
case syntax.StringLit:
var x string
if !lit.Bad {
if len(s) > 0 && s[0] == '`' {
// strip carriage returns from raw string
s = strings.Replace(s, "\r", "", -1)
}
x, _ = strconv.Unquote(s)
}
return Val{U: x}
default:
panic("unhandled BasicLit kind")
}
}
无论是 import 语句中包的路径、结构体中的字段标签还是表达式中的字符串都会使用这个方法将原生字符串中最后的换行符删除并对字符串 Token 进行 Unquote,也就是去掉字符串两遍的引号等无关干扰,还原其本来的面目。
字符串拼接
Go 语言拼接字符串会使用 + 符号,编译器会将该符号对应的 OADD 节点转换成 OADDSTR 类型的节点,随后在 walkexpr 方法中调用 addstr 函数生成用于拼接字符串的代码:
func walkexpr(n *Node, init *Nodes) *Node {
switch n.Op {
...
case OADDSTR:
n = addstr(n, init)
}
}
addstr 能够在编译期间选择合适的函数对字符串进行拼接,该函数会根据带拼接的字符串数量选择不同的逻辑:
- 如果小于或者等于 5 个,那么会调用
concatstring{2,3,4,5}等一系列函数; - 如果超过 5 个,那么会选择
runtime.concatstrings传入一个数组切片;
func addstr(n *Node, init *Nodes) *Node {
// order.expr rewrote OADDSTR to have a list of strings.
c := n.List.Len()
if c < 2 {
Fatalf("addstr count %d too small", c)
}
buf := nodnil()
if n.Esc == EscNone {
sz := int64(0)
for _, n1 := range n.List.Slice() {
if n1.Op == OLITERAL {
sz += int64(len(strlit(n1)))
}
}
// Don't allocate the buffer if the result won't fit.
if sz < tmpstringbufsize {
// Create temporary buffer for result string on stack.
t := types.NewArray(types.Types[TUINT8], tmpstringbufsize)
buf = nod(OADDR, temp(t), nil)
}
}
// build list of string arguments
args := []*Node{buf}
for _, n2 := range n.List.Slice() {
args = append(args, conv(n2, types.Types[TSTRING]))
}
var fn string
if c <= 5 {
// 少量的字符串使用直接的运行时帮助程序。
// note: order.expr knows this cutoff too.
fn = fmt.Sprintf("concatstring%d", c)
} else {
// 大量字符串作为切片传递给运行时。
fn = "concatstrings"
t := types.NewSlice(types.Types[TSTRING])
slice := nod(OCOMPLIT, nil, typenod(t))
if prealloc[n] != nil {
prealloc[slice] = prealloc[n]
}
slice.List.Set(args[1:]) // skip buf arg
args = []*Node{buf, slice}
slice.Esc = EscNone
}
cat := syslook(fn)
r := nod(OCALL, cat, nil)
r.List.Set(args)
r = typecheck(r, ctxExpr)
r = walkexpr(r, init)
r.Type = n.Type
return r
}
其实无论使用 concatstring{2,3,4,5} 中的哪一个,最终都会调用 runtime.concatstrings,它会先对遍历传入的切片参数,再过滤空字符串并计算拼接后字符串的长度。
concatstrings 实现了 Go 字符串串联 x + y + z + ...。操作数在切片 a 中传递。 如果 buf != nil,则编译器已确定结果不会逃逸出调用函数,因此,如果字符串数据足够小,则可以将其存储在 buf 中。
func concatstrings(buf *tmpBuf, a []string) string {
idx := 0
l := 0
count := 0
for i, x := range a {
n := len(x)
if n == 0 {
continue
}
if l+n < l {
throw("string concatenation too long")
}
l += n
count++
idx = i
}
if count == 0 {
return ""
}
// 如果非空字符串的数量为 1 并且当前的字符串不在栈上,
// 就可以直接返回该字符串,不需要做出额外操作。
if count == 1 && (buf != nil || !stringDataOnStack(a[idx])) {
return a[idx]
}
s, b := rawstringtmp(buf, l)
for _, x := range a {
copy(b, x)
b = b[len(x):]
}
return s
}
在正常情况下,运行时会调用 copy 将输入的多个字符串拷贝到目标字符串所在的内存空间。新的字符串是一片新的内存空间,与原来的字符串也没有任何关联,一旦需要拼接的字符串非常大,拷贝带来的性能损失是无法忽略的。
类型转换
类型转换的开销并没有想象的那么小,经常会看到 runtime.slicebytetostring 等函数出现在火焰图中,成为程序的性能热点。
从字节数组到字符串的转换需要使用 runtime.slicebytetostring 函数,例如:string(bytes),该函数在函数体中会先处理两种比较常见的情况,也就是长度为 0 或者 1 的字节数组:
// Buf 是结果的固定大小的缓冲区,如果结果不逃逸,则为 nil。
func slicebytetostring(buf *tmpBuf, b []byte) (str string) {
l := len(b)
if l == 0 {
// Turns out to be a relatively common case.
// Consider that you want to parse out data between parens in "foo()bar",
// you find the indices and convert the subslice to string.
return ""
}
if raceenabled {
racereadrangepc(unsafe.Pointer(&b[0]),
uintptr(l),
getcallerpc(),
funcPC(slicebytetostring))
}
if msanenabled {
msanread(unsafe.Pointer(&b[0]), uintptr(l))
}
// runtime.stringStructOf 会将传入的字符串指针转换成 runtime.stringStruct 结构体指针
// 设置结构体持有的字符串指针 str 和长度 len
if l == 1 {
stringStructOf(&str).str = unsafe.Pointer(&staticbytes[b[0]])
stringStructOf(&str).len = 1
return
}
// 分配新的内存空间
var p unsafe.Pointer
if buf != nil && len(b) <= len(buf) {
p = unsafe.Pointer(buf)
} else {
p = mallocgc(uintptr(len(b)), nil, false)
}
stringStructOf(&str).str = p
stringStructOf(&str).len = len(b)
// 通过 runtime.memmove 将原 []byte 中的字节全部复制到新的内存空间中
memmove(p, (*(*slice)(unsafe.Pointer(&b))).array, uintptr(len(b)))
return
}
处理过后会根据传入的缓冲区大小决定是否需要为新字符串分配一片内存空间,runtime.stringStructOf 会将传入的字符串指针转换成 runtime.stringStruct 结构体指针,然后设置结构体持有的字符串指针 str 和长度 len,最后通过 runtime.memmove 将原 []byte 中的字节全部复制到新的内存空间中。
当想要将字符串转换成 []byte 类型时,需要使用 runtime.stringtoslicebyte 函数,该函数的实现非常容易理解:
func stringtoslicebyte(buf *tmpBuf, s string) []byte {
var b []byte
if buf != nil && len(s) <= len(buf) {
*buf = tmpBuf{}
b = buf[:len(s)]
} else {
b = rawbyteslice(len(s))
}
copy(b, s)
return b
}
上述函数会根据是否传入缓冲区做出不同的处理:
- 当传入缓冲区时,它会使用传入的缓冲区存储
[]byte; - 当没有传入缓冲区时,运行时会调用
runtime.rawbyteslice创建新的字节切片并将字符串中的内容拷贝过去
字符串和 []byte 中的内容虽然一样,但是字符串的内容是只读的,不能通过下标或者其他形式改变其中的数据,而 []byte 中的内容是可以读写的。不过无论从哪种类型转换到另一种都需要拷贝数据,而内存拷贝的性能损耗会随着字符串和 []byte 长度的增长而增长。
Map
Go 中的 map 使用的是链地址法解决哈希冲突,但是它的实现并不是对冲突的元素采用链表存储,而是采用了数组的形式。
哈希表相关概念
哈希表是计算机科学中的最重要数据结构之一,这不仅因为它 O(1) 的读写性能非常优秀,还因为它提供了键值之间的映射。想要实现一个性能优异的哈希表,需要注意两个关键点 —— 哈希函数和冲突解决方法。
哈希函数
哈希函数(常被称为散列函数)是可以用于将任意大小的数据映射到固定大小值的函数,常见的包括MD5、SHA系列等。实现哈希表的关键点在于哈希函数的选择,哈希函数的选择在很大程度上能够决定哈希表的读写性能。在理想情况下,哈希函数应该能够将不同键映射到不同的索引上,这要求哈希函数的输出范围大于输入范围,但是由于键的数量会远远大于映射的范围,所以在实际使用时,这个理想的效果是不可能实现的。
一个设计优秀的哈希函数应该包含以下特性:
- 均匀性:一个好的哈希函数应该在其输出范围内尽可能均匀地映射,也就是说,应以大致相同的概率生成输出范围内的每个哈希值。
- 效率高:哈希效率要高,即使很长的输入参数也能快速计算出哈希值。
- 可确定性:哈希过程必须是确定性的,这意味着对于给定的输入值,它必须始终生成相同的哈希值。
- 雪崩效应:微小的输入值变化也会让输出值发生巨大的变化。
- 不可逆:从哈希函数的输出值不可反向推导出原始的数据。
哈希桶与装载因子
哈希桶。哈希桶(也称为槽,类似于抽屉原理中的一个抽屉)可以理解为一个哈希值,所有的哈希值组成哈希空间。
装载因子。装载因子是表示哈希表中元素的填满程度。它的计算公式:
$$
装载因子=填入哈希表中的元素个数/哈希表的长度。
$$装载因子越大,填入的元素越多,空间利用率就越高,但发生哈希冲突的几率就变大。反之,装载因子越小,填入的元素越少,冲突发生的几率减小,但空间浪费也会变得更多,而且还会提高扩容操作的次数。
装载因子也是决定哈希表是否进行扩容的关键指标,在 java 的
HashMap的中,其默认装载因子为 0.75;Python的dict默认装载因子为2/3。
哈希冲突
哈希函数是将任意大小的数据映射到固定大小值的函数。那么,可以预见到,即使哈希函数设计得足够优秀,几乎每个输入值都能映射为不同的哈希值。但是,当输入数据足够大,大到能超过固定大小值的组合能表达的最大数量数,冲突将不可避免!
这里提到的哈希碰撞不是多个键对应的哈希完全相等,可能是多个哈希的部分相等,例如:两个键对应哈希的前四个字节相同。
抽屉原理:桌上有十个苹果,要把这十个苹果放到九个抽屉里,无论怎样放,至少会有一个抽屉里面放不少于两个苹果。抽屉原理有时也被称为鸽巢原理。
解决哈希冲突的方法
开放寻址法
开放寻址法是一种在哈希表中解决哈希碰撞的方法,这种方法的核心思想是依次探测和比较数组中的元素以判断目标键值对是否存在于哈希表中
对于开放寻址法而言,所有的元素都是存储在 Hash 表当中的,所以无论任何时候都要保证哈希表的槽位数 m 大于或等于键的数据 n(必要时,需要对哈希表进行动态扩容)。
开放寻址法有多种方式:线性探测法、平方探测法、随机探测法和双重哈希法。举个线性探测法的例子:
设 Hash(key) 表示关键字 key 的哈希值, 表示哈希表的槽位数(哈希表的大小)。
线性探测法则可以表示为:
如果
Hash(x) % M已经有数据,则尝试(Hash(x) + 1) % M;如果
(Hash(x) + 1) % M也有数据了,则尝试(Hash(x) + 2) % M;如果
(Hash(x) + 2) % M也有数据了,则尝试(Hash(x) + 3) % M;
……
开放寻址法中对性能影响最大的是装载因子。随着装载因子的增加,线性探测的平均用时就会逐渐增加,这会影响哈希表的读写性能。当装载率超过 70% 之后,哈希表的性能就会急剧下降,而一旦装载率达到 100%,整个哈希表就会完全失效,这时查找和插入任意元素的时间复杂度都是 O(n) 的,这时需要遍历数组中的全部元素,所以在实现哈希表时需要多关注装载因子的变化。
链地址法
链地址法的思想是将映射在一个桶里的所有元素用链表串起来。
对于开放寻址法而言,它只有数组一种数据结构就可完成存储,继承了数组的优点,对 CPU 缓存友好,易于序列化操作。但是它对内存的利用率不如链地址法,且发生冲突时代价更高。当数据量明确、装载因子小,适合采用开放寻址法。
链表节点可以在需要时再创建,不必像开放寻址法那样事先申请好足够内存,因此链地址法对于内存的利用率会比开方寻址法高。链地址法对装载因子的容忍度会更高,并且适合存储大对象、大数据量的哈希表。而且相较于开放寻址法,它更加灵活,支持更多的优化策略,比如可采用红黑树代替链表。但是链地址法需要额外的空间来存储指针。
在 Python 中
dict在发生哈希冲突时采用的开放寻址法,而 java 的HashMap采用的是链地址法,而 Go 中使用的也是链地址法,但不完全遵循了链地址法的思想,其主要使用的空间还是数组,其次才用了链表。
Map 中的数据结构
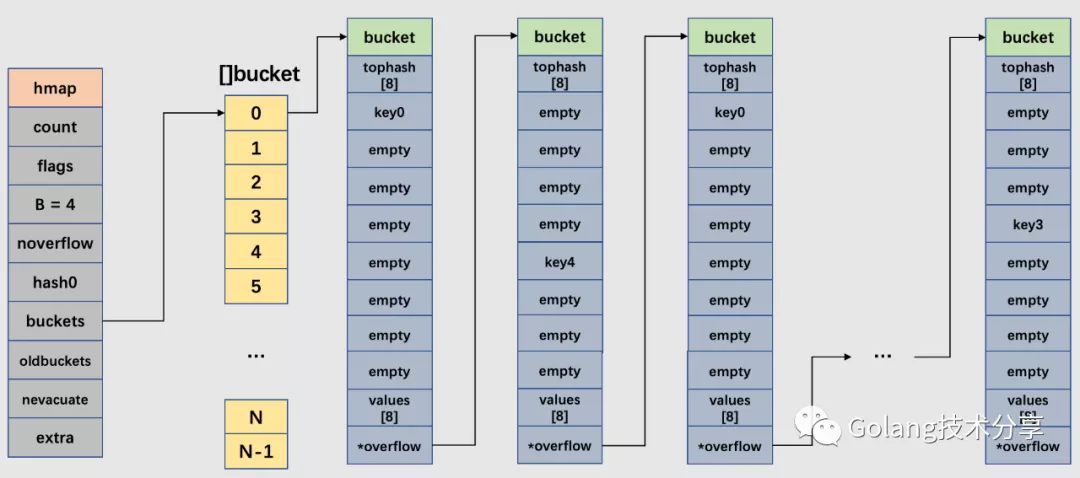
Go 中的结构体为 hamp,该结构体的字段如下:
type hmap struct {
// 代表当前哈希表中的元素个数,len(map) 返回的就是该字段值
count int
// 状态标识,比如正在被写、buckets 和 oldbuckets 在被遍历、等量扩容(Map扩容相关字段)
flags uint8
// buckets(桶)的数量的对数,也就是说该哈希表中桶的数量为 2^B 个
B uint8
// 溢出桶的大致数量
noverflow uint16
// 哈希种子,这个值在哈希创建时随机生成,并在计算 key 的哈希的时候会传入哈希函数,以此提高哈希函数的随机性
hash0 uint32 // hash seed
// 指向 buckets 数组的指针,数组大小为 2^B,如果元素个数为 0,它为 nil。
buckets unsafe.Pointer
// 如果发生扩容,oldbuckets 是指向老的 buckets 数组的指针,老的 buckets 数组大小是新的buckets 的 1/2。非扩容状态下,它为 nil。
oldbuckets unsafe.Pointer
// 表示扩容进度,小于此地址的 buckets 代表已搬迁完成。
nevacuate uintptr
// 这个字段是为了优化 GC 扫描而设计的。当 key 和 value 均不包含指针,并且都可以 <=128 字节时使用。extra 是指向 mapextra 类型的指针。
extra *mapextra
}
bmap
buckets 是一个指针,它指向的是一个类型为 bmap 的结构体数组,也就是具体存储 map 键值对的哈希空间。bmap 的结构如下:
type bmap struct {
// tophash 包含此桶中每个键的哈希值最高字节(高8位)信息。
// 如果tophash[0] < minTopHash,tophash[0]则代表桶的搬迁(evacuation)状态。
tophash [bucketCnt]uint8
}
这里的 tophash 指的是哈希值的高八位,在 Go 中,Hash 值的分布如下,高八位即 high-order bits 部分:

在运行期间,bmap 结构体其实不止包含 tophash 字段,因为哈希表中可能存储不同类型的键值对(例如声明了接口类型),而且 Go 语言也不支持泛型,所以键值对占据的内存空间大小只能在编译时进行推导。bmap 中的其他字段在运行时也都是通过计算内存地址的方式访问的,所以它的定义中就不包含这些字段。所以在编译期间通过 cmd/compile/internal/gc.bmap 函数重建了它的结构,动态地创建一个新的结构:
type bmap struct {
//hash值的高八位
topbits [8]uint8
// key 的数组
keys [8]keytype
// value 的数组
values [8]valuetype
// 对齐内存使用的,不是每个 bmap 都有会这个字段,需要满足一定条件
pad uintptr
// 溢出桶,也是指向一个 bmap,上面的字段 topbits、keys、elems 长度为 8,最多存8组键值对,存满了就往指向的这个 bmap 里存
overflow uintptr
}
一个 bmap 的内存模型如下所示:
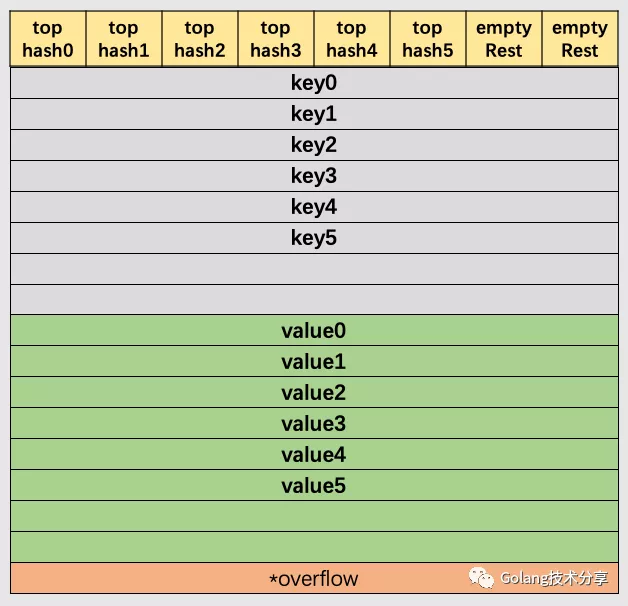
在上图解示例中,该桶的第 7 位 cell 和第 8 位 cell 还未有对应键值对。需要注意的是,key 和 value 是各自存储起来的,并非想象中的 key/value/key/value… 的形式。这样做虽然会让代码组织稍显复杂,但是它的好处是能消除填充所需要的字段(padding)。例如 map[int64]int ,如果按照 key/value/key/value/... 这样的模式存储,那在每一个 key/value 对之后都要额外 padding 7 个字节;而将所有的 key,value 分别绑定到一起,这种形式 key/key/.../value/value/...,则只需要在最后添加 padding。
此外,在 8 个键值对数据后面有一个 overflow 指针,因为桶中最多只能装 8 个键值对,如果有多余的键值对落到了当前桶,那么就需要再构建一个桶(称为溢出桶),通过 overflow 指针链接起来。
mapextra
当 map 的 key 和 value 都不是指针,并且 size 都小于 128 字节的情况下,会把 bmap 标记为不含指针,这样可以避免 gc 时扫描整个 hmap。但是,bmap 其实有一个 overflow 的字段,是指针类型的,破坏了 bmap 不含指针的设想,这时会把 overflow 移动到 extra 字段来,在这个字段里将指针指向溢出桶。
所以实际上 bmap.overflow 和 hmap.extra.overflow 所指向的地址是一样的,都是溢出桶的内存地址,只是在某些特殊情况下用 hmap.extra.overflow 代替 bmap.overflow ,从而优化了 GC 过程。
type mapextra struct {
// 如果 key 和 value 都不包含指针,并且可以被 inline(<=128 字节)
// 就使用 hmap 的 extra 字段来存储 overflow buckets,这样可以避免 GC 扫描整个 map
// overflow 包含的是 hmap.buckets 的 overflow 的 buckets
// oldoverflow 包含扩容时的 hmap.oldbuckets 的 overflow 的 bucket
overflow *[]*bmap
oldoverflow *[]*bmap
// 指向空闲的 overflow bucket 的指针
nextOverflow *bmap
}
GC 优化
在 Go 中,除了普通指针外,还保留了另外两种类型的指针,通过它们可以绕过类型系统,达到 c 语言自由操控内存的灵活程度。其他两种指针如下:
unsafe.Pointer。uintptr。
要理解这两者,一定要建立个概念:指针本质上就是个数,只不过这个数保存的是内存地址而已。32位机器寻址空间为32位,64位机器寻址空间为64位,一个指针占用大小就等于机器的位数。
uintptr很简单,其就是单纯一个保存内存地址的数,在32位机器下等价于uint32,64位机器下等价于uint64。既然是一个数,自然就支持运算,从而就能表示任意一个内存位置。但问题是一个数据仅仅通过内存地址是无法定位的,还需要知道它多大,说白点就是无法单纯依靠 uintptr 这个指针对数据进行操作。而普通的带类型的指针,除了告诉地址外,这个类型就告诉了数据的大小,从而帮助编译器理解如何取操作指向的内存。如*int32、*int64指针就分别告诉编译器操作指向地址的4B、8B数据。
解释清楚了go语言中的普通指针以及uintptr指针,那么这个相较于 c 语言多出的unsafe.Pointer是什么呢?
unsafe.Pointer指泛型指针,和uinptr一样只保留了内存地址而不关心类型。但它和uintptr的区别是,前者指向的对象会在 gc 中引用计数,从而不被 gc 当做垃圾回收掉,而后者相反,其只单纯表示内存地址这个数,也就是说有个数据地址就算被uintptr保存,也会被无情回收掉。
go语言三种指针总结:
- 普通指针。不支持指针运算,保存地址以及类型信息,指向数据不会被gc回收。
unsafe.Pointer。不支持指针运算,保存地址但不保存类型信息,指向数据不会被gc回收。uintptr。支持地址运算,保存地址但不保存类型信息,指向数据会被gc回收。
bmap 这个结构体里有一个 overflow 指针,它指向溢出的 bucket。因为它是一个指针,所以 GC 的时候肯定要扫描它,也就要扫描所有的 bmap。
而当 map 的 key/value 都是非指针类型的话,扫描是可以避免的,直接标记整个 map 的颜色(三色标记法)就行了(因为这就是一个对象,不存在引用),不用去扫描每个 bmap 的 overflow 指针。
但是溢出的 bucket 总是可能存在的,这和 key/value 的类型无关。
于是就利用 hmap 里的 extra 结构体的 overflow 指针来 “hold” 这些 overflow 的 bucket,并把 bmap 结构体的 overflow 指针类型变成一个 unitptr 类型(这些是在编译期干的)。
于是整个 bmap 就完全没有指针了,也就不会在 GC 期间被扫描。
另一方面,当 GC 在扫描 hmap 时,通过 extra.overflow 这条路径(指针)就可以将 overflow 的 bucket 正常标记成黑色,从而不会被 GC 错误地回收。
这里我理解成,实际上就是节省了对第一层桶的扫描,实际上溢出桶在 GC 期间还是都会被扫描一遍
因此,当 map 中的 key/value 存在指针时,bmap 会补全成以下类型:
// keytype和valuetype由编译器推导给出
type bmap struct {
tophash [8]uint8 //8个键对应的hash高8位
keys [8]keytype //8个键
values [8]valuetype //8个桶
overflow *bmap //overflow就是链表节点的next指针,指向下一个同义词桶
}
而当 map 中不包含指针时,bmap 会被补全为以下类型:
type bmap struct {
tophash [8]uint8
keys [8]keytype
values [8]valuetype
overflow uintptr //只保留下一个同义词桶的地址,而不引用计数。
}
通过这个原理,就可以利用它来对一些场景进行性能优化,例如:
map[string]int -> map[[12]byte]int
因为 string 底层有指针,所以当 string 作为 map 的 key 时,GC 阶段会扫描整个 map;而数组 [12]byte 是一个值类型,不会被 GC 扫描。
map 中的常量
map 中还定义了一些重要的常量:
注意:键和值超过 128 个字节后,会被转换成指针
const (
// 一个桶中最多容纳的键值对的对数,也就是一个桶最多容纳 2^3=8 个
bucketCntBits = 3
bucketCnt = 1 << bucketCntBits
// 触发扩容的装载因子为 13/2=6.5
loadFactorNum = 13
loadFactorDen = 2
// 键和值超过 128 个字节后,会被转换成指针
maxKeySize = 128
maxElemSize = 128
// 数据偏移量,大小为 bmap 结构体的大小,它需要正确的对齐,
dataOffset = unsafe.Offsetof(struct {
b bmap
v int64
}{}.v)
// 每个桶(如果有溢出,则包含它的 overflow 的链桶)在搬迁完成状态(evacuated* states)下,
// 要么会包含它所有的键值对,要么一个都不包含(但不包括调用 evacuate() 方法阶段,
// 该方法调用只会在对 map 发起 write 时发生,在该阶段其他 goroutine 是无法查看该map的(map 非并发安全))。
// 简单的说,在非写过程的状态中,桶里的数据要么一起搬走,要么一个都还未搬。
// tophash 除了放置正常的高 8 位 hash 值,还会存储一些特殊状态值(标志该 cell 的搬迁状态)。
// 正常的tophash值,最小应该是5,以下列出的就是一些特殊状态值:
// 表示 cell 为空,并且比它高索引位的 cell 或者 overflows 中的 cell 都是空的。(初始化 bucket 时,就是该状态)
emptyRest = 0
// 空的cell,cell已经被搬迁到新的bucket
emptyOne = 1
// 键值对已经搬迁完毕,key 在新 buckets 数组的前半部分
evacuatedX = 2
// 键值对已经搬迁完毕,key 在新 buckets 数组的后半部分
evacuatedY = 3
// cell 为空,整个 bucket 已经搬迁完毕
evacuatedEmpty = 4
// tophash的最小正常值
minTopHash = 5
// flags
// 可能有迭代器在使用 buckets
iterator = 1
// 可能有迭代器在使用 oldbuckets
oldIterator = 2
// 有协程正在向 map 写入 key
hashWriting = 4
// 等量扩容
sameSizeGrow = 8
// 用于迭代器检查的 bucket ID
noCheck = 1<<(8*sys.PtrSize) - 1
)
整体来说,map 的数据结构如下所示:
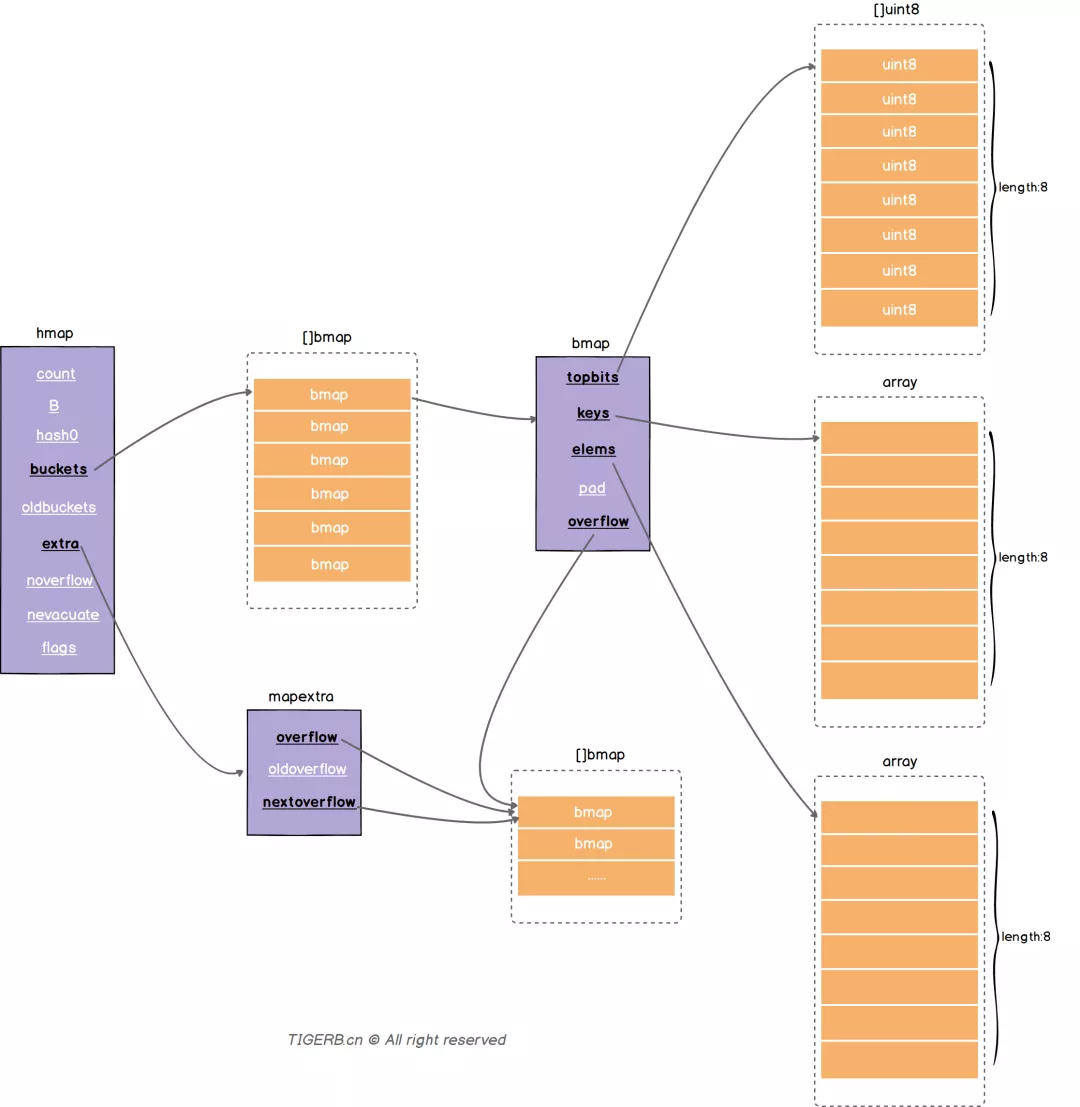
在上面的数据结构中,实际上 buckets 指向的 []bmap 和 bmap.overflow 指向的 []bmap 的内存在地址空间上是连续的,这个可以在下面 map 初始化的时候看出来。
Map 初始化
map 初始化的方式有以下两种:
make(map[k]v)
// 指定初始化大小为 hint 的 map
make(map[k]v,hint)
对于不指定初始化大小,和初始化值 hint<=8(bucketCnt) 时,go会调用 makemap_small 函数(源码位置 src/runtime/map.go),并直接从堆上进行分配。
func makemap_small() *hmap {
h := new(hmap)
h.hash0 = fastrand()
return h
}
当 hint>8 时,则调用 makemap 函数:
// 如果编译器认为可以在栈上创建 map 和第一个 bucket,那么 h 和 bucket 可能都是非空
// 如果 h != nil,那么 map 可以直接在 h 中创建
// 如果 h.buckets != nil,那么 h 指向的 bucket 可以作为 map 的第一个 bucket 使用
func makemap(t *maptype, hint int, h *hmap) *hmap {
// math.MulUintptr 返回 hint 与 t.bucket.size 的乘积,并判断该乘积是否溢出。
mem, overflow := math.MulUintptr(uintptr(hint), t.bucket.size)
// maxAlloc 的值,根据平台系统的差异而不同,具体计算方式参照 src/runtime/malloc.go
if overflow || mem > maxAlloc {
hint = 0
}
// initialize Hmap
if h == nil {
h = new(hmap)
}
// 通过 fastrand 得到一个随机的哈希种子
h.hash0 = fastrand()
// 根据输入的元素个数 hint,找到能装下这些元素所需要的 B 值
B := uint8(0)
// 2^B < hint/装载因子,找到满足条件的 B
for overLoadFactor(hint, B) {
B++
}
h.B = B
// 分配初始哈希表
// 如果 B 为0,那么 buckets 字段后续会在 mapassign 方法中 lazily 分配
if h.B != 0 {
var nextOverflow *bmap
// makeBucketArray 创建一个 map 的底层保存 buckets 的数组,它最少会分配 h.B^2 的大小。
h.buckets, nextOverflow = makeBucketArray(t, h.B, nil)
if nextOverflow != nil {
h.extra = new(mapextra)
h.extra.nextOverflow = nextOverflow
}
}
return h
}
分配 buckets 数组的 makeBucketArray 函数如下:
// makeBucket 为 map 创建用于保存 buckets 的数组。
func makeBucketArray(t *maptype, b uint8, dirtyalloc unsafe.Pointer) (buckets unsafe.Pointer, nextOverflow *bmap) {
base := bucketShift(b)
nbuckets := base
// 对于小的 b 值(小于4),即桶的数量小于 16 时,使用溢出桶的可能性很小。对于此情况,就避免计算开销。
if b >= 4 {
// 当桶的数量大于等于 16 个时,正常情况下就会额外创建 2^(b-4) 个溢出桶
nbuckets += bucketShift(b - 4)
sz := t.bucket.size * nbuckets
up := roundupsize(sz)
if up != sz {
nbuckets = up / t.bucket.size
}
}
// 这里,dirtyalloc 分两种情况。
// 如果它为 nil,则会分配一个新的底层数组。
// 如果它不为 nil,则它指向的是曾经分配过的底层数组,该底层数组是由之前同样的 t 和 b 参数通过 makeBucketArray 分配的
// 如果数组不为空,需要把该数组之前的数据清空并复用。
if dirtyalloc == nil {
// 由这里可以看出,正常桶和溢出桶在内存中的存储空间是连续的,因为分配的大小是正常桶+溢出桶
buckets = newarray(t.bucket, int(nbuckets))
} else {
buckets = dirtyalloc
size := t.bucket.size * nbuckets
if t.bucket.ptrdata != 0 {
memclrHasPointers(buckets, size)
} else {
memclrNoHeapPointers(buckets, size)
}
}
// 在满足分配溢出桶的条件下,为了把跟踪这些溢出桶的开销降至最低,使用了以下约定:
// 如果预分配的溢出桶的 overflow 指针为 nil,那么可以通过指针碰撞(bumping the pointer)获得更多可用桶。
// 关于指针碰撞:假设内存是绝对规整的,所有用过的内存都放在一边,空闲的内存放在另一边,中间放着一个指针作为分界点的指示器,那所分配内存就仅仅是把指针向空闲空间那边挪动一段与对象大小相等的距离,这种分配方式称为“指针碰撞”)
if base != nbuckets {
// buckets(基地址) + base(2^B)*bucketsize, 即获得第一个 overflow
nextOverflow = (*bmap)(add(buckets, base*uintptr(t.bucketsize)))
// 对于最后一个溢出桶,需要一个安全的非 nil 指针指向它,这是为了保证这部分尚未使用的内存 GC 期间安全
// 最后一个 overflow
last := (*bmap)(add(buckets, (nbuckets-1)*uintptr(t.bucketsize)))
// 最后一个 overflow 指针指向 buckets(基地址, 也是安全的指针)
last.setoverflow(t, (*bmap)(buckets))
}
return buckets, nextOverflow
}
通过上面的创建过程,初始化出来的 map 大致是如下的结构:
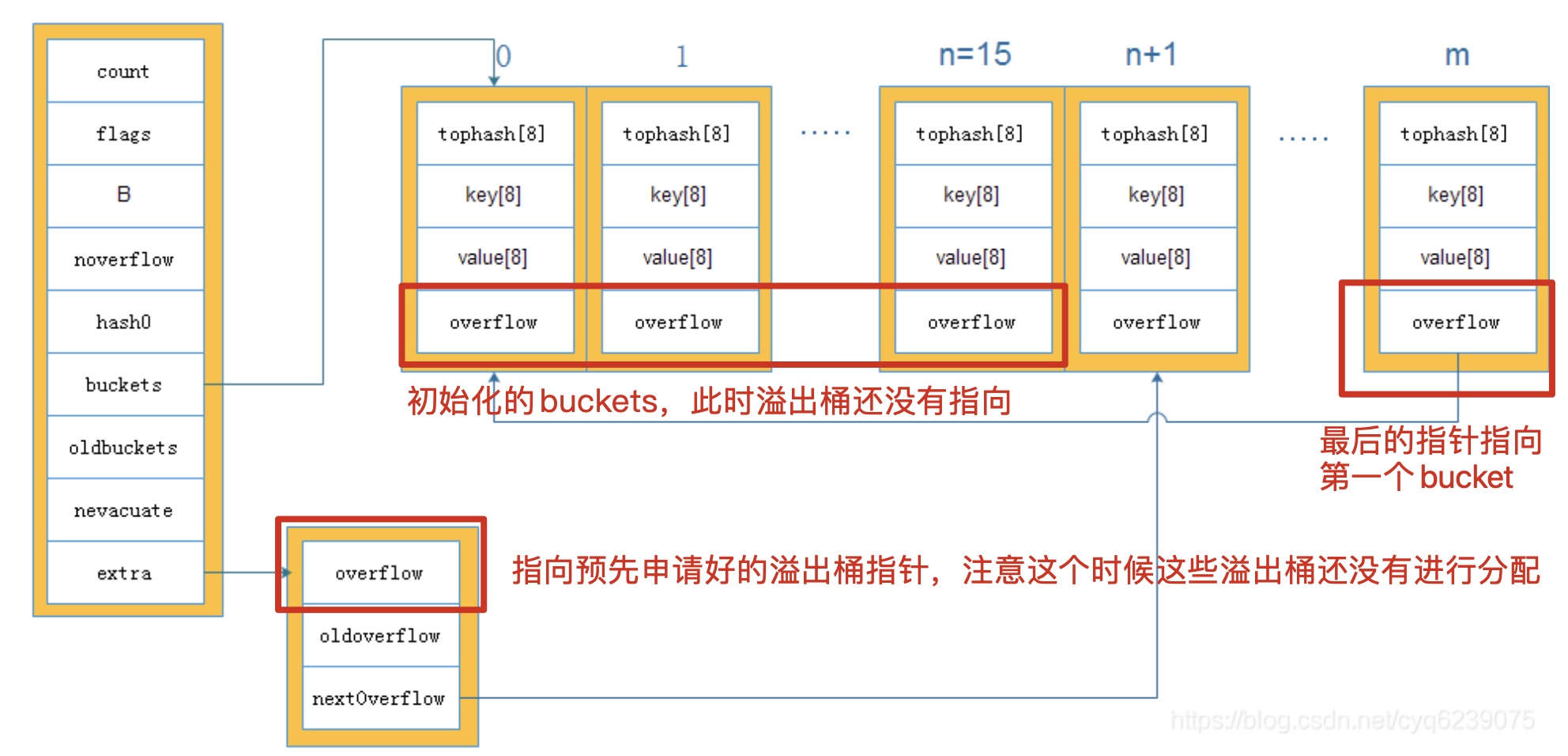
此外,还能看出,正常桶和溢出桶在内存中的存储空间是连续的,只是被 hmap 中的不同字段引用而已
Map 的哈希函数
在初始化 go 程序运行环境时(src/runtime/proc.go 中的 schedinit),就需要通过 alginit 方法完成对哈希的初始化:
func schedinit() {
lockInit(&sched.lock, lockRankSched)
...
tracebackinit()
moduledataverify()
stackinit()
mallocinit()
fastrandinit() // must run before mcommoninit
mcommoninit(_g_.m, -1)
cpuinit() // must run before alginit
// 这里调用alginit()
alginit() // maps must not be used before this call
modulesinit() // provides activeModules
typelinksinit() // uses maps, activeModules
itabsinit() // uses activeModules
...
goargs()
goenvs()
parsedebugvars()
gcinit()
...
}
对于哈希算法的选择,程序会根据当前架构判断是否支持 AES,如果支持就使用 AES hash,其实现的代码位于 src/runtime/asm_{386,amd64,arm64}.s 中;若不支持,其 hash 算法则根据 xxhash 算法和 cityhash 算法启发而来,代码分别对应于 32 位(src/runtime/hash32.go)和 64 位机器(src/runtime/hash32.go)中:
func alginit() {
// Install AES hash algorithms if the instructions needed are present.
if (GOARCH == "386" || GOARCH == "amd64") &&
cpu.X86.HasAES && // AESENC
cpu.X86.HasSSSE3 && // PSHUFB
cpu.X86.HasSSE41 { // PINSR{D,Q}
initAlgAES()
return
}
if GOARCH == "arm64" && cpu.ARM64.HasAES {
initAlgAES()
return
}
getRandomData((*[len(hashkey) * sys.PtrSize]byte)(unsafe.Pointer(&hashkey))[:])
hashkey[0] |= 1 // make sure these numbers are odd
hashkey[1] |= 1
hashkey[2] |= 1
hashkey[3] |= 1
}
上面在创建 map 的时候,map 的哈希种子是通过 h.hash0 = fastrand() 得到的。它是在以下 maptype 中的 hasher 中被使用到,在下文内容中会看到hash值的生成。
type maptype struct {
typ _type
key *_type
elem *_type
bucket *_type // internal type representing a hash bucket
// hasher 的第一个参数就是指向 key 的指针,
// h.hash0 = fastrand() 得到的 hash0,就是 hasher 方法的第二个参数。
// hasher方法返回的就是hash值。
hasher func(unsafe.Pointer, uintptr) uintptr
keysize uint8 // size of key slot
elemsize uint8 // size of elem slot
bucketsize uint16 // size of bucket
flags uint32
}
Map 的基本操作
Key 的定位
假定 key 经过哈希计算后得到 64bit 位的哈希值。如果 B=5,buckets 数组的长度,即桶的数量是 32(2 的 5 次方)。
例如,现要置一key于map中,该key经过哈希后,得到的哈希值如下:

哈希值低位(low-order bits)用于选择桶,哈希值高位(high-order bits)用于在一个独立的桶中区别出键。当 B 等于 5 时,那么选择的哈希值低位也是 5 位,即 01010,它的十进制值为10,代表 10 号桶。再用哈希值的高 8 位,找到此 key 在桶中的位置。最开始桶中还没有 key,那么新加入的 key 和 value 就会被放入第一个 key 空位和 value 空位。
注意:对于高八位的选择,该操作的实质是取余,但是取余开销很大,在实际代码实现中采用的是位操作,其实现如下:
func tophash(hash uintptr) uint8 {
top := uint8(hash >> (sys.PtrSize*8 - 8))
if top < minTopHash {
top += minTopHash
}
return top
}
当两个不同的 key 落在了同一个桶中,这时就发生了哈希冲突。
go 的解决方式是链地址法(这里只描述非扩容且该 key 是第一次添加的情况):在桶中按照顺序寻到第一个空位并记录下来,后续在该桶和它的溢出桶中均未发现存在的该 key,将 key 置于第一个空位;否则,去该桶的溢出桶中寻找空位,如果没有溢出桶,则添加溢出桶,并将其置溢出桶的第一个空位。
例如,下图中的 B 值为 5,所以桶的数量为 32。通过哈希函数计算出待插入 key 的哈希值,低 5 位哈希00110,对应于 6 号桶;高 8 位10010111,十进制为 151,由于桶中前 6 个 cell 已经有正常哈希值填充了(遍历),所以将 151 对应的高位哈希值放置于第 7 位cell(第8个 cell 为empty Rest,表明它还未使用),对应将 key 和 value 分别置于相应的第七个空位。
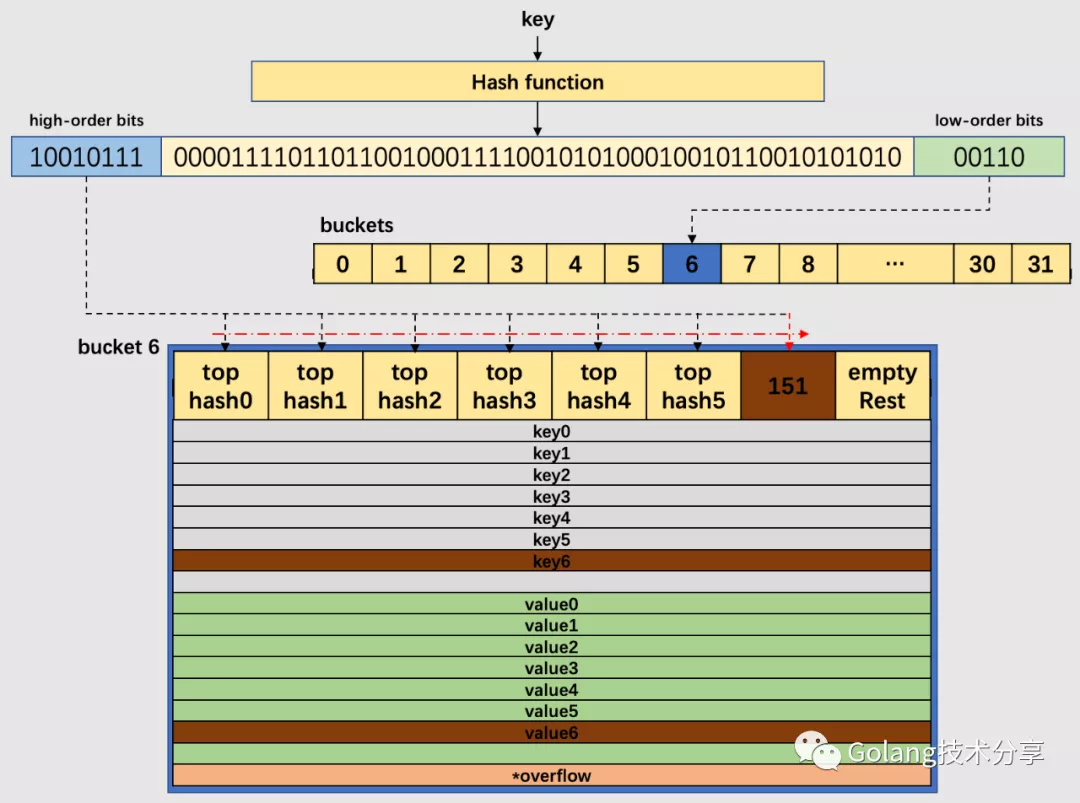
如果是查找 key,那么会根据高位哈希值去桶中的每个 cell 中找,若在桶中没找到,并且 overflow 不为nil,那么继续去溢出桶中寻找,直至找到,如果所有的 cell 都找过了,还未找到,则返回 key 类型的默认值(例如 key 是 int 类型,则返回 0)。
查找key
通过 key 查找 value 的方式有以下两种:
v := hash[key] // => v := *mapaccess1(maptype, hash, &key)
v, ok := hash[key] // => v, ok := mapaccess2(maptype, hash, &key)
赋值语句左侧接受参数的个数会决定使用的运行时方法:
- 当接受一个参数时,会使用
mapaccess1,该函数仅会返回一个指向目标值的指针; - 当接受两个参数时,会使用
mapaccess2,除了返回目标值之外,它还会返回一个用于表示当前键对应的值是否存在的bool值。
mapaccess1 查找 key 的代码实现如下:
func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
// 如果开启了竞态检测 -race
if raceenabled && h != nil {
callerpc := getcallerpc()
pc := funcPC(mapaccess1)
racereadpc(unsafe.Pointer(h), callerpc, pc)
raceReadObjectPC(t.key, key, callerpc, pc)
}
// 如果开启了 memory sanitizer -msan
if msanenabled && h != nil {
msanread(key, t.key.size)
}
// 如果 map 为空或者元素个数为 0,返回零值
if h == nil || h.count == 0 {
if t.hashMightPanic() {
t.hasher(key, 0) // see issue 23734
}
return unsafe.Pointer(&zeroVal[0])
}
// 注意,这里是按位与操作
// 当 h.flags 对应的值为 hashWriting(代表有其他 goroutine 正在往 map 中写 key)时,
// 那么位计算的结果不为 0,因此抛出以下错误。
// 这也表明,go 的 map 是非并发安全的
if h.flags&hashWriting != 0 {
throw("concurrent map read and map write")
}
// 不同类型的 key,会使用不同的 hash 算法,这里获取 hash 值
hash := t.hasher(key, uintptr(h.hash0))
// 返回 1 << b-1,即 low-order bits,用于下面与操作筛选出对应的 bucket
m := bucketMask(h.B)
// 按位与操作,找到对应的 bucket
b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.bucketsize)))
// 如果 oldbuckets 不为空,那么证明 map 发生了扩容
// 如果有扩容发生,老的 buckets 中的数据可能还未搬迁至新的 buckets 里
// 所以需要先在老的 buckets 中找
if c := h.oldbuckets; c != nil {
if !h.sameSizeGrow() {
// 增量扩容情况下,老 buckets 数组的大小是原来的一半
m >>= 1
}
// 找到 oldbucket 地址
oldb := (*bmap)(add(c, (hash&m)*uintptr(t.bucketsize)))
// 如果在 oldbuckets 中 tophash[0] 的值,为 evacuatedX、evacuatedY,evacuatedEmpty 其中之一
// 则 evacuated() 返回为true,说明搬迁完成。
// 因此,只有当搬迁未完成时,才会从此 oldbucket 中遍历
if !evacuated(oldb) {
b = oldb
}
}
// 取出当前 key 值的 tophash 值,即高八位的值
top := tophash(hash)
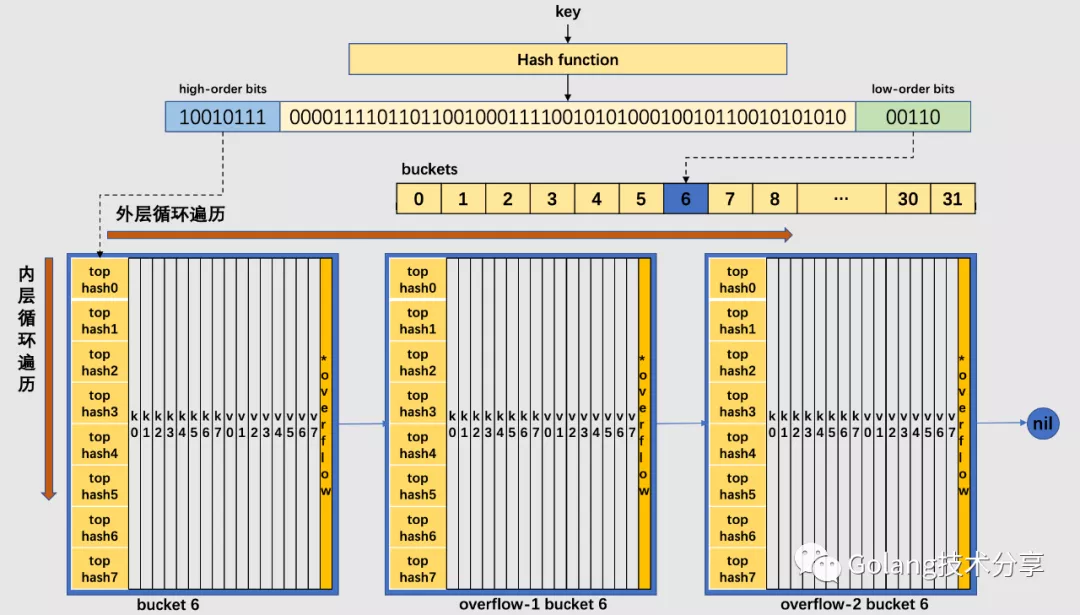
bucketloop:
// 以下是查找的核心逻辑
// 双重循环遍历:外层循环是从桶到溢出桶遍历;内层是桶中的 cell 遍历
// 跳出循环的条件有三种:
// 1. 第一种是已经找到 key 值;
// 2. 第二种是当前桶再无溢出桶;
// 3. 第三种是当前桶中有 cell 位的 tophash 值是 emptyRest,这个值它代表此时的桶后面的 cell 还未利用,所以无需再继续遍历。
// 初始化时 b 为 key 所在的桶,此时是在正常桶中
for ; b != nil; b = b.overflow(t) {
// 该桶存放最多 8 个键值对,依次对比 tophash 值是否相等
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
// 不相等且满足第三种条件,跳出循环
if b.tophash[i] == emptyRest {
break bucketloop
}
// 不相等继续遍历
continue
}
// 因为在 bucket 中 key 是用连续的存储空间存储的,因此可以通过 bucket 地址 +
// 数据偏移量(bmap 结构体的大小,也就是 tophash 占用的大小,因为 dataOffset 定义的是声明的 bmap)+
// keysize 的大小,得到 k 的地址
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
// 如果 key 是指针(当键超过 maxKeySize(128个字节)时会转换为指针),则需要进行解引用
if t.() {
k = *((*unsafe.Pointer)(k))
}
// 判断 key 是否相等
if t.key.equal(key, k) {
// 同理,value 的地址也是相似的计算方法,只是再要加上8个 keysize 的内存地址
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))
// 如果 value 是指针,解引用
if t.indirectelem() {
e = *((*unsafe.Pointer)(e))
}
// 返回找到的值
return e
}
}
}
// 所有的bucket都未找到,则返回零值
return unsafe.Pointer(&zeroVal[0])
}
根据上面的代码,可以看出它的查找流程如下:
- 判断 map 是否为空,为空的话返回零值
- 通过按位与的操作检测 map 是否有其他线程在进行写入,有的话则抛出错误。这也表明 map 不是并发安全的
- 对 key 取 hash 获得哈希值,通过哈希值的低位确定在哪一个 bucket
- 判断是否发生了扩容,如果发生了扩容并且键值搬迁未完成,则需要先到 old bucket 中查找
- 开始内外层循环遍历,依次对比 tophash 是否相等,直到找到对应的 key 或者找不到退出循环,查找过程结束
对于 mapaccess2 函数,它的函数签名如下:
func mapaccess2(t *maptype, h *hmap, key unsafe.Pointer) (unsafe.Pointer, bool)
与 mapaccess1 相比,mapaccess2 只是多了一个bool类型的返回值,它代表的是是否在 map 中找到了对应的key ,这里贴一下间断的代码:
func mapaccess2(t *maptype, h *hmap, key unsafe.Pointer) (unsafe.Pointer, bool) {
...
bucketloop:
for ; b != nil; b = b.overflow(t) {
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
if alg.equal(key, k) {
v := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))
// 多了一个 boolean 返回值
return v, true
}
}
}
// 找不到,返回 false
return unsafe.Pointer(&zeroVal[0]), false
}
同时,源码中还有mapaccessK方法,它的函数签名如下。
func mapaccessK(t *maptype, h *hmap, key unsafe.Pointer) (unsafe.Pointer, unsafe.Pointer) {}
与 mapaccess1 相比,mapaccessK 同时返回了 key和 value,其代码逻辑也一致。
写入 key
向 map 中插入或者修改 key,最终调用的是 mapassign 函数。
实际上插入或修改 key 的语法是一样的,只不过前者操作的 key 在 map 中不存在,而后者操作的 key 存在 map 中。
mapassign 函数如下:
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
// 如果 h 是空指针,赋值会引起panic
// 例如以下语句
// var m map[string]int
// m["k"] = 1
if h == nil {
panic(plainError("assignment to entry in nil map"))
}
// 如果开启了竞态检测 -race
if raceenabled {
callerpc := getcallerpc()
pc := funcPC(mapassign)
racewritepc(unsafe.Pointer(h), callerpc, pc)
raceReadObjectPC(t.key, key, callerpc, pc)
}
// 如果开启了memory sanitizer -msan
if msanenabled {
msanread(key, t.key.size)
}
// 同样检查是否有其他 goroutine 正在对 map 进行 key 写入,有的话抛出错误
if h.flags&hashWriting != 0 {
throw("concurrent map writes")
}
// 获取哈希值
hash := t.hasher(key, uintptr(h.hash0))
// 将 flags 的值与 hashWriting 做按位"异或"运算并赋值到 flags
// 因为在当前 goroutine 可能还未完成 key 的写入,再次调用 t.hasher 会发生 panic。
h.flags ^= hashWriting
// 这种情况在初始化 map 并且 hint<=8(bucketCnt)时,由于直接在堆上进行分配,所以会出现
if h.buckets == nil {
h.buckets = newobject(t.bucket) // newarray(t.bucket, 1)
}
again:
// bucketMask 返回值是 2 的 B 次方减 1,即 low-order bits
// 因此,通过 hash 值与 bucketMask 返回值做按位与操作获取 low-order bits,
// 返回在 buckets 数组中的第几号桶
bucket := hash & bucketMask(h.B)
// 如果 map 正在搬迁(即h.oldbuckets != nil)中,则先进行搬迁工作。
if h.growing() {
growWork(t, h, bucket)
}
// 计算出上面求出的 bucket 的内存位置
// post = start + bucketNumber * bucketsize
b := (*bmap)(unsafe.Pointer(uintptr(h.buckets) + bucket*uintptr(t.bucketsize)))
// 获取高八位哈希值
top := tophash(hash)
var inserti *uint8
var insertk unsafe.Pointer
var elem unsafe.Pointer
bucketloop:
for {
// 遍历桶中的 8 个 cell
for i := uintptr(0); i < bucketCnt; i++ {
// 这里分两种情况:
// 第一种情况是 cell 位的 tophash 值和当前 tophash 值不相等
// 在 b.tophash[i] != top 的情况下,这个位置有可能会是一个空槽位
// 一般情况下 map 的槽位分布是这样的,e 表示 empty:
// [h0][h1][h2][h3][h4][e][e][e]
// 但在执行过 delete 操作时,可能会变成这样:
// [h0][h1][e][e][h5][e][e][e]
// 所以如果再插入的话,会尽量往前面的位置插
// [h0][h1][e][e][h5][e][e][e]
// ^
// ^
// 这个位置
// 所以在循环的时候还要顺便把前面的空位置先记下来
// 因为有可能在后面会找到相等的 key,也可能找不到相等的 key
if b.tophash[i] != top {
// 当前是一个空槽位并且这是第一个空位
if isEmpty(b.tophash[i]) && inserti == nil {
// 记录这个空闲的位置tophash的地址,用于后面赋值,同时获取将要插入 k,v 位置的地址
inserti = &b.tophash[i]
insertk = add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))
}
// 查找到末尾了,break 跳出循环
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
// 第二种情况是 cell 位的 tophash 值和当前的 tophash 值相等
// 查找当前 cell 位的 key 值
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
if t.indirectkey() {
k = *((*unsafe.Pointer)(k))
}
// 注意,即使当前 cell 位的 tophash 值相等,不一定它对应的 key 也是相等的
// 所以还要做一个 key 值判断,判断如果 key 值不相等,记录下一轮遍历
if !t.key.equal(key, k) {
continue
}
// 如果已经有该 key 了,就更新它
if t.needkeyupdate() {
typedmemmove(t.key, k, key)
}
// 这里获取到了要插入 key 对应的 value 的内存地址
// pos = start + dataOffset + 8*keysize + i*elemsize
elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))
// 如果顺利到这,就直接跳到done的结束逻辑中去
// 这种情况下不会触发下面的情况,直接跳到 done
goto done
}
// 如果桶中的 8 个 cell 遍历完,还未找到对应的空 cell 或覆盖 cell,
// 那么就进入它的溢出桶中去遍历
ovf := b.overflow(t)
// 如果连溢出桶中都没有找到合适的 cell,跳出循环。
if ovf == nil {
break
}
b = ovf
}
// 在已有的桶和溢出桶中都未找到合适的 cell 供 key 写入,那么有可能会触发以下两种情况
// 情况一:
// 判断当前 map 的装载因子是否达到设定的 6.5 阈值,或者当前 map 的溢出桶数量是否过多。如果存在这两种情况之一,则进行扩容操作。
// 注意,这里 hashGrow() 实际并未完成扩容,对哈希表数据的搬迁(复制)操作是通过 growWork() 来完成的。
// 重新跳入 again 逻辑,在进行完 growWork() 操作后,再次遍历新的桶。
if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
// 此处涉及的扩容机制后面讲
hashGrow(t, h)
goto again
}
// 情况二:
// 在不满足情况一的条件下,会为当前桶再新建溢出桶,
// 并将 tophash,key 插入到新建溢出桶的对应内存的 0 号位置
if inserti == nil {
// 获取新建溢出桶的位置(后面有分析这个函数的实现)
newb := h.newoverflow(t, b)
// 记录这个空闲的位置tophash的地址,用于后面赋值,同时获取将要插入 k、v 的位置的指针
inserti = &newb.tophash[0]
insertk = add(unsafe.Pointer(newb), dataOffset)
elem = add(insertk, bucketCnt*uintptr(t.keysize))
}
// 如果 key 是指针(当键超过 maxKeySize(128个字节)时会转换为指针),则需要进行解引用获取值
if t.indirectkey() {
kmem := newobject(t.key)
// 赋值
*(*unsafe.Pointer)(insertk) = kmem
insertk = kmem
}
// value 同理
if t.indirectelem() {
vmem := newobject(t.elem)
// 获取 value 应该插入的地址
*(*unsafe.Pointer)(elem) = vmem
}
// 更新 key 值
typedmemmove(t.key, insertk, key)
// 将 tophash 赋值到bmap tophash数组的[i]位置
*inserti = top
h.count++
done:
// 再判断一次当前 map 是否有其他 goroutine 在写
if h.flags&hashWriting == 0 {
throw("concurrent map writes")
}
h.flags &^= hashWriting
if t.indirectelem() {
// 获取 value 应该插入的地址
elem = *((*unsafe.Pointer)(elem))
}
// 返回 value 的底层内存位置
return elem
}
在上面的写入流程中,在已有的桶和溢出桶中都未找到合适的 cell 供 key 写入,并且尚不满足扩容阈值的情况下,会通过 newoverflow 获得新的溢出桶。前面 map 初始化的时候提到过,其初始化后的结构是这样子的:
所以 extra.nextOverflow 会指向预分配的溢出桶,另外最后一个溢出桶的 overflow 会指向 buckets[0],通过这个特性,可以用来判断是否是最后一个溢出桶。
这里再分析一下 newoverflow 的实现:
func (h *hmap) newoverflow(t *maptype, b *bmap) *bmap {
var ovf *bmap
// 在创建 map 时,实际上会先分配一部分溢出桶用于后续需要
// 这里就会先检查是否有预分配的溢出桶,并且溢出桶还没有用完
if h.extra != nil && h.extra.nextOverflow != nil {
// ovf 指向预分配的溢出桶位置
ovf = h.extra.nextOverflow
// overflow 为 nil ,说明不是最后一个桶
if ovf.overflow(t) == nil {
// 这时候只需要修改 nextOverflow 地址指向下一个溢出桶(因为内存是连续的),即碰撞指针的思想
h.extra.nextOverflow = (*bmap)(add(unsafe.Pointer(ovf), uintptr(t.bucketsize)))
} else {
// overflow 不是 nil,说明这是最后的一个桶了,
// 重置此桶上的 overflow 指针为 nil,同时设置 extra.nextOverflow = nil,
// 标记溢出桶已经用完了
ovf.setoverflow(t, nil)
h.extra.nextOverflow = nil
}
} else {
// 没有溢出桶 或者 溢出桶用完了
// 内存空间重新分配一个bmap
ovf = (*bmap)(newobject(t.bucket))
}
// 生成溢出桶 bmap 的计数器计数
h.incrnoverflow()
if t.bucket.ptrdata == 0 {
// 创建 extra 和 overflow
h.createOverflow()
*h.extra.overflow = append(*h.extra.overflow, ovf)
}
// 将这个 bucket 的 overflow 指针指向溢出桶
b.setoverflow(t, ovf)
return ovf
}
通过对 mapassign 的代码分析之后,发现该函数并没有将插入 key 对应的 value 写入对应的内存,而是返回了 value 应该插入的内存地址。也就是说 map 并不会在 mapassign 这个运行时函数中将值拷贝到桶中,该函数只会返回内存地址。
真正的赋值操作是在编译期间插入的,对下面的程序使用 go tool 工具分析:
package main
func main() {
m := make(map[int]int)
for i := 0; i < 100; i++ {
m[i] = 666
}
}
m[i] = 666对应的汇编代码
$ go tool compile -S map.go
...
0x0098 00152 (map.go:6) LEAQ type.map[int]int(SB), CX
0x009f 00159 (map.go:6) MOVQ CX, (SP)
0x00a3 00163 (map.go:6) LEAQ ""..autotmp_2+184(SP), DX
0x00ab 00171 (map.go:6) MOVQ DX, 8(SP)
0x00b0 00176 (map.go:6) MOVQ AX, 16(SP)
0x00b5 00181 (map.go:6) CALL runtime.mapassign_fast64(SB) // 调用函数runtime.mapassign_fast64,该函数实质就是 mapassign(上文示例源代码是该 mapassign 系列的通用逻辑)
0x00ba 00186 (map.go:6) MOVQ 24(SP), AX 24(SP), AX // 返回值,即 value 应该存放的内存地址
0x00bf 00191 (map.go:6) MOVQ $666, (AX) // 把 666 放入该地址中
...
可以看到,赋值的最后一步实际上是编译器额外生成的汇编指令来完成的,可见靠 runtime 有些工作是没有做完的。所以,在 go 中,编译器和 runtime 配合,才能完成一些复杂的工作。
此外,可以看到上面的函数调用是 runtime.mapassign_fast64,这里说明一下:
mapassign有一系列的函数,根据key类型的不同,编译器会将其优化为相应的“快速函数”,但在实现思路上其实都跟mapassign一样。类型有以下这些:
key 类型 插入 uint32 mapassign_fast32(t *maptype, h *hmap, key uint32) unsafe.Pointer uint64 mapassign_fast64(t *maptype, h *hmap, key uint64) unsafe.Pointer string mapassign_faststr(t *maptype, h *hmap, ky string) unsafe.Pointer
最后,总结一下 map 中 key 的写入流程:
- 检测 map 中
hmap是否为空指针,是否有其他groutine在进行写入,如果有抛出错误;标记flags表示当前groutine在对 map 进行写操作 - 根据哈希值的低位获得对应的 bucket
- 判断是否正在进行扩容后的搬迁,如果是则先进行搬迁
- 计算高八位的哈希值,首先循环遍历桶中的 8 个 cell,如果 8 个 cell 遍历完还没有,则到溢出桶中进行遍历。这里分两种情况:
- 第一种情况是 cell 位的
tophash值和当前tophash值不相等,因为有可能删除导致中间个别cell没有值,但是在后面又还有可能找到相等的tophash,所以这时会先记录第一个不相等的值(可能当前位为空),然后继续遍历,目的是尽可能往前插入键值 - 第二种情况是
cell位的tophash值和当前的tophash值相等,此时会查看当前的 key 值,因为即使当前cell位的tophash值相等,不一定它对应的key也是相等的。不相等则继续遍历,相等则获取当前value的地址直接返回(相当于更新 value)。
- 如果遍历所有之后没有找到合适的位置,则需要新建溢出桶来承载键值对。这里也分为两种情况:
第一种是需要判断当前 map 的装载因子是否达到 6.5 的阈值或者溢出桶过多,这两种情况都需要对 map 进行扩容处理后再重新遍历
第二种情况则是在在不满足情况一的条件下,为当前桶新建溢出桶,此时优先通过碰撞指针的方式使用预分配的溢出桶,如果没有再申请新的溢出桶。之后将
tophash,key插入到新建溢出桶的对应内存的 0 号位置,然后返回value的底层内存位置
map 扩容
map 在扩容的时候有两个指标:装载因子和溢出桶的数量。
为了保证访问效率,当 map 将要添加、修改或删除 key 时,都会检查是否需要扩容,扩容实际上是以空间换时间的手段。在上面源码 mapassign 中,其实已经注释 map 扩容条件,主要是两点:
- 判断已经达到装载因子的临界点,即
元素个数 > 桶(bucket)总数 * 6.5,这时候说明大部分的桶可能都快满了(即平均每个桶存储的键值对达到 6.5 个),如果插入新元素,有大概率需要挂在溢出桶(overflow bucket)上。
func overLoadFactor(count int, B uint8) bool {
return count > bucketCnt && uintptr(count) > loadFactorNum*(bucketShift(B)/loadFactorDen)
}
- 判断溢出桶是否太多,当
桶总数 < 2 ^ 15时,如果溢出桶总数 >= 桶总数,则认为溢出桶过多。当桶总数 >= 2 ^ 15时,直接与2 ^ 15比较,当溢出桶总数 >= 2 ^ 15时,即认为溢出桶太多了。
func tooManyOverflowBuckets(noverflow uint16, B uint8) bool {
if B > 15 {
B = 15
}
return noverflow >= uint16(1)<<(B&15)
}
对于第2点,其实是对第 1 点的补充。因为在装载因子比较小的情况下,有可能 map 的查找和插入效率也很低,而仅判断第 1 点是避免不了这种情况的。在这种情况下,计算装载因子的分子比较小,即 map 里元素总数少,但是桶数量多(真实分配的桶数量多,包括大量的溢出桶)。
在某些场景下,比如不断的增删,这样会造成 overflow 的 bucket 数量增多,但负载因子又不高,未达不到第 1 点的临界值,就不能触发扩容来缓解这种情况。这样会造成桶的使用率不高,值存储得比较稀疏,查找插入效率会变得非常低,因此有了第 2 点判断指标。这就像是一座空城,房子很多,但是住户很少,都分散了,找起人来很困难。
例如下面,由于 map 的不断删除,0 号 bucket 中的桶链就造成了大量的稀疏桶。
针对这两种情况,官方采用了不同的解决方案
- 针对 1,将 B + 1,新建一个 buckets 数组,也就是说新的 buckets 大小是原来的 2 倍,然后旧 buckets 数据搬迁到新的 buckets。该方法称之为增量扩容。
- 针对 2,并不扩大容量,buckets 数量维持不变,重新做一遍类似增量扩容的搬迁动作,把松散的键值对重新排列一次,以使 bucket 的使用率更高,进而保证更快的存取。该方法称之为等量扩容。
对于 2 的解决方案,其实存在一个极端的情况:如果插入 map 的 key 哈希都一样,那么它们就会落到同一个 bucket 里,超过 8 个就会产生 overflow bucket,结果也会造成 overflow bucket 数过多。移动元素其实解决不了问题,因为这时整个哈希表已经退化成了一个链表,操作效率变成了 O(n)。但 Go 的每一个 map 都会在初始化阶段的 makemap 时定一个随机的哈希种子,所以要构造这种冲突是没那么容易的。
在源码中,和扩容相关的主要是 hashGrow() 函数与 growWork() 函数**。hashGrow() 函数实际上并没有真正地“搬迁”,它只是分配好了新的 buckets,并将老的 buckets 挂到了 oldbuckets 字段上。真正搬迁 buckets 的动作在 growWork() 函数中,而调用 growWork() 函数的动作是在 mapassign() 和 mapdelete() 函数中。**也就是插入(包括修改)、删除 key 的时候,都会尝试进行搬迁 buckets 的工作。它们会先检查 oldbuckets 是否搬迁完毕(检查 oldbuckets 是否为 nil),再决定是否进行搬迁工作。
再重新看一下 mapassign 的相关片段:
again:
...
// 如果 map 正在搬迁(即h.oldbuckets != nil)中,则先进行搬迁工作。
if h.growing() {
// 这里其实只搬迁了当前的 bucket
growWork(t, h, bucket)
}
...
// 重新跳入 again 逻辑,在进行完 growWork() 操作后,再次遍历新的桶。
if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
// 分配新的 buckets,并将老的 buckets 挂到 oldbuckets 字段上
hashGrow(t, h)
goto again
}
再分别看看 hashGrow 和 growWork 的实现:
hashGrow 函数:
func hashGrow(t *maptype, h *hmap) {
// 如果达到条件 1,那么将 B 值加 1,相当于是原来的 2 倍
// 否则对应条件 2,进行等量扩容,所以 B 不变
bigger := uint8(1)
if !overLoadFactor(h.count+1, h.B) {
bigger = 0
h.flags |= sameSizeGrow
}
// 记录老的buckets
oldbuckets := h.buckets
// 申请新的 buckets 空间
newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)
// 注意 &^ 运算符,这块代码的逻辑是转移标志位
flags := h.flags &^ (iterator | oldIterator)
if h.flags&iterator != 0 {
flags |= oldIterator
}
// 提交 grow
h.B += bigger
h.flags = flags
h.oldbuckets = oldbuckets
h.buckets = newbuckets
// 搬迁进度为0
h.nevacuate = 0
// overflow buckets 数为0
h.noverflow = 0
// 如果发现 hmap 是通过 extra 字段来存储 overflow buckets 时
if h.extra != nil && h.extra.overflow != nil {
// Promote current overflow buckets to the old generation.
if h.extra.oldoverflow != nil {
throw("oldoverflow is not nil")
}
h.extra.oldoverflow = h.extra.overflow
h.extra.overflow = nil
}
if nextOverflow != nil {
if h.extra == nil {
h.extra = new(mapextra)
}
h.extra.nextOverflow = nextOverflow
}
}
growWork 函数:
func growWork(t *maptype, h *hmap, bucket uintptr) {
// 为了确认搬迁的 bucket 是我们正在使用的 bucket
// 即如果当前 key 映射到老的 bucket1,那么就搬迁该 bucket1。
evacuate(t, h, bucket&h.oldbucketmask())
// 如果还未完成扩容工作,则再搬迁一个bucket。
if h.growing() {
evacuate(t, h, h.nevacuate)
}
}
从 growWork() 函数可以知道,搬迁的核心逻辑是 evacuate() 函数。
从上面可以看出,扩容过程是渐进性的,每次最多搬迁两个桶。
为什么每次至多搬迁 2 个bucket?
这其实是一种性能考量,如果 map 存储了数以亿计的 key-value,一次性搬迁将会造成比较大的延时,因此才采用逐步搬迁策略。
在搬迁函数 evacuate 中,其逻辑主要涉及一个是 bucket 序列号的变化,另外一个就是搬迁区间的确认。
- bucket 序列号的变化
对于 bucket 序列号的变化,增量扩容(条件1)和等量扩容(条件2)都需要进行 bucket 的搬迁工作。对于等量扩容而言,由于 buckets 的数量不变,因此可以按照序号来搬迁。例如老的的 0 号 bucket,仍然搬至新的 0 号 bucket 中。

但是,对于增量扩容而言,就会有所不同。例如原来的 B=5,那么增量扩容时,B 就会变成 6。那么决定 key 值落入哪个 bucket 的低位哈希值就会发生变化(从取 5 位变为取 6 位),取新的低位 hash 值得过程称为 rehash。

因此,在增量扩容中,某个 key 在搬迁前后 bucket 序号可能和原来相等,也可能是相比原来加上 2^B(原来的 B 值),取决于低 hash 值第倒数第 B+1 位是 0 还是 1。
如下图中,当原始的 B = 3 时,旧 buckets 数组长度为 8,在编号为 2 的 bucket 中,其 2 号 cell 和 5 号 cell,它们的低 3 位哈希值相同(不相同的话,也就不会落在同一个桶中了),但是它们的低 4 位分别是 0010、1010。当发生了增量扩容,2 号就会被搬迁到新 buckets 数组的 2 号 bucket 中去,5 号被搬迁到新 buckets 数组的 10 号 bucket 中去,它们的桶号差距是 2 的 3 次方。
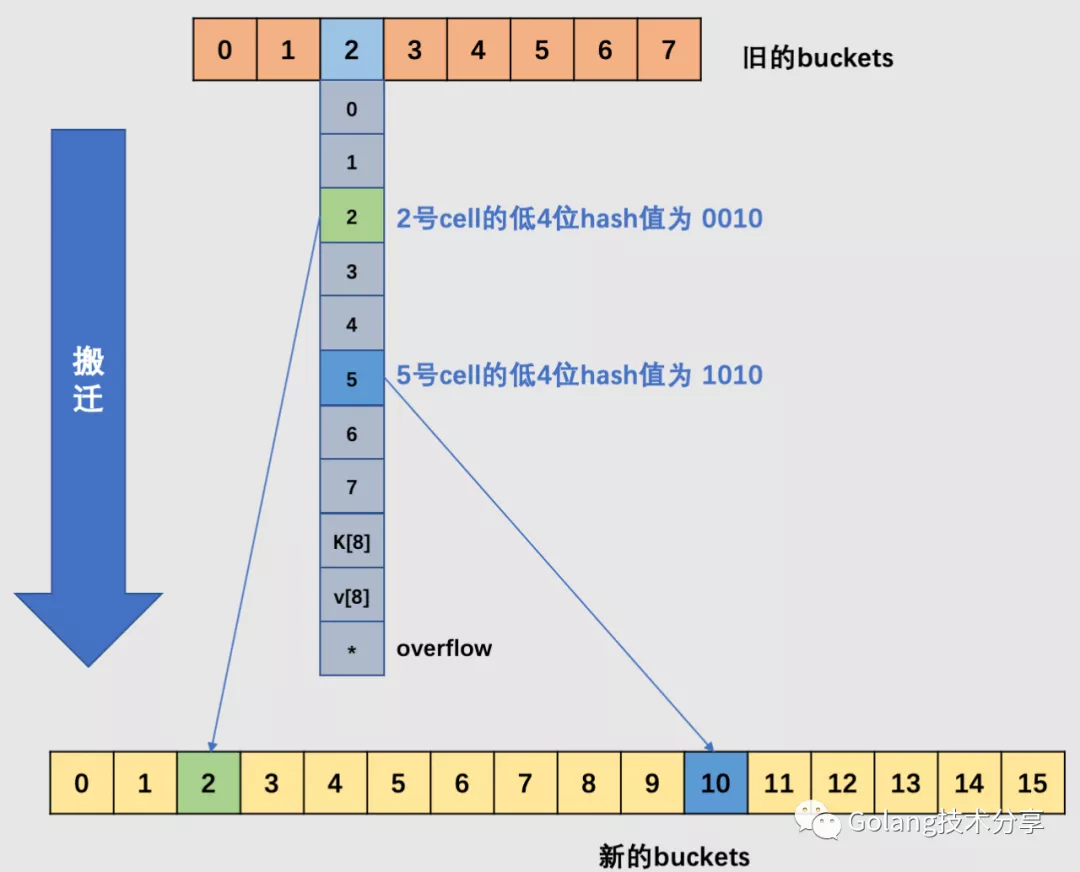
- 搬迁区间的确认
在源码中,有 bucket x 和 bucket y 的概念,其实就是增量扩容到原来的 2 倍,桶的数量是原来的 2 倍,前一半桶被称为 bucket x,后一半桶被称为 bucket y。一个 bucket 中的 key 可能会分裂到两个桶中去,分别位于 bucket x 的桶,或 bucket y 中的桶。所以在搬迁一个 cell 之前,需要知道这个 cell 中的 key 是落到哪个区间(而对于同一个桶而言,搬迁到 bucket x 和 bucket y 桶序号的差别是老的 buckets 大小,即 2^old_B)。
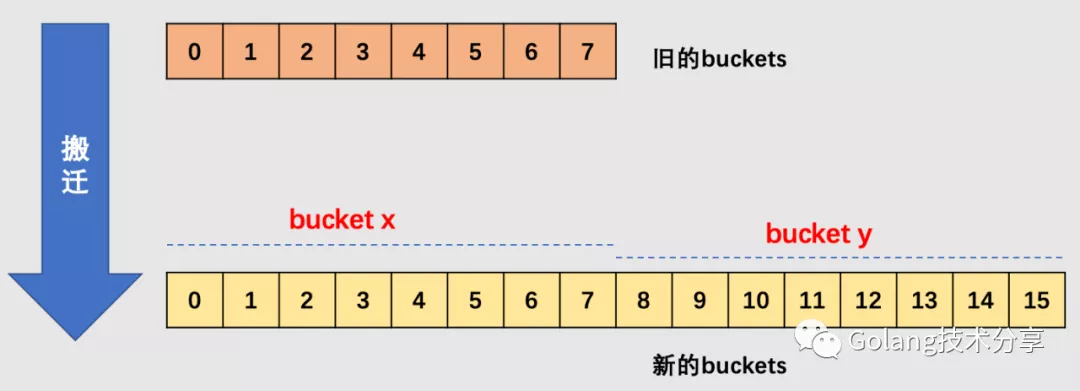
确定了要搬迁到的目标 bucket 后,搬迁操作就比较好进行了。将源 key/value 值 copy 到目的地相应的位置。设置 key 在原始 buckets 的 tophash 为 evacuatedX 或是 evacuatedY,表示已经搬迁到了新 map 的bucket x 或是 bucket y,新 map 的 tophash 则正常取 key 哈希值的高 8 位。
为什么确定 key 落在哪个区间很重要?
因为对于增量扩容而言,原本一个 bucket 中的 key 会被分裂到两个 bucket 中去,它们分别处于 bucket x 和 bucket y 中,但是它们之间存在关系 bucket x + 2^B = bucket y (其中,B 是老 bucket 对应的 B 值)。
假设 key 所在的老 bucket 序号为 n,那么如果 key 落在新的 bucket x,则它应该置入 bucket x 起始位置 + n*bucket 的内存中去;如果 key 落在新的 bucket y,则它应该置入 bucket y 起始位置 + n*bucket 的内存中去。因此,确定 key 落在哪个区间,这样就很方便进行内存地址计算,快速找到 key 应该插入的内存地址。
下面看看 evacuate() 函数的具体实现:
func evacuate(t *maptype, h *hmap, oldbucket uintptr) {
// 传进来的 oldbucket 实际上是当前定位到的需要搬迁的 bucket
// 这里首先定位原先 bucket 的位置
b := (*bmap)(add(h.oldbuckets, oldbucket*uintptr(t.bucketsize)))
// 获取扩容之前 bucket 的个数
newbit := h.noldbuckets()
// 判断该 bucket 是否已经完成搬迁
if !evacuated(b) {
// 官方TODO,后续也许会实现:如果没有迭代器使用旧的存储桶,则重用溢出存储桶而不是使用新的存储桶。
// xy 包含了高低区间的搬迁目的地内存信息,[bucket, index, key, value]
// x.b 是对应的搬迁目的桶
// x.k 是指向对应目的桶中存储当前 key 的内存地址
// x.e 是指向对应目的桶中存储当前 value 的内存地址
var xy [2]evacDst
x := &xy[0]
// 获取基地址
x.b = (*bmap)(add(h.buckets, oldbucket*uintptr(t.bucketsize)))
x.k = add(unsafe.Pointer(x.b), dataOffset)
x.e = add(x.k, bucketCnt*uintptr(t.keysize))
// 只有当增量扩容时才计算 bucket y 的相关信息(和后续计算 useY 相呼应)
if !h.sameSizeGrow() {
y := &xy[1]
y.b = (*bmap)(add(h.buckets, (oldbucket+newbit)*uintptr(t.bucketsize)))
y.k = add(unsafe.Pointer(y.b), dataOffset)
y.e = add(y.k, bucketCnt*uintptr(t.keysize))
}
// evacuate 函数每次只完成一个 bucket 的搬迁工作,因此要遍历完此 bucket 的所有的 cell,将有值的 cell copy 到新的地方。
// bucket 还会链接 overflow bucket,它们同样需要搬迁。
// 因此同样会有 2 层循环,外层遍历 bucket 和 overflow bucket,内层遍历 bucket 的所有 cell。
// 遍历当前桶 bucket 和其之后的溢出桶 overflow bucket
// 注意:初始的 b 是待搬迁的老 bucket
for ; b != nil; b = b.overflow(t) {
k := add(unsafe.Pointer(b), dataOffset)
e := add(k, bucketCnt*uintptr(t.keysize))
// 遍历桶中的 cell,这里 i,k,e 分别用于对应 tophash 下标,key 和 value
for i := 0; i < bucketCnt; i, k, e = i+1, add(k, uintptr(t.keysize)), add(e, uintptr(t.elemsize)) {
// 获取tophash
top := b.tophash[i]
// 如果当前 cell 的 tophash 值是 emptyOne 或者 emptyRest,
// 则代表此 cell 没有key。将其标记为evacuatedEmpty,表示它“已经被搬迁”。
if isEmpty(top) {
b.tophash[i] = evacuatedEmpty
continue
}
// 正常不会出现这种情况
// 未被搬迁的 cell 只可能是 emptyOne、emptyRest 或是正常的 top hash(大于等于 minTopHash)
if top < minTopHash {
throw("bad map state")
}
k2 := k
// 如果 key 是指针,则解引用
if t.indirectkey() {
k2 = *((*unsafe.Pointer)(k2))
}
var useY uint8
// 如果是增量扩容
if !h.sameSizeGrow() {
// 计算哈希值,判断当前key和vale是要被搬迁到bucket x还是bucket y
hash := t.hasher(k2, uintptr(h.hash0))
if h.flags&iterator != 0 && !t.reflexivekey() && !t.key.equal(k2, k2) {
// 有一个特殊情况:有一种 key,每次对它计算 hash,得到的结果都不一样。
// 这个 key 就是 math.NaN() 的结果,它的含义是 not a number,类型是 float64。
// 当它作为 map 的 key时,会遇到一个问题:再次计算它的哈希值和它当初插入 map 时的计算出来的哈希值不一样!
// 这个 key 是永远不会被 Get 操作获取的!当使用 m[math.NaN()] 语句的时候,是查不出来结果的。
// 这个 key 只有在遍历整个 map 的时候,才能被找到。
// 并且,可以向一个 map 插入多个数量的 math.NaN() 作为 key,它们并不会被互相覆盖。
// 当搬迁碰到 math.NaN() 的 key 时,只通过 tophash 的最低位决定分配到 X part 还是 Y part(如果扩容后是原来 buckets 数量的 2 倍)。
// 如果 tophash 的最低位是 0 ,分配到 X part;如果是 1 ,则分配到 Y part。
useY = top & 1
top = tophash(hash)
} else {
// 对于正常的 key,则进入 else 的逻辑
if hash&newbit != 0 {
useY = 1
}
}
}
if evacuatedX+1 != evacuatedY || evacuatedX^1 != evacuatedY {
throw("bad evacuatedN")
}
// 标示这个位置k,v 迁到 x 还是 y,
// 因为 evacuatedX + 1 == evacuatedY,如果 useY 是 0,那就是 x,否则是 y
b.tophash[i] = evacuatedX + useY
// useY 要么为0,要么为 1。
// 这里就是选取在 bucket x 的起始内存位置,或者选择在 bucket y 的起始内存位置
// (只有增量同步才会有这个选择可能)。
dst := &xy[useY]
// 如果目的地的桶已经装满了(8个cell),那么需要新建一个溢出桶,继续搬迁到溢出桶上去。
if dst.i == bucketCnt {
// newoverflow() 前面分析过,它会当将已经事先创建好的 overflow bucket 设置到 bucket 上了
dst.b = h.newoverflow(t, dst.b)
dst.i = 0
dst.k = add(unsafe.Pointer(dst.b), dataOffset)
dst.e = add(dst.k, bucketCnt*uintptr(t.keysize))
}
// 通过与操作直接避免了边界检查,并设置相应下标位置的值为 tophash(真的妙!!!)
dst.b.tophash[dst.i&(bucketCnt-1)] = top
// 如果待搬迁的key是指针,则复制指针过去
if t.indirectkey() {
*(*unsafe.Pointer)(dst.k) = k2
} else {
// 如果待搬迁的key是值,则复制值过去
typedmemmove(t.key, dst.k, k)
}
// value 和 key 同理
if t.indirectelem() {
*(*unsafe.Pointer)(dst.e) = *(*unsafe.Pointer)(e)
} else {
typedmemmove(t.elem, dst.e, e)
}
// 将当前搬迁目的桶的记录 key/value 的索引值(也可以理解为 cell 的索引值)加一
dst.i++
// 计算下一个 dst.k,dst.e 的内存地址
// 由于桶的内存布局中在最后还有 overflow 的指针,所以这里不用担心更新有可能会超出 key 和 value 数组的指针地址。
dst.k = add(dst.k, uintptr(t.keysize))
dst.e = add(dst.e, uintptr(t.elemsize))
}
}
// 如果没有协程在使用老的桶,就对老的桶进行清理,用于帮助 gc
if h.flags&oldIterator == 0 && t.bucket.ptrdata != 0 {
b := add(h.oldbuckets, oldbucket*uintptr(t.bucketsize))
// 只清除 bucket 的 key,value 部分,保留 top hash 部分,指示搬迁状态
ptr := add(b, dataOffset)
n := uintptr(t.bucketsize) - dataOffset
memclrHasPointers(ptr, n)
}
}
// 用于更新搬迁进度
if oldbucket == h.nevacuate {
advanceEvacuationMark(h, t, newbit)
}
}
更新搬迁进度的函数 advanceEvacuationMark 实现如下:
func advanceEvacuationMark(h *hmap, t *maptype, newbit uintptr) {
// 搬迁桶的进度加一
h.nevacuate++
// 实验表明,1024 至少会比 newbit 高出一个数量级。
// newbit 是传进来的参数,代表扩容之前老的 bucket 个数。
// 所以,用当前进度加 1024 用于确保 O(1) 行为。
stop := h.nevacuate + 1024
if stop > newbit {
stop = newbit
}
// 计算已经搬迁完的桶数
for h.nevacuate != stop && bucketEvacuated(t, h, h.nevacuate) {
h.nevacuate++
}
// 如果h.nevacuate == newbit,则代表所有的桶都已经搬迁完毕
if h.nevacuate == newbit { // newbit == # of oldbuckets
// 搬迁完毕,所以指向老的 buckets 的指针置为nil
h.oldbuckets = nil
// 前面说过,如果 map 中 key 和 value 均不包含指针,则都可以 inline。
// 那么保存它们的 buckets 数组其实是挂在 hmap.extra 中的。
// 所以,这种情况下,其实我们是搬迁的 extra 的 buckets 数组。
// 因此,在这种情况下,需要在搬迁完毕后,将 hmap.extra.oldoverflow 指针置为nil。
if h.extra != nil {
h.extra.oldoverflow = nil
}
// 最后,清除正在扩容的标志位,扩容完毕。
h.flags &^= sameSizeGrow
}
}
这里在看一下对于判断当前 bucket 是否搬迁完成的函数 evacuated :
func evacuated(b *bmap) bool {
h := b.tophash[0]
return h > emptyOne && h < minTopHash
}
如果 b.tophash[0] 的值在标志值范围内,即在 (0,4) 区间里,说明已经被搬迁过了。
empty = 0
evacuatedEmpty = 1
evacuatedX = 2
evacuatedY = 3
minTopHash = 4
到这里就完成了 map 的扩容,总结一下整体的流程如下:
- 首先判断是需要等量扩容还是增量扩容,增量扩容的条件是
元素个数 > 桶(bucket)总数 * 6.5。而等量扩容的条件是当桶总数 < 2 ^ 15时,如果溢出桶总数 >= 桶总数,则认为溢出桶过多;当桶总数 >= 2 ^ 15时,直接与2 ^ 15比较,当溢出桶总数 >= 2 ^ 15时,即认为溢出桶太多了 - 记录当前
buckets数据,申请新的buckets空间 - 将
oldbuckets指针原有的buckets,设置nextOverflow指针 - 通过
growWork函数执行旧键值对的搬迁,搬迁采用渐进式的方式,每次至多搬迁 2 个bucket。 - 搬迁过程会进行 rehash,对于等量扩容,则只需要将旧的键值对取出来依次放入即可;对于增量扩容,从哈希值的倒数 B 位(原来的 B 值)多取 1 位,变成 B+1位(这里其实是因为扩容后容量为 2 倍,所以在最高位多取一位相当于乘以 2)。然后根据多取出来的一位是 0 还是 1 进行分配,0 则分配到前一般桶
bucket x加上偏移的位置;1 则分配到后一般桶backet y对应加上偏移的位置。
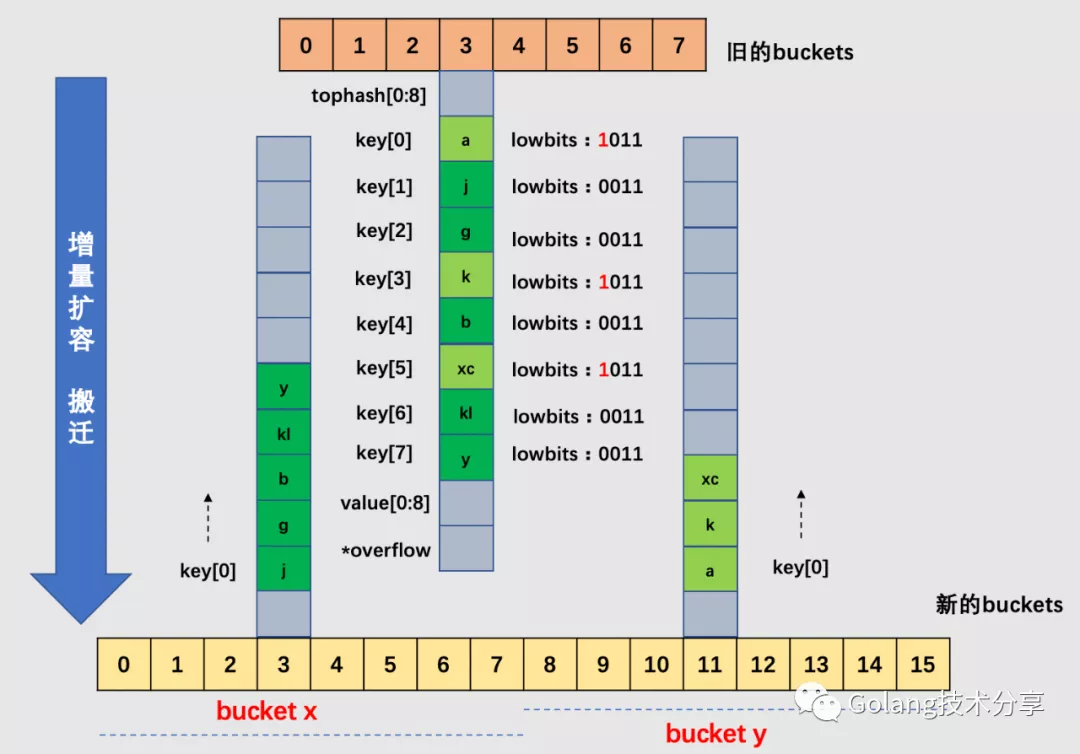
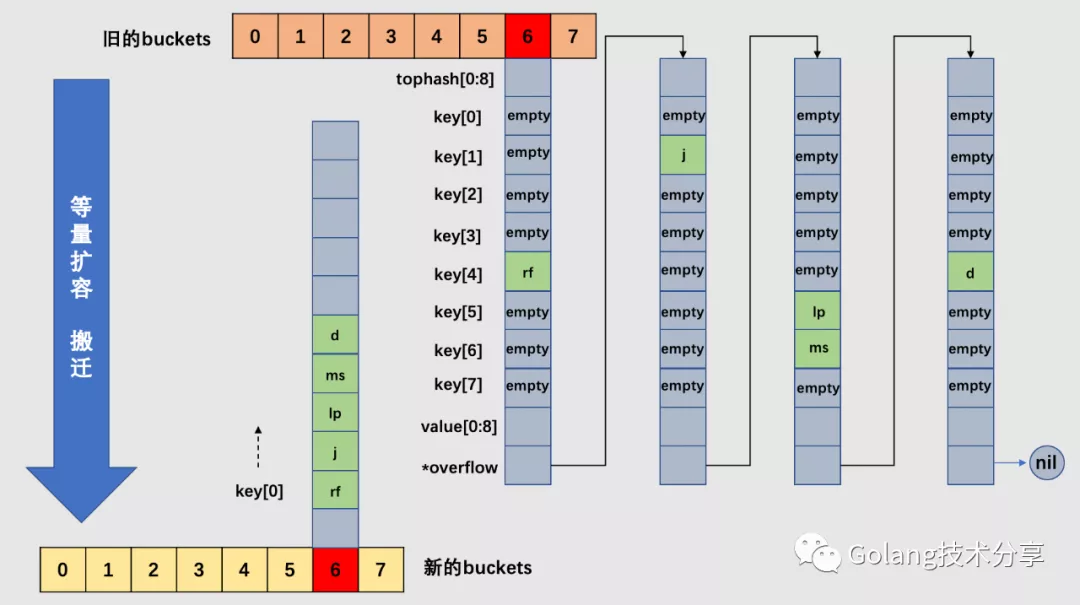
针对下面的 map,其 B 为3,所以原始 buckets 数组为8。当 map 元素数变多,加载因子超过 6.5,所以引起了增量扩容。
以 3 号 bucket 为例,可以看到,由于 B 值加 1,所以在新选取桶时,需要取低 4 位哈希值,这样就会造成 cell 会被搬迁到新 buckets 数组中不同的桶(3 号或 11 号桶)中去。注意,在一个桶中,搬迁 cell 的工作是有序的:它们是依序填进对应新桶的 cell 中去的。
当然,实际情况中 3 号桶很可能还有溢出桶,在这里为了简化绘图,假设 3 号桶没有溢出桶,如果有溢出桶,则相应地添加到新的 3 号桶和 11 号桶中即可,如果对应的 3 号和 11 号桶均装满,则给新的桶添加溢出桶来装载。
对于下图的 map,其 B 也为 3。假设整个 map 中的 overflow 过多,触发了等量扩容。注意,等量扩容时,新的 buckets 数组大小和旧 buckets 数组是一样的。
以 6 号桶为例,它有一个 bucket 和 3 个 overflow buckets,但是实际上桶里的数据非常稀疏,等量扩容的目的就是为了把松散的键值对重新排列一次,以使 bucket 的使用率更高,进而保证更快的存取。搬迁完毕后,新的 6 号桶中只有一个基础 bucket,暂时并不需要溢出桶。这样,和原 6 号桶相比,数据变得紧密,使后续的数据存取变快。
删除 key
哈希表的删除逻辑与写入逻辑很相似,只是触发哈希的删除需要使用关键字,如果在删除期间遇到了哈希表的扩容,就会分流桶中的元素,分流结束之后会找到桶中的目标元素完成键值对的删除工作。
删除操作底层的执行函数是 mapdelete,它的流程如下:
首先会检查
h.flags标志,如果发现写标位是 1,直接panic,因为这表明有其他协程同时在进行写操作。接着计算
key的哈希,找到落入的bucket。检查此map如果正在扩容的过程中,直接触发一次搬迁操作。删除操作同样是两层循环,核心还是找到
key的具体位置。寻找过程都是类似的,在bucket中挨个cell寻找。找到对应位置后,对
key或者value进行“清零”操作。修改
map中cell的状态,如果bucket以一堆emptyOne状态结束, 还需要将其更改为emptyRest状态
func mapdelete(t *maptype, h *hmap, key unsafe.Pointer) {
// 如果开启了竞态检测 -race
if raceenabled && h != nil {
callerpc := getcallerpc()
pc := funcPC(mapdelete)
racewritepc(unsafe.Pointer(h), callerpc, pc)
raceReadObjectPC(t.key, key, callerpc, pc)
}
// 如果开启了memory sanitizer -msan
if msanenabled && h != nil {
msanread(key, t.key.size)
}
// 如果map为空或者元素个数为0, 直接返回
if h == nil || h.count == 0 {
if t.hashMightPanic() {
t.hasher(key, 0) // see issue 23734
}
return
}
// 当 h.flags 对应的值为 hashWriting (代表有其他goroutine正在往map中写key)时,
// 那么位计算的结果不为0, 因此抛出错误
if h.flags&hashWriting != 0 {
throw("concurrent map writes")
}
hash := t.hasher(key, uintptr(h.hash0))
// 将 flags 的值与 hashWriting 做按位 "异或" 运算
// 之所以调用 t.hasher 后设置 hashWriting, 是因为 t.hasher 可能会 panic,
// 在这种情况下, 实际上并没有执行写(删除)操作.
h.flags ^= hashWriting
// 计算出桶的位置
bucket := hash & bucketMask(h.B)
if h.growing() {
// 直接触发一次搬迁操作
growWork(t, h, bucket)
}
// 获取 bucket 的内存地址
b := (*bmap)(add(h.buckets, bucket*uintptr(t.bucketsize)))
bOrig := b
top := tophash(hash)
search:
// 以下是查找的核心逻辑
// 同样双重循环遍历: 外层循环是从桶到溢出桶遍历; 内层是桶中的cell遍历
// 跳出循环的条件有三种:
// 第一种是已经找到 key 值, 并且已经完成清理工作
// 第二种是当前桶再无溢出桶;
// 第三种是当前桶中有 cell 位的 tophash 值是 emptyRest, 它代表此时的桶后面的 cell 还未利用, 所以无需再继续遍历
for ; b != nil; b = b.overflow(t) {
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
// 第三种情况
if b.tophash[i] == emptyRest {
break search
}
continue
}
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
k2 := k
if t.indirectkey() {
k2 = *((*unsafe.Pointer)(k2))
}
if !t.key.equal(key, k2) {
continue
}
// 第一种情况, 说明已经找到了 key 值完全一样
// 对 key 清零
if t.indirectkey() {
*(*unsafe.Pointer)(k) = nil
} else if t.key.ptrdata != 0 {
memclrHasPointers(k, t.key.size)
}
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))
// 对 value 清零
if t.indirectelem() {
*(*unsafe.Pointer)(e) = nil
} else if t.elem.ptrdata != 0 {
memclrHasPointers(e, t.elem.size)
} else {
memclrNoHeapPointers(e, t.elem.size)
}
// 对应的 tophash 设置成 emptyOne
b.tophash[i] = emptyOne
// 如果 bucket 现在以一堆 emptyOne 状态结束, 将其更改为 emptyRest 状态.
// 将此功能设为一个单独的函数会很好, 但是 for 循环当前不可内联
// 可以立即结束循环的的两种状况:
// 情况1: 当前 cell 是 bucket 的最后一个 cell, 且后续的 overflow bucket 的 cell tophash 不为 emptyRest
// 情况2: 当前 cell 后续的 cell tophash 不为 emptyRest
if i == bucketCnt-1 {
// 第一种情况
if b.overflow(t) != nil && b.overflow(t).tophash[0] != emptyRest {
goto notLast
}
} else {
// 第二种情况
if b.tophash[i+1] != emptyRest {
goto notLast
}
}
// 如果 bucket 现在以一堆 emptyOne 状态结束, 将其更改为 emptyRest 状态
// 在这里存在两种情况:
// 跳出本循环的两种情况:
// 1. 遇到桶内的第一个 bucket。注意: 桶实质上就是一个单向的链表。
// 2. 遇到 cell 的 tophash 非删除状态(emptyOne)
for {
b.tophash[i] = emptyRest
if i == 0 {
// 回到桶开始的位置
if b == bOrig {
break
}
// 获取当前 bucket 的前面的 prev bucket(即 prev bucket 的 overflow 是当前 bucket)
// 每次都是从桶内的首个元素开始,相当于从后往前将 emptyOne 改成 emptyRest
c := b
for b = bOrig; b.overflow(t) != c; b = b.overflow(t) {
}
i = bucketCnt - 1
} else {
i--
}
if b.tophash[i] != emptyOne {
break
}
}
notLast:
// 对应 count 值减一
h.count--
break search
}
}
if h.flags&hashWriting == 0 {
throw("concurrent map writes")
}
// 清除 hashWriting flag
h.flags &^= hashWriting
}
同样,和写入函数一样,根据 key 类型的不同,删除操作会被优化成更具体的函数:
| key 类型 | 删除 |
|---|---|
| uint32 | mapdelete_fast32(t *maptype, h *hmap, key uint32) |
| uint64 | mapdelete_fast64(t *maptype, h *hmap, key uint64) |
| string | mapdelete_faststr(t *maptype, h *hmap, ky string) |
遍历 map
迭代 map 的结果是无序的,对于下面的例子:
package main
func main() {
m := make(map[int]int)
for i := 0; i < 10; i++ {
m[i] = i
}
for k, v := range m {
fmt.Println(k, v)
}
}
运行以上代码,会发现每次输出顺序都是不同的。
map 遍历的过程,是按序遍历 bucket,同时按需遍历 bucket 中和其 overflow bucket 中的 cell。但是 map 在扩容后,会发生 key 的搬迁,这造成原来落在一个 bucket 中的 key,搬迁后,有可能会落到其他 bucket 中了,从这个角度看,遍历 map 的结果就不可能是按照原来的顺序了。
但其实,go 为了保证遍历 map 的结果是无序的,做了以下事情:map在遍历时,并不是从固定的 0 号 bucket 开始遍历的,每次遍历,都会从一个随机值序号的 bucket,再从其中随机的 cell 开始遍历。然后再按照桶序遍历下去,直到回到起始桶结束。
下面的例子是遍历一个处于未扩容状态的 map。如果 map 正处于扩容状态时,需要先判断当前遍历 bucket 是否已经完成搬迁,如果数据还在老的 bucket,那么就去老 bucket 中拿数据。
当发生了增量扩容时,一个老的 bucket 数据可能会分裂到两个不同的 bucket 中去,那么此时,如果需要从老的 bucket 中遍历数据,例如 1 号,则不能将老 1 号 bucket 中的数据全部取出,仅仅只能取出老 1 号 bucket 中那些在裂变之后,分配到新 1 号 bucket 中的那些 key。
对下面的例子进行编译:
package main
import "fmt"
func main() {
m := make(map[string]int)
m["silverming"] = 18
for k, v := range m {
fmt.Println(k, v)
}
}
执行命令:
go tool compile -S main.go
可以看到如下几行汇编的代码:
//...
0x0104 00260 (main.go:8) CALL runtime.mapiterinit(SB)
//...
0x01c8 00456 (main.go:8) CALL runtime.mapiternext(SB)
//...
可以看到对于 map 的迭代,底层调用的是 mapiterinit 和 mapiternext 函数。
mapiterinit 就是对 hiter 结构体里的字段进行初始化赋值操作,这个结构用于保证随机性。
hiter 的结构如下:
type hiter struct {
// key 指针
key unsafe.Pointer
// value 指针
elem unsafe.Pointer
// map 类型,包含如 key size 大小等
t *maptype
h *hmap
// 初始化时指向的 buckets
buckets unsafe.Pointer
// 当前遍历到的 bmap
bptr *bmap
overflow *[]*bmap // keeps overflow buckets of hmap.buckets alive
oldoverflow *[]*bmap // keeps overflow buckets of hmap.oldbuckets alive
// 起始遍历的 bucket 编号
startBucket uintptr
// 在迭代过程中开始的桶内偏移,也就是从桶的哪个 cell 开始
offset uint8
// 是否又从头遍历了
wrapped bool
// B 的大小
B uint8
// 当前 cell 序号
i uint8
// 指向当前的 bucket
bucket uintptr
// 因为扩容需要检查的 bucket
checkBucket uintptr
}
mapinterinit 函数的实现如下:
// mapiterinit 初始化用于在 map 上进行遍历的 hiter 结构
// it 指向的 hiter 结构由编译器顺序传递在堆栈上分配, 或者由 reflect_mapiterinit 在堆上分配
// 由于结构包含指针, 因此两者都需要将 hiter 归零
func mapiterinit(t *maptype, h *hmap, it *hiter) {
// 如果开启了竞态检测 -race
if raceenabled && h != nil {
callerpc := getcallerpc()
racereadpc(unsafe.Pointer(h), callerpc, funcPC(mapiterinit))
}
// hmap 不存在 或者 hmap 没有存储数据
if h == nil || h.count == 0 {
return
}
// hiter 的大小是 12 个系统指针大小。在 cmd/compile/internal/gc/reflect.go:hiter() 当中有这样的体现
if unsafe.Sizeof(hiter{})/sys.PtrSize != 12 {
throw("hash_iter size incorrect") // see cmd/compile/internal/gc/reflect.go
}
it.t = t
it.h = h
// 抓取桶状态快照
it.B = h.B
it.buckets = h.buckets
if t.bucket.ptrdata == 0 {
// 重新分配 overflow
// 并在 hiter 中存储指向当前 h.extra.overflow 和 h.extra.oldoverflow.
// 这样在迭代的过程中, 不论 table 的增长还是有新的 overflow buckets 被添加到 table 当中
// 都可以让 overflow bucket 处于活动状态
h.createOverflow()
it.overflow = h.extra.overflow
it.oldoverflow = h.extra.oldoverflow
}
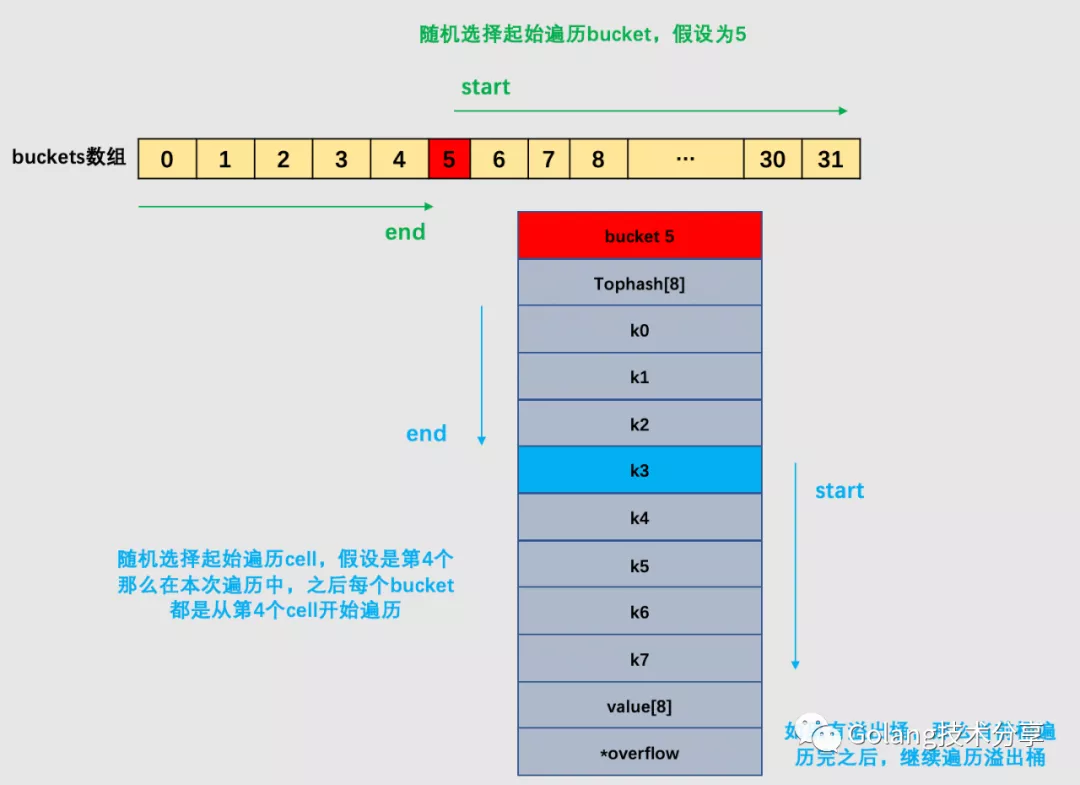
// 随机迭代的关键代码
// 生成随机数
r := uintptr(fastrand())
if h.B > 31-bucketCntBits {
// 在 B>28 时, 增加一个偏移量
r += uintptr(fastrand()) << 31
}
// 确定从哪个 bucket 开始遍历
// bucketMask(h.B) 返回 2^B-1,也就是桶的数量-1
it.startBucket = r & bucketMask(h.B)
// 确定从哪个 bucket 的哪个 cell 开始遍历
it.offset = uint8(r >> h.B & (bucketCnt - 1))
// iterator state
it.bucket = it.startBucket
// 标记当前的迭代器
// 多个迭代器可以同时运行
if old := h.flags; old&(iterator|oldIterator) != iterator|oldIterator {
atomic.Or8(&h.flags, iterator|oldIterator)
}
// 开始进行迭代
mapiternext(it)
}
上面的代码实现中,例如,B = 2,那 bucketMask(h.B) 结果就是 3,低 8 位为 00000011,将 r 与之相与,就可以得到一个 0~3 的 bucket 序号;bucketCnt - 1 等于 7,低 8 位为 00000111,将 r 右移 2 位后,与 7 相与,就可以得到一个 0~7 号的 cell。
于是,在 mapiternext 函数中就会从 it.startBucket 的 it.offset 号的 cell 开始遍历,取出其中的 key 和 value,直到又回到起点 bucket,完成遍历过程。
源码部分比较好看懂,尤其是理解了前面注释的几段代码后,再看这部分代码就没什么压力了。所以,接下来,通过图形化的方式说说整个遍历过程。
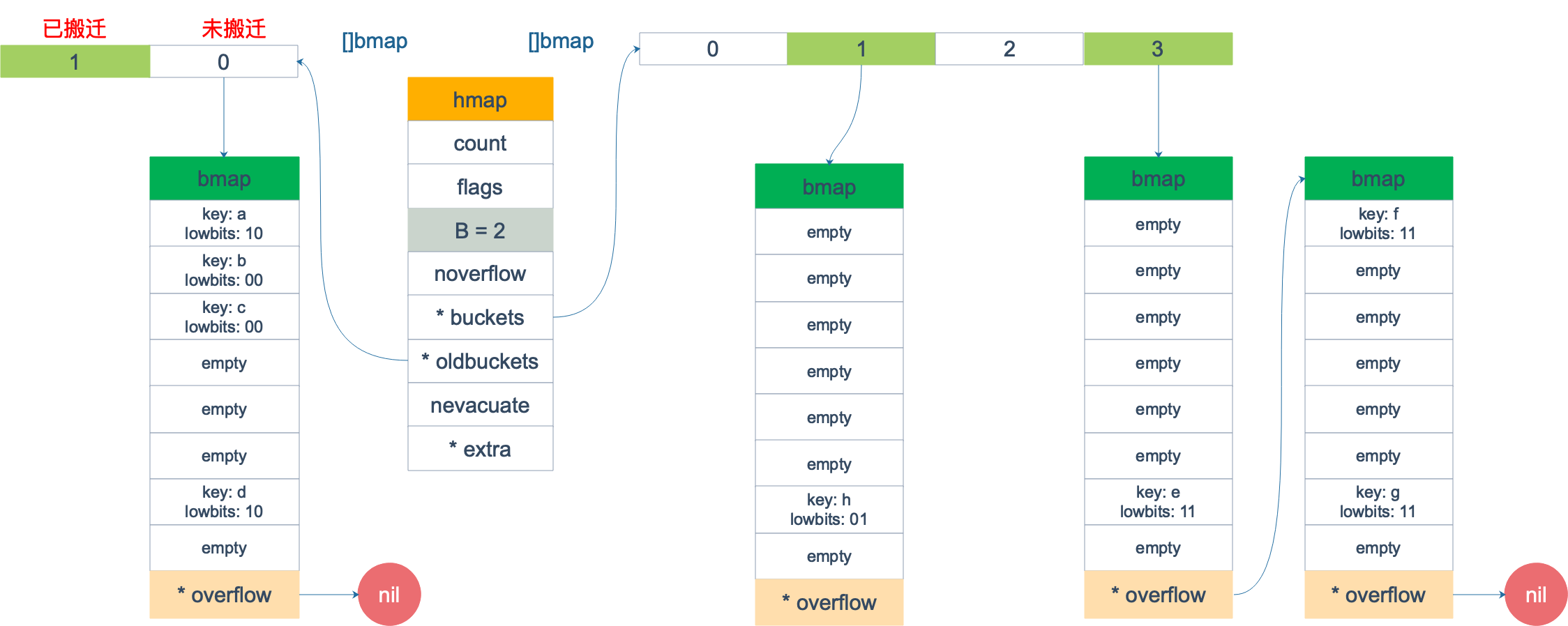
假设有下图所示的一个 map,起始时 B = 1,有两个 bucket,后来触发了扩容(这里不要深究扩容条件,只是一个设定),B 变成 2。并且, 1 号 bucket 中的内容搬迁到了新的 bucket,1 号裂变成 1 号和 3 号;0 号 bucket 暂未搬迁。老的 bucket 挂在在 *oldbuckets 指针上面,新的 bucket 则挂在 *buckets 指针上面。
这时,对此 map 进行遍历。假设经过初始化后,startBucket = 3,offset = 2。于是,遍历的起点将是 3 号 bucket 的 2 号 cell,下面这张图就是开始遍历时的状态:
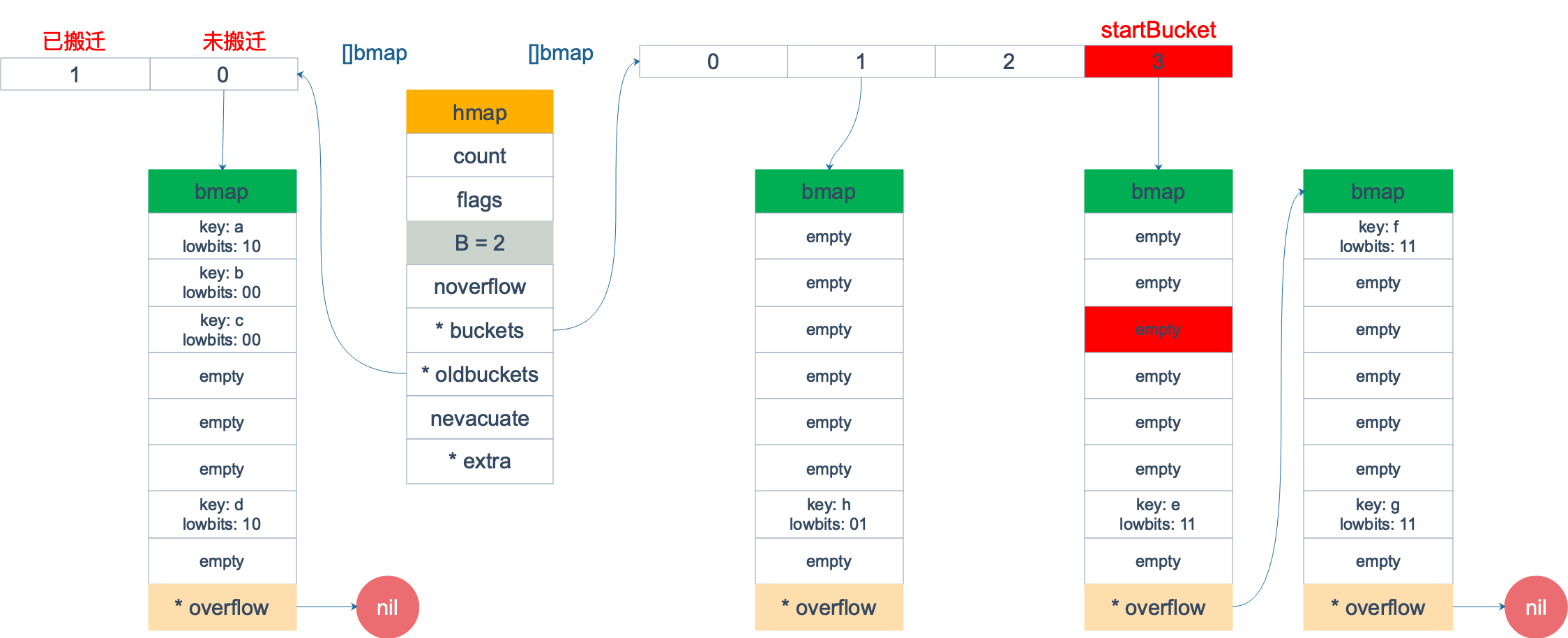
标红的表示起始位置,bucket 遍历顺序为:3 -> 0 -> 1 -> 2。
因为 3 号 bucket 对应老的 1 号 bucket,因此先检查老 1 号 bucket 是否已经被搬迁过。判断方法就是:
func evacuated(b *bmap) bool {
h := b.tophash[0]
return h > empty && h < minTopHash
}
如果 b.tophash[0] 的值在标志值范围内,即在 (0,4) 区间里,说明已经被搬迁过了。
empty = 0
evacuatedEmpty = 1
evacuatedX = 2
evacuatedY = 3
minTopHash = 4
在本例中,老 1 号 bucket 已经被搬迁过了。所以它的 tophash[0] 值在 (0,4) 范围内,因此只用遍历新的 3 号 bucket。
依次遍历 3 号 bucket 的 cell,这时候会找到第一个非空的 key:元素 e。到这里,mapiternext 函数返回,这时的遍历结果仅有一个元素。
由于返回的 key 不为空,所以会继续调用 mapiternext 函数。
继续从上次遍历到的地方往后遍历,从新 3 号 overflow bucket 中找到了元素 f 和 元素 g。
新 3 号 bucket 遍历完之后,回到了新 0 号 bucket。0 号 bucket 对应老的 0 号 bucket,经检查,老 0 号 bucket 并未搬迁,因此对新 0 号 bucket 的遍历就改为遍历老 0 号 bucket。
那是不是把老 0 号 bucket 中的所有 key 都取出来呢?并没有这么简单,老 0 号 bucket 在搬迁后将裂变成 2 个 bucket:新 0 号、新 2 号。而我们此时正在遍历的只是新 0 号 bucket(注意,遍历都是遍历的 *bucket 指针,也就是所谓的新 buckets)。所以,只会取出老 0 号 bucket 中那些在裂变之后,分配到新 0 号 bucket 中的那些 key。
因此,lowbits == 00 的将进入遍历结果集。
和之前的流程一样,继续遍历新 1 号 bucket,发现老 1 号 bucket 已经搬迁,只用遍历新 1 号 bucket 中现有的元素就可以了。
继续遍历新 2 号 bucket,它来自老 0 号 bucket,因此需要在老 0 号 bucket 中那些会裂变到新 2 号 bucket 中的 key,也就是 lowbit == 10 的那些 key。
最后,继续遍历到新 3 号 bucket 时,发现所有的 bucket 都已经遍历完毕,整个迭代过程执行完毕。
所以整个遍历后的结果就是:

接下来看看遍历过程,mapiternext 的实现:
func mapiternext(it *hiter) {
h := it.h
// 如果开启了竞态检测 -race
if raceenabled {
callerpc := getcallerpc()
racereadpc(unsafe.Pointer(h), callerpc, funcPC(mapiternext))
}
// 检测当前是不是有 groutine 在进行写入,有的话直接抛出错误
if h.flags&hashWriting != 0 {
throw("concurrent map iteration and map write")
}
// 获取相应的元素
t := it.t
bucket := it.bucket
b := it.bptr
i := it.i
checkBucket := it.checkBucket
next:
// current bucket 为 nil, 第一次或者最后一次迭代
if b == nil {
// 当前的 bucket 是开始的 bucket 并且已经遍历过了
if bucket == it.startBucket && it.wrapped {
// end of iteration
it.key = nil
it.elem = nil
return
}
// 如果迭代器是在增长过程中启动的,尚未完成增长。
// 并且要查看的存储桶尚未装满(即尚未撤离旧存储桶),
// 则需要遍历旧存储桶,仅返回将要迁移到该存储桶的旧存储桶的值。
// 也就是像上面的例子,仅仅只能取出老 1 号 bucket 中那些在裂变之后,分配到新 1 号 bucket 中的那些 key。
if h.growing() && it.B == h.B {
// 按位与操作,根据 bucket 新增位是 1 还是 0 判断分配到哪里,
// 0 的是需要遍历的(见扩容原理)
oldbucket := bucket & it.h.oldbucketmask()
b = (*bmap)(add(h.oldbuckets, oldbucket*uintptr(t.bucketsize)))
// 判断当前 bucket 是否已经搬迁了
if !evacuated(b) {
// 如果还没有完成搬迁,则当前 bucket 不需要遍历,后面会跳到 oldbucket 中遍历
checkBucket = bucket
} else {
// 还没后完成搬迁,则当前 bucket 不需要遍历
b = (*bmap)(add(it.buckets, bucket*uintptr(t.bucketsize)))
checkBucket = noCheck
}
} else {
// 正常情况,没有发生扩容时的遍历
b = (*bmap)(add(it.buckets, bucket*uintptr(t.bucketsize)))
checkBucket = noCheck
}
bucket++
// 到了顺序上的最后一个 bucket,置 0 继续遍历
if bucket == bucketShift(it.B) {
bucket = 0
it.wrapped = true
}
i = 0
}
// 遍历当前 bucket 的 cell
for ; i < bucketCnt; i++ {
offi := (i + it.offset) & (bucketCnt - 1)
//
if isEmpty(b.tophash[offi]) || b.tophash[offi] == evacuatedEmpty {
// TODO: emptyRest is hard to use here, as we start iterating
// in the middle of a bucket. It's feasible, just tricky.
// 当前的 cell 状态是 emptyRest, emptyOne(空), evacuatedEmpty(迁移前是emptyRest, emptyOne)
continue
}
// 获取 k,e 分别对应 key 和 value 的内存地址
k := add(unsafe.Pointer(b), dataOffset+uintptr(offi)*uintptr(t.keysize))
if t.indirectkey() {
k = *((*unsafe.Pointer)(k))
}
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+uintptr(offi)*uintptr(t.elemsize))
// 去掉需要忽略的特殊情况,也就是增量扩容的情况
if checkBucket != noCheck && !h.sameSizeGrow() {
// 特殊情况:需要遍历 oldbucket 的场景
// 遍历 oldbucket,跳过将要转到另一个新 bucket 的任何键(在增长过程中,每个 oldbucket 会扩展到两个 bucket 中)。
// reflexivekey() // true if k==k for all keys
if t.reflexivekey() || t.key.equal(k, k) {
// 如果 oldbucket 中的 cell 不是搬移到迭代中的当前新存储桶的, 则将其跳过.
hash := t.hasher(k, uintptr(h.hash0))
if hash&bucketMask(it.B) != checkBucket {
continue
}
} else {
// 如果 k!= k(也就是 key 值是 NaNs 的特殊情况), 则 hash 不可重复. 这里需要对迁移期间发送 NaN 的方向进行可重复且随机的选择.
// 这里将使用低位的 tophash 来决定 NaN 的走法.
// 注意: 这种情况就是为什么我们需要两个迁移值, 即 evacuatedX 和 evacuatedY, 它们的低位不同.
if checkBucket>>(it.B-1) != uintptr(b.tophash[offi]&1) {
continue
}
}
}
// 遍历, 获取对应的 k, v
if (b.tophash[offi] != evacuatedX && b.tophash[offi] != evacuatedY) ||
!(t.reflexivekey() || t.key.equal(k, k)) {
// 特殊情况:
// 在正常状况(没有发生map扩容[增量方式])下进行遍历也称为 golden data;
// 或者
// key != key (只能发生 key=NANs 的状况下), 这些 key 是没法更新和删除的, 只能在遍历的时候返回。
it.key = k
if t.indirectelem() {
e = *((*unsafe.Pointer)(e))
}
it.elem = e
} else {
// 自从启动迭代器以来,哈希表已经增长。这个 key 的 value 现在位于其他位置。
// 检查当前哈希表中的数据。
// 此代码处理 key 已被删除,更新,删除或重新插入的情况。
// 注意:这里需要重新注册 key ,因为它可能已更新为 equal()相同但不相同的 key(例如+0.0与-0.0)。
rk, re := mapaccessK(t, h, k)
if rk == nil {
// key 已经被删除
continue
}
it.key = rk
it.elem = re
}
// 后续处理
it.bucket = bucket
if it.bptr != b { // avoid unnecessary write barrier; see issue 14921
it.bptr = b
}
it.i = i + 1
it.checkBucket = checkBucket
return
}
b = b.overflow(t)
i = 0
goto next
}
在上面的遍历过程中有一个特殊情况,如果碰到 key 是 math.NaN() 这种的,处理方式要看它被分裂后具体落入哪个 bucket。只不过只用看它 tophash 的最低位。如果 tophash 的最低位是 0 ,分配到 X part;如果是 1 ,则分配到 Y part。据此决定是否取出 key,放到遍历结果集里。
map 遍历的核心在于理解 2 倍扩容时,老 bucket 会分裂到 2 个新 bucket 中去。而遍历操作,会按照新 bucket 的序号顺序进行,碰到老 bucket 未搬迁的情况时,要在老 bucket 中找到将来要搬迁到新 bucket 来的 key。也就是上面说的当发生了增量扩容时,一个老的 bucket 数据可能会分裂到两个不同的 bucket 中去,那么此时,如果需要从老的 bucket 中遍历数据,例如 1 号,则不能将老 1 号 bucket 中的数据全部取出,仅仅只能取出老 1 号 bucket 中那些在裂变之后,分配到新 1 号 bucket 中的那些 key。
总结
以上就是 Map 的相关实现原理,可以看到,它并不是一个并发安全的数据结构。同时对 map 进行读写时,程序很容易出错。因此,要想在并发情况下使用 map,可以加上锁(sync.Mutex 或者 sync.RwMutex)。其实,Go 标准库中已经实现了并发安全的 map——sync.Map。
遍历 map 的结果是无序的,在使用中,应该注意到该点。
通过 map 的结构体可以知道,它其实是通过指针指向底层 buckets 数组。所以和 slice 一样,尽管 go 函数都是值传递,但是,当 map 作为参数被函数调用时,在函数内部对 map 的操作同样会影响到外部的map。
另外,有个特殊的 key 值 math.NaN,它每次生成的哈希值是不一样的,这会造成 m[math.NaN] 是拿不到值的,而且多次对它赋值,会让 map 中存在多个 math.NaN 的 key。
函数调用
Go 语言使用栈传递参数和接收返回值,所以它只需要在栈上多分配一些内存就可以返回多个值。
对于下面的例子:
package main
func myFunction(a, b int) (int, int) {
return a + b, a - b
}
func main() {
myFunction(66, 77)
}
main 函数在调用 myFunction 之前会先通过汇编指令 SUBQ $40, SP 指令在栈上分配了 40 字节的内存空间,分配如下的栈结构:

相应的大小和用途如下:
| 空间 | 大小 | 作用 |
|---|---|---|
| SP+32 ~ BP | 8 字节 | main 函数的栈基址指针 |
| SP+16 ~ SP+32 | 16 字节 | 函数 myFunction 的两个返回值 |
| SP ~ SP+16 | 16 字节 | 函数 myFunction 的两个参数 |
当入参时,入参的压栈顺序和 C 语言一样,都是从右到左,即第一个参数 66 在栈顶的 SP ~ SP+8,第二个参数存储在 SP+8 ~ SP+16 的空间中。
当准备好函数的入参之后,会调用汇编指令 CALL "".myFunction(SB),这个指令首先会将 main 的返回地址存入栈中,然后改变当前的栈指针 SP 并执行 myFunction 的汇编指令。
muFunction 函数在执行时首先会将 main 函数中预留的两个返回值地址置成 int 类型的默认值 0,然后根据栈的相对位置获取参数并进行加减操作并将值存回栈中,在 myFunction 函数返回之间,栈中的数据如下图所示:

图 4-3 myFunction 函数返回前的栈
在 myFunction 返回后,main 函数会恢复栈基址指针并销毁已经失去作用的 40 字节栈内存。
跟 C 语言对比
C 语言和 Go 语言在设计函数的调用惯例时选择了不同的实现。C 语言同时使用寄存器和栈传递参数,使用 eax 寄存器传递返回值;而 Go 语言使用栈传递参数和返回值。这两种设计的优点和缺点如下:
- C 语言的方式能够极大地减少函数调用的额外开销,但是也增加了实现的复杂度;
- CPU 访问栈的开销比访问寄存器高几十倍;
- 需要单独处理函数参数过多的情况;
- Go 语言的方式能够降低实现的复杂度并支持多返回值,但是牺牲了函数调用的性能;
- 不需要考虑超过寄存器数量的参数应该如何传递;
- 不需要考虑不同架构上的寄存器差异;
- 函数入参和出参的内存空间需要在栈上进行分配;
Go 语言使用栈作为参数和返回值传递的方法是综合考虑后的设计,选择这种设计意味着编译器会更加简单、更容易维护。
参数传递
Go 语言选择了传值的方式,无论是传递基本类型、结构体还是指针,都会对传递的参数进行拷贝。
整型和数组
如下所示的函数 myFunction 接收了两个参数,整型变量 i 和数组 arr,这个函数会将传入的两个参数的地址打印出来,在最外层的主函数也会在 myFunction 函数调用前后分别打印两个参数的地址:
func myFunction(i int, arr [2]int) {
fmt.Printf("in my_funciton - i=(%d, %p) arr=(%v, %p)\n", i, &i, arr, &arr)
}
func main() {
i := 30
arr := [2]int{66, 77}
fmt.Printf("before calling - i=(%d, %p) arr=(%v, %p)\n", i, &i, arr, &arr)
myFunction(i, arr)
fmt.Printf("after calling - i=(%d, %p) arr=(%v, %p)\n", i, &i, arr, &arr)
}
$ go run main.go
before calling - i=(30, 0xc0000b2008) arr=([66 77], 0xc0000b2010)
in my_funciton - i=(30, 0xc0000b2028) arr=([66 77], 0xc0000b2040)
after calling - i=(30, 0xc0000b2008) arr=([66 77], 0xc0000b2010)
当通过命令运行这段代码时会发现,main 函数和被调用者 myFunction 中参数的地址是完全不同的。
不过从 main 函数的角度来看,在调用 myFunction 前后,整数 i 和数组 arr 两个参数的地址都没有变化。
如果在 myFunction 函数内部对参数进行修改是否会影响 main 函数中的变量呢?这里更新 myFunction 函数并重新执行这段代码:
func myFunction(i int, arr [2]int) {
i = 29
arr[1] = 88
fmt.Printf("in my_funciton - i=(%d, %p) arr=(%v, %p)\n", i, &i, arr, &arr)
}
$ go run main.go
before calling - i=(30, 0xc00012a008) arr=([66 77], 0xc00012a010)
in my_funciton - i=(29, 0xc00012a028) arr=([66 88], 0xc00012a040)
after calling - i=(30, 0xc00012a008) arr=([66 77], 0xc00012a010)
可以看到在 myFunction 中对参数的修改也仅仅影响了当前函数,并没有影响调用方 main 函数,所以能得出如下结论:Go 语言的整型和数组类型都是值传递的,也就是在调用函数时会对内容进行拷贝。需要注意的是如果当前数组的大小非常的大,这种传值的方式会对性能造成比较大的影响。
结构体和指针
下面这段代码中定义了一个结构体 MyStruct 以及接受两个参数的 myFunction 方法:
type MyStruct struct {
i int
}
func myFunction(a MyStruct, b *MyStruct) {
a.i = 31
b.i = 41
fmt.Printf("in my_function - a=(%d, %p) b=(%v, %p)\n", a, &a, b, &b)
}
func main() {
a := MyStruct{i: 30}
b := &MyStruct{i: 40}
fmt.Printf("before calling - a=(%d, %p) b=(%v, %p)\n", a, &a, b, &b)
myFunction(a, b)
fmt.Printf("after calling - a=(%d, %p) b=(%v, %p)\n", a, &a, b, &b)
}
$ go run main.go
before calling - a=({30}, 0xc0000b2008) b=(&{40}, 0xc0000ac018)
in my_function - a=({31}, 0xc0000b2028) b=(&{41}, 0xc0000ac028)
after calling - a=({30}, 0xc0000b2008) b=(&{41}, 0xc0000ac018)
从上述运行的结果可以得出如下结论:
- 传递结构体时:会拷贝结构体中的全部内容;
- 传递结构体指针时:会拷贝结构体指针;
修改结构体指针是改变了指针指向的结构体,b.i 可以被理解成 (*b).i,也就是先获取指针 b 背后的结构体,再修改结构体的成员变量。
简单修改上述代码,分析一下 Go 语言结构体在内存中的布局:
type MyStruct struct {
i int
j int
}
func myFunction(ms *MyStruct) {
ptr := unsafe.Pointer(ms)
for i := 0; i < 2; i++ {
c := (*int)(unsafe.Pointer((uintptr(ptr) + uintptr(8*i))))
*c += i + 1
fmt.Printf("[%p] %d\n", c, *c)
}
}
func main() {
a := &MyStruct{i: 40, j: 50}
myFunction(a)
fmt.Printf("[%p] %v\n", a, a)
}
$ go run main.go
[0xc000134010] 41
[0xc000134018] 52
[0xc000134010] &{41 52}
在这段代码中,通过指针修改结构体中的成员变量,结构体在内存中是一片连续的空间,指向结构体的指针也是指向这个结构体的首地址。将 MyStruct 指针修改成 int 类型的,那么访问新指针就会返回整型变量 i,将指针移动 8 个字节之后就能获取下一个成员变量 j。
如果将上述代码简化成如下所示的代码片段并使用 go tool compile 进行编译会得到如下的结果:
type MyStruct struct {
i int
j int
}
func myFunction(ms *MyStruct) *MyStruct {
return ms
}
$ go tool compile -S -N -l main.go
"".myFunction STEXT nosplit size=20 args=0x10 locals=0x0
0x0000 00000 (main.go:8) MOVQ $0, "".~r1+16(SP) // 初始化返回值
0x0009 00009 (main.go:9) MOVQ "".ms+8(SP), AX // 复制引用
0x000e 00014 (main.go:9) MOVQ AX, "".~r1+16(SP) // 返回引用
0x0013 00019 (main.go:9) RET
在这段汇编语言中,当参数是指针时,也会使用 MOVQ "".ms+8(SP), AX 指令复制引用,然后将复制后的指针作为返回值传递回调用方。根据上面函数调用的原理,可以知道此时栈内的结构如下:
所以将指针作为参数传入某个函数时,函数内部会复制指针,也就是会同时出现两个指针指向原有的内存空间,所以 Go 语言中传指针也是传值。
总结
Go 通过栈传递函数的参数和返回值,在调用函数之前会在栈上为返回值分配合适的内存空间,随后将入参从右到左按顺序压栈并拷贝参数,返回值会被存储到调用方预留好的栈空间上,可以简单总结出以下几条规则:
- 通过堆栈传递参数,入栈的顺序是从右到左,而参数的计算是从左到右;
- 函数返回值通过堆栈传递并由调用者预先分配内存空间;
- 调用函数时都是传值,接收方会对入参进行复制再计算;
需要注意,在传递数组或者内存占用非常大的结构体时,应该尽量使用指针作为参数类型来避免发生数据拷贝进而影响性能。
接口
Go 语言中接口的实现都是隐式的,只需要实现接口中的方法就相当于实现了接口。Go 语言只会在传递参数、返回参数以及变量赋值时才会对某个类型是否实现接口进行检查。例如有以下代码:
type error interface {
Error() string
}
type RPCError struct {
Code int64
Message string
}
// *RPCError 实现了 error 接口
func (e *RPCError) Error() string {
return fmt.Sprintf("%s, code=%d", e.Message, e.Code)
}
func main() {
var rpcErr error = NewRPCError(400, "unknown err") // 赋值进行类型检查1
err := AsErr(rpcErr) // 传参进行类型检查
println(err)
}
func NewRPCError(code int64, msg string) error {
return &RPCError{ // 参数返回类型检查
Code: code,
Message: msg,
}
}
func AsErr(err error) error {
return err
}
Go 语言在编译期间会对代码进行类型检查,上面的代码总共触发了三次类型检查:
- 将
*RPCError类型的变量赋值给error类型的变量rpcErr; - 将
*RPCError类型的变量rpcErr传递给签名中参数类型为error的AsErr函数; - 将
*RPCError类型的变量从函数签名的返回值类型为error的NewRPCError函数中返回;
从类型检查的过程来看,编译器仅在需要时才检查类型,类型实现接口时只需要实现接口中的全部方法,不需要像 Java 等编程语言中一样显式声明。
类型
接口也是 Go 语言中的一种类型,它能够出现在变量的定义、函数的入参和返回值中并对它们进行约束,不过 Go 语言中有两种略微不同的接口,一种是带有一组方法的接口,另一种是不带任何方法的 interface{}:
Go 语言使用 runtime.iface 表示第一种接口,使用 runtime.eface 表示第二种不包含任何方法的接口 interface{},两种接口虽然都使用 interface 声明,但是由于后者在 Go 语言中很常见,所以在实现时使用了特殊的类型。
需要注意的是,与 C 语言中的 void * 不同,interface{} 类型不是任意类型。如果将类型转换成了 interface{} 类型,变量在运行期间的类型也会发生变化,获取变量类型时会得到 interface{}。
package main
func main() {
type Test struct{}
v := Test{}
Print(v)
}
func Print(v interface{}) {
println(v)
}
上面 Print 函数不接受任意类型的参数,只接受 interface{} 类型的值,在调用 Print 函数时会对参数 v 进行类型转换,将原来的 Test 类型转换成 interface{} 类型。
指针和接口
下面的代码总结了如何使用结构体、结构体指针实现接口,以及如何使用结构体、结构体指针初始化变量。
type Cat struct {}
type Duck interface { ... }
func (c Cat) Quack {} // 使用结构体实现接口
func (c *Cat) Quack {} // 使用结构体指针实现接口
var d Duck = Cat{} // 使用结构体初始化变量
var d Duck = &Cat{} // 使用结构体指针初始化变量
实现接口的类型和初始化返回的类型两个维度共组成了四种情况,然而这四种情况不是都能通过编译器的检查:
| 结构体实现接口 | 结构体指针实现接口 | |
|---|---|---|
| 结构体初始化变量 | 通过 | 不通过 |
| 结构体指针初始化变量 | 通过 | 通过 |
四种中只有使用指针实现接口,使用结构体初始化变量无法通过编译,其他的三种情况都可以正常执行。
也就是说,实现了接收者是值类型的方法,相当于自动实现了接收者是指针类型的方法;而实现了接收者是指针类型的方法,不会自动生成对应接收者是值类型的方法
对于方法的接受者是结构体,而初始化的变量是结构体指针:
type Cat struct{}
func (c Cat) Quack() {
fmt.Println("meow")
}
func main() {
var c Duck = &Cat{}
c.Quack()
}
作为指针的 &Cat{} 变量能够隐式地获取到指向的结构体,所以能在结构体上调用 Walk 和 Quack 方法。表面上看,*Cat 类型并没有实现 Quack 方法,但是因为 Cat 类型实现了 Quack 方法,所以让 *Cat 类型自动拥有了 Quack 方法。
但是如果将上述代码中方法的接受者和初始化的类型进行交换,代码就无法通过编译了:
type Duck interface {
Quack()
}
type Cat struct{}
func (c *Cat) Quack() {
fmt.Println("meow")
}
func main() {
var c Duck = Cat{}
c.Quack()
}
$ go build interface.go
./interface.go:20:6: cannot use Cat literal (type Cat) as type Duck in assignment:
Cat does not implement Duck (Quack method has pointer receiver)
编译器会提醒:Cat 类型没有实现 Duck 接口,Quack 方法的接受者是指针。
原因在于,Go 语言在传递参数时都是传值的:
如上图所示,无论上述代码中初始化的变量 c 是 Cat{} 还是 &Cat{},使用 c.Quack() 调用方法时都会发生值拷贝:
- 如上图左侧,对于
&Cat{}来说,这意味着拷贝一个新的&Cat{}指针,这个指针与原来的指针指向一个相同并且唯一的结构体,所以编译器可以隐式的对变量解引用(dereference)获取指针指向的结构体; - 如上图右侧,对于
Cat{}来说,这意味着Quack方法会接受一个全新的Cat{},因为方法的参数是Cat,编译器不会无中生有创建一个新的指针;即使编译器可以创建新指针,这个指针指向的也不是最初调用该方法的结构体;
从设计上来说,接收者是指针类型的方法,很可能在方法中会对接收者的属性进行更改操作,从而影响接收者;而对于接收者是值类型的方法,在方法中不会对接收者本身产生影响。所以,当实现了一个接收者是值类型的方法,就可以自动生成一个接收者是对应指针类型的方法,因为两者都不会影响接收者。但是,当实现了一个接收者是指针类型的方法,如果此时自动生成一个接收者是值类型的方法,原本期望对接收者的改变(通过指针实现),现在无法实现,因为值类型会产生一个拷贝,不会真正影响调用者。
因此,当使用指针实现接口时,只有指针类型的变量才会实现该接口;当使用结构体实现接口时,指针类型和结构体类型都会实现该接口。
值接收者和指针接收者应用场景
如果方法的接收者是值类型,无论调用者是对象还是对象指针,修改的都是对象的副本,不影响调用者;如果方法的接收者是指针类型,则调用者修改的是指针指向的对象本身。
使用指针作为方法的接收者的理由:
方法能够修改接收者指向的值。
避免在每次调用方法时复制该值,在值的类型为大型结构体时,这样做会更加高效。
但是是使用值接收者还是指针接收者,不是由该方法是否修改了调用者(也就是接收者)来决定,而是应该基于该类型的本质。
如果类型具备“原始的本质”,也就是说它的成员都是由 Go 语言里内置的原始类型,如字符串,整型值等,那就定义值接收者类型的方法。像内置的引用类型,如 slice,map,interface,channel,这些类型比较特殊,声明他们的时候,实际上是创建了一个 header, 对于他们也是直接定义值接收者类型的方法。这样,调用函数时,是直接 copy 了这些类型的 header,而 header 本身就是为复制设计的。
Go 语言里的引用类型有如下几个:切片、映射、通道、接口和函数类型。当声明上述类型的变量时,创建的变量被称作标头(header)值。从技术细节上说,字符串也是一种引用类型。
每个引用类型创建的标头值是包含一个指向底层数据结构的指针。每个引用类型还包含一组独特的字段,用于管理底层数据结构。因为标头值是为复制而设计的,所以永远不需要共享一个引用类型的值。标头值里包含一个指针,因此通过复制来传递一个引用类型的值的副本,本质上就是在共享底层数据结构。
如果类型具备非原始的本质,不能被安全地复制,这种类型总是应该被共享,那就定义指针接收者的方法。比如 go 源码里的文件结构体(struct File)就不应该被复制,应该只有一份实体。
接口的数据结构
Go 语言根据接口类型是否包含一组方法将接口类型分成了两类:
- 使用
runtime.iface结构体表示包含方法的接口 - 使用
runtime.eface结构体表示不包含任何方法的interface{}类型;
eface 结构
runtime.eface 结构体在 Go 语言中的定义是这样的:
type eface struct { // 16 字节
_type *_type
data unsafe.Pointer
}
由于 interface{} 类型不包含任何方法,所以它的结构也相对来说比较简单,只包含指向底层数据和类型的两个指针:维护了一个 _type 字段,表示空接口所承载的具体的实体类型;data 描述了具体的值。
从上述结构也能推断出:Go 语言的任意类型都可以转换成 interface{}。
iface 结构
另一个用于表示接口的结构体是 runtime.iface:
type iface struct { // 16 字节
tab *itab
data unsafe.Pointer
}
iface 内部维护两个指针,tab 指向一个 itab 实体, 它表示接口的类型以及赋给这个接口的实体类型。data 则指向接口具体的值,一般而言是一个指向堆内存的指针。
itab 结构体
runtime.itab 结构体是接口类型的核心组成部分,每一个 runtime.itab 都占 32 字节,可以将其看成接口类型和具体类型的组合,它们分别用 inter 和 _type 两个字段表示:
type itab struct { // 32 字节
inter *interfacetype
_type *_type
hash uint32
_ [4]byte
fun [1]uintptr
}
inter字段则描述了接口的类型_type字段描述了实体的具体类型hash是对_type.hash的拷贝,当想将interface类型转换成具体类型时,可以使用该字段快速判断目标类型和具体类型runtime._type是否一致;fun是一个动态大小的数组,用于放置和接口方法对应的具体数据类型的方法地址。它是一个用于动态派发的虚函数表,存储了一组函数指针。一般在每次给接口赋值发生转换时会更新此表,或者直接拿缓存的 itab。另外,数组大小虽然是 1,但是这里存储的是第一个方法的函数指针,如果有更多的方法,在它之后的内存空间里继续存储。从汇编角度来看,通过增加地址就能获取到这些函数指针,没什么影响。所以虽然该变量被声明成大小固定的数组,但是在使用时会通过原始指针获取其中的数据,所以
fun数组中保存的元素数量是不确定的。顺便提一句,这些方法是按照函数名称的字典序进行排列的。
interfacetype
interfacetype 描述的是接口的类型,它的实现如下:
type interfacetype struct {
typ _type
pkgpath name
mhdr []imethod
}
它包装了 _type 类型,_type 实际上是描述 Go 语言中各种数据类型的结构体。这里需要注意到,这里还包含一个 mhdr 字段,表示接口所定义的函数列表, pkgpath 记录定义了接口的包名。
_type
runtime._type 是 Go 语言类型的运行时表示。它描述了实体的类型,包括内存对齐方式,大小等。下面是运行时包中的结构体,其中包含了很多类型的元信息,例如:类型的大小、哈希、对齐以及种类等。
注意这里的 hash 值是根据类型、方法生成的,与 data 内容无关
type _type struct {
// 存储了类型占用的内存空间,为内存空间的分配提供信息
size uintptr
ptrdata uintptr
// 类型的 hash 值,能够快速确定类型是否相等
hash uint32
// 类型的 flag,和反射相关
tflag tflag
// 内存对齐相关
align uint8
fieldAlign uint8
// 类型的编号,有 bool, slice, struct 等等等等
kind uint8
// 用于判断当前类型的多个对象是否相等,
// 该字段是为了减少 Go 语言二进制包大小从 `typeAlg` 结构体中迁移过来的
equal func(unsafe.Pointer, unsafe.Pointer) bool
// gc 相关
gcdata *byte
str nameOff
ptrToThis typeOff
}
Go 语言各种数据类型都是在 _type 字段的基础上,增加一些额外的字段来进行管理的:
type arraytype struct {
typ _type
elem *_type
slice *_type
len uintptr
}
type chantype struct {
typ _type
elem *_type
dir uintptr
}
type slicetype struct {
typ _type
elem *_type
}
type structtype struct {
typ _type
pkgPath name
fields []structfield
}
这些数据类型的结构体定义,是反射实现的基础。
整体来说,iface 的结构如下:
接口的动态类型和动态值
从上面的数据结构可以看到,iface包含两个字段:tab 是接口表指针,指向类型信息;data 是数据指针,则指向具体的数据。它们分别被称为动态类型和动态值。而接口值包括动态类型和动态值。
接口值的零值是指动态类型和动态值都为 nil。当仅且当这两部分的值都为 nil 的情况下,这个接口值就才会被认为 接口值 == nil。
例如下面的例子:
type Coder interface {
code()
}
type Gopher struct {
name string
}
func (g Gopher) code() {
fmt.Printf("%s is coding\n", g.name)
}
func main() {
var c Coder
fmt.Println(c == nil)
fmt.Printf("c: %T, %v\n", c, c)
var g *Gopher
fmt.Println(g == nil)
c = g
fmt.Println(c == nil)
fmt.Printf("c: %T, %v\n", c, c)
}
输出:
true
c: <nil>, <nil>
true
false
c: *main.Gopher, <nil>
一开始,c 的动态类型和动态值都为 nil,g 也为 nil,当把 g 赋值给 c 后,c 的动态类型变成了 *main.Gopher,仅管 c 的动态值仍为 nil,但是当 c 和 nil 作比较的时候,结果就是 false 了。
再看一个例子:
package main
type TestStruct struct{}
func NilOrNot(v interface{}) bool {
return v == nil
}
func main() {
var s *TestStruct
fmt.Println(s == nil) // #=> true
fmt.Println(NilOrNot(s)) // #=> false
}
$ go run main.go
true
false
简单总结一下上述代码执行的结果:
- 将上述变量与
nil比较会返回true; - 将上述变量传入
NilOrNot方法并与nil比较会返回false;
出现上述现象的原因是: 调用 NilOrNot 函数时发生了隐式的类型转换,除了向方法传入参数之外,变量的赋值也会触发隐式类型转换。在类型转换时,TestStruct 类型会转换成 interface{} 类型,转换后的变量不仅包含转换前的变量,还包含变量的类型信息 TestStruct,所以转换后的变量与 nil 不相等。
编译器自动检测类型是否实现接口
经常看到一些开源库里会有一些类似下面这种奇怪的用法:
var _ io.Writer = (*myWriter)(nil)
这种做法是为了让编译器由此检查 myWriter 类型是否实现了 io.Writer 接口。
下面有个例子:
package main
import "io"
type myWriter struct {
}
/*func (w myWriter) Write(p []byte) (n int, err error) {
return
}*/
func main() {
// 检查 *myWriter 类型是否实现了 io.Writer 接口
var _ io.Writer = (*myWriter)(nil)
// 检查 myWriter 类型是否实现了 io.Writer 接口
var _ io.Writer = myWriter{}
}
注释掉为 myWriter 定义的 Write 函数后,运行程序:
src/main.go:14:6: cannot use (*myWriter)(nil) (type *myWriter) as type io.Writer in assignment:
*myWriter does not implement io.Writer (missing Write method)
src/main.go:15:6: cannot use myWriter literal (type myWriter) as type io.Writer in assignment:
myWriter does not implement io.Writer (missing Write method)
报错信息:*myWriter/myWriter 未实现 io.Writer 接口,也就是未实现 Write 方法。
解除注释后,运行程序不报错。
实际上,上述赋值语句会发生隐式地类型转换,在转换的过程中,编译器会检测等号右边的类型是否实现了等号左边接口所规定的函数。
总结一下,可通过在代码中添加类似如下的代码,用来检测类型是否实现了接口:
var _ io.Writer = (*myWriter)(nil)
var _ io.Writer = myWriter{}
反射
Go 语言提供了一种机制在运行时更新变量和检查它们的值、调用它们的方法,但是在编译时并不知道这些变量的具体类型,这称为反射机制。
反射的作用
需要反射的 2 个常见场景:
- 有时需要编写一个函数,但是并不知道传给函数的参数类型是什么,可能是没约定好;也可能是传入的类型很多,这些类型并不能统一表示。这时反射就会用的上了。
- 有时候需要根据某些条件决定调用哪个函数,比如根据用户的输入来决定。这时就需要对函数和函数的参数进行反射,在运行期间动态地执行函数。
但是使用反射也存在一定的风险:
- 与反射相关的代码,经常是难以阅读的。在软件工程中,代码可读性也是一个非常重要的指标。
- Go 语言作为一门静态语言,编码过程中,编译器能提前发现一些类型错误,但是对于反射代码是无能为力的。所以包含反射相关的代码,很可能会运行很久,才会出错,这时候经常是直接 panic,可能会造成严重的后果。
- 反射对性能影响还是比较大的,比正常代码运行速度慢一到两个数量级。所以,对于一个项目中处于运行效率关键位置的代码,尽量避免使用反射特性。
反射的三大法则
运行时反射是程序在运行期间检查其自身结构的一种方式。反射带来的灵活性是一把双刃剑,反射作为一种元编程方式可以减少重复代码,但是过量的使用反射会使程序逻辑变得难以理解并且运行缓慢。在 Go 官方关于反射的博客中提到,反射有三大定律:
从
interface{}变量可以反射出反射对象;从反射对象可以获取
interface{}变量;要修改反射对象,其值必须可设置;
第一法则
反射是一种检测存储在 interface 中的类型和值机制。这可以通过 TypeOf 函数和 ValueOf 函数得到。
反射的第一法则是能将 Go 语言的 interface{} 变量转换成反射对象。这里之所以说是 interface ,是因为当执行如 reflect.ValueOf(1) 时,虽然看起来是获取了基本类型 int 对应的反射类型,但是**由于 reflect.TypeOf、reflect.ValueOf 两个方法的入参都是 interface{} 类型,所以在方法执行的过程中发生了类型转换。**所以实际上都是从 interface{} 中反射对象。
因为Go 语言的函数调用都是值传递的,所以变量会在函数调用时进行类型转换。基本类型 int 会转换成 interface{} 类型,这也就是为什么第一条法则是从接口到反射对象。
上面提到的 reflect.TypeOf 和 reflect.ValueOf 函数就能完成这里的转换,如果认为 Go 语言的类型和反射类型处于两个不同的世界,那么这两个函数就是连接这两个世界的桥梁。
第二法则
第二条实际上和第一条是相反的机制,它将 ValueOf 的返回值通过 Interface() 函数反向转变成 interface 变量。
反射的第二法则是可以从反射对象可以获取 interface{} 变量。既然能够将接口类型的变量转换成反射对象,那么一定需要其他方法将反射对象还原成接口类型的变量,reflect 中的 reflect.Value.Interface 就能完成这项工作。
不过调用 reflect.Value.Interface 方法只能获得 interface{} 类型的变量,如果想要将其还原成最原始的状态还需要经过如下所示的显式类型转换:
v := reflect.ValueOf(1)
v.Interface().(int)
第一第二法则就是说接口型变量和反射类型对象可以相互转化,反射类型对象实际上就是指的前面说的reflect.Type 和 reflect.Value。
第三法则
如果需要操作一个反射变量,那么它必须是可设置的。反射变量可设置的本质是它存储了原变量本身,这样对反射变量的操作,就会反映到原变量本身;反之,如果反射变量不能代表原变量,那么操作了反射变量,不会对原变量产生任何影响,所以第二种情况在语言层面是不被允许的。
举一个经典例子:
var x float64 = 3.4
v := reflect.ValueOf(x)
v.SetFloat(7.1) // Error: will panic.
执行上面的代码会产生 panic,原因是反射变量 v 不能代表 x 本身,因为调用 reflect.ValueOf(x) 这一行代码的时候,传入的参数在函数内部只是一个拷贝,是值传递,所以 v 代表的只是 x 的一个拷贝,因此对 v 进行操作是被禁止的。
可设置是反射变量 Value 的一个性质,但不是所有的 Value 都是可被设置的。
就像在一般的函数里那样,当想改变传入的变量时,使用指针就可以解决了。但是在反射中:
var x float64 = 3.4
p := reflect.ValueOf(&x)
fmt.Println("type of p:", p.Type())
fmt.Println("settability of p:", p.CanSet())
输出是这样的:
type of p: *float64
settability of p: false
也就是说即使使用指针,p 还不是代表 x,这只是 x 的指针,p.Elem() 才真正代表 x(相当于解引用),这样就可以真正操作 x 了:
v := p.Elem()
v.SetFloat(7.1)
fmt.Println(v.Interface()) // 7.1
fmt.Println(x) // 7.1
关于第三条,记住一句话:如果想要操作原变量,反射变量 Value 必须要 hold 住原变量的地址才行。
反射的实现
当向接口变量赋予一个实体类型的时候,接口会存储实体的类型信息,反射就是通过接口的类型信息实现的,反射建立在类型的基础上。
Go 语言在 reflect 包里定义了各种类型,实现了反射的各种函数,通过它们可以在运行时检测类型的信息、改变类型的值。
types 和 interface
Go 语言中,每个变量都有一个静态类型,也就是声明时候的类型。这是在编译阶段就确定了的,比如 int, float64, []int 等等。注意,这个类型是声明时候的类型,不是底层数据类型。
Go 官方博客里就举了一个例子:
type MyInt int
var i int
var j MyInt
尽管 i,j 的底层类型都是 int,但他们是不同的静态类型,除非进行类型转换,否则,i 和 j 不能同时出现在等号两侧。j 的静态类型就是 MyInt。
反射主要与 interface{} 类型相关。上面的接口一节已经列出了 interface 的底层结构,即 iface 和 eface 。
iface 描述的是非空接口,它包含方法;
type iface struct {
tab *itab
data unsafe.Pointer
}
type itab struct {
inter *interfacetype
_type *_type
link *itab
hash uint32
bad bool
inhash bool
unused [2]byte
fun [1]uintptr
}
其中 itab 由具体类型 _type 以及 interfacetype 组成。_type 表示具体类型,而 interfacetype 则表示具体类型实现的接口类型。
与之相对的是 eface,描述的是空接口,不包含任何方法,Go 语言里有的类型都实现了空接口。
type eface struct {
_type *_type
data unsafe.Pointer
}
它只维护了一个 _type 字段,表示空接口所承载的具体的实体类型。data 描述了具体的值。
需要明确的一点:接口变量可以存储任何实现了接口定义的所有方法的变量。
Go 语言中最常见的就是 Reader 和 Writer 接口:
type Reader interface {
Read(p []byte) (n int, err error)
}
type Writer interface {
Write(p []byte) (n int, err error)
}
接下来,就是接口之间的各种转换和赋值了:
var r io.Reader
tty, err := os.OpenFile("/Users/silverming/test", os.O_RDWR, 0)
if err != nil {
return nil, err
}
r = tty
首先声明 r 的类型是 io.Reader,注意,这是 r 的静态类型,此时它的动态类型为 nil,并且它的动态值也是 nil。
之后,r = tty 这一语句,将 r 的动态类型变成 *os.File,动态值则变成非空,表示打开的文件对象。这时,r 可以用<value, type>对来表示为: <tty, *os.File>。
此时虽然 fun 所指向的函数只有一个 Read 函数,其实 *os.File 还包含 Write 函数,也就是说 *os.File 其实还实现了 io.Writer 接口。因此下面的断言语句可以执行:
var w io.Writer
w = r.(io.Writer)
之所以用断言,而不能直接赋值,是因为 r 的静态类型是 io.Reader,并没有实现 io.Writer 接口。断言能否成功,看 r 的动态类型是否符合要求。
这样,w 也可以表示成 <tty, *os.File>,仅管它和 r 一样,但是 w 可调用的函数取决于它的静态类型 io.Writer,也就是说它只能有这样的调用形式: w.Write() 。w 的内存形式如下图:
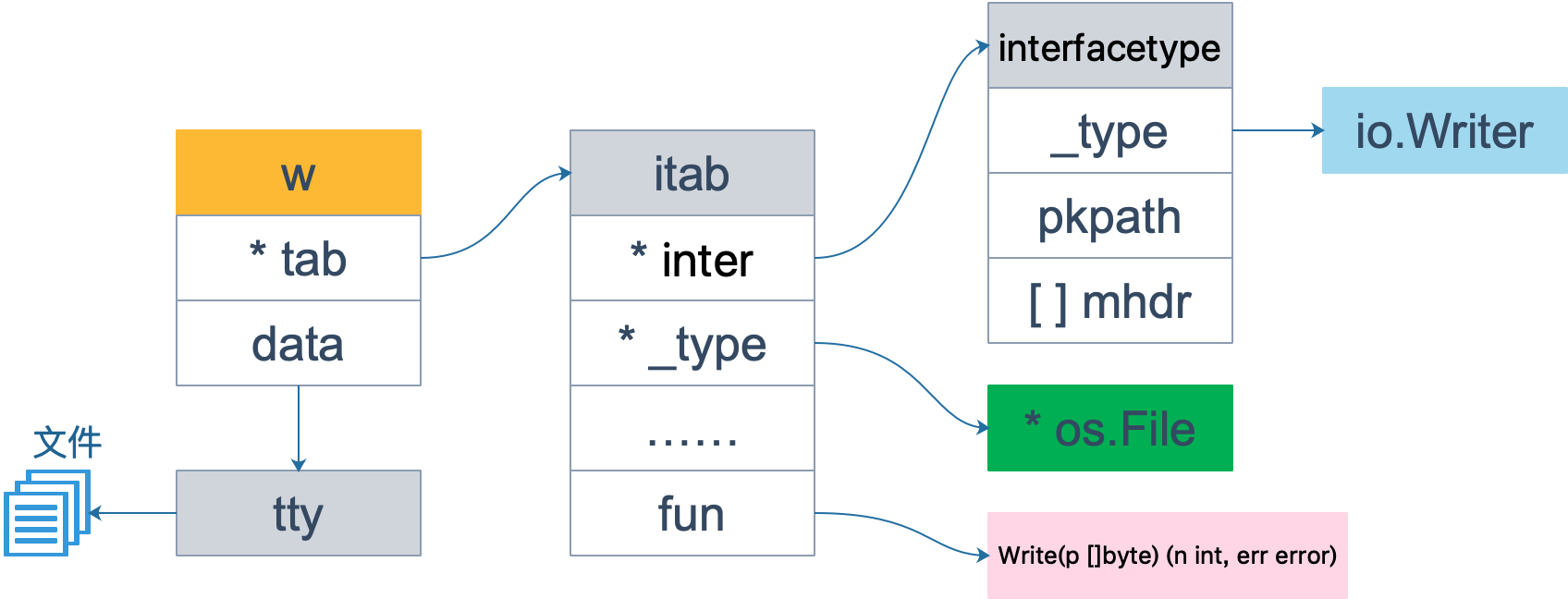
和 r 相比,仅仅是 fun 对应的函数变了:Read -> Write。
最后,再看一个赋值:
var empty interface{}
empty = w
由于 empty 是一个空接口,因此所有的类型都实现了它,w 可以直接赋给它,不需要执行断言操作。

从上面的三张图可以看到,interface 包含三部分信息:_type 是类型信息,*data 指向实际类型的实际值,itab 包含实际类型的信息,包括大小、包路径,还包含绑定在类型上的各种方法(图上没有画出方法)。
emptyInterface
Go 语言的 interface{} 类型在语言内部是通过 reflect.emptyInterface 结体表示的,其中的 rtype 字段用于表示变量的类型,另一个 word 字段指向内部封装的数据。
这里的 emptyInterface 和上面提到的 eface 其实是一回事(字段名略有差异,字段是相同的),且在不同的源码包:前者在 reflect 包,后者在 runtime 包。 eface.typ 就是动态类型。
type emptyInterface struct {
typ *rtype
word unsafe.Pointer
}
TypeOf 方法的实现原理
reflect 包里定义了一个接口和一个结构体,即 reflect.Type 和 reflect.Value,它们提供很多函数来获取存储在接口里的类型信息。
reflect.Type 主要提供关于类型相关的信息,所以它和 _type 关联比较紧密;reflect.Value 则结合 _type 和 data 两者,能获取数据的运行时表示,因此程序员可以获取甚至改变类型的值。
reflect 包中提供了两个基础的关于反射的函数来获取上述的接口和结构体:
func TypeOf(i interface{}) Type
func ValueOf(i interface{}) Value
TypeOf 函数用来提取一个接口中值的类型信息。由于它的输入参数是一个空的 interface{},看下源码:
func TypeOf(i interface{}) Type {
eface := *(*emptyInterface)(unsafe.Pointer(&i))
return toType(eface.typ)
}
调用此函数时,实参会先被转化为 interface{} 类型。这样,实参的类型信息、方法集、值信息都存储到 interface{} 变量里了。然后将传入的变量隐式转换成 reflect.emptyInterface 类型,并获取其中存储的类型信息 reflect.rtype。
至于 toType 函数,只是做了一个类型转换:
func toType(t *rtype) Type {
if t == nil {
return nil
}
return t
}
rtype
首先看看获取的 rtypr ,它和 _type 是一回事,而且源代码里也注释了:两边要保持同步:
// rtype must be kept in sync with ../runtime/type.go:/^type._type.
type rtype struct {
size uintptr
ptrdata uintptr // number of bytes in the type that can contain pointers
hash uint32 // hash of type; avoids computation in hash tables
tflag tflag // extra type information flags
align uint8 // alignment of variable with this type
fieldAlign uint8 // alignment of struct field with this type
kind uint8 // enumeration for C
// function for comparing objects of this type
// (ptr to object A, ptr to object B) -> ==?
equal func(unsafe.Pointer, unsafe.Pointer) bool
gcdata *byte // garbage collection data
str nameOff // string form
ptrToThis typeOff // type for pointer to this type, may be zero
}
reflect 包下所有的类型都会包含 rtype 这个字段,表示各种类型的公共信息;另外,不同类型包含自己的一些独特的部分。
比如下面的 arrayType 和 chanType 都包含 rytpe,而前者还包含 slice,len 等和数组相关的信息;后者则包含 dir 表示通道方向的信息:
// arrayType represents a fixed array type.
type arrayType struct {
rtype `reflect:"array"`
elem *rtype // array element type
slice *rtype // slice type
len uintptr
}
// chanType represents a channel type.
type chanType struct {
rtype `reflect:"chan"`
elem *rtype // channel element type
dir uintptr // channel direction (ChanDir)
}
Type 接口的方法
注意,TypeOf 函数的返回值 Type 实际上是一个接口,定义了很多方法,用来获取类型相关的各种信息,而上面的 *rtype 实现了 Type 接口。Type 接口有如下的方法:
type Type interface {
// 所有的类型都可以调用下面这些函数
// 此类型的变量对齐后所占用的字节数
Align() int
// 如果是 struct 的字段,对齐后占用的字节数
FieldAlign() int
// 方法返回类型的方法集中的第 i 个方法。
// 如果不在[0, NumMethod ())范围内,它会发生 panic。
//
// 对于非接口类型 T 或 *T,返回的 Method 的 Type 和 Func 字段描述了一个函数,
// 其第一个参数为接收方。
//
// 对于接口类型,返回的 Method 的 Type 字段给出方法签名,没有接收方,而 Func 字段为 nil。
//
// 仅可导出方法,并且它们按字典顺序排序
Method(int) Method
// MethodByName 返回在类型的方法集中具有该名称的方法和一个布尔值,指示是否找到该方法。
//
// 对于非接口类型 T 或 *T,返回的 Method 的 Type 和 Func 字段描述了一个函数,
// 其第一个参数为接收方。
//
// 对于接口类型,返回的 Method 的 Type 字段给出方法签名,没有接收方,而 Func 字段为 nil
MethodByName(string) (Method, bool)
// 获取类型方法集里导出的方法个数
NumMethod() int
// 类型名称
Name() string
// 返回类型所在的路径,如:encoding/base64
PkgPath() string
// 返回类型的大小,和 unsafe.Sizeof 功能类似
Size() uintptr
// 返回类型的字符串表示形式
String() string
// 返回类型的类型值
Kind() Kind
// 类型是否实现了接口 u
Implements(u Type) bool
// 是否可以赋值给 u
AssignableTo(u Type) bool
// 是否可以类型转换成 u
ConvertibleTo(u Type) bool
// 类型是否可以比较
Comparable() bool
// 下面的方法仅适用于某些特定类型,具体取决于种类。
// 每种类型允许使用的方法有:
// Int*, Uint*, Float*, Complex*: Bits
// Array: Elem, Len
// Chan: ChanDir, Elem
// Func: In, NumIn, Out, NumOut, IsVariadic.
// Map: Key, Elem
// Ptr: Elem
// Slice: Elem
// Struct: Field, FieldByIndex, FieldByName, FieldByNameFunc, NumField
// 类型所占据的位数
Bits() int
// 返回通道的方向,只能是 chan 类型调用,其他类型会 panic
ChanDir() ChanDir
// 返回类型是否是可变参数,只能是 func 类型调用
// 比如 t 是类型 func(x int, y ... float64)
// 那么 t.IsVariadic() == true
IsVariadic() bool
// 返回内部子元素类型,只能由类型 Array, Chan, Map, Ptr, or Slice 调用
Elem() Type
// 返回结构体类型的第 i 个字段,只能是结构体类型调用
// 如果 i 超过了总字段数,就会 panic
Field(i int) StructField
// 返回嵌套的结构体的字段,等效于为每个索引 i 依次调用 Field
FieldByIndex(index []int) StructField
// 通过字段名称获取字段
FieldByName(name string) (StructField, bool)
// FieldByNameFunc returns the struct field with a name
// 返回名称符合 func 函数的字段
FieldByNameFunc(match func(string) bool) (StructField, bool)
// 获取函数类型的第 i 个参数的类型
In(i int) Type
// 返回 map 的 key 类型,只能由类型 map 调用
Key() Type
// 返回 Array 的长度,只能由类型 Array 调用
Len() int
// 返回类型字段的数量,只能由类型 Struct 调用
NumField() int
// 返回函数类型的输入参数个数
NumIn() int
// 返回函数类型的返回值个数
NumOut() int
// 返回函数类型的第 i 个值的类型
Out(i int) Type
// 返回类型结构体的相同部分
common() *rtype
// 返回类型结构体的不同部分
uncommon() *uncommonType
}
Type 定义了非常多的方法,通过它们可以获取类型的一切信息。注意到,Type 接口实现了 String() 函数,满足 fmt.Stringer 接口,因此使用 fmt.Println 打印的时候,输出的是 String() 的结果。另外,fmt.Printf() 函数,如果使用 %T 来作为格式参数,输出的是 reflect.TypeOf 的结果,也就是打印参数的动态类型。
例如:
fmt.Printf("%T", 3) // int
ValueOf 实现原理
ValueOf 的实现源码如下:
func ValueOf(i interface{}) Value {
if i == nil {
return Value{}
}
// 保证当前值逃逸到堆上
escapes(i)
return unpackEface(i)
}
// 分解 eface
func unpackEface(i interface{}) Value {
e := (*emptyInterface)(unsafe.Pointer(&i))
t := e.typ
if t == nil {
return Value{}
}
f := flag(t.Kind())
if ifaceIndir(t) {
f |= flagIndir
}
return Value{t, e.word, f}
}
返回值 reflect.Value 表示 interface{} 里存储的实际变量,它能提供实际变量的各种信息。相关的方法常常是需要结合类型信息和值信息。例如,如果要提取一个结构体的字段信息,那就需要用到 _type (具体到这里是指 structType) 类型持有的关于结构体的字段信息、偏移信息,以及 *data 所指向的内容 —— 结构体的实际值。
从源码看,先将 i 转换成 *emptyInterface 类型, 再将它的 typ 字段和 word 字段以及一个标志位字段组装成一个 Value 结构体,而这就是 ValueOf 函数的返回值,它包含类型结构体指针、真实数据的地址、标志位。
Value 结构体定义了很多方法,通过这些方法可以直接操作 Value 字段 ptr 所指向的实际数据:
// 设置切片的 len 字段,如果类型不是切片,就会panic
func (v Value) SetLen(n int)
// 设置切片的 cap 字段
func (v Value) SetCap(n int)
// 设置字典的 kv
func (v Value) SetMapIndex(key, val Value)
// 返回切片、字符串、数组的索引 i 处的值
func (v Value) Index(i int) Value
// 根据名称获取结构体的内部字段值
func (v Value) FieldByName(name string) Value
// ……
Value 字段还有很多其他的方法。例如:
// 用来获取 int 类型的值
func (v Value) Int() int64
// 用来获取结构体字段(成员)数量
func (v Value) NumField() int
// 尝试向通道发送数据(不会阻塞)
func (v Value) TrySend(x reflect.Value) bool
// 通过参数列表 in 调用 v 值所代表的函数(或方法
func (v Value) Call(in []Value) (r []Value)
// 调用变参长度可变的函数
func (v Value) CallSlice(in []Value) []Value
另外,通过 Type() 方法和 Interface() 方法可以打通 interface、Type、Value 三者。Type() 方法也可以返回变量的类型信息,与 reflect.TypeOf() 函数等价。Interface() 方法可以将 Value 还原成原来的 interface。
总结一下:TypeOf() 函数返回一个接口,这个接口定义了一系列方法,利用这些方法可以获取关于类型的所有信息; ValueOf() 函数返回一个结构体变量,包含类型信息以及实际值。
reflect.Set的实现
当想要更新 reflect.Value 时,一般需要这样做:
func main() {
i := 2.33
v := reflect.ValueOf(&i)
v.Elem().SetFloat(6.66)
// value: 6.66
log.Println("value: ", i)
}
这里会需要调用 reflect.Value.Set 更新反射对象,该方法会调用 reflect.flag.mustBeAssignable 和 reflect.flag.mustBeExported 分别检查当前反射对象是否是可以被设置的以及字段是否是对外公开的:
func (v Value) Set(x Value) {
// 检查当前反射对象是否是可以被设置
v.mustBeAssignable()
// 检查 x 字段是否是对外公开
x.mustBeExported() // do not let unexported x leak
var target unsafe.Pointer
if v.kind() == Interface {
target = v.ptr
}
x = x.assignTo("reflect.Set", v.typ, target)
if x.flag&flagIndir != 0 {
// func typedmemmove(t *rtype, dst unsafe.Pointer, src unsafe.Pointer)
// typedmemmove 将类型 t 的值从 src 复制到 dst。
typedmemmove(v.typ, v.ptr, x.ptr)
} else {
*(*unsafe.Pointer)(v.ptr) = x.ptr
}
}
Set 函数的步骤如下:
检查反射对象及其字段是否可以被设置。
检查反射对象及其字段是否导出(对外公开)。
调用
assignTo方法创建一个新的反射对象并对原本的反射对象进行覆盖。assignTo会根据当前和被设置的反射对象类型创建一个新的reflect.Value结构体:- 如果两个反射对象的类型是可以被直接替换,就会直接返回目标反射对象;
- 如果当前反射对象是接口并且目标对象实现了接口,就会把目标对象简单包装成接口值;
func (v Value) assignTo(context string, dst *rtype, target unsafe.Pointer) Value { if v.flag&flagMethod != 0 { v = makeMethodValue(context, v) } switch { case directlyAssignable(dst, v.typ): // Overwrite type so that they match. // Same memory layout, so no harm done. fl := v.flag&(flagAddr|flagIndir) | v.flag.ro() fl |= flag(dst.Kind()) // 返回一个新的结构题 return Value{dst, v.ptr, fl} case implements(dst, v.typ): if target == nil { target = unsafe_New(dst) } if v.Kind() == Interface && v.IsNil() { // A nil ReadWriter passed to nil Reader is OK, // but using ifaceE2I below will panic. // Avoid the panic by returning a nil dst (e.g., Reader) explicitly. return Value{dst, nil, flag(Interface)} } x := valueInterface(v, false) if dst.NumMethod() == 0 { *(*interface{})(target) = x } else { ifaceE2I(dst, x, target) } return Value{dst, target, flagIndir | flag(Interface)} } // Failed. panic(context + ": value of type " + v.typ.String() + " is not assignable to type " + dst.String()) }根据
assignTo方法所返回的指针值,对当前反射对象的指针进行值的修改。
简单来讲就是,检查是否可以设置,接着创建一个新的对象,最后对其修改。是一个非常标准的赋值流程。
未导出成员
利用反射机制,对于结构体中未导出成员,可以读取,但不能修改其值。
注意,正常情况下,代码是不能读取结构体未导出成员的,但通过反射可以越过这层限制。另外,通过反射,结构体中可以被修改的成员只有是导出成员,也就是字段名的首字母是大写的。
一个可取地址的 reflect.Value 变量会记录一个结构体成员是否是未导出成员,如果是的话则拒绝修改操作。
CanAddr不能说明一个变量是否可以被修改。CanSet则可以检查对应的reflect.Value是否可取地址并可被修改。
package main
import (
"reflect"
"fmt"
)
type Child struct {
Name string
handsome bool
}
func main() {
qcrao := Child{Name: "qcrao", handsome: true}
v := reflect.ValueOf(&qcrao)
f := v.Elem().FieldByName("Name")
fmt.Println(f.String())
f.SetString("stefno")
fmt.Println(f.String())
f = v.Elem().FieldByName("handsome")
// 这一句会导致 panic,因为 handsome 字段未导出
//f.SetBool(true)
fmt.Println(f.Bool())
}
执行结果:
qcrao
stefno
true
上面的例子中,handsome 字段未导出,可以读取,但不能调用相关 set 方法,否则会 panic。反射用起来一定要小心,调用类型不匹配的方法,会导致各种 panic。
反射的实际应用
反射的实际应用非常广:IDE 中的代码自动补全功能、对象序列化(json 函数库)、fmt 相关函数的实现、ORM(全称是:Object Relational Mapping,对象关系映射)……
这里举 2 个例子:json 序列化和 DeepEqual 函数。
json 序列化
json 是一种独立于语言的数据格式。最早用于浏览器和服务器之间的实时无状态的数据交换,并由此发展起来。
Go 语言中,主要提供 2 个函数用于序列化和反序列化:
func Marshal(v interface{}) ([]byte, error)
func Unmarshal(data []byte, v interface{}) error
两个函数的参数都包含 interface,具体实现的时候,都会用到反射相关的特性。
对于序列化和反序列化函数,均需要知道参数的所有字段,包括字段类型和值,再调用相关的 get 函数或者 set 函数进行实际的操作。
DeepEqual 的作用及原理
在测试函数中,经常会需要这样的函数:判断两个变量的实际内容完全一致。
例如:如何判断两个 slice 所有的元素完全相同;如何判断两个 map 的 key 和 value 完全相同等等。
上述问题,可以通过 DeepEqual 函数实现。
func DeepEqual(x, y interface{}) bool
DeepEqual 函数的参数是两个 interface,实际上也就是可以输入任意类型,输出 true 或者 flase 表示输入的两个变量是否是“深度”相等。
先明白一点,如果是不同的类型,即使是底层类型相同,相应的值也相同,那么两者也不是“深度”相等。
type MyInt int
type YourInt int
func main() {
m := MyInt(1)
y := YourInt(1)
fmt.Println(reflect.DeepEqual(m, y)) // false
}
上面的代码中,m, y 底层都是 int,而且值都是 1,但是两者静态类型不同,前者是 MyInt,后者是 YourInt,因此两者不是“深度”相等。
在源码里,有对 DeepEqual 函数的非常清楚地注释,列举了不同类型,DeepEqual 的比较情形,这里做一个总结:
| 类型 | 深度相等情形 |
|---|---|
| Array | 相同索引处的元素“深度”相等 |
| Struct | 相应字段,包含导出和不导出,“深度”相等 |
| Func | 只有两者都是 nil 时 |
| Interface | 两者存储的具体值“深度”相等 |
| Map | 1、都为 nil;2、非空、长度相等,指向同一个 map 实体对象,或者相应的 key 指向的 value “深度”相等 |
| Pointer | 1、使用 == 比较的结果相等;2、指向的实体“深度”相等 |
| Slice | 1、都为 nil;2、非空、长度相等,首元素指向同一个底层数组的相同元素,即 &x[0] == &y[0] 或者 相同索引处的元素“深度”相等 |
| numbers, bools, strings, and channels | 使用 == 比较的结果为真 |
一般情况下,DeepEqual 的实现只需要递归地调用 == 就可以比较两个变量是否是真的“深度”相等。
但是,有一些异常情况:比如 func 类型是不可比较的类型,只有在两个 func 类型都是 nil 的情况下,才是“深度”相等*;*float 类型,由于精度的原因,也是不能使用 == 比较的;包含 func 类型或者 float 类型的 struct, interface, array 等。
对于指针而言,当两个值相等的指针就是“深度”相等,因为两者指向的内容是相等的,即使两者指向的是 func 类型或者 float 类型,这种情况下不关心指针所指向的内容。
同样,对于指向相同 slice, map 的两个变量也是“深度”相等的,不关心 slice, map 具体的内容。
对于“有环”的类型,比如循环链表,比较两者是否“深度”相等的过程中,需要对已比较的内容作一个标记,一旦发现两个指针之前比较过,立即停止比较,并判定二者是深度相等的。这样做的原因是,及时停止比较,避免陷入无限循环。
来看源码:
func DeepEqual(x, y interface{}) bool {
if x == nil || y == nil {
return x == y
}
v1 := ValueOf(x)
v2 := ValueOf(y)
if v1.Type() != v2.Type() {
return false
}
return deepValueEqual(v1, v2, make(map[visit]bool), 0)
}
首先查看两者是否有一个是 nil 的情况,这种情况下,只有两者都是 nil,函数才会返回 true。
接着,使用反射,获取x,y 的反射对象,并且立即比较两者的类型,根据前面的内容,这里实际上是动态类型,如果类型不同,直接返回 false。
最后,最核心的内容在子函数 deepValueEqual 中。
代码比较长,思路却比较简单清晰:核心是一个 switch 语句,识别输入参数的不同类型,分别递归调用 deepValueEqual 函数,一直递归到最基本的数据类型,比较 int,string 等可以直接得出 true 或者 false,再一层层地返回,最终得到“深度”相等的比较结果。
实际上,各种类型的比较套路比较相似,这里就直接节选一个稍微复杂一点的 map 类型的比较:
// deepValueEqual 函数
// ……
case Map:
if v1.IsNil() != v2.IsNil() {
return false
}
if v1.Len() != v2.Len() {
return false
}
if v1.Pointer() == v2.Pointer() {
return true
}
for _, k := range v1.MapKeys() {
val1 := v1.MapIndex(k)
val2 := v2.MapIndex(k)
if !val1.IsValid() || !val2.IsValid() || !deepValueEqual(v1.MapIndex(k), v2.MapIndex(k), visited, depth+1) {
return false
}
}
return true
// ……
和前文总结的表格里,比较 map 是否相等的思路比较一致,也不需要多说什么。说明一点,visited 是一个 map,记录递归过程中,比较过的“对”:
type visit struct {
a1 unsafe.Pointer
a2 unsafe.Pointer
typ Type
}
map[visit]bool
比较过程中,一旦发现比较的“对”,已经在 map 里出现过的话,直接判定“深度”比较结果的是 true。
通道类型
Channel 是支撑 Go 语言高性能并发编程模型的重要结构。Go 语言中最常见的、也是经常被人提及的设计模式就是:不要通过共享内存的方式进行通信,而是应该通过通信的方式共享内存。在很多主流的编程语言中,多个线程传递数据的方式一般都是共享内存,为了解决线程竞争,需要限制同一时间能够读写这些变量的线程数量,然而这与 Go 语言鼓励的设计并不相同。
虽然在 Go 语言中也能使用共享内存加互斥锁进行通信,但是 Go 语言提供了一种不同的并发模型,即通信顺序进程(Communicating sequential processes,CSP)。Goroutine 和 Channel 分别对应 CSP 中的实体和传递信息的媒介,Goroutine 之间会通过 Channel 传递数据。
上图中的两个 Goroutine,一个会向 Channel 中发送数据,另一个会从 Channel 中接收数据,它们两者能够独立运行并不存在直接关联,但是能通过 Channel 间接完成通信。
数据结构
Channel 在运行时使用 runtime.hchan结构体表示,当创建一个 channel 的时候,实际上创建的是如下的一个结构体:
type hchan struct {
qcount uint
dataqsiz uint
buf unsafe.Pointer
elemsize uint16
closed uint32
elemtype *_type
sendx uint
recvx uint
recvq waitq
sendq waitq
lock mutex
}
该结构体中的五个字段 qcount、dataqsiz、buf、sendx、recv 构建底层的循环队列:
qcount— Channel 中的元素个数;dataqsiz— Channel 中的循环队列的长度;buf— Channel 的缓冲区数据指针;sendx— Channel 的发送操作处理到的位置;recvx— Channel 的接收操作处理到的位置;
除此之外,elemsize 和 elemtype 分别表示当前 Channel 能够收发的元素类型和大小;sendq 和 recvq 存储了当前 Channel 由于缓冲区空间不足而阻塞的 Goroutine 列表,这些等待队列使用双向链表 runtime.waitq 表示,链表中所有的元素都是 runtime.sudog 结构:
type waitq struct {
first *sudog
last *sudog
}
runtime.sudog 表示一个在等待列表中的 Goroutine,该结构中存储了两个分别指向前后 runtime.sudog 的指针以构成链表。
创建管道
Go 语言中所有 Channel 的创建都会使用 make 关键字。编译器会将 make(chan int, 10) 表达式转换成 OMAKE 类型的节点,并在类型检查阶段将 OMAKE 类型的节点转换成 OMAKECHAN 类型。这一阶段会对传入 make 关键字的缓冲区大小进行检查,如果不向 make 传递表示缓冲区大小的参数,那么就会设置一个默认值 0,也就是当前的 Channel 不存在缓冲区。
func makechan(t *chantype, size int) *hchan {
elem := t.elem
mem, _ := math.MulUintptr(elem.size, uintptr(size))
var c *hchan
switch {
case mem == 0:
c = (*hchan)(mallocgc(hchanSize, nil, true))
c.buf = c.raceaddr()
case elem.kind&kindNoPointers != 0:
c = (*hchan)(mallocgc(hchanSize+mem, nil, true))
c.buf = add(unsafe.Pointer(c), hchanSize)
default:
c = new(hchan)
c.buf = mallocgc(mem, elem, true)
}
c.elemsize = uint16(elem.size)
c.elemtype = elem
c.dataqsiz = uint(size)
return c
}
上述代码根据 Channel 中收发元素的类型和缓冲区的大小初始化 runtime.hchan 和缓冲区:
- 如果当前 Channel 中不存在缓冲区,那么就只会为
runtime.hchan分配一段内存空间; - 如果当前 Channel 中存储的类型不是指针类型,会为当前的 Channel 和底层的数组分配一块连续的内存空间;
- 在默认情况下会单独为
runtime.hchan和缓冲区分配内存;
在函数的最后会统一更新 elemsize、elemtype 和 dataqsiz 几个字段。
向通道传递数据
当想要向 Channel 发送数据时,就需要使用 ch <- i 语句,编译器会将它解析成 OSEND 节点并最终调用 runtime.chansend 并传入 Channel 和需要发送的数据。
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool {
lock(&c.lock)
if c.closed != 0 {
unlock(&c.lock)
panic(plainError("send on closed channel"))
}
在发送数据的逻辑执行之前会先为当前 Channel 加锁,防止多个线程并发修改数据。所以本质上往 channel 中写数据也是有加锁操作的
如果 Channel 已经关闭,那么向该 Channel 发送数据时会报 “send on closed channel” 错误并中止程序。
该函数的执行过程分成以下的三个部分:
- 当存在等待的接收者时,通过
runtime.send直接将数据发送给阻塞的接收者; - 当缓冲区存在空余空间时,将发送的数据写入 Channel 的缓冲区;
- 当不存在缓冲区或者缓冲区已满时,等待其他 Goroutine 从 Channel 接收数据;
直接发送
如果目标 Channel 没有被关闭并且已经有处于读等待的 Goroutine,那么 runtime.chansend 会从接收队列 recvq 中取出最先陷入等待的 Goroutine 并直接向它发送数据:
if sg := c.recvq.dequeue(); sg != nil {
send(c, sg, ep, func() { unlock(&c.lock) }, 3)
return true
}
发送数据时会调用 runtime.send,该函数的执行可以分成两个部分:
- 调用
runtime.sendDirect将发送的数据直接拷贝到x = <-c表达式中变量x所在的内存地址上; - 调用
runtime.goready将等待接收数据的 Goroutine 标记成可运行状态Grunnable并把该 Goroutine 放到发送方所在的处理器的runnext上等待执行,该处理器在下一次调度时会立刻唤醒数据的接收方;
func send(c *hchan, sg *sudog, ep unsafe.Pointer, unlockf func(), skip int) {
if sg.elem != nil {
sendDirect(c.elemtype, sg, ep)
sg.elem = nil
}
gp := sg.g
unlockf()
gp.param = unsafe.Pointer(sg)
goready(gp, skip+1)
}
需要注意的是,发送数据的过程只是将接收方的 Goroutine 放到了处理器的 runnext 中,程序没有立刻执行该 Goroutine。
缓冲区
如果创建的 Channel 包含缓冲区并且 Channel 中的数据没有装满,首先会使用 runtime.chanbuf 计算出下一个可以存储数据的位置,然后通过 runtime.typedmemmove 将发送的数据拷贝到缓冲区中并增加 sendx 索引和 qcount 计数器。如果当前 Channel 的缓冲区未满,向 Channel 发送的数据会存储在 Channel 的 sendx 索引所在的位置并将 sendx 索引加一。因为这里的 buf 是一个循环数组,所以当 sendx 等于 dataqsiz 时会重新回到数组开始的位置。
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool {
...
if c.qcount < c.dataqsiz {
qp := chanbuf(c, c.sendx)
typedmemmove(c.elemtype, qp, ep)
c.sendx++
if c.sendx == c.dataqsiz {
c.sendx = 0
}
c.qcount++
unlock(&c.lock)
return true
}
...
}
阻塞发送
当 Channel 没有接收者能够处理数据时,向 Channel 发送数据会被下游阻塞,当然使用 select 关键字可以向 Channel 非阻塞地发送消息。向 Channel 阻塞地发送数据会执行下面的代码,可以简单梳理一下这段代码的逻辑:
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool {
...
if !block {
unlock(&c.lock)
return false
}
gp := getg()
mysg := acquireSudog()
mysg.elem = ep
mysg.g = gp
mysg.c = c
gp.waiting = mysg
c.sendq.enqueue(mysg)
goparkunlock(&c.lock, waitReasonChanSend, traceEvGoBlockSend, 3)
gp.waiting = nil
gp.param = nil
mysg.c = nil
releaseSudog(mysg)
return true
}
- 调用
runtime.getg获取发送数据使用的 Goroutine; - 执行
runtime.acquireSudog获取runtime.sudog结构并设置这一次阻塞发送的相关信息,例如发送的 Channel、是否在 select 中和待发送数据的内存地址等; - 将刚刚创建并初始化的
runtime.sudog加入发送等待队列,并设置到当前 Goroutine 的waiting上,表示 Goroutine 正在等待该sudog准备就绪; - 调用
runtime.goparkunlock将当前的 Goroutine 陷入沉睡等待唤醒; - 被调度器唤醒后会执行一些收尾工作,将一些属性置零并且释放
runtime.sudog结构体;
函数在最后会返回 true 表示这次我们已经成功向 Channel 发送了数据。
总结
在这里可以简单梳理和总结一下使用 ch <- i 表达式向 Channel 发送数据时遇到的几种情况:
- 如果当前 Channel 的
recvq上存在已经被阻塞的 Goroutine,那么会直接将数据发送给当前 Goroutine 并将其设置成下一个运行的 Goroutine; - 如果 Channel 存在缓冲区并且其中还有空闲的容量,会直接将数据存储到缓冲区
sendx所在的位置上; - 如果不满足上面的两种情况,会创建一个
runtime.sudog结构并将其加入 Channel 的sendq队列中,当前 Goroutine 也会陷入阻塞等待其他的协程从 Channel 接收数据;
发送数据的过程中包含几个会触发 Goroutine 调度的时机:
- 发送数据时发现 Channel 上存在等待接收数据的 Goroutine,立刻设置处理器的
runnext属性,但是并不会立刻触发调度; - 发送数据时并没有找到接收方并且缓冲区已经满了,这时会将自己加入 Channel 的
sendq队列并调用runtime.goparkunlock触发 Goroutine 的调度让出处理器的使用权;
从通道接收数据
Go 语言中可以使用两种不同的方式去接收 Channel 中的数据:
i <- ch
i, ok <- ch
这两种不同的方法经过编译器的处理都会变成 ORECV 类型的节点,后者会在类型检查阶段被转换成 OAS2RECV 类型。
虽然不同的接收方式会被转换成 runtime.chanrecv1 和 runtime.chanrecv2 两种不同函数的调用,但是这两个函数最终还是会调用 runtime.chanrecv。
当从一个空 Channel 接收数据时会直接调用 runtime.gopark 让出处理器的使用权。
如果当前 Channel 已经被关闭并且缓冲区中不存在任何数据,那么会清除 ep 指针中的数据并立刻返回。
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {
if c == nil {
if !block {
return
}
gopark(nil, nil, waitReasonChanReceiveNilChan, traceEvGoStop, 2)
throw("unreachable")
}
// 这里也加了锁
lock(&c.lock)
if c.closed != 0 && c.qcount == 0 {
unlock(&c.lock)
if ep != nil {
typedmemclr(c.elemtype, ep)
}
return true, false
}
从代码可以看出,对于 channel 的读操作,同样是加了锁来保障并发安全。
除了上述两种特殊情况,使用 runtime.chanrecv 从 Channel 接收数据时还包含以下三种不同情况:
- 当存在等待的发送者时,通过
runtime.recv从阻塞的发送者或者缓冲区中获取数据; - 当缓冲区存在数据时,从 Channel 的缓冲区中接收数据;
- 当缓冲区中不存在数据时,等待其他 Goroutine 向 Channel 发送数据;
直接接收
当 Channel 的 sendq 队列中包含处于等待状态的 Goroutine 时,该函数会取出队列头等待的 Goroutine,处理的逻辑和发送时相差无几,只是发送数据时调用的是 runtime.send 函数,而接收数据时使用 runtime.recv:
if sg := c.sendq.dequeue(); sg != nil {
recv(c, sg, ep, func() { unlock(&c.lock) }, 3)
return true, true
}
该函数会根据缓冲区的大小分别处理不同的情况:
- 如果 Channel 不存在缓冲区;
- 调用
runtime.recvDirect将 Channel 发送队列中 Goroutine 存储的elem数据拷贝到目标内存地址中;
- 调用
- 如果 Channel 存在缓冲区;
- 将队列中的数据拷贝到接收方的内存地址;
- 将发送队列头的数据拷贝到缓冲区中,释放一个阻塞的发送方;
无论发生哪种情况,运行时都会调用 runtime.goready 将当前处理器的 runnext 设置成发送数据的 Goroutine,在调度器下一次调度时将阻塞的发送方唤醒。
缓冲区
当 Channel 的缓冲区中已经包含数据时,从 Channel 中接收数据会直接从缓冲区中 recvx 的索引位置中取出数据进行处理。如果接收数据的内存地址不为空,那么会使用 runtime.typedmemmove将缓冲区中的数据拷贝到内存中、清除队列中的数据并完成收尾工作。收尾工作包括递增 recvx,一旦发现索引超过了 Channel 的容量时,会将它归零重置循环队列的索引;除此之外,该函数还会减少 qcount 计数器并释放持有 Channel 的锁。
阻塞接收
当 Channel 的发送队列中不存在等待的 Goroutine 并且缓冲区中也不存在任何数据时,从管道中接收数据的操作会变成阻塞的,然而不是所有的接收操作都是阻塞的,与 select 语句结合使用时就可能会使用到非阻塞的接收操作。
在正常的接收场景中,会使用 runtime.sudog 将当前 Goroutine 包装成一个处于等待状态的 Goroutine 并将其加入到接收队列中。
完成入队之后,还会调用 runtime.goparkunlock 立刻触发 Goroutine 的调度,让出处理器的使用权并等待调度器的调度。
总结
梳理一下从 Channel 中接收数据时可能会发生的五种情况:
- 如果 Channel 为空,那么会直接调用
runtime.gopark挂起当前 Goroutine; - 如果 Channel 已经关闭并且缓冲区没有任何数据,
runtime.chanrecv会直接返回; - 如果 Channel 的
sendq队列中存在挂起的 Goroutine,会将recvx索引所在的数据拷贝到接收变量所在的内存空间上并将sendq队列中 Goroutine 的数据拷贝到缓冲区; - 如果 Channel 的缓冲区中包含数据,那么直接读取
recvx索引对应的数据; - 在默认情况下会挂起当前的 Goroutine,将
runtime.sudog结构加入recvq队列并陷入休眠等待调度器的唤醒;
总结一下从 Channel 接收数据时,会触发 Goroutine 调度的两个时机:
- 当 Channel 为空时;
- 当缓冲区中不存在数据并且也不存在数据的发送者时;
关闭通道
编译器会将用于关闭管道的 close 关键字转换成 OCLOSE 节点以及 runtime.closechan 函数。
当 Channel 是一个空指针或者已经被关闭时,Go 语言运行时都会直接崩溃并抛出异常:
func closechan(c *hchan) {
if c == nil {
panic(plainError("close of nil channel"))
}
lock(&c.lock)
if c.closed != 0 {
unlock(&c.lock)
panic(plainError("close of closed channel"))
}
处理完了这些异常的情况之后就可以开始执行关闭 Channel 的逻辑了,主要工作就是将 recvq 和 sendq 两个队列中的数据加入到 Goroutine 列表 gList 中,与此同时该函数会清除所有 runtime.sudog 上未被处理的元素,最后会为所有被阻塞的 Goroutine 调用 runtime.goready 触发调度。
Go 同步原语与锁
锁是一种并发编程中的同步原语(Synchronization Primitives),在 go 中,它能保证多个 Goroutine 在访问同一片内存时不会出现竞争条件(Race condition)等问题。
Go 中提供了常见的同步原语 sync.Mutex、sync.RWMutex、sync.WaitGroup、sync.Once 和 sync.Cond 以及扩展原语 golang/sync/errgroup.Group、golang/sync/semaphore.Weighted 和 golang/sync/singleflight.Group
这些基本原语提供了较为基础的同步功能,但是它们是一种相对原始的同步机制,在多数情况下,都应该使用抽象层级更高的 Channel 实现同步。
Mutex
sync.Mutex 有两种模式 — 正常模式和饥饿模式。在正常模式下,锁的等待者会按照先进先出的顺序获取锁。但是刚被唤起的 Goroutine 与新创建的 Goroutine 竞争时,大概率会获取不到锁,为了减少这种情况的出现,一旦 Goroutine 超过 1ms 没有获取到锁,它就会将当前互斥锁切换饥饿模式,防止部分 Goroutine 被饿死。
在饥饿模式中,互斥锁会直接交给等待队列最前面的 Goroutine。新的 Goroutine 在该状态下不能获取锁、也不会进入自旋状态,它们只会在队列的末尾等待。如果一个 Goroutine 获得了互斥锁并且它在队列的末尾或者它等待的时间少于 1ms,那么当前的互斥锁就会切换回正常模式。
与饥饿模式相比,正常模式下的互斥锁能够提供更好地性能,饥饿模式的能避免 Goroutine 由于陷入等待无法获取锁而造成的高尾延时。
Go 的 sync.Mutex 由两个字段 state,sema 组成,其中 state 表示当前互斥锁的状态,而 sema 是用于控制锁状态的信号量。
type Mutex struct {
state int32
sema uint32
}
互斥锁的状态
state 字段的最低三位分别表示 mutexLocked、mutexWoken 和 mutexStarving,剩下的位置用来表示当前有多少个 Goroutine 在等待互斥锁的释放。

在默认情况下,互斥锁的所有状态位都是 0,int32 中的不同位分别表示了不同的状态:
mutexLocked— 表示互斥锁的锁定状态;mutexWoken— 表示从正常模式被从唤醒;mutexStarving— 当前的互斥锁进入饥饿状态;waitersCount— 当前互斥锁上等待的 Goroutine 个数;
加锁
互斥锁的加锁通过 sync.Mutex.Lock 方法实现:
func (m *Mutex) Lock() {
// Fast path: grab unlocked mutex.
if atomic.CompareAndSwapInt32(&m.state, 0, mutexLocked) {
if race.Enabled {
race.Acquire(unsafe.Pointer(m))
}
return
}
// Slow path (outlined so that the fast path can be inlined)
m.lockSlow()
}
当锁的状态是 0 时,将 mutexLocked 位置成 1;
如果互斥锁的状态不是 0 时就会调用 sync.Mutex.lockSlow 尝试通过自旋(Spinnig)等方式等待锁的释放,该方法的主体是一个非常大 for 循环,这里将它分成几个部分介绍获取锁的过程:
- 判断当前 Goroutine 能否进入自旋;
- 通过自旋等待互斥锁的释放;
- 计算互斥锁的最新状态;
- 更新互斥锁的状态并获取锁;
func (m *Mutex) lockSlow() {
var waitStartTime int64
starving := false
awoke := false
iter := 0
old := m.state
for {
// Don't spin in starvation mode, ownership is handed off to waiters
// so we won't be able to acquire the mutex anyway.
if old&(mutexLocked|mutexStarving) == mutexLocked && runtime_canSpin(iter) {
// Active spinning makes sense.
// Try to set mutexWoken flag to inform Unlock
// to not wake other blocked goroutines.
if !awoke && old&mutexWoken == 0 && old>>mutexWaiterShift != 0 &&
atomic.CompareAndSwapInt32(&m.state, old, old|mutexWoken) {
awoke = true
}
runtime_doSpin()
iter++
old = m.state
continue
}
自旋是一种多线程同步机制,当前的进程在进入自旋的过程中会一直保持 CPU 的占用,持续检查某个条件是否为真。在多核的 CPU 上,自旋可以避免 Goroutine 的切换,使用恰当会对性能带来很大的增益,但是使用的不恰当就会拖慢整个程序,所以 Goroutine 进入自旋的条件非常苛刻:
- 互斥锁只有在普通模式才能进入自旋;
runtime_canSpin需要返回true:- 运行在多 CPU 的机器上;
- 当前 Goroutine 为了获取该锁进入自旋的次数小于四次;
- 当前机器上至少存在一个正在运行的处理器 P 并且处理的运行队列为空;
一旦当前 Goroutine 能够进入自旋就会调用 runtime_doSpin。
处理了自旋相关的特殊逻辑之后,互斥锁会根据上下文计算当前互斥锁最新的状态。几个不同的条件分别会更新 state 字段中存储的不同信息 — mutexLocked、mutexStarving、mutexWoken 和 mutexWaiterShift。
计算了新的互斥锁状态之后,会使用 CAS 函数 atomic.CompareAndSwapInt32 更新状态。
如果没有通过 CAS 获得锁,会调用 runtime_SemacquireMutex 通过信号量保证资源不会被两个 Goroutine 获取,该方法会在方法中不断尝试获取锁并陷入休眠等待信号量的释放,一旦当前 Goroutine 可以获取信号量,它就会立刻返回。
解锁
解锁过程与加锁过程相比就很简单,该过程会先使用 atomic.AddInt32 函数快速解锁,这时会发生两种情况:
- 如果该函数返回的新状态等于 0,当前 Goroutine 就成功解锁了互斥锁;
- 如果该函数返回的新状态不等于 0,这段代码会调用
sync.Mutex.unlockSlow开始慢速解锁。
func (m *Mutex) Unlock() {
if race.Enabled {
_ = m.state
race.Release(unsafe.Pointer(m))
}
// Fast path: drop lock bit.
new := atomic.AddInt32(&m.state, -mutexLocked)
if new != 0 {
// Outlined slow path to allow inlining the fast path.
// To hide unlockSlow during tracing we skip one extra frame when tracing GoUnblock.
m.unlockSlow(new)
}
}
慢速解锁会先校验锁状态的合法性 — 如果当前互斥锁已经被解锁过了会直接抛出异常 “sync: unlock of unlocked mutex” 中止当前程序。
在正常情况下会根据当前互斥锁的状态,分别处理正常模式和饥饿模式下的互斥锁:
- 在正常模式下,如果互斥锁不存在等待者或者互斥锁的
mutexLocked、mutexStarving、mutexWoken状态不都为 0,那么当前方法可以直接返回,不需要唤醒其他等待者;如果互斥锁存在等待者,会通过runtime_Semrelease唤醒等待者并移交锁的所有权; - 在饥饿模式下,上述代码会直接调用
runtime_Semrelease将当前锁交给下一个正在尝试获取锁的等待者,等待者被唤醒后会得到锁,在这时互斥锁还不会退出饥饿状态;
总结
互斥锁的加锁过程比较复杂,它涉及自旋、信号量以及调度等概念:
- 如果互斥锁处于初始化状态,会通过置位
mutexLocked加锁; - 如果互斥锁处于
mutexLocked状态并且在普通模式下工作,会进入自旋,执行 30 次PAUSE指令消耗 CPU 时间等待锁的释放; - 如果当前 Goroutine 等待锁的时间超过了 1ms,互斥锁就会切换到饥饿模式;
- 互斥锁在正常情况下会通过
runtime.sync_runtime_SemacquireMutex将尝试获取锁的 Goroutine 切换至休眠状态,等待锁的持有者唤醒; - 如果当前 Goroutine 是互斥锁上的最后一个等待的协程或者等待的时间小于 1ms,那么它会将互斥锁切换回正常模式;
互斥锁的解锁过程与之相比就比较简单:
- 当互斥锁已经被解锁时,调用
sync.Mutex.Unlock会直接抛出异常; - 当互斥锁处于饥饿模式时,将锁的所有权交给队列中的下一个等待者,等待者会负责设置
mutexLocked标志位; - 当互斥锁处于普通模式时,如果没有 Goroutine 等待锁的释放或者已经有被唤醒的 Goroutine 获得了锁,会直接返回;在其他情况下会通过
sync.runtime_Semrelease唤醒对应的 Goroutine。
RWMutex
读写互斥锁 sync.RWMutex 是细粒度的互斥锁,它不限制资源的并发读,但是读写、写写操作无法并行执行。
type RWMutex struct {
w Mutex // 复用互斥锁提供的能力
// writerSem 和 readerSem 分别用于写等待读和读等待写
writerSem uint32
readerSem uint32
readerCount int32 // 存储了当前正在执行的读操作数量
readerWait int32 // 表示当写操作被阻塞时等待的读操作个数
}
写锁
当资源的使用者想要获取写锁时,需要调用 RWMutex.Lock 方法:
func (rw *RWMutex) Lock() {
if race.Enabled {
_ = rw.w.state
race.Disable()
}
// First, resolve competition with other writers.
rw.w.Lock()
// Announce to readers there is a pending writer.
r := atomic.AddInt32(&rw.readerCount, -rwmutexMaxReaders) + rwmutexMaxReaders
// Wait for active readers.
if r != 0 && atomic.AddInt32(&rw.readerWait, r) != 0 {
runtime_SemacquireMutex(&rw.writerSem, false, 0)
}
if race.Enabled {
race.Enable()
race.Acquire(unsafe.Pointer(&rw.readerSem))
race.Acquire(unsafe.Pointer(&rw.writerSem))
}
}
- 调用结构体内部的
Mutex的Lock方法阻塞后续的写操作,因为互斥锁已经被获取,其他 Goroutine 在获取写锁时会进入自旋或者休眠; - 调用
atomic.AddInt32函数阻塞后续的读操作,改操作将readerCount置为负数; - 如果仍然有其他 Goroutine 持有互斥锁的读锁,该 Goroutine 会调用
runtime_SemacquireMutex进入休眠状态等待所有读锁所有者执行结束后释放writerSem信号量将当前协程唤醒。
写锁的释放会调用 Mutex 的 Unlock 方法:
func (rw *RWMutex) Unlock() {
if race.Enabled {
_ = rw.w.state
race.Release(unsafe.Pointer(&rw.readerSem))
race.Disable()
}
// Announce to readers there is no active writer.
r := atomic.AddInt32(&rw.readerCount, rwmutexMaxReaders)
if r >= rwmutexMaxReaders {
race.Enable()
throw("sync: Unlock of unlocked RWMutex")
}
// Unblock blocked readers, if any.
for i := 0; i < int(r); i++ {
runtime_Semrelease(&rw.readerSem, false, 0)
}
// Allow other writers to proceed.
rw.w.Unlock()
if race.Enabled {
race.Enable()
}
}
写锁的释放分以下几个执行:
- 调用
atomic.AddInt32函数将readerCount变回正数,释放读锁; - 通过 for 循环释放所有因为获取读锁而陷入等待的 Goroutine;
- 调用
Mutex.Unlock释放写锁。
获取写锁时会先阻塞写锁的获取,后阻塞读锁的获取,这种策略能够保证读操作不会被连续的写操作饿死。
读锁
读锁通过 RLock 添加:
func (rw *RWMutex) RLock() {
if race.Enabled {
_ = rw.w.state
race.Disable()
}
if atomic.AddInt32(&rw.readerCount, 1) < 0 {
// A writer is pending, wait for it.
runtime_SemacquireMutex(&rw.readerSem, false, 0)
}
if race.Enabled {
race.Enable()
race.Acquire(unsafe.Pointer(&rw.readerSem))
}
}
- 通过
atomic.AddInt32方法将readerCount参数加一,如果返回一个负数,则表示其他 Goroutine 获得了写锁,当前 Goroutine 就会调用runtime_SemacquireMutex陷入休眠等待锁的释放; - 如果该方法的结果是一个非负数,则证明没有 Goroutine 获得写锁,当前方法会成功返回。
读锁的释放通过 RWMutex.RUnlock 方法实现:
func (rw *RWMutex) RUnlock() {
if race.Enabled {
_ = rw.w.state
race.ReleaseMerge(unsafe.Pointer(&rw.writerSem))
race.Disable()
}
if r := atomic.AddInt32(&rw.readerCount, -1); r < 0 {
// Outlined slow-path to allow the fast-path to be inlined
rw.rUnlockSlow(r)
}
if race.Enabled {
race.Enable()
}
}
该方法首先会减少正在读资源的 readCount 整数,根据 atomic.AddInt32 的返回结果进行不同的处理:
如果返回值大于等于零 — 读锁直接解锁成功;
如果返回值小于零,表示此事有一个正在执行的写操作,在这时会调用
rw.rUnlockSlow方法,该方法会减少获取写锁的写操作等待的读操作数readerWait,并在所有读操作都被释放之后触发写操作的信号量writerSem,该信号量被触发时,调度器就会唤醒尝试获取写锁的 Goroutine。这里的场景是在获得写锁后阻塞了后续读锁的获取,但是此时写锁也被阻塞,需要等待正在读的所有读锁释放后才能执行
WaitGroup
sync.WaitGroup 可以等待一组 Goroutine 的返回,一个比较常见的使用场景是批量发出 RPC 或者 HTTP 请求:
requests := []*Request{...}
wg := &sync.WaitGroup{}
wg.Add(len(requests))
for _, request := range requests {
go func(r *Request) {
defer wg.Done()
// res, err := service.call(r)
}(request)
}
wg.Wait()
通过 waitGroup,可以将原本顺序执行的代码在多个 Goroutine 中并发执行,加快程序处理的速度。
结构体
waitGroup 的结构如下:
type WaitGroup struct {
noCopy noCopy
state1 [3]uint32
}
- noCopy 保证
WaitGroup不会被开发者通过再赋值的方式拷贝 - state1 是一个总共占用 12 字节的数组,存储当前
WaitGroup的状态和信号量,在 64 位与 32 位的机器上,其状态表现有一定的差异。
接口
WaitGroup 提供了三个接口:Add,Done,Wait。其中 Done 方法只是调用了 wg.Add(-1) 进行实现。
wg.Add
func (wg *WaitGroup) Add(delta int) {
statep, semap := wg.state()
state := atomic.AddUint64(statep, uint64(delta)<<32)
v := int32(state >> 32)
w := uint32(state)
if v < 0 {
panic("sync: negative WaitGroup counter")
}
if v > 0 || w == 0 {
return
}
*statep = 0
for ; w != 0; w-- {
runtime_Semrelease(semap, false, 0)
}
}
Add 方法会更新 sync.WaitGroup 的计数器 counter,计数器只能是非负数,一旦出现负数就会发生程序崩溃。当调用计数器归零,即所有任务都执行完成时,会通过 runtime_Semrelease 唤醒处于等待状态的 Goroutine。
wg.Wait
statep, semap := wg.state()
if race.Enabled {
_ = *statep // trigger nil deref early
race.Disable()
}
for {
state := atomic.LoadUint64(statep)
v := int32(state >> 32)
w := uint32(state)
if v == 0 {
if race.Enabled {
race.Enable()
race.Acquire(unsafe.Pointer(wg))
}
return
}
if atomic.CompareAndSwapUint64(statep, state, state+1) {
if race.Enabled && w == 0 {
race.Write(unsafe.Pointer(semap))
}
runtime_Semacquire(semap)
if *statep != 0 {
panic("sync: WaitGroup is reused before previous Wait has returned")
}
if race.Enabled {
race.Enable()
race.Acquire(unsafe.Pointer(wg))
}
return
}
}
Wait 方法会在计数器大于 0 并且不存在等待的 Goroutine 时,通过 runtime_Semacquire 陷入睡眠。当计数器归零时,陷入睡眠状态的 Goroutine 会被唤醒,上述方法也会立刻返回。
Once
Once 可以用来保证在 Go 程序运行期间的某段代码只会执行一次。在运行如下所示的代码时,会看到如下所示的运行结果:
func main() {
o := &sync.Once{}
for i := 0; i < 10; i++ {
o.Do(func() {
fmt.Println("only once")
})
}
}
$ go run main.go
only once
Go
Once 的结构体如下:
type Once struct {
done uint32 // 用于标识当前动作是否已执行过
m Mutex
}
Once 中只有一个对外暴露的方法 Do:
func (o *Once) Do(f func()) {
if atomic.LoadUint32(&o.done) == 0 {
// Outlined slow-path to allow inlining of the fast-path.
o.doSlow(f)
}
}
func (o *Once) doSlow(f func()) {
o.m.Lock()
defer o.m.Unlock()
if o.done == 0 {
defer atomic.StoreUint32(&o.done, 1)
f()
}
}
- 如果传入的函数已经执行过,会直接返回;
- 如果传入的函数没有执行过,会调用
doSlow,该方法会为当前 Goroutine 获取互斥锁,执行传入的参数,然后将成员变量done设置成 1 来保证函数不会执行第二次。
Cond
Cond 可以让一组的 Goroutine 在满足特定条件时都被唤醒。每一个 sync.Cond 结构体在初始化时都需要传入一个互斥锁,使用方式如下:
var status int64
func main() {
c := sync.NewCond(&sync.Mutex{})
for i := 0; i < 10; i++ {
go listen(c)
}
time.Sleep(1 * time.Second)
go broadcast(c)
ch := make(chan os.Signal, 1)
signal.Notify(ch, os.Interrupt)
<-ch
}
func broadcast(c *sync.Cond) {
c.L.Lock()
atomic.StoreInt64(&status, 1)
c.Broadcast()
c.L.Unlock()
}
func listen(c *sync.Cond) {
c.L.Lock()
for atomic.LoadInt64(&status) != 1 {
c.Wait()
}
fmt.Println("listen")
c.L.Unlock()
}
$ go run main.go
listen
...
listen
上述代码同时运行了 11 个 Goroutine,这 11 个 Goroutine 分别做了不同事情:
- 10 个 Goroutine 通过
sync.Cond.Wait等待特定条件的满足; - 1 个 Goroutine 会调用
sync.Cond.Broadcast唤醒所有陷入等待的 Goroutine;
调用 sync.Cond.Broadcast 方法后,上述代码会打印出 10 次 “listen” 并结束调用。
结构体
type Cond struct {
noCopy noCopy
// L is held while observing or changing the condition
L Locker
notify notifyList
checker copyChecker
}
noCopy— 用于保证结构体不会在编译期间拷贝;copyChecker— 用于禁止运行期间发生的拷贝;L— 用于保护内部的notify字段,Locker接口类型的变量;notify— 一个 Goroutine 的链表,它是实现同步机制的核心结构。
notifyList 的结构如下所示:
type notifyList struct {
wait uint32
notify uint32
lock uintptr // key field of the mutex
head unsafe.Pointer
tail unsafe.Pointer
}
head和tail 分别指向的链表的头和尾,wait和notify` 分别表示当前正在等待的和已经通知到的 Goroutine 的索引。
接口
Wait 方法用于将当前的 Goroutine 陷入休眠状态,它的执行过程分为两个步骤:
runtime_notifyListAdd将等待计数器加一并解锁runtime_notifyListWait等待其他 Goroutine 的唤醒并加锁
func (c *Cond) Wait() {
c.checker.check()
t := runtime_notifyListAdd(&c.notify)
// 加锁是在使用 Cond 的时候在业务逻辑里加上的
c.L.Unlock()
runtime_notifyListWait(&c.notify, t)
c.L.Lock()
}
Signal 和 Broadcast 方法用来唤醒陷入休眠的 Goroutine 的方法,它们的实现有一些细微的差别:
Signal方法会唤醒队列最前面的 Goroutine;sync.Cond.Broadcast方法会唤醒队列中全部的 Goroutine。
func (c *Cond) Signal() {
c.checker.check()
runtime_notifyListNotifyOne(&c.notify)
}
func (c *Cond) Broadcast() {
c.checker.check()
runtime_notifyListNotifyAll(&c.notify)
}
Goroutine 的唤醒顺序也是按照加入队列的先后顺序,先加入的会先被唤醒,而后加入的可能 Goroutine 需要等待调度器的调度。
ErrGroup
ErrGroup 在一组 Goroutine 中提供了同步、错误传播以及上下文取消的功能,可以使用如下所示的方式并行获取网页的数据:
var g errgroup.Group
var urls = []string{
"http://www.golang.org/",
"http://www.google.com/",
}
for i := range urls {
url := urls[i]
g.Go(func() error {
resp, err := http.Get(url)
if err == nil {
resp.Body.Close()
}
return err
})
}
if err := g.Wait(); err == nil {
fmt.Println("Successfully fetched all URLs.")
}
Go 方法能够创建一个 Goroutine 并在其中执行传入的函数,而 Wait 方法会等待所有 Goroutine 全部返回,该方法的不同返回结果也有不同的含义:
- 如果返回错误 — 这一组 Goroutine 最少返回一个错误;
- 如果返回空值 — 所有 Goroutine 都成功执行;
结构体
ErrGroup 结构体同时由三个比较重要的部分组成:
cancel— 创建context.Context时返回的取消函数,用于在多个 Goroutine 之间同步取消信号;wg— 用于等待一组 Goroutine 完成子任务的同步原语;errOnce— 用于保证只接收一个子任务返回的错误;
type Group struct {
cancel func()
wg sync.WaitGroup
errOnce sync.Once
err error
}
接口
WithContext 返回一个新的 Group 和一个从 ctx 派生的关联上下文。派生的 Context 在第一次传递给 Go 的函数返回非 nil 错误或第一次 Wait 返回时被取消。
Go 方法用户运行新的并行子任务,这个方法的执行过程如下:
- 调用
sync.WaitGroup.Add增加待处理的任务; - 创建新的 Goroutine 并运行子任务;
- 返回错误时及时调用
cancel并对err赋值,只有最早返回的错误才会被上游感知到,后续的错误都会被舍弃:
func (g *Group) Go(f func() error) {
g.wg.Add(1)
go func() {
defer g.wg.Done()
if err := f(); err != nil {
g.errOnce.Do(func() {
g.err = err
if g.cancel != nil {
g.cancel()
}
})
}
}()
}
另一个用于等待的 golang/sync/errgroup.Group.Wait 方法只是调用了 sync.WaitGroup.Wait,在子任务全部完成时取消 context.Context 并返回可能出现的错误。
func (g *Group) Wait() error {
g.wg.Wait()
if g.cancel != nil {
g.cancel()
}
return g.err
}
Semaphore
信号量是在并发编程中常见的一种同步机制,在需要控制访问资源的进程数量时就会用到信号量,它会保证持有的计数器在 0 到初始化的权重之间波动。
- 每次获取资源时都会将信号量中的计数器减去对应的数值,在释放时重新加回来;
- 当遇到计数器大于信号量大小时,会进入休眠等待其他线程释放信号;
Go 提供了带权重的信号量 semaphore.Weighted,可以按照不同的权重对资源的访问进行管理,这个结构体对外也只暴露了四个方法:
NewWeighted用于创建新的信号量Acquire用于阻塞地获取指定权重的资源,如果当前没有空闲资源,会陷入休眠等待;TryAcquire用于非阻塞地获取指定权重的资源,如果当前没有空闲资源,会直接返回false;Release用于释放制定权重的资源
结构体
NewWeighted 方法能根据传入的最大权重创建一个指向 Weighted 结构体的指针:
func NewWeighted(n int64) *Weighted {
w := &Weighted{size: n}
return w
}
type Weighted struct {
size int64
cur int64
mu sync.Mutex
waiters list.List
}
Weighted 结构体中包含一个 waiters 列表,其中存储着等待获取资源的 Goroutine,除此之外它还包含当前信号量的上限以及一个计数器 cur,这个计数器的范围就是 [0, size]
信号量中的计数器会随着用户对资源的访问和释放进行改变,引入的权重概念能够提供更细粒度的资源的访问控制,尽可能满足常见的用例。
获取
Acquire 方法用于获取指定权重的资源,其中包含三种不同情况:
- 当信号量中剩余的资源大于获取的资源并且没有等待的 Goroutine 时,会直接获取信号量;
- 当需要获取的信号量大于
semaphore.Weighted的上限时,由于不可能满足条件会直接返回错误; - 遇到其他情况时会将当前 Goroutine 加入到等待列表并通过
select等待调度器唤醒当前 Goroutine,Goroutine 被唤醒后会获取信号量;
func (s *Weighted) Acquire(ctx context.Context, n int64) error {
s.mu.Lock()
if s.size-s.cur >= n && s.waiters.Len() == 0 {
s.cur += n
s.mu.Unlock()
return nil
}
if n > s.size {
// Don't make other Acquire calls block on one that's doomed to fail.
s.mu.Unlock()
<-ctx.Done()
return ctx.Err()
}
ready := make(chan struct{})
w := waiter{n: n, ready: ready}
elem := s.waiters.PushBack(w)
s.mu.Unlock()
select {
case <-ctx.Done():
err := ctx.Err()
s.mu.Lock()
select {
case <-ready:
// Acquired the semaphore after we were canceled. Rather than trying to
// fix up the queue, just pretend we didn't notice the cancelation.
err = nil
default:
isFront := s.waiters.Front() == elem
s.waiters.Remove(elem)
// If we're at the front and there're extra tokens left, notify other waiters.
if isFront && s.size > s.cur {
s.notifyWaiters()
}
}
s.mu.Unlock()
return err
case <-ready:
return nil
}
}
另一个用于获取信号量的方法 TryAcquire 只会非阻塞地判断当前信号量是否有充足的资源,如果有充足的资源会直接立刻返回 true,否则会返回 false:
func (s *Weighted) TryAcquire(n int64) bool {
s.mu.Lock()
success := s.size-s.cur >= n && s.waiters.Len() == 0
if success {
s.cur += n
}
s.mu.Unlock()
return success
}
因为 TryAcquire 不会等待资源的释放,所以可能更适用于一些延时敏感、用户需要立刻感知结果的场景。
释放
当要释放信号量时,Release 方法会从头到尾遍历 waiters 列表中全部的等待者,如果释放资源后的信号量有充足的剩余资源就会通过 Channel 唤起指定的 Goroutine:
func (s *Weighted) Release(n int64) {
s.mu.Lock()
s.cur -= n
if s.cur < 0 {
s.mu.Unlock()
panic("semaphore: released more than held")
}
s.notifyWaiters()
s.mu.Unlock()
}
func (s *Weighted) notifyWaiters() {
for {
next := s.waiters.Front()
if next == nil {
break // No more waiters blocked.
}
w := next.Value.(waiter)
if s.size-s.cur < w.n {
break
}
s.cur += w.n
s.waiters.Remove(next)
close(w.ready)
}
}
当然也可能会出现剩余资源无法唤起 Goroutine 的情况,在这时当前方法在释放锁后会直接返回。
如果一个信号量需要的占用的资源非常多,它可能会长时间无法获取锁,这也是 semaphore.Weighted.Acquire 引入上下文参数的原因,即为信号量的获取设置超时时间。
SingleFlight
SingleFlight 能够在一个服务中抑制对下游的多次重复请求。通过使用其方法 Do 或者 DoChan 来包装方法,被包装的方法在对于同一个key,只会有一个协程执行,其他协程等待那个协程执行结束后,拿到同样的结果。
Do 方法:
func (g *Group) Do(key string, fn func() (interface{}, error)) (v interface{}, err error, shared bool)
- key:对于同一个 key,同时只有一个协程执行
- fn:被包装的函数
- v:返回值,即执行的结果,其他等待的协程都会拿到
- shared:表示是否有其他协程得到了这个结果
DoChan 方法:
func (g *Group) DoChan(key string, fn func() (interface{}, error)) <-chan Result
与Do方法一样,只是返回的是一个channel,执行结果会发送到channel中,其他等待的协程都可以从channel中拿到结果。
一个比较常见的使用场景是:在使用 Redis 对数据库中的数据进行缓存,发生缓存击穿时,大量的流量都会打到数据库上进而影响服务的尾延时。通过 SingleFlight.Group 能有效地解决这个问题,它能够限制对同一个键值对的多次重复请求,减少对下游的瞬时流量。
使用方式:
type service struct {
requestGroup singleflight.Group
}
func (s *service) handleRequest(ctx context.Context, request Request) (Response, error) {
v, err, _ := requestGroup.Do(request.Hash(), func() (interface{}, error) {
rows, err := // select * from tables
if err != nil {
return nil, err
}
return rows, nil
})
if err != nil {
return nil, err
}
return Response{
rows: rows,
}, nil
}
因为请求的哈希在业务上一般表示相同的请求,所以上述代码使用它作为请求的键。
结构体
singleflight.Group 结构体由一个互斥锁 sync.Mutex 和一个映射表组成,每一个 call 结构体都保存了当前调用对应的信息:
type Group struct {
mu sync.Mutex // protects m
m map[string]*call // lazily initialized
}
type call struct {
wg sync.WaitGroup
val interface{}
err error
forgotten bool
dups int
chans []chan<- Result
}
val和err字段都只会在执行传入的函数时赋值一次并在sync.WaitGroup.Wait返回时被读取;dups和chans两个字段分别存储了抑制的请求数量以及用于同步结果的 Channel。
接口
singleflight.Group 提供了两个用于抑制相同请求的方法:Do 和 DoChan,这两个方法在功能上没有太多的区别,只是在接口的表现上稍有不同。
每次调用 Do 方法都会获取互斥锁,随后判断是否已经存在键对应的 call:
- 当不存在对应的
call时:- 初始化一个新的
call指针 - 增加
sync.WaitGroup持有的计数器 - 将
call指针添加到映射表 - 释放持有的互斥锁
- 阻塞的调用
doCall方法等待结果的返回
- 初始化一个新的
- 当存在对应的
call时:- 增加
dups计数器,它表示当前重复的调用次数; - 释放持有的互斥锁;
- 通过
sync.WaitGroup.Wait等待请求的返回;
- 增加
func (g *Group) Do(key string, fn func() (interface{}, error)) (v interface{}, err error, shared bool) {
g.mu.Lock()
if g.m == nil {
g.m = make(map[string]*call)
}
if c, ok := g.m[key]; ok {
c.dups++
g.mu.Unlock()
c.wg.Wait()
if e, ok := c.err.(*panicError); ok {
panic(e)
} else if c.err == errGoexit {
runtime.Goexit()
}
return c.val, c.err, true
}
c := new(call)
c.wg.Add(1)
g.m[key] = c
g.mu.Unlock()
g.doCall(c, key, fn)
return c.val, c.err, c.dups > 0
}
因为 val 和 err 两个字段都只会在 doCall 方法中赋值,所以当 gdoCall 和 sync.WaitGroup.Wait 返回时,函数调用的结果和错误都会返回给 Do 的调用者。
对于 DoChan 方法,则是异步的调用方式:
func (g *Group) DoChan(key string, fn func() (interface{}, error)) <-chan Result {
ch := make(chan Result, 1)
g.mu.Lock()
if g.m == nil {
g.m = make(map[string]*call)
}
if c, ok := g.m[key]; ok {
c.dups++
c.chans = append(c.chans, ch)
g.mu.Unlock()
return ch
}
c := &call{chans: []chan<- Result{ch}}
c.wg.Add(1)
g.m[key] = c
g.mu.Unlock()
go g.doCall(c, key, fn)
return ch
}
参考文章:
深度解密Go语言之关于 interface 的 10 个问题