Go 内存管理与垃圾回收
Go 语言抛弃了 C/C++ 中的开发者管理内存的方式:主动申请与主动释放,增加了逃逸分析和 GC,这样开发者就能从内存管理中释放出来,有更多的精力去关注软件设计,而不是底层的内存问题。这是 Go 语言成为高生产力语言的原因之一。
从非常宏观的角度讲,Go的内存管理是下图这个样子:
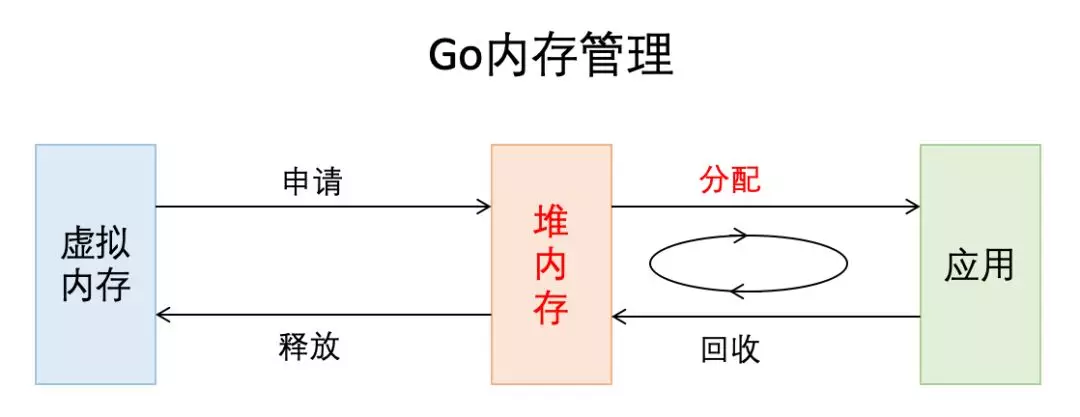
程序中的数据和变量都会被分配到程序所在的虚拟内存中,内存空间包含两个重要区域 — 栈区(Stack)和堆区(Heap)。函数调用的参数、返回值以及局部变量大都会被分配到栈上,这部分内存会由编译器进行管理;不同编程语言使用不同的方法管理堆区的内存,C++ 等编程语言会由工程师主动申请和释放内存,Go 以及 Java 等编程语言会由工程师和编译器共同管理,堆中的对象由内存分配器分配并由垃圾收集器回收。
传统的存储体系
计算机存储体系
计算机的存储体系的存储金字塔如图:
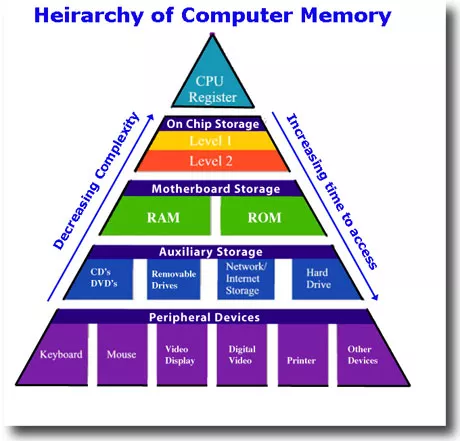
从上至下依次是:
- CPU寄存器
- Cache
- 内存
- 硬盘等辅助存储设备
- 鼠标等外接设备
从上至下,访问速度越来越慢,访问时间越来越长。
CPU速度很快,但硬盘等持久存储很慢,如果 CPU 直接访问磁盘,磁盘可以拉低 CPU 的速度,机器整体性能就会低下,为了弥补这 2 个硬件之间的速率差异,所以在 CPU 和磁盘之间增加了比磁盘快很多的内存。
然而,CPU 跟内存的速率也不是相同的,CPU 的速率提高的很快(摩尔定律),而内存速率增长的很慢,虽然 CPU 的速率现在增加的很慢了,但是内存的速率也没增加多少,速率差距很大,从 1980 年开始 CPU 和内存速率差距在不断拉大,为了弥补这 2 个硬件之间的速率差异,所以在 CPU 跟内存之间增加了比内存更快的 Cache,Cache 是内存数据的缓存,可以降低 CPU 访问内存的时间。
随着 CPU 的速率还在不断增大,Cache 也在不断改变,从最初的 1 级,到后来的 2 级,到当代的 3 级 Cache:

三级 Cache 分别是 L1、L2、L3,它们的速率是三个不同的层级,L1 速率最快,与 CPU 速率最接近,是 RAM 速率的 100 倍,L2 速率就降到了 RAM 的25倍,L3 的速率更靠近 RAM 的速率。
整个存储体系,从磁盘到CPU寄存器,上一层都可以看做是下一层的缓存。
操作系统存储体系
虚拟内存
虚拟内存是当代操作系统必备的一项重要功能了,它向进程屏蔽了底层了 RAM 和磁盘,并向进程提供了远超物理内存大小的内存空间。
虚拟内存的分层设计如下:
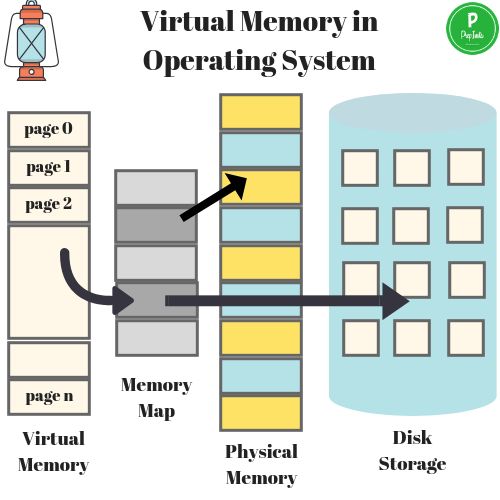
上图展示了某进程访问数据,当 Cache 没有命中的时候,访问虚拟内存获取数据的过程。
访问内存,实际访问的是虚拟内存,虚拟内存通过页表查看当前要访问的虚拟内存地址是否已经加载到了物理内存,如果已经在物理内存,则取物理内存数据,如果没有对应的物理内存,则从磁盘加载数据到物理内存,并把物理内存地址和虚拟内存地址更新到页表。
在这里,物理内存就是磁盘存储缓存层。
另外,在没有虚拟内存的时代,物理内存对所有进程是共享的,多进程同时访问同一个物理内存存在并发访问问题。引入虚拟内存后,每个进程都要各自的虚拟内存,内存的并发访问问题的粒度从多进程级别,可以降低到多线程级别。
堆和栈
在操作系统中,进程对内存的管理,主要是通过虚拟内存的堆和栈进行。
下图展示了一个进程的虚拟内存划分,代码中使用的内存地址都是虚拟内存地址,而不是实际的物理内存地址。栈和堆只是虚拟内存上 2 块不同功能的内存区域:
- 栈在高地址,从高地址向低地址增长。
- 堆在低地址,从低地址向高地址增长。
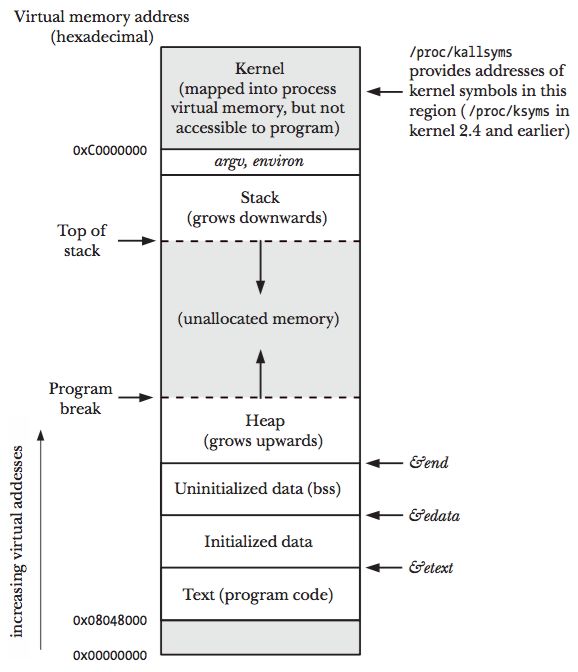
栈和堆相比有这么几个好处:
- 栈的内存管理简单,分配比堆上快。
- 栈的内存不需要回收,而堆需要,无论是主动 free,还是被动的垃圾回收,这都需要花费额外的 CPU。
- 栈上的内存有更好的局部性,堆上内存访问就不那么友好了,CPU 访问的 2 块数据可能在不同的页上, CPU 访问数据的时间可能就上去了。
堆内存管理
通常在讲内存管理的时候,主要都是指堆内存的管理,因为栈的内存管理不需要程序去操心。堆内存分为三个部分:分配内存块,回收内存块和组织内存块。
内存的分配一般会由分配器进行分配,编程语言的内存分配器一般包含两种分配方法,一种是线性分配器(Sequential Allocator,Bump Allocator),另一种是空闲链表分配器(Free-List Allocator),这两种分配方法有着不同的实现机制和特性。
线性分配
线性分配(Bump Allocator)是一种高效的内存分配方法,但是有较大的局限性。当在编程语言中使用线性分配器,只需要在内存中维护一个指向内存特定位置的指针,当用户程序申请内存时,分配器只需要检查剩余的空闲内存、返回分配的内存区域并修改指针在内存中的位置,即移动下图中的指针:
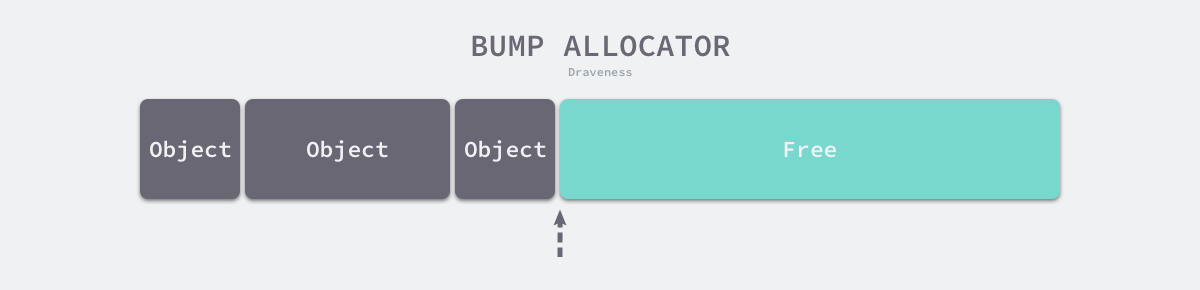
根据线性分配器的原理,可以推测它有较快的执行速度,以及较低的实现复杂度;但是线性分配器无法在内存被释放时重用内存。如下图所示,如果已经分配的内存被回收,线性分配器是无法重新利用红色的这部分内存的:
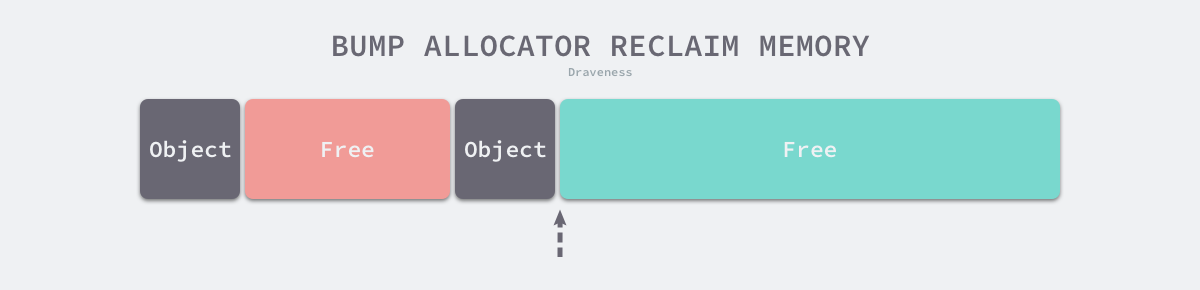
正是因为线性分配器的这种特性,所以需要合适的垃圾回收算法配合使用。标记压缩(Mark-Compact)、复制回收(Copying GC)和分代回收(Generational GC)等算法可以通过拷贝的方式整理存活对象的碎片,将空闲内存定期合并,这样就能利用线性分配器的效率提升内存分配器的性能了。
因为线性分配器的使用需要配合具有拷贝特性的垃圾回收算法,所以 C 和 C++ 等需要直接对外暴露指针的语言就无法使用该策略。
空闲链表分配
空闲链表分配器(Free-List Allocator)可以重用已经被释放的内存,它在内部会维护一个类似链表的数据结构。在一个最简单的内存管理中,堆内存最初会是一个完整的大块,即未分配内存。当用户程序申请内存时,就会从未分配内存,分割出一个小内存块(block),然后用链表把所有内存块连接起来。此时需要一些信息描述每个内存块的基本信息,比如大小(size)、是否使用中(used)和下一个内存块的地址(next),内存块实际数据存储在 data 中。如果之前已经分配过,空闲链表分配器会依次遍历空闲的内存块,找到足够大的内存,然后申请新的资源并修改链表:
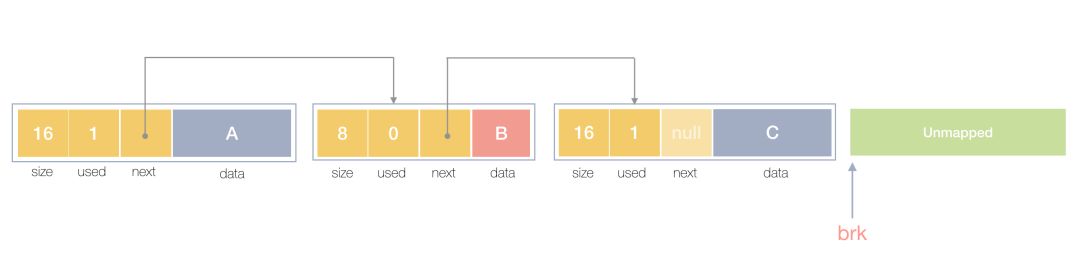
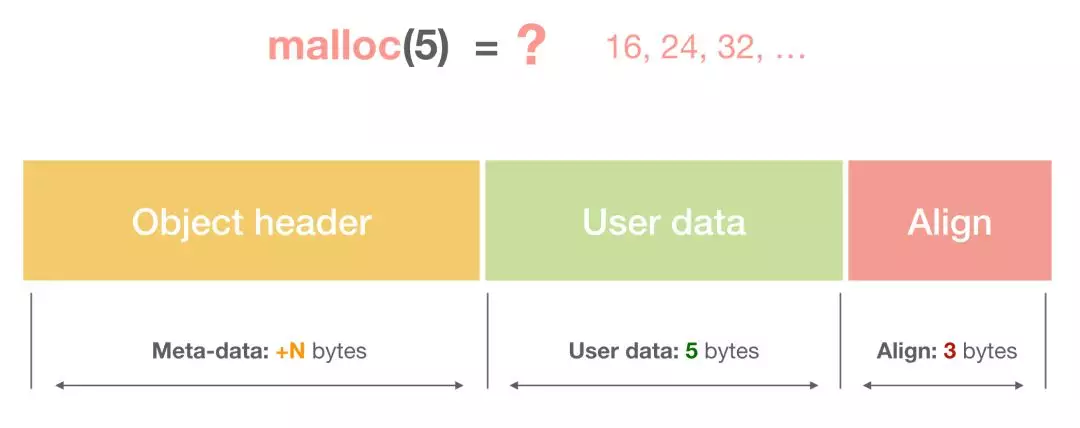
一个内存块包含了 3 类信息,如下图所示,分别是元数据、用户数据和对齐字段,内存对齐是为了提高访问效率。下图申请 5 Byte 内存的时候,就需要进行内存对齐:
因为不同的内存块以链表的方式连接,所以使用这种方式分配内存的分配器可以重新利用回收的资源,但是因为分配内存时需要遍历链表,所以它的时间复杂度就是 𝑂(𝑛)。空闲链表分配器可以选择不同的策略在链表中的内存块中进行选择,最常见的就是以下四种方式:
- 首次适应(First-Fit)— 从链表头开始遍历,选择第一个大小大于申请内存的内存块;
- 循环首次适应(Next-Fit)— 从上次遍历的结束位置开始遍历,选择第一个大小大于申请内存的内存块;
- 最优适应(Best-Fit)— 从链表头遍历整个链表,选择最合适的内存块;
- 隔离适应(Segregated-Fit)— 将内存分割成多个链表,每个链表中的内存块大小相同,申请内存时先找到满足条件的链表,再从链表中选择合适的内存块
Go 中使用的管理方式跟第四种有些相似,该策略会将内存分割成由 4、8、16、32 字节的内存块组成的链表,当向内存分配器申请 8 字节的内存时,会在下图中的第二个链表找到空闲的内存块并返回。隔离适应的分配策略减少了需要遍历的内存块数量,提高了内存分配的效率。
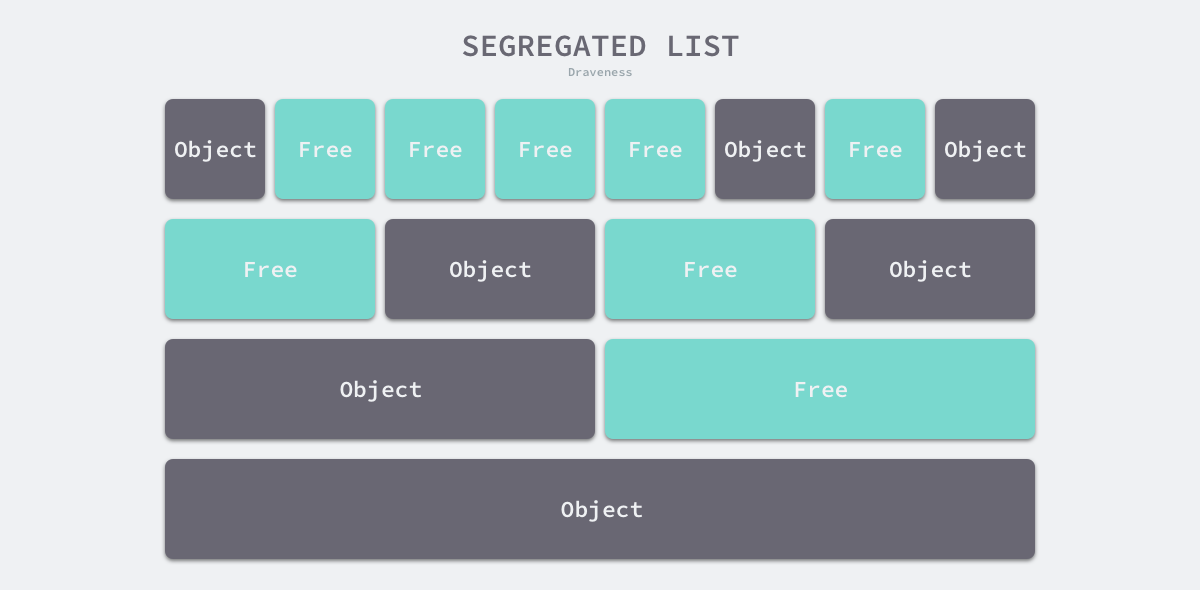
Go 堆内存管理
TCMalloc
TCMalloc 是 Thread Cache Malloc 的简称,是 Go 内存管理的起源,Go 的内存管理是借鉴了 TCMalloc,随着 Go 的迭代,Go 的内存管理与 TCMalloc 不一致地方在不断扩大,但其主要思想、原理和概念都是和 TCMalloc 一致的。
在 Linux 里,其实有不少的内存管理库,比如 glibc 的 ptmalloc,FreeBSD 的 jemalloc,Google 的 tcmalloc 等等,本质都是在多线程编程下,追求更高内存管理效率:更快的分配是主要目的。
那如何更快的分配内存?可以从三个层次来说明。
前面提到:
引入虚拟内存后,让内存的并发访问问题的粒度从多进程级别,降低到多线程级别。
这是更快分配内存的第一个层次。
同一进程的所有线程共享相同的内存空间,他们申请内存时需要加锁,如果不加锁就存在同一块内存被 2 个线程同时访问的问题。
TCMalloc 的做法是为每个线程预分配一块缓存,线程申请小内存时,可以从缓存分配内存,这样有 2 个好处:
- 为线程预分配缓存需要进行 1 次系统调用,后续线程申请小内存时,从缓存分配,都是在用户态执行,没有系统调用,缩短了内存总体的分配和释放时间,这是快速分配内存的第二个层次。
- 多个线程同时申请小内存时,从各自的缓存分配,访问的是不同的地址空间,无需加锁,把内存并发访问的粒度进一步降低了,这是快速分配内存的第三个层次。
TCMalloc 基本原理
TCMalloc 的基本原理如下图所示:

在 TCMalloc 中,有几个重要概念:
Page:操作系统对内存管理以页为单位,TCMalloc 也是这样,只不过 TCMalloc 里的 Page 大小与操作系统里的大小并不一定相等,而是倍数关系。《TCMalloc解密》里称 x64 下 Page 大小是 8KB。
Span:一组连续的 Page 被称为 Span,比如可以有 2 个页大小的 Span,也可以有 16 页大小的 Span,Span 比 Page 高一个层级,是为了方便管理一定大小的内存区域,Span 是 TCMalloc 中内存管理的基本单位。
ThreadCache:每个线程各自的 Cache,一个 Cache 包含多个空闲内存块链表,每个链表连接的都是内存块,不同的链表上的内存块大小可能是不相同的,而同一个链表上内存块的大小是相同的,也可以说按内存块大小,给内存块分了个类,这样可以根据申请的内存大小,快速从合适的链表选择空闲内存块。由于每个线程有自己的 ThreadCache,所以 ThreadCache 访问是无锁的。
CentralCache:是所有线程共享的缓存,也是保存的空闲内存块链表,链表的数量与 ThreadCache 中链表数量相同,当 ThreadCache 内存块不足时,可以从 CentralCache 取,当 ThreadCache 内存块多时,可以放回 CentralCache。由于 CentralCache 是共享的,所以它的访问是要加锁的。
PageHeap:PageHeap 是堆内存的抽象,PageHeap 存的也是若干链表,链表保存的是 Span,当 CentralCache 没有内存的时,会从 PageHeap 取,把 1 个 Span 拆成若干内存块,添加到对应大小的链表中,当 CentralCache 内存多的时候,会放回 PageHeap。如下图,分别是 1 页 Page 的 Span 链表,2 页 Page 的 Span 链表等,最后是 large span set,这个是用来保存中大对象的。毫无疑问,PageHeap 也是要加锁的。

上面提到的小、中、大对象,在 Go 内存管理中也有类似的概念,TCMalloc 中对于对象大小的定义是:
- 小对象大小:0~256KB
- 中对象大小:257~1MB
- 大对象大小:>1MB
小对象的分配流程:ThreadCache -> CentralCache -> HeapPage,大部分时候,ThreadCache 缓存都是足够的,不需要去访问 CentralCache 和 HeapPage,无锁分配加无系统调用,分配效率是非常高的。
中对象分配流程:直接在 PageHeap 中选择适当的大小即可,128 Page 的 Span 所保存的最大内存就是1MB。
大对象分配流程:从 large span set 选择合适数量的页面组成 span,用来存储数据。
Go 堆内存管理的实现
Go 内存管理源自 TCMalloc,但它比 TCMalloc 还多了 2 件东西:逃逸分析和垃圾回收,这两项也大大提高了 Go 的生产力。
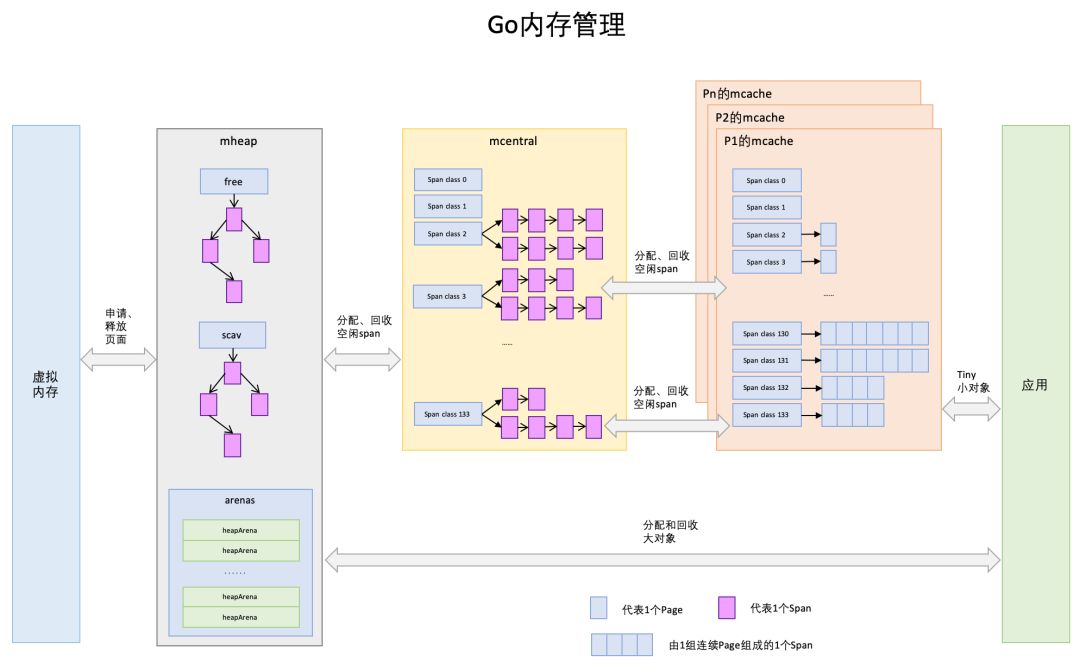
Go 内存管理的基本概念
Go 内存管理的许多概念在 TCMalloc 中已经有了,含义是相同的,只是名字有一些变化。下面是 Go 内存管理的原理图:
Page
与 TCMalloc 中的 Page 相同,x64 下 1 个 Page 的大小是 8KB。上图的最下方,1 个浅蓝色的长方形代表 1 个Page。
Span
与TCMalloc中的Span相同,Span是内存管理的基本单位,代码中为mspan,一组连续的Page组成1个Span,所以上图一组连续的浅蓝色长方形代表的是一组Page组成的1个Span,另外,1个淡紫色长方形为1个Span。
mcache
mcache 与 TCMalloc 中的 ThreadCache 类似,mcache 保存的是各种大小的 Span,并按 Span class 分类,小对象直接从 mcache 分配内存,它起到了缓存的作用,并且可以无锁访问。
但 mcache 与 ThreadCache 也有不同点,TCMalloc 中是每个线程 1 个 ThreadCache,Go 中是每个 P 拥有 1 个 mcache,因为在 Go 程序中,当前最多有 GOMAXPROCS 个线程在运行,所以最多需要 GOMAXPROCS 个 mcache 就可以保证各线程对 mcache 的无锁访问,线程的运行又是与 P 绑定的,把 mcache 交给 P 刚刚好。
mcentral
mcentral 与 TCMalloc 中的 CentralCache 类似,是所有线程共享的缓存,需要加锁访问,它按 Span class 对 Span 分类,串联成链表,当 mcache 的某个级别 Span 的内存被分配光时,它会向 mcentral 申请 1 个当前级别的 Span。
但 mcentral 与 CentralCache 也有不同点,CentralCache 是每个级别的 Span 有1个链表,mcache 是每个级别的 Span 有 2 个链表, 这和 mcache 申请内存有关。
在代码实现层面,mcentral 实际上是被 mheap 所持有的,是 mheap 结构体中的一个字段,这里是从物理含义层面把它们区分开来。
mheap
mheap 与 TCMalloc 中的 PageHeap 类似,它是堆内存的抽象,把从 OS 申请出的内存页组织成 Span,并保存起来。当 mcentral 的 Span 不够用时会向 mheap 申请,mheap 的 Span 不够用时会向 OS 申请,向 OS 的内存申请是按页来的,然后把申请来的内存页生成 Span 组织起来,同样也是需要加锁访问的。
但 mheap 与 PageHeap 也有不同点:mheap 把 Span 组织成了树结构,而不是链表,并且还是 2 棵树,然后把 Span 分配到 heapArena 进行管理,它包含地址映射和 span 是否包含指针等位图,这样做的主要原因是为了更高效的利用内存:分配、回收和再利用。
mheap 里保存了 2 棵二叉排序树,按 span 的 page 数量进行排序:
free:free 中保存的 span 是空闲并且非垃圾回收的 span。scav:scav 中保存的是空闲并且已经垃圾回收的 span。
如果是垃圾回收导致的 span 释放,span 会被加入到 scav,否则加入到 free,比如刚从 OS 申请的的内存也组成的 Span。
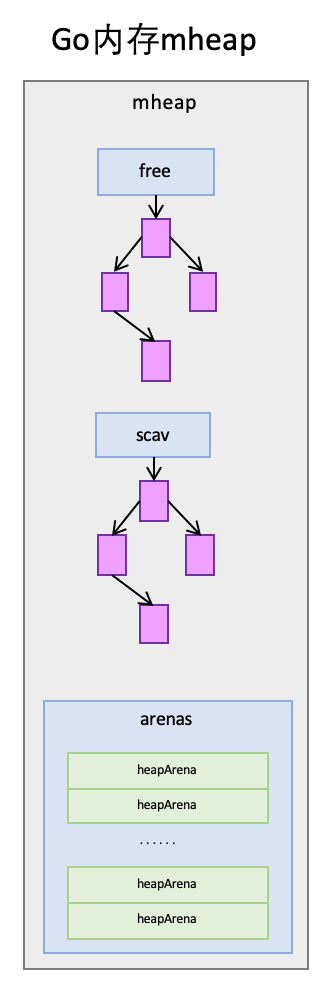
mheap 中还有 arenas,由一组 heapArena 组成,每一个 heapArena 都包含了连续的 pagesPerArena 个 span,这个主要是为 mheap 管理 span 和垃圾回收服务。
mheap 本身是一个全局变量,它其中的数据,也都是从 OS 直接申请来的内存,并不在 mheap 所管理的那部分内存内。
heapArena
Go 采用了稀疏内存管理,堆区的所有内存可能为不连续的,go 将堆区内存视为一个个内存块,每一个内存块的大小为 64MB,并使用 heapArena 结构进行管理。也就是说,每一个 heapArena 会管理 64 MB 的内存空间。在 mheap 全局结构中维护 heapArena 的指针数组,大小为 4M,这使 go 能管理 256 TB 的内存。
heapArena 结构中的成员变量如下:
type heapArena struct {
bitmap [heapArenaBitmapBytes]byte
spans [pagesPerArena]*mspan
pageInUse [pagesPerArena / 8]uint8
pageMarks [pagesPerArena / 8]uint8
zeroedBase uintptr
}
- bitmap :bitmap 区域标识 arena 区域哪些地址保存了对象,并且用 4bit 标志位表示对象是否包含指针、GC 标记信息。bitmap 中一个 byte 大小的内存对应 arena 区域中 4 个指针大小(指针大小为 8B )的内存,也就是每 2 bit 管理一个 8Byte(x64 平台下的指针大小)的指针,低 4 位为这四个指针大小数据是否为指针,高 4 位为 gc 扫描时是否需要继续往后扫描,主要用于 GC
- spans:mspan 数组,go 语言中会为每一页指定一个 mspan 结构用来管理(每页大小为 8KB),所以数组大小为 64MB /8KB=8192 (每一个 heapArena 管理 64 MB 内存)
- pageInUse,pageMarks:pages gc 使用的字段,
pageInUse表示相关的页的状态为mSpanInUse(GC 负责垃圾回收,与之相对的是 goroutine 的栈内存,由栈管理),pages表示相关页是否存在有效对象(在 gc 扫描中被标记),用来加速内存回收。 - zeroedBase:用来加速第一次分配,一开始为0,标记该 arena 的第一页的第一个字节尚未使用过,随着内存的分配逐渐递增直到
heapArenaBitmapBytes,换句话说,它标记了该 arena 已经分配到了哪个位置。
大小转换
除了以上内存块组织概念,还有几个重要的大小概念,它们是内存分配、组织和地址转换的基础。
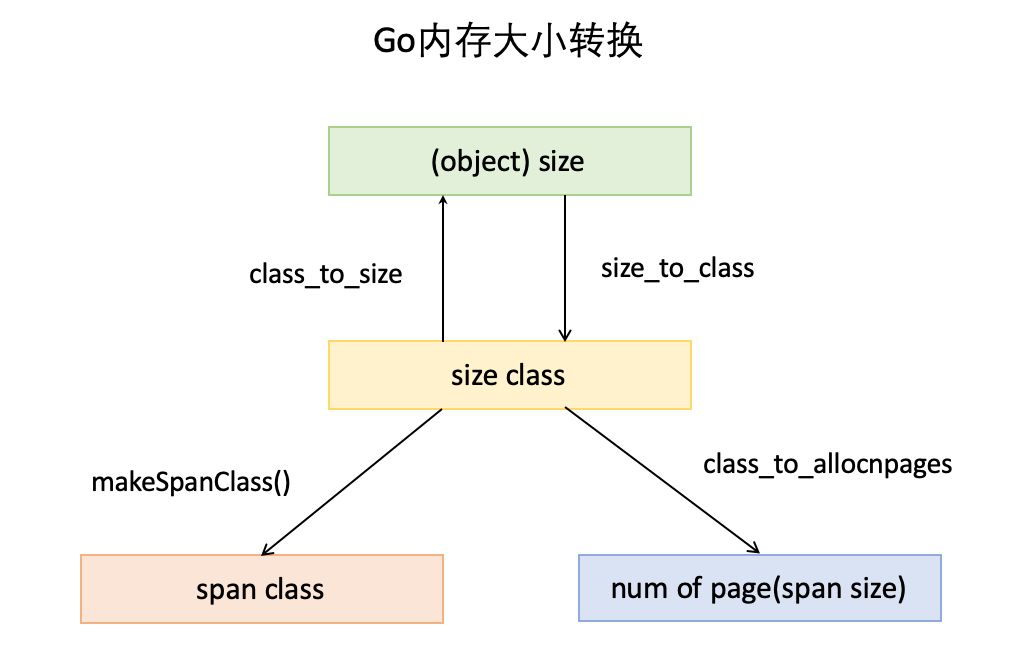
- object size:代码里简称
size,指申请内存的对象的实际大小。 - size class:代码里简称
class,它表示 size 的级别,相当于把 size 归类到一定大小的区间段,比如size[1,8]属于size class 1,size(8,16]属于size class 2。 - span class:跨度类,指 span 的级别,但 span class 的大小与 span 的大小并没有正比关系。span class 主要用来和 size class 做对应,1 个 size class 对应 2 个 span class,2 个 span class 的 span 大小相同,只是功能不同,1 个用来存放包含指针的对象,一个用来存放不包含指针的对象,不包含指针对象的 Span 就无需GC扫描了。
- num of page:代码里简称
npage,代表 Page 的数量,其实就是 Span 包含的页数,用来分配内存。
Go 语言的内存管理模块中一共包含 67 种跨度类(span class),每一个跨度类都会存储特定大小的对象并且包含特定数量的页数以及对象,所有的数据都会被预选计算好并存储在变量中。
下表展示了跨度类和其他 size 之间的映射关系,从左到右前四列对应的就是 size class、obj size、span size 和 num of objects:
截图代码在
runtime.sizeclasses.go下
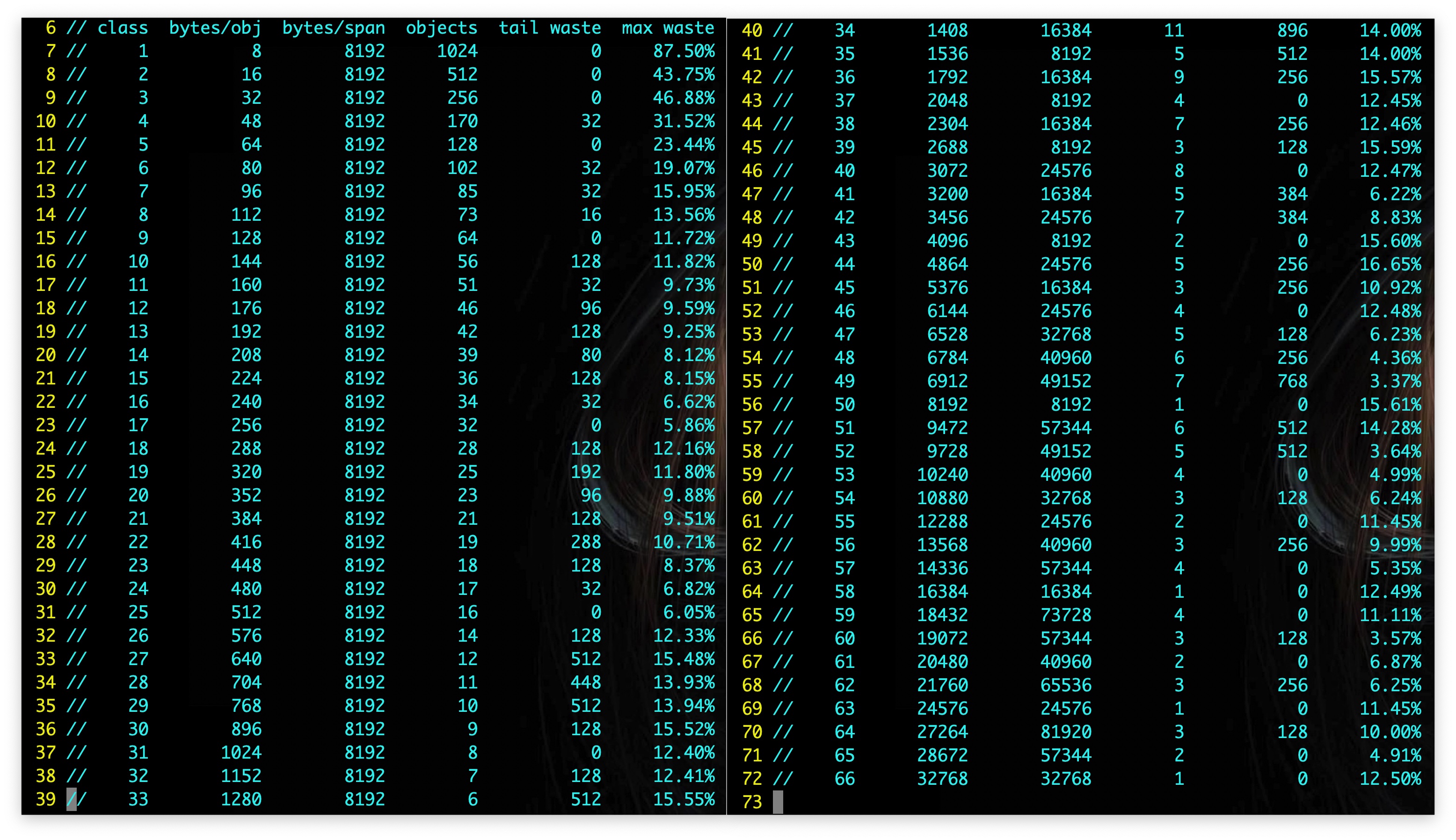
在实现中,会根据前 3 列做 size、size class 和 num of page 之间的转换。
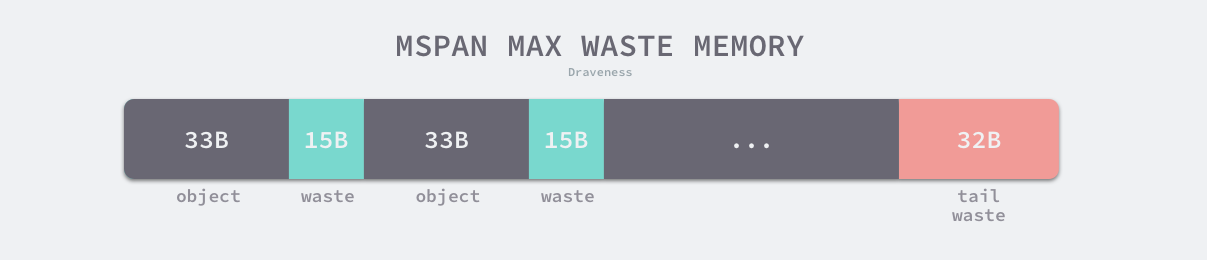
另外,第4列 num of objects 代表是当前 size class 级别的 Span 可以保存多少对象数量,第 5 列 tail waste 是 span%obj 计算的结果,表示尾部会浪费多少字节的内存,因为 span 的大小并不一定是对象大小的整数倍。最后一列 max waste 代表最大浪费的内存百分比。
以上图中的第四个跨度类为例,跨度类为 4 的 span class 中对象的大小上限为 48 字节、管理 1 个页、最多可以存储 170 个对象。因为内存需要按照页进行管理,所以在尾部会浪费 32 字节的内存,当页中存储的对象都是 33 字节时(满足存储在第 4 类的类大小的最低阈值),最多会浪费 31.52% 的资源:
$$
\frac{(48−33)∗170+32}{8192}=0.31518
$$
此外,运行时中还包含 ID 为 0 的特殊跨度类,它能够管理大于 32KB 的特殊对象,用于分配大对象。
在 Go 内存大小转换那幅图中已经标记各大小之间的转换,分别是数组:class_to_size,size_to_class 和 class_to_allocnpages,这 3 个数组内容,就是跟上表的映射关系匹配的。比如 class_to_size,从上表看 class 1对应的保存对象大小为 8,所以 class_to_size[1]=8,span 大小为 8192 Byte,即 8KB,为 1 页,所以 class_to_allocnpages[1]=1。
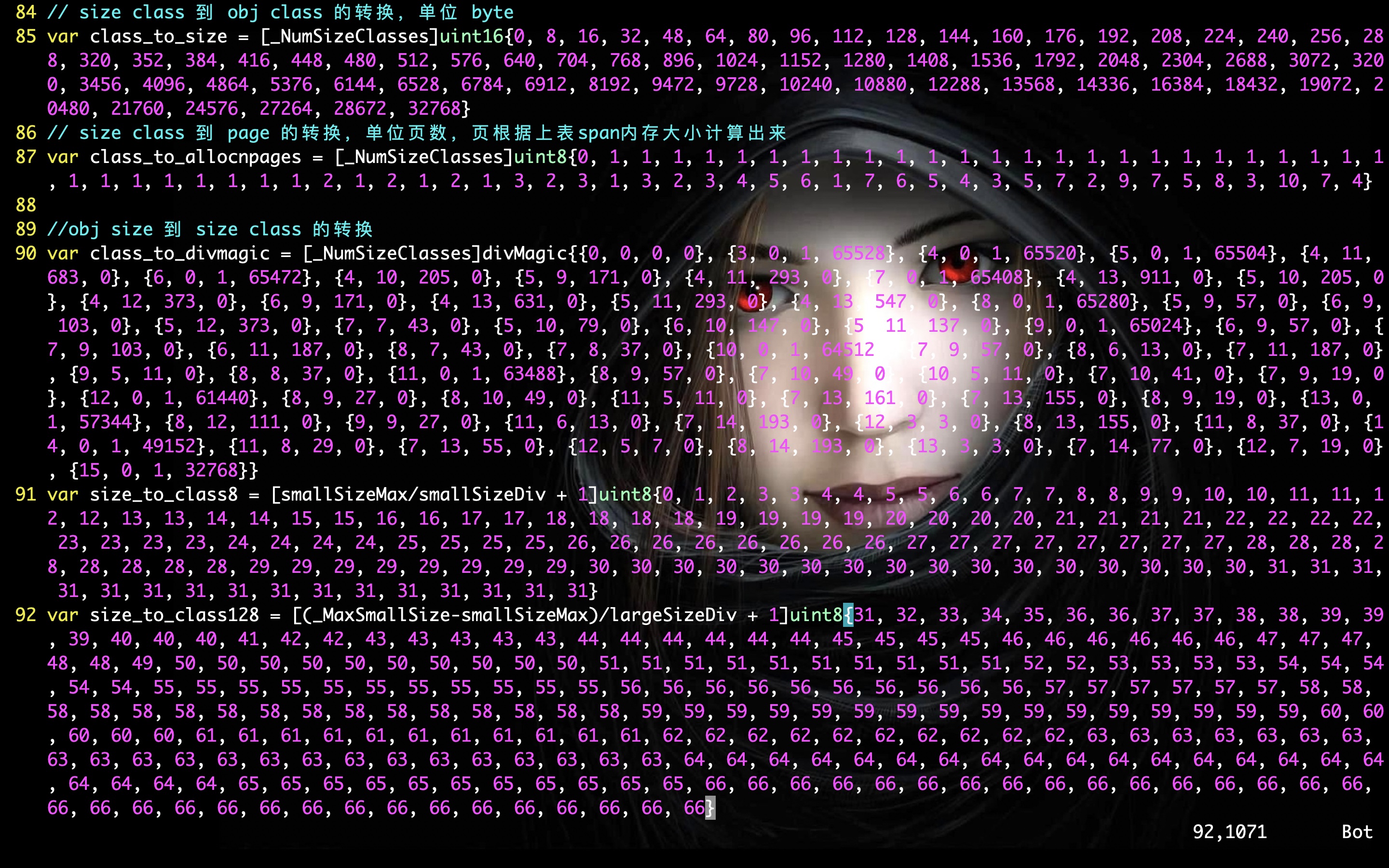
为何不使用函数计算各种转换,而是写成数组?
有1个很重要的原因:空间换时间。上表中的转换,并不能通过简单的公式进行转换,比如 size 和 size class 的关系,并不是正比的。这些数据是使用较复杂的公式计算出来的,公式在 makesizeclass.go 中,这其中存在指数运算与 for 循环,造成每次大小转换的时间复杂度为 O(N*2^N)。另外,对一个程序而言,内存的申请和管理操作是很多的,如果不能快速完成,就是非常的低效。把以上大小转换写死到数组里,做到了把大小转换的时间复杂度直接降到 O(1)。
Go 内存分配具体过程
Go 中的内存分类并不像 TCMalloc 那样分成小、中、大对象,而是分为微对象、小对象和大对象。
| 类别 | 大小 |
|---|---|
| 微对象 | (0, 16B) |
| 小对象 | [16B, 32KB] |
| 大对象 | (32KB, +∞) |
整体来说,微对象和小对象是在 mcache 中分配的,而大对象是直接从 mheap 分配。
微对象的分配
微对象是在 mcache 中的微分配器分配的。在线程缓存 mcache 中还包含几个用于分配微对象的字段,这几个字段组成了微对象分配器,专门为 16 字节以下的对象申请和管理内存:
type mcache struct {
tiny uintptr
tinyoffset uintptr
local_tinyallocs uintptr
}
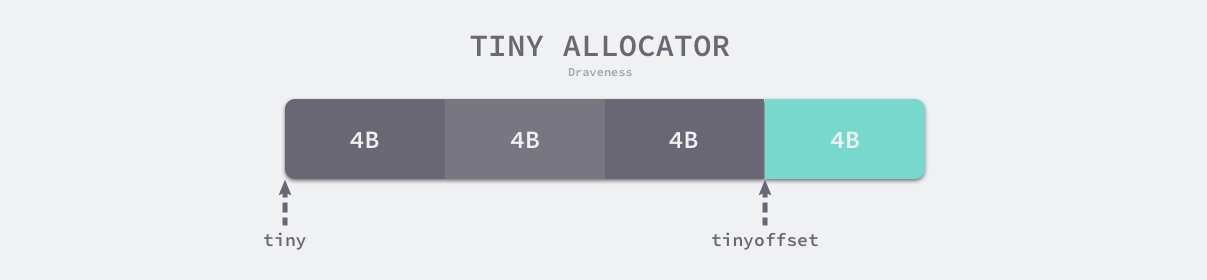
微分配器只会用于分配非指针类型的内存,上面三个字段中 tiny 会指向堆中的一片内存,tinyOffset 是下一个空闲内存所在的偏移量,最后的 local_tinyallocs 会记录内存分配器中分配的对象个数。
微对象的分配会使用线程缓存上的微分配器提高微对象分配的性能,主要使用它来分配较小的字符串以及逃逸的临时变量。微分配器可以将多个较小的内存分配请求合入同一个内存块中,只有当内存块中的所有对象都需要被回收时,整片内存才可能被回收。
微分配器管理的对象不可以是指针类型,管理多个对象的内存块大小可以通过变量 maxTinySize 调整,在默认情况下,内存块的大小为 16 字节。maxTinySize 的值越大,组合多个对象的可能性就越高,内存浪费也就越严重;maxTinySize 越小,内存浪费就会越少,不过无论如何调整,8 的倍数都是一个很好的选择。
如下图所示,微分配器已经在 16 字节的内存块中分配了 12 字节的对象,如果下一个待分配的对象小于 4 字节,它就会直接使用内存块的剩余部分,减少内存碎片,不过该内存块只有在所有个对象都被标记为垃圾时才会被回收。
小对象的分配
根据上面的跨度类映射表,size class 从 1 到 66 共 66 个,代码中_NumSizeClasses=67代表了实际使用的 size class 数量,即 67 个,从 0 到66。size class 0 用于管理大于 32KB 的特殊对象,用于分配大对象,在小对象分配不会用到。
重新看一下 Go 内存管理的原理图:
每一个线程缓存都持有 67 * 2 个 mspan,也就是上文提到 1 个 size class 对应 2 个span class:
numSpanClasses = _NumSizeClasses * 2
numSpanClasses 为 span class 的数量,也就是 134 个,所以 span class 的下标是从 0 到 133,所以图中 mcache 标注了的 span class 是span class 0 到 span class 133。每 1 个 span class 都指向 1 个 span,也就是 mcache 最多有134个span。
为对象寻找 span
为对象寻找 span 的流程如下:
- 计算对象所需内存大小 size
- 根据 size 到 size class 映射,计算出所需的 size class
- 根据 size class 和对象是否包含指针计算出 span class
- 获取该 span class 指向的 span。
以分配一个不包含指针的,大小为 24 Byte 的对象为例。
根据映射表:
// class bytes/obj bytes/span objects tail waste max waste
// 1 8 8192 1024 0 87.50%
// 2 16 8192 512 0 43.75%
// 3 32 8192 256 0 46.88%
// 4 48 8192 170 32 31.52%
size class 3,它的对象大小范围是 (16,32]Byte,24 Byte 刚好在此区间,所以此对象的 size class 为 3。
Size class 到 span class 的计算如下:
1// noscan 为 true 代表对象不包含指针
2func makeSpanClass(sizeclass uint8, noscan bool) spanClass {
3 return spanClass(sizeclass<<1) | spanClass(bool2int(noscan))
4}
所以,对应的 span class 为:
span class = 3 << 1 | 1 = 7
所以该对象需要的是 span class 7 指向的 span。
从 span 分配对象空间
Span 可以按对象大小切成很多份,这些都可以从映射表上计算出来,以 size class 3 对应的 span 为例,span 大小是 8KB,每个对象实际所占空间为 32Byte,这个 span 就被分成了256块,可以根据 span 的起始地址计算出每个对象块的内存地址。
随着内存的分配,span中的对象内存块,有些被占用,有些未被占用,比如下图,整体代表 1 个 span,蓝色块代表已被占用内存,绿色块代表未被占用内存。

当分配内存时,只要快速找到第一个可用的绿色块,并计算出内存地址即可,如果需要还可以对内存块数据清零。
span 没有空间怎么分配对象
span 内的所有内存块都被占用时,没有剩余空间继续分配对象,mcache 会向 mcentral 申请 1 个 span, mcache 拿到 span 后继续分配对象。
mcentral 向 mcache 提供 span
mcentral 和 mcache 一样,都是 0~133 这 134 个 span class 级别,但每个级别都保存了 2 个 span list,即 2 个 span 链表:
nonempty:这个链表里的 span,所有 span 都至少有 1 个空闲的对象空间。这些 span 是 mcache 释放 span 时加入到该链表的。empty:这个链表里的 span,所有的 span 都不确定里面是否有空闲的对象空间。当一个 span 交给 mcache 的时候,就会加入到 empty 链表。
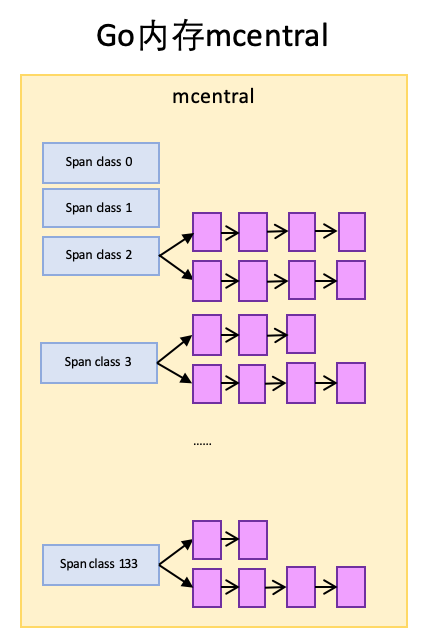
实际代码中每 1 个 span class 对应 1 个 mcentral,图里把所有 mcentral 抽象成 1 个整体了。
mcache 向 mcentral 要 span 时,mcentral会先从 nonempty 搜索满足条件的 span,如果没找到再从 emtpy搜索满足条件的 span,然后把找到的 span 交给 mcache。
在两个链表中都没有找到可用的内存单元,它会触发扩容操作从堆中申请新的内存。
mcentral 向 mheap 要 span
mcentral 向 mcache 提供 span 时,如果 emtpy 里也没有符合条件的 span,mcentral 会向 mheap 申请 span。
mcentral 需要向 mheap 提供需要的内存页数和 span class 级别,然后它优先从 free 中搜索可用的 span,如果没有找到,会从 scav 中搜索可用的 span,如果还没有找到,它会向 OS 申请内存,再重新搜索 2 棵树,必然能找到 span。如果找到的 span 比需求的 span 大,则把 span 进行分割成 2 个 span,其中 1 个刚好是需求大小,把剩下的 span 再加入到 free 中去,然后设置需求 span 的基本信息,然后交给 mcentral。
mheap向OS申请内存
当 mheap 没有足够的内存时,mheap 会向 OS 申请内存,把申请的内存页保存到 span,然后把 span 插入到 free 树 。
在 32 位系统上,mheap 还会预留一部分空间,当 mheap 没有空间时,先从预留空间申请,如果预留空间内存也没有了,才向 OS 申请。
大对象的分配
对于大对象会单独处理,不会从线程缓存或者中心缓存中获取内存管理单元,而是直接在系统的栈中调用 runtime.largeAlloc 函数分配大片的内存。
总结
下图展示了 go 内存中所有结构的关系:
heap 最中间的灰色区域 arena 覆盖了 Go 程序的整个虚拟内存, 每个 arena 包括一段 bitmap 和一段指向连续 span 的指针; 每个 span 由一串连续的页组成;每个 arena 的起始位置通过 arenaHint 进行记录。
分配的顺序从右向左,代价也就越来越大。
小对象和微对象优先从白色区域 mcache 分配 span,这个过程不需要加锁(白色); 若失败则会从 mheap 持有的 mcentral 加锁获得新的 span,这个过程需要加锁,但只是局部(灰色); 若仍失败则会从右侧的 free 或 scav 进行分配,这个过程需要对整个 heap 进行加锁,代价最大(黑色)。
此外,内存分配中还有两个重要的思想:
- 使用缓存提高效率。在存储的整个体系中到处可见缓存的思想,Go 内存分配和管理也使用了缓存,利用缓存一是减少了系统调用的次数,二是降低了锁的粒度,减少加锁的次数,从这 2 点提高了内存管理效率。
- 以空间换时间,提高内存管理效率。空间换时间是一种常用的性能优化思想,这种思想其实非常普遍,比如Hash、Map、二叉排序树等数据结构的本质就是空间换时间,在数据库中也很常见,比如数据库索引、索引视图和数据缓存等,再如 Redis 等缓存数据库也是空间换时间的思想。
Go 垃圾回收与内存释放
如果只申请和分配内存,内存终将枯竭,Go 使用垃圾回收收集不再使用的span,调用 mspan.scavenge() 把 span 释放给 OS(并非真释放,只是告诉 OS 这片内存的信息无用了,如果 OS 需要的话可以收回去),然后交给 mheap,mheap 对 span 进行 span 的合并,把合并后的 span 加入 scav 树中,等待再分配内存时,由 mheap 进行内存再分配。这部分的工作由垃圾收集器,也就是 GC(Garbage Collection)完成的。
垃圾回收概念
垃圾回收(GC garbage collection)指的一般是自动垃圾回收(Automatic Garbage Collection),它计算机科学中是一种自动的存储器管理机制,当一个计算机上的动态存储器不再需要时,就应该予以释放,以让出存储器。这种存储器资源管理,就称为垃圾回收。本质上垃圾回收就是一个自动回收堆内存的工具。
简单地说,垃圾回收(GC)是在后台运行一个守护线程,它的作用是在监控各个对象的状态,识别并且丢弃不再使用的对象来释放和重用资源。
需要注意,GC 不负责回收栈中的内存,原因在于栈是一块专用内存,专门为了函数执行而准备的,存储着函数中的局部变量以及调用栈。除此以外,栈中的数据都有一个特点——简单。比如局部变量就不能被函数外访问,所以这块内存用完就可以直接释放。正是因为这个特点,栈中的数据可以通过简单的编译器指令自动清理,也就不需要通过 GC 来回收了。
垃圾收集算法
在垃圾回收中通过使用适当的垃圾收集算法能够提高回收效率,常见的标记算法有标记——清除算法、复制算法、标记——整理算法和分代收集算法。
go 中设计的标记算法有标记——清除算法,以及优化的三色标记法,另外还引入了屏障技术以在并发或者增量的标记算法中保证正确性。
标记——清除算法
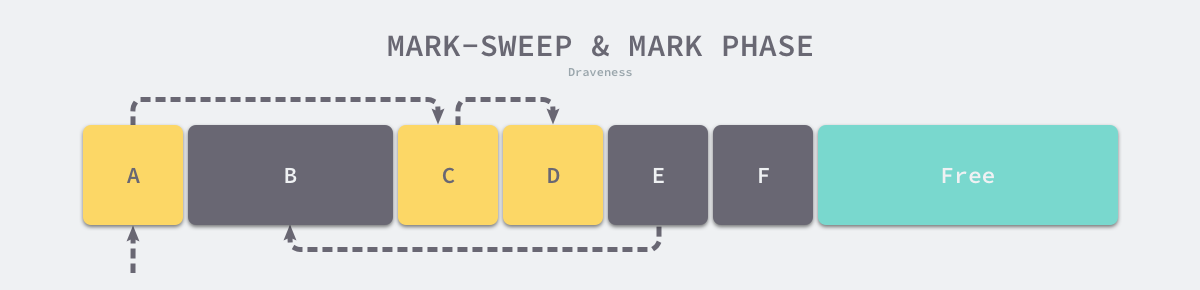
标记清除(Mark-Sweep)算法是最常见的垃圾收集算法,标记清除收集器是跟踪式垃圾收集器,其执行过程可以分成标记(Mark)和清除(Sweep)两个阶段:
- 标记阶段:从根对象出发查找并标记堆中所有存活的对象;
- 清除阶段:遍历堆中的全部对象,回收未被标记的垃圾对象并将回收的内存加入空闲链表;
如下图所示,内存空间中包含多个对象,从根对象出发依次遍历对象的子对象并将从根节点可达的对象都标记成存活状态,即 A、C 和 D 三个对象,剩余的 B、E 和 F 三个对象因为从根节点不可达,所以会被当做垃圾:
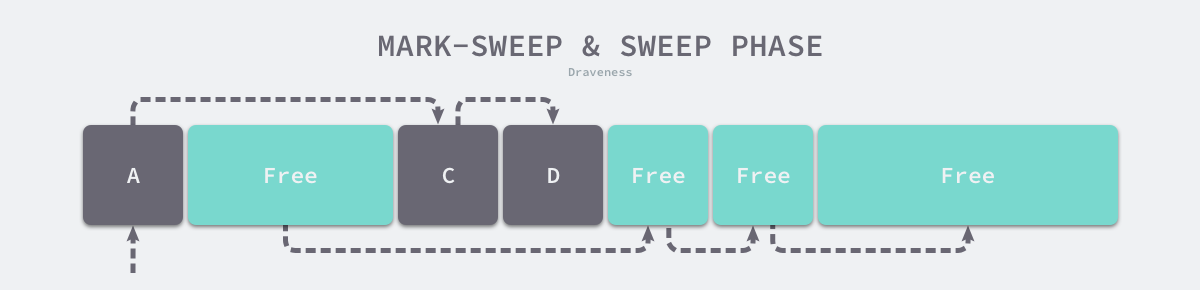
标记阶段结束后会进入清除阶段,在该阶段中收集器会依次遍历堆中的所有对象,释放其中没有被标记的 B、E 和 F 三个对象并将新的空闲内存空间以链表的结构串联起来,方便内存分配器的使用。
这是最传统的标记清除算法,垃圾收集器从垃圾收集的根对象出发,递归遍历这些对象指向的子对象并将所有可达的对象标记成存活;标记阶段结束后,垃圾收集器会依次遍历堆中的对象并清除其中的垃圾,整个过程需要标记对象的存活状态,用户程序在垃圾收集的过程中也不能执行,也就是存在 STW(stop the world)问题。
三色标记法
为了解决原始标记清除算法带来的长时间 STW,多数现代的追踪式垃圾收集器都会实现三色标记算法的变种以缩短 STW 的时间。三色标记算法将程序中的对象分成白色、黑色和灰色三类:
- 白色对象:潜在的垃圾,其内存可能会被垃圾收集器回收;
- 黑色对象:活跃的对象,包括不存在任何引用外部指针的对象以及从根对象可达的对象;
- 灰色对象:活跃的对象,因为存在指向白色对象的外部指针,垃圾收集器会扫描这些对象的子对象;
在垃圾收集器开始工作时,程序中不存在任何的黑色对象,垃圾收集的根对象会被标记成灰色,垃圾收集器只会从灰色对象集合中取出对象开始扫描,当灰色集合中不存在任何对象时,标记阶段就会结束。
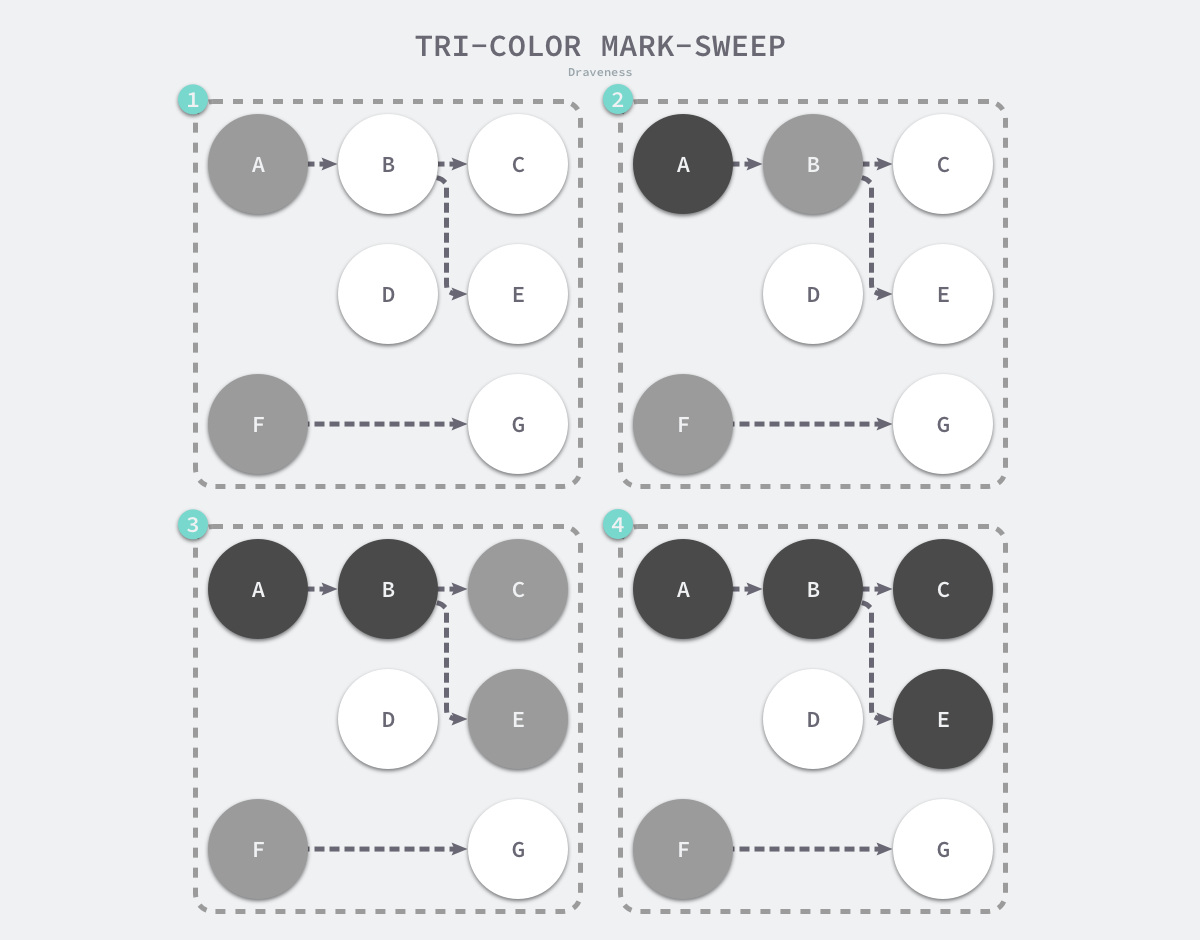
三色标记垃圾收集器的工作原理可以将其归纳成以下几个步骤:
- 从灰色对象的集合中选择一个灰色对象并将其标记成黑色;
- 将黑色对象指向的所有对象都标记成灰色,保证该对象和被该对象引用的对象都不会被回收;
- 重复上述两个步骤直到对象图中不存在灰色对象;
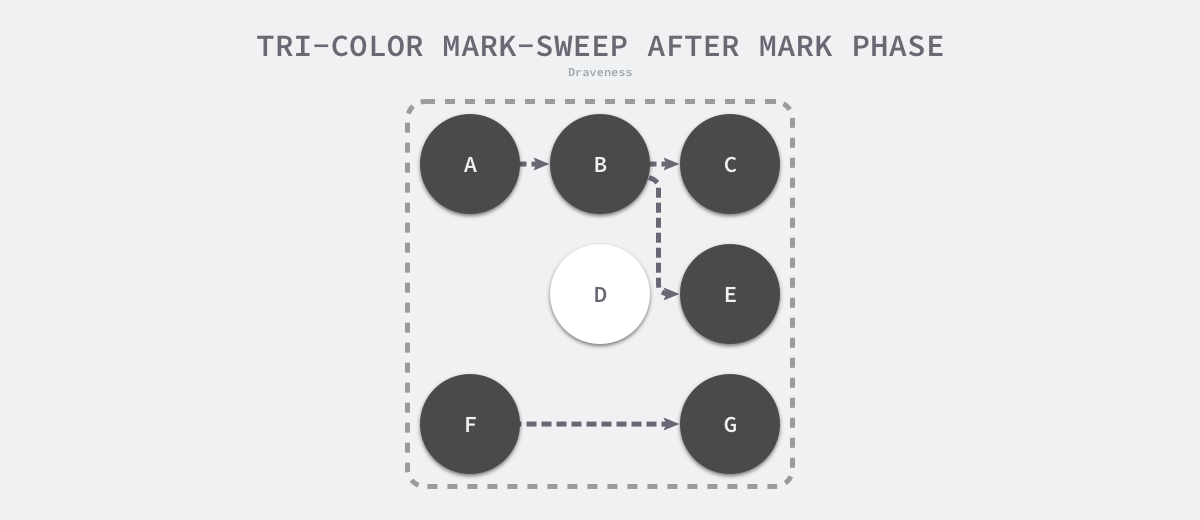
当三色的标记清除的标记阶段结束之后,应用程序的堆中就不存在任何的灰色对象,只能看到黑色的存活对象以及白色的垃圾对象,垃圾收集器可以回收这些白色的垃圾。下面是使用三色标记垃圾收集器执行标记后的堆内存,堆中只有对象 D 为待回收的垃圾:
因为用户程序可能在标记执行的过程中修改对象的指针,所以三色标记清除算法本身是不可以并发或者增量执行的,它仍然需要 STW,在如下所示的三色标记过程中,用户程序建立了从 A 对象到 D 对象的引用,但是因为程序中已经不存在灰色对象了,所以 D 对象会被垃圾收集器错误地回收。
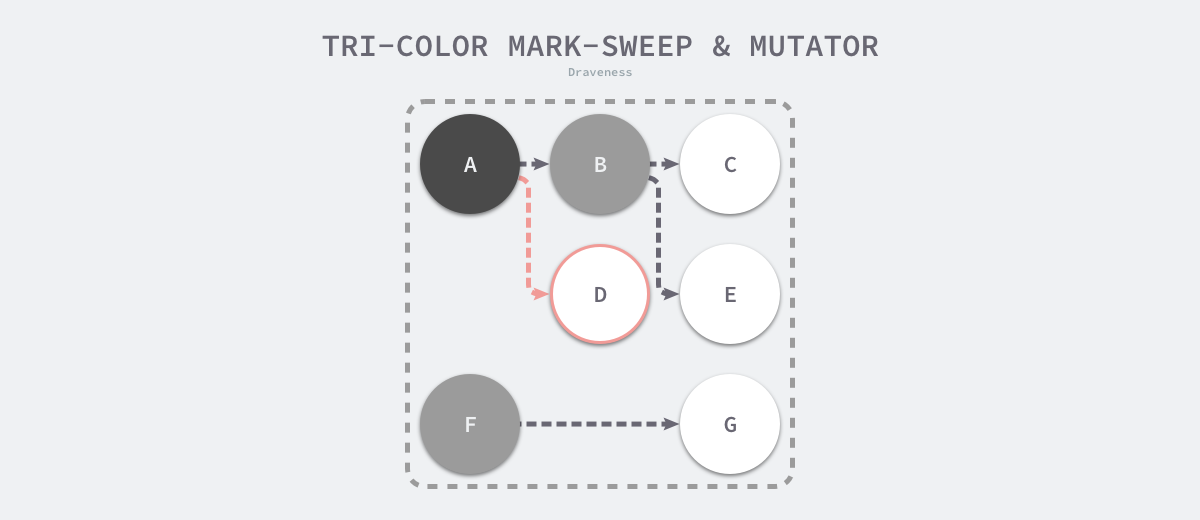
本来不应该被回收的对象却被回收了,这在内存管理中是非常严重的错误,这种错误被称为悬挂指针,即指针没有指向特定类型的合法对象,影响了内存的安全性。
如下代码示例:
var A Wb
var B Wb
type Wb struct {
Obj *int
}
func simpleSet(c *int) {
A.Obj = nil
B.Obj = c
// gc begin
// scan A
A.Obj = c
// scan B
B.Obj = nil
}
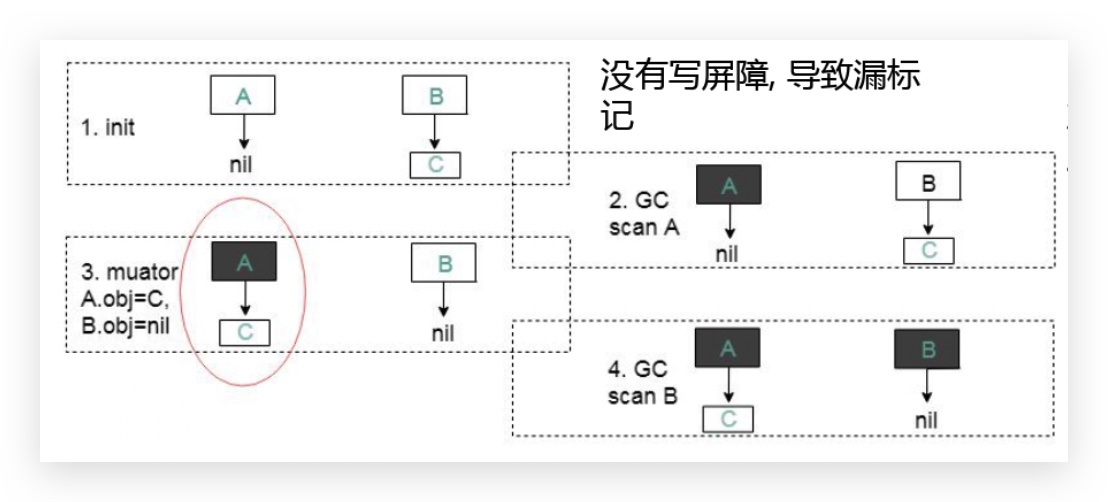
看上面的代码和图示,第2步标记完A对象, A又没有引用对象,那A变成黑色对象。在第3步的时候,把对象C从B转到了A,第4步,GC继续标记,扫描B,此时B没有引用对象,变成了黑色对象,此时就会发现C对象被漏标记了。
想要并发或者增量地标记对象还是需要使用屏障技术。
屏障技术
内存屏障技术是一种屏障指令,它可以让 CPU 或者编译器在执行内存相关操作时遵循特定的约束,目前的多数的现代处理器都会乱序执行指令以最大化性能,但是该技术能够保证代码对内存操作的顺序性,在内存屏障前执行的操作一定会先于内存屏障后执行的操作。
想要在并发或者增量的标记算法中保证正确性,需要达成以下两种三色不变性(Tri-color invariant)中的任意一种:
- 强三色不变性:黑色对象不会指向白色对象,只会指向灰色对象或者黑色对象;
- 弱三色不变性:黑色对象指向的白色对象必须包含一条从灰色对象经由多个白色对象的可达路径;
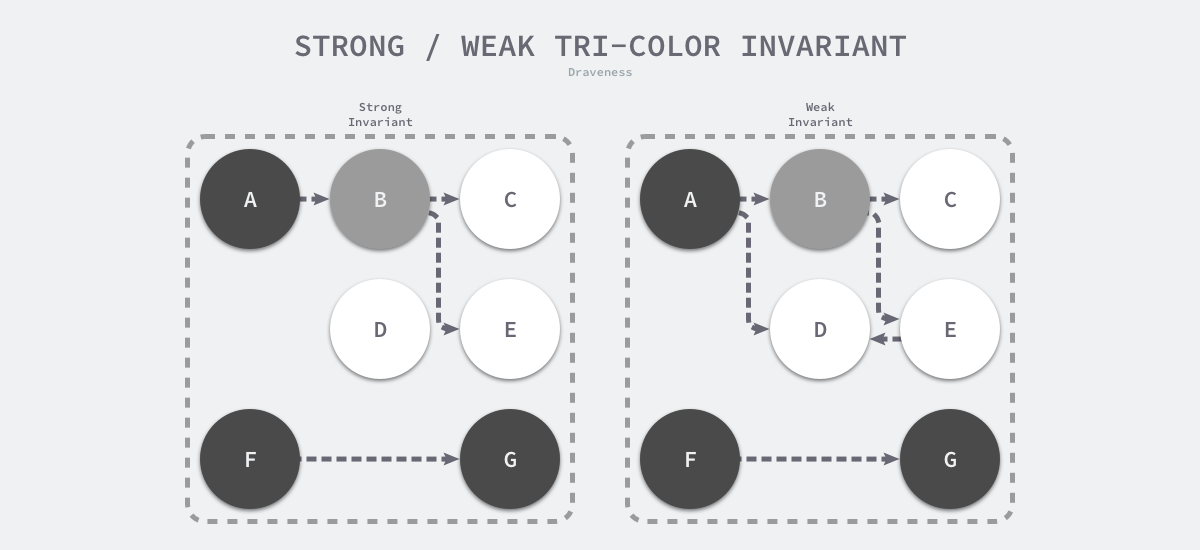
上图分别展示了遵循强三色不变性和弱三色不变性的堆内存,遵循上述两个不变性中的任意一个,都能保证垃圾收集算法的正确性,而屏障技术就是在并发或者增量标记过程中保证三色不变性的重要技术。
垃圾收集中的屏障技术更像是一个钩子方法,它是在用户程序读取对象、创建新对象以及更新对象指针时执行的一段代码,根据操作类型的不同,可以将它们分成读屏障(Read barrier)和写屏障(Write barrier)两种,因为读屏障需要在读操作中加入代码片段,对用户程序的性能影响很大,所以编程语言往往都会采用写屏障保证三色不变性。
Go 语言中使用的写屏障技术有两种,分别是 Dijkstra 提出的插入写屏障和 Yuasa 提出的删除写屏障。
插入写屏障
插入屏障(insertion barrier)技术,又称为增量更新屏障(incremental update) 。 其核心思想在赋值时对已存活的对象集合的插入行为通知给回收器,进而产生可能需要额外(重新)扫描的对象。 如果某一对象的引用被插入到已经被标记为黑色的对象中,这类屏障会保守地将其作为非白色存活对象, 以满足强三色不变性。
Dijkstra 在 1978 年提出了插入写屏障,通过如下所示的写屏障,其思想是对于插入到黑色对象中的白色指针,无论其在未来是否会被赋值器删除,该屏障都会将其标记为可达(着色)。用户程序和垃圾收集器可以在交替工作的情况下保证程序执行的正确性,下面是插入写屏障的伪代码:
writePointer(slot, ptr):
shade(ptr)
*slot = ptr
每当执行类似 *slot = ptr 的表达式时,会先执行上面写屏障通过 shade 函数尝试改变指针的颜色,如果 ptr 指针是白色的,那么该函数会将该对象设置成灰色,也就是将指针指向的目的节点标记成灰色,其他情况则保持不变。
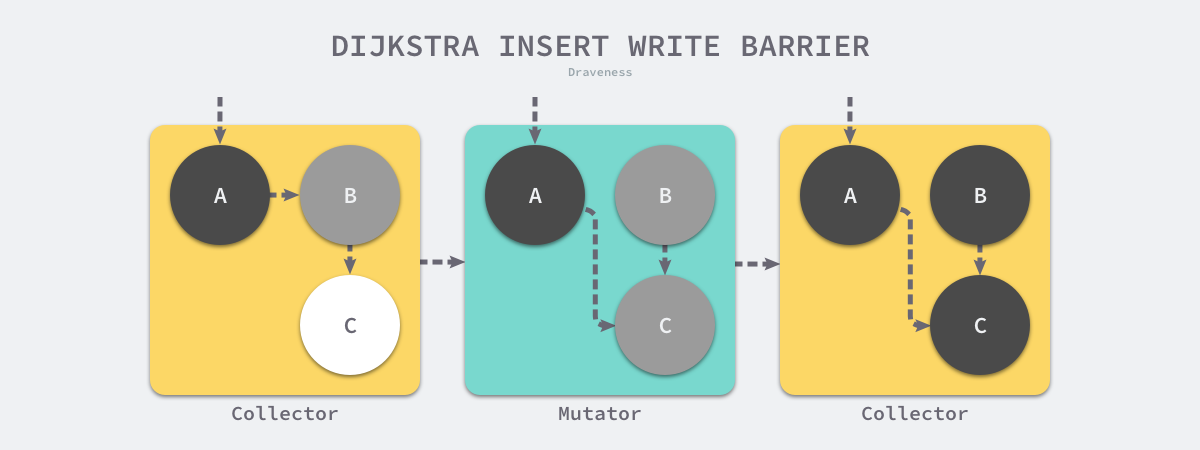
假设在应用程序中使用 Dijkstra 提出的插入写屏障,在一个垃圾收集器和用户程序交替运行的场景中会出现如上图所示的标记过程:
- 垃圾收集器将根对象指向 A 对象标记成黑色并将 A 对象指向的对象 B 标记成灰色;
- 用户程序修改 A 对象的指针,将原本指向 B 对象的指针指向 C 对象,这时触发写屏障将 C 对象标记成灰色;
- 垃圾收集器依次遍历程序中的其他灰色对象,将它们分别标记成黑色;
Dijkstra 的插入写屏障是一种相对保守的屏障技术,它会将有存活可能的对象都标记成灰色以满足强三色不变性。在如上所示的垃圾收集过程中,实际上不再存活的 B 对象最后没有被回收;而如果在第二和第三步之间将 A 指向 C 对象的指针改回指向 B,垃圾收集器仍然认为 C 对象是存活的,这些被错误标记的垃圾对象只有在下一个循环才会被回收。
插入式的 Dijkstra 写屏障虽然实现非常简单并且也能保证强三色不变性,但是它也有很明显的缺点。因为栈上的对象在垃圾收集中也会被认为是根对象(保证GC 不回收栈上的内存),所以为了保证内存的安全,**Dijkstra 必须为栈上的对象增加写屏障或者在标记阶段完成重新对栈上的对象进行扫描,这是因为在 GC 期间栈上新分配的对象如果没有进行标记,那它就是白色的对象。**这两种方法各有各的缺点,前者会大幅度增加写入指针的额外开销,后者重新扫描栈对象时需要暂停程序,垃圾收集算法的设计者需要在这两者之前做出权衡。
再举一个具体一点的例子,假设某个灰色对象 A 指向白色对象 B, 而此时并发地将黑色对象 C 指向(ref3)了白色对象 B, 并将灰色对象 A 对白色对象 B 的引用移除(ref2),那么整体过程如下:
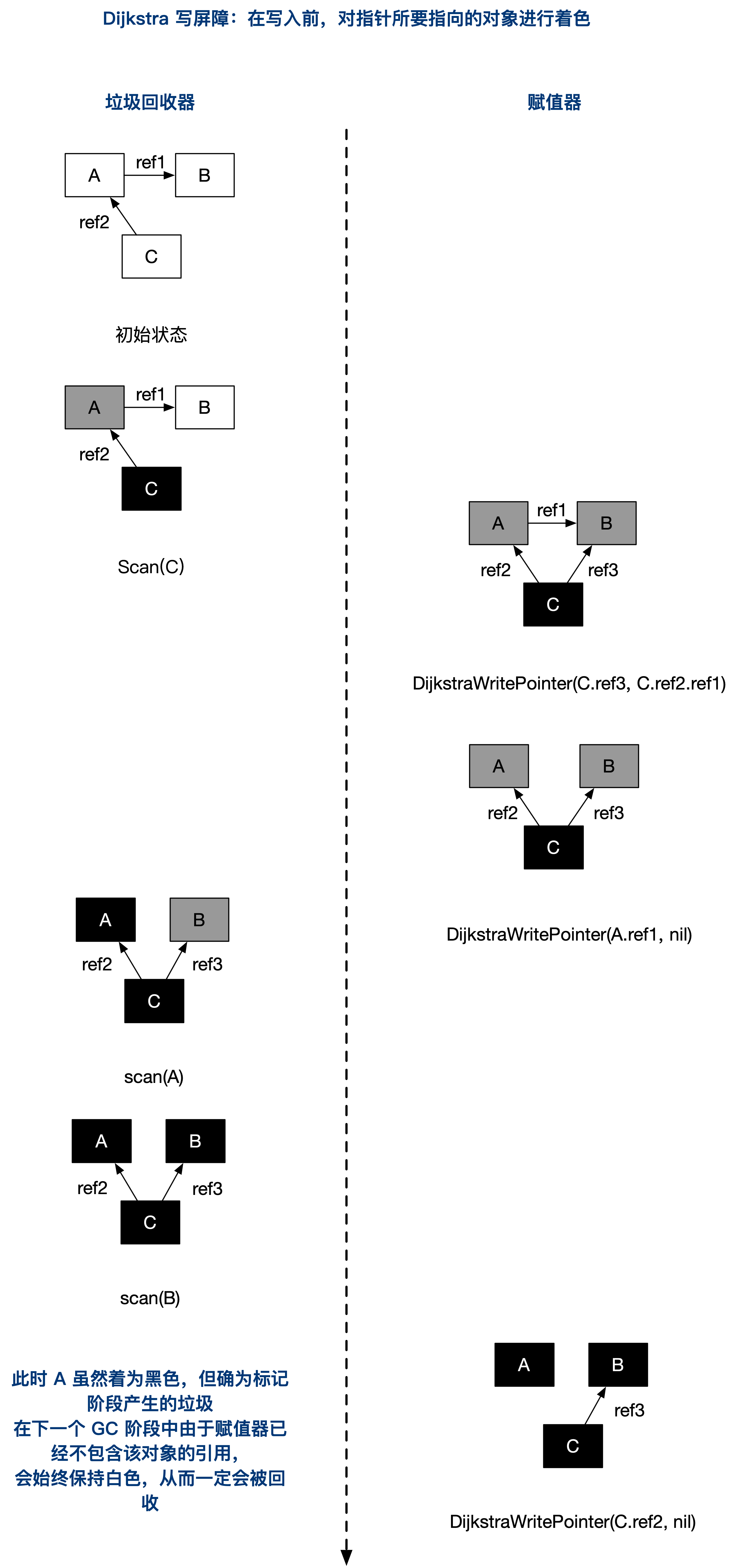
整体来说,插入写屏障的优势在于性能方面,并且实现简单,但是存在有不在存活的对象最后没有被回收以及栈上对象性能影响的问题。
删除写屏障
删除屏障(deletion barrier)技术,又称为基于起始快照的屏障(snapshot-at-the-beginning)。 其思想是当赋值器从灰色或白色对象中删除白色指针时,通过写屏障将这一行为通知给并发执行的回收器。 这一过程很像是在操纵对象图之前对图进行了一次快照。
Yuasa 在 1990 年的论文 Real-time garbage collection on general-purpose machines 中提出了删除写屏障,因为一旦该写屏障开始工作,它就会保证开启写屏障时堆上所有对象的可达,所以也被称作快照垃圾收集(Snapshot GC)。
该算法会使用如下所示的写屏障保证增量或者并发执行垃圾收集时程序的正确性:
writePointer(slot, ptr)
shade(*slot)
*slot = ptr
shade(*slot) 会先将 *slot 标记为灰色, 进而该写操作总是创造了一条灰色到灰色或者灰色到白色对象的路径,从而满足弱三色不变性。
假设在应用程序中使用 Yuasa 提出的删除写屏障,还是用上面的例子:
假设某个灰色对象 A 指向白色对象 B, 而此时并发地将黑色对象 C 指向(ref3)了白色对象 B, 并将灰色对象 A 对白色对象 B 的引用移除(ref2)
那么在一个垃圾收集器和用户程序交替运行的场景中会出现如下图所示的标记过程:
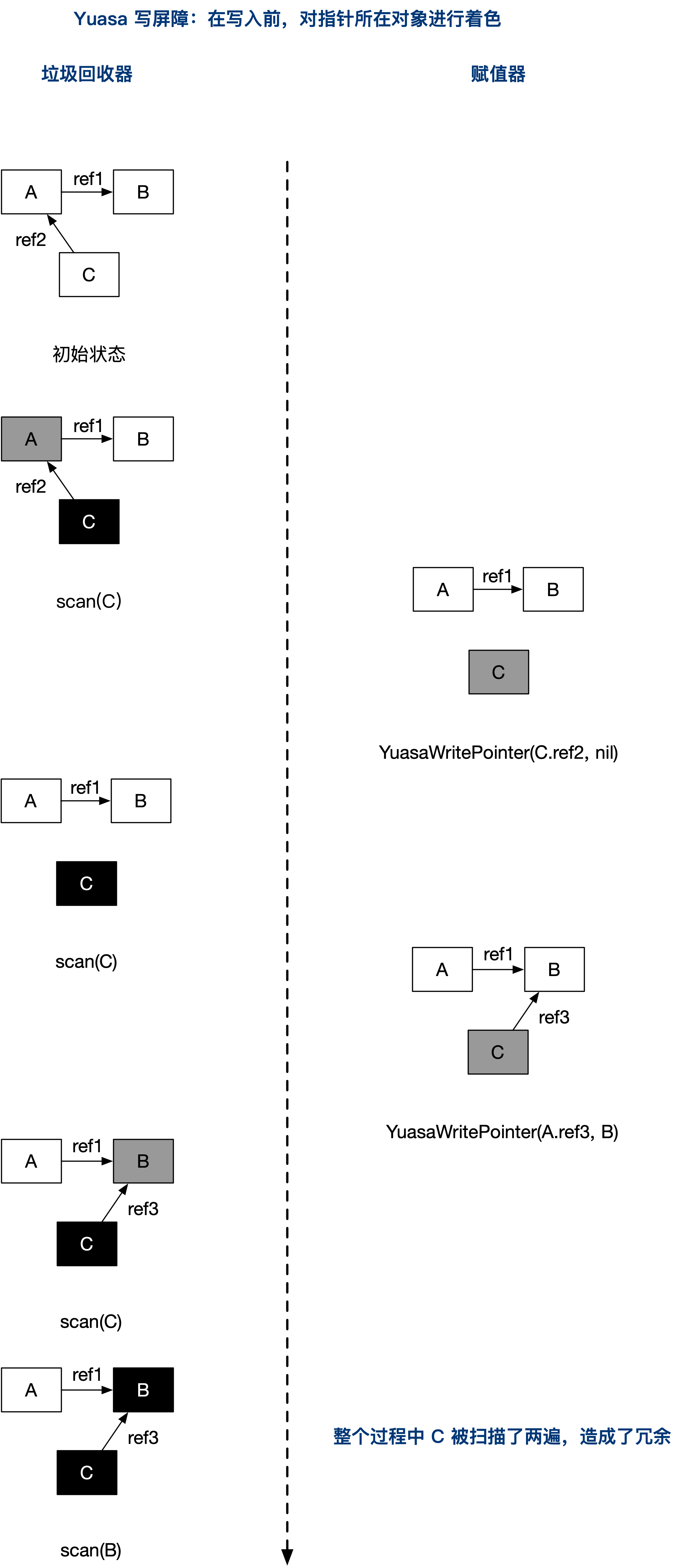
- 在上面删除
ref2时,通过使用删除写屏障YuasaWritePointer(C.ref1,nil),将节点 C 标灰 - 然后在增加
ref3时,直接指向 B 即可 - 在整个过程中,由于 C 的颜色改变,导致 C 会被扫描两遍,第一遍是初始时标黑,第二遍是由于置灰后重新标黑,所以会有冗余的情况。
Yuasa 删除屏障的优势在于不需要标记结束阶段的重新扫描, 结束时候能够准确的回收所有需要回收的白色对象。 缺陷是 Yuasa 删除屏障会拦截写操作,使得某些节点重新置灰,产生冗余的扫描。
混合写屏障
在 Go 语言 v1.7 版本之前,运行时会使用 Dijkstra 插入写屏障保证强三色不变性,但是运行时并没有在所有的垃圾收集根对象上开启插入写屏障。因为 Go 语言的应用程序可能包含成百上千的 Goroutine,而垃圾收集的根对象一般包括全局变量和栈对象,如果运行时需要在几百个 Goroutine 的栈上都开启写屏障,会带来巨大的额外开销,所以 Go 团队在实现上选择了在标记阶段完成时暂停程序、将所有栈对象标记为灰色并重新扫描,在活跃 Goroutine 非常多的程序中,重新扫描的过程需要占用 10 ~ 100ms 的时间。
Go 语言在 v1.8 组合 Dijkstra 插入写屏障和 Yuasa 删除写屏障构成了如下所示的混合写屏障,该写屏障会将被覆盖的对象标记成灰色并在当前栈没有扫描时将新对象也标记成灰色:
writePointer(slot, ptr):
shade(*slot)
if current stack is grey:
shade(ptr)
*slot = ptr
为了移除栈的重扫描过程,除了引入混合写屏障之外,在垃圾收集的标记阶段,还需要将创建的所有新对象都标记成黑色,防止新分配的栈内存和堆内存中的对象被错误地回收,因为栈内存在标记阶段最终都会变为黑色,所以不再需要重新扫描栈空间。
垃圾收集器
垃圾收集器的类型
传统的垃圾收集算法会在垃圾收集的执行期间暂停应用程序,一旦触发垃圾收集,垃圾收集器就会抢占 CPU 的使用权占据大量的计算资源以完成标记和清除工作,然而很多追求实时的应用程序无法接受长时间的 STW。
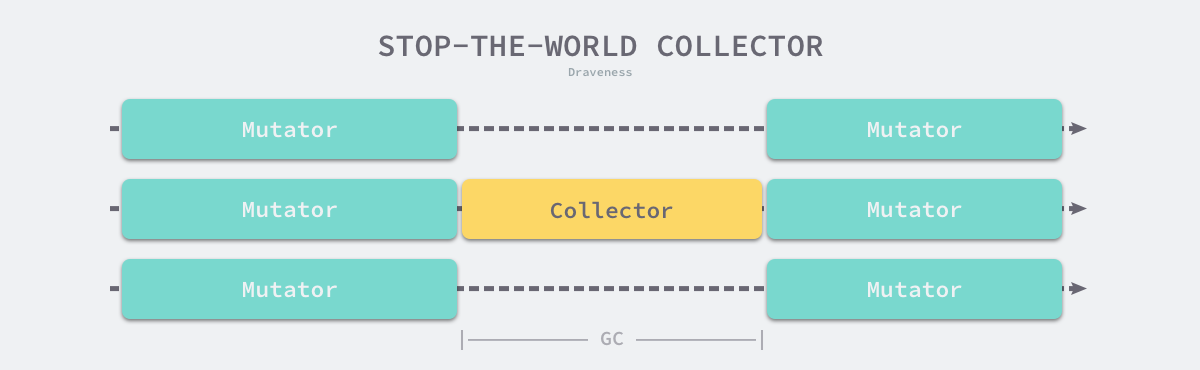
以前的计算资源还没有今天这么丰富,今天的计算机往往都是多核的处理器,垃圾收集器一旦开始执行就会浪费大量的计算资源,为了减少应用程序暂停的最长时间和垃圾收集的总暂停时间,会使用下面的策略优化现代的垃圾收集器:
- 增量垃圾收集:增量地标记和清除垃圾,降低应用程序暂停的最长时间;
- 并发垃圾收集:利用多核的计算资源,在用户程序执行时并发标记和清除垃圾;
因为增量和并发两种方式都可以与用户程序交替运行,所以需要使用屏障技术保证垃圾收集的正确性;与此同时,应用程序也不能等到内存溢出时触发垃圾收集,因为当内存不足时,应用程序已经无法分配内存,这与直接暂停程序没有什么区别,增量和并发的垃圾收集需要提前触发并在内存不足前完成整个循环,避免程序的长时间暂停。
增量收集器
增量式(Incremental)的垃圾收集是减少程序最长暂停时间的一种方案,它可以将原本时间较长的暂停时间切分成多个更小的 GC 时间片,虽然从垃圾收集开始到结束的时间更长了,但是这也减少了应用程序暂停的最大时间:
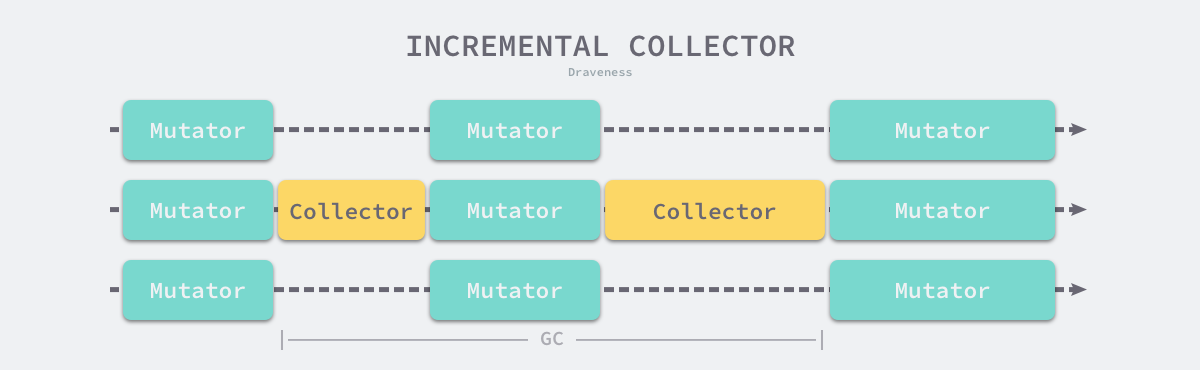
需要注意的是,增量式的垃圾收集需要与三色标记法一起使用,为了保证垃圾收集的正确性,需要在垃圾收集开始前打开写屏障,这样用户程序对内存的修改都会先经过写屏障的处理,保证了堆内存中对象关系的强三色不变性或者弱三色不变性。虽然增量式的垃圾收集能够减少最大的程序暂停时间,但是增量式收集也会增加一次 GC 循环的总时间,在垃圾收集期间,因为写屏障的影响用户程序也需要承担额外的计算开销,所以增量式的垃圾收集也不是只有优点的。
并发收集器
并发(Concurrent)的垃圾收集不仅能够减少程序的最长暂停时间,还能减少整个垃圾收集阶段的时间,通过开启读写屏障、利用多核优势与用户程序并行执行,并发垃圾收集器能够减少垃圾收集对应用程序的影响:
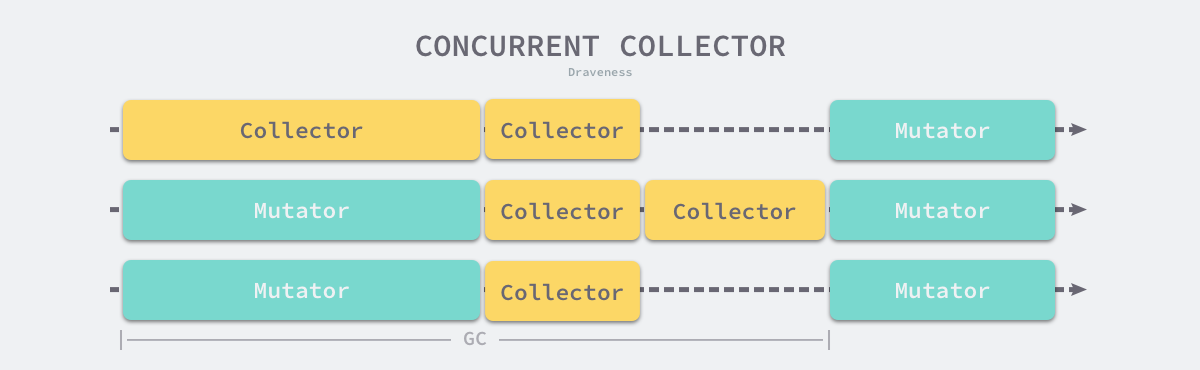
虽然并发收集器能够与用户程序一起运行,但是并不是所有阶段都可以与用户程序一起运行,部分阶段还是需要暂停用户程序的,不过与传统的算法相比,并发的垃圾收集可以将能够并发执行的工作尽量并发执行;当然,因为读写屏障的引入,并发的垃圾收集器也一定会带来额外开销,不仅会增加垃圾收集的总时间,还会影响用户程序,这是在设计垃圾收集策略时必须要注意的。
go 的垃圾收集器
Go 语言在 v1.5 中引入了并发的垃圾收集器,该垃圾收集器使用了上面提到的三色抽象和混合写屏障技术保证垃圾收集器执行的正确性,其工作流程大致如下:
首先,并发垃圾收集器必须在合适的时间点触发垃圾收集循环,假设 Go 语言程序运行在一台 4 核的物理机上,那么在垃圾收集开始后,收集器会占用 25% 计算资源在后台来扫描并标记内存中的对象:
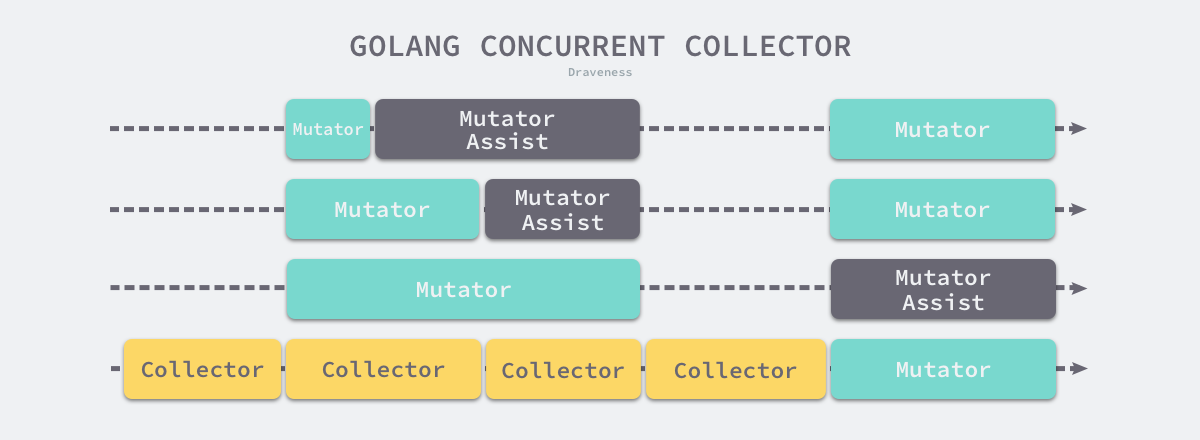
Go 语言的并发垃圾收集器会在扫描对象之前暂停程序做一些标记对象的准备工作,其中包括启动后台标记的垃圾收集器以及开启写屏障,如果在后台执行的垃圾收集器不够快,应用程序申请内存的速度超过预期,运行时就会让申请内存的应用程序辅助完成垃圾收集的扫描阶段,在标记和标记终止阶段结束之后就会进入异步的清理阶段,将不用的内存增量回收。
v1.5 版本实现的并发垃圾收集策略由专门的 Goroutine 负责在处理器之间同步和协调垃圾收集的状态。当其他的 Goroutine 发现需要触发垃圾收集时,它们需要将该信息通知给负责修改状态的主 Goroutine,然而这个通知的过程会带来一定的延迟,这个延迟的时间窗口很可能是不可控的,用户程序会在这段时间分配界面很多内存空间。
v1.6 引入了去中心化的垃圾收集协调机制,将垃圾收集器变成一个显式的状态机,任意的 Goroutine 都可以调用方法触发状态的迁移,goroutine 有以下几个状态:
_GCoff:GC未运行,在后台扫描,禁用写屏障_GCmark:GC 标记根和工作缓冲区,写屏障已启用,所有新创建的对象都会被直接标记成黑色_GCmarktermination:GC 标记进入终止阶段,新创建的对象会被直接标记成黑色,写屏障启用
回收堆目标
STW 的垃圾收集器虽然需要暂停程序,但是它能够有效地控制堆内存的大小,Go 语言运行时的默认配置会在堆内存达到上一次垃圾收集的 2 倍时,触发新一轮的垃圾收集,这个行为可以通过环境变量 GOGC 调整,在默认情况下它的值为 100,即增长 100% 的堆内存才会触发 GC。

因为并发垃圾收集器会与程序一起运行,所以它无法准确的控制堆内存的大小,并发收集器需要在达到目标前触发垃圾收集,这样才能够保证内存大小的可控,并发收集器需要尽可能保证垃圾收集结束时的堆内存与用户配置的 GOGC 一致。
Go 语言 v1.5 引入并发垃圾收集器的同时使用垃圾收集调步(Pacing)算法计算触发的垃圾收集的最佳时间,确保触发的时间既不会浪费计算资源,也不会超出预期的堆大小。如下图所示,其中黑色的部分是上一次垃圾收集后标记的堆大小,绿色部分是上次垃圾收集结束后新分配的内存,因为使用并发垃圾收集,所以黄色的部分就是在垃圾收集期间分配的内存,最后的红色部分是垃圾收集结束时与目标的差值,并发收集器应该尽可能减少红色部分内存,降低垃圾收集带来的额外开销以及程序的暂停时间。

垃圾收集过程
Go 语言的垃圾收集可以分成标记准备、标记、标记终止和清除四个不同阶段,它们分别完成了不同的工作:
标记准备阶段
这个阶段需要暂停程序(STW),所有的处理器在这时会进入安全点(Safe point);如果当前垃圾收集循环是强制触发的,还需要处理还未被清理的内存管理单元,同时将状态切换至 _GCmark、开启写屏障、用户程序协助(Mutator Assiste)并将根对象入队。
标记阶段
- 恢复执行程序,标记进程和用于协助的用户程序会开始并发标记内存中的对象,写屏障会将被覆盖的指针和新指针都标记成灰色,而所有新创建的对象都会被直接标记成黑色;
- 开始扫描根对象,包括所有 Goroutine 的栈、全局对象以及不在堆中的运行时数据结构,扫描 Goroutine 栈期间会暂停当前处理器;
- 依次处理灰色队列中的对象,将对象标记成黑色并将它们指向的对象标记成灰色;
- 使用分布式的终止算法检查剩余的工作,发现标记阶段完成后进入标记终止阶段
在这个阶段开始,即标记开始的时候,收集器会默认抢占 25% 的 CPU 性能,剩下的 75% 会分配给程序执行。但是一旦收集器认为来不及进行标记任务了,就会改变这个 25% 的性能分配。这个时候收集器会抢占程序额外的 CPU,这部分被抢占 goroutine 有个名字叫 Mark Assist。而且因为抢占 CPU的目的主要是 GC 来不及标记新增的内存,那么抢占正在分配内存的 goroutine 效果会更加好,所以分配内存速度越快的 goroutine 就会被抢占越多的资源。这种抢占的优化方式叫做标记辅助。
除此以外 GC 还有一个额外的优化**,一旦某次 GC 中用到了 Mark Assist,下次 GC 就会提前开始,目的是尽量减少 Mark Assist 的使用,从而避免影响正常的程序执行**。
标记终止阶段
- 暂停程序、将状态切换至
_GCmarktermination,关闭辅助标记的用户程序; - 清理处理器上的线程缓存;
标记结束阶段还需要做的事情是计算下一次清理的目标和计划,比如第二阶段使用了 Mark Assist 就会促使下次 GC 提早进行。如果想人为地减少或者增加 GC 的频率,那么可以用 GOGC 这个环境变量设置。Go 的 GC 有且只会有一个参数进行调优,也就是 GOGC,目的是为了防止开发者在一大堆调优参数中摸不着头脑。
通常情况下,标记结束阶段会耗时 60-90 微秒。
清理阶段
- 将状态切换至
_GCoff开始清理阶段,初始化清理状态并关闭写屏障; - 恢复用户程序,所有新创建的对象会标记成白色;
- 后台并发清理所有的内存管理单元,当 Goroutine 申请新的内存管理单元时就会触发清理。
Go 程序是怎么把内存释放给操作系统的?
释放内存的函数是 sysUnused,它会被 mspan.scavenge() 调用:
// MAC下的实现
func sysUnused(v unsafe.Pointer, n uintptr) {
// MADV_FREE_REUSABLE is like MADV_FREE except it also propagates
// accounting information about the process to task_info.
madvise(v, n, _MADV_FREE_REUSABLE)
}
注释说 _MADV_FREE_REUSABLE 与 MADV_FREE 的功能类似,它的功能是给内核提供一个建议:这个内存地址区间的内存已经不再使用,可以回收。但内核是否回收,以及什么时候回收,这就是内核的事情了。如果内核真把这片内存回收了,当 Go 程序再使用这个地址时,内核会重新进行虚拟地址到物理地址的映射。所以在内存充足的情况下,内核也没有必要立刻回收内存。
从上面的流程可以知道,垃圾回收过程使用 _GCoff、_GCmark 和 _GCmarktermination 三个状态表示垃圾收集的全部阶段,一次完整的垃圾回收会分为四个阶段,分别是标记准备、标记、结束标记以及清理。在标记准备和标记结束阶段会需要 STW,标记阶段会减少程序的性能,而清理阶段是不会对程序有影响的。
GOGC 对性能的影响
前面提到了 go 只提供了 GOGC 这个参数进行垃圾回收调优, 默认值是 100。表示当内存的增加值小于等于上次垃圾回收 100% 时会强制进行一次垃圾回收。可以通过环境变量将这个值修改成 200,表示当内存增加 200% 时强制进行垃圾回收,或者将这个值设置为负数表示不进行垃圾回收。下面的例子演示了不同的 GOGC 对性能的影响:
假设有如下分配内存的函数:
func DoAllocate(nKB int, wg *sync.WaitGroup) {
var slice []byte
for i := 0; i < nKB; i++ {
t := make([]byte, 1024) // 1KB
slice = append(slice, t...)
}
wg.Done()
}
在 main 函数中执行多个 groutine 进行内存分配调用,这里内存一直增长就会达到触发 GC 的阈值:
func main() {
t0 := time.Now()
n := 10
wg := new(sync.WaitGroup)
wg.Add(n)
for i := 0; i < n; i++ {
// 程序运行时最多分配 50MB-100MB 内存, 防止影响宿主机
go DoAllocate(50*1024, wg)
}
wg.Wait()
println("time used", time.Since(t0).Milliseconds(), "ms")
}
通过下面的脚本 run.sh 在不同的 GOGC 下运行:
data=( -1 10 50 100 200 400 800 1600 3200)
for i in ${data[@]} ; do
echo "==== start", GOGC=$i "===="
GOGC=$i go run main.go
echo
done
可以看到运行结果:
==== start, GOGC=-1 ====
time used 1602 ms
==== start, GOGC=10 ====
time used 470 ms
==== start, GOGC=50 ====
time used 543 ms
==== start, GOGC=100 ====
time used 948 ms
==== start, GOGC=200 ====
time used 748 ms
==== start, GOGC=400 ====
time used 553 ms
==== start, GOGC=800 ====
time used 530 ms
==== start, GOGC=1600 ====
time used 619 ms
==== start, GOGC=3200 ====
time used 547 ms
可以看到最快是 470 ms,最慢是 1602 ms,最快和最慢的速度几乎相差了 4 倍,一个简单的修改就可以造成性能巨大的改变。
go 垃圾回收的时机
自动触发
运行时会在应用程序启动时在后台开启一个用于强制触发垃圾收集的 Goroutine,该 Goroutine 的职责非常简单:调用 runtime.gcStart 方法尝试启动新一轮的垃圾收集,其实现如下:
func init() {
go forcegchelper()
}
func forcegchelper() {
forcegc.g = getg()
for {
lock(&forcegc.lock)
if forcegc.idle != 0 {
throw("forcegc: phase error")
}
atomic.Store(&forcegc.idle, 1)
// 主动陷入休眠
goparkunlock(&forcegc.lock, waitReasonForceGGIdle, traceEvGoBlock, 1)
// this goroutine is explicitly resumed by sysmon
if debug.gctrace > 0 {
println("GC forced")
}
// 尝试启动新一轮的垃圾收集
gcStart(gcTrigger{kind: gcTriggerTime, now: nanotime()})
}
}
为了减少对计算资源的占用,该 Goroutine 会在循环中调用 runtime.goparkunlock 主动陷入休眠等待其他 Goroutine 的唤醒,所以 runtime.forcegchelper 在大多数时间都是陷入休眠的,但是它会被系统监控器 runtime.sysmon 在满足垃圾收集条件时唤醒。
自动垃圾回收的自动触发条件有两个:
- 堆内存的分配达到控制器计算的触发堆大小的阈值。阈值是由一个
gcpercent的变量控制的,当新分配的内存占已在使用中的内存的比例超过gcprecent时就会触发。默认情况下为 100,即堆内存相比上次垃圾收集增长 100% 时应该触发 GC。比如一次回收完毕后,内存的使用量为 5M,那么下次回收的时机则是内存分配达到 10M 的时候。也就是说,并不是内存分配越多,垃圾回收频率越高。 - 达到定时时间,如果一直达不到内存大小的阈值,这个时候 GC 就会被定时时间触发,就会触发新的循环,该出发条件由
forcegcperiod变量控制,默认为 2 分钟。比如一直达不到10M,那就定时(默认 2min 触发一次)触发一次GC保证资源的回收。
手动触发
用户程序会通过 runtime.GC 函数在程序运行期间主动通知运行时执行,该方法在调用时会阻塞调用方直到当前垃圾收集循环完成,在垃圾收集期间也可能会通过 STW 暂停整个程序。其流程大致如下:
在正式开始垃圾收集前,运行时需等待上一个循环的标记终止、标记和标记终止阶段完成;
触发新一轮的垃圾收集并等待该轮垃圾收集的标记终止阶段正常结束;
清理全部待处理的内存管理单元并等待所有的清理工作完成,等待期间会让出处理器;
完成本轮垃圾收集的清理工作后,将该阶段的堆内存状态快照发布出来,可以获取这时的内存状态;
手动触发垃圾收集的过程不是特别常见,一般只会在运行时的测试代码中才会出现,不过如果认为触发主动垃圾收集是有必要的,也可以直接调用该方法,但是这并不是一种推荐的做法。
Go 栈内存管理
应用程序的内存一般会分成堆区和栈区两个部分,程序在运行期间可以主动从堆区申请内存空间,这些内存由上面介绍的内存分配器分配并由垃圾收集器负责回收。而对于栈区的内存,一般由编译器自动进行分配和释放,其中存储着函数的入参以及局部变量,这些参数会随着函数的创建而创建,函数的返回而消亡,一般不会在程序中长期存在,这种线性的内存分配策略有着极高地效率。
栈内存管理的基本概念
寄存器
寄存器是中央处理器(CPU)中的稀缺资源,它的存储能力非常有限,但是能提供最快的读写速度,充分利用寄存器的效率可以构建高性能的应用程序。栈区的操作就会使用到两个以上的寄存器
栈寄存器在是 CPU 寄存器中的一种,它的主要作用是跟踪函数的调用栈,Go 语言的汇编代码中包含 BP 和 SP 两个栈寄存器,它们分别存储了栈的基址指针和栈顶的地址,栈内存与函数调用的关系非常紧密,BP 和 SP 之间的内存就是当前函数的调用栈。
由于历史的设计问题,目前的栈区内存都是从高地址向低地址扩展的,当应用程序申请或者释放栈内存时只需要修改 SP 寄存器的值,这种线性的内存分配方式与堆内存相比更加快速,占用极少的额外开销。
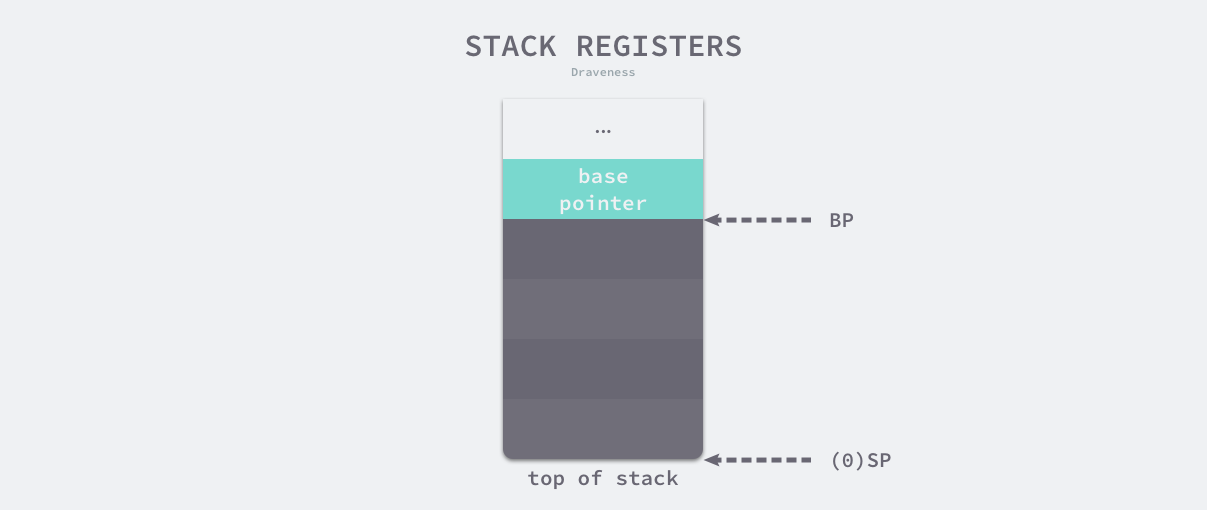
线程栈
回顾一下虚拟内存的基本结构:
Stack 的大小是固定的,运行时内存占用超过上限,程序会崩溃掉并报告 segment 错误。 然而这个固定的栈大小在某些场景下可能不是一个合适的值,如果一个程序需要同时运行几百个甚至上千个线程,那么这些线程中的绝大部分都只会用到很少的栈空间,而如果函数的调用栈非常深,固定的栈大小也无法满足用户程序的需求。为了修复这个问题,可以调大内核参数中的 stack size, 或者在创建线程时显式地传入所需要大小的内存块。 这两种方案都有自己的优缺点, 前者比较简单但会影响到系统内所有的 thread,后者需要开发者精确计算每个 thread 的大小, 负担比较高。
有没有办法既不影响所有 thread 又不会给开发者增加太多的负担呢? 当然是有的,比如: 可以在函数调用处插桩, 每次调用的时候检查当前栈的空间是否能够满足新函数的执行,满足的话直接执行,否则创建新的栈空间并将老的栈拷贝到新的栈然后再执行。 这个想法听起来可行,但当前的 Linux thread 模型却不能满足,实现的话只能够在用户空间实现,并且有不小的难度。
go 使用内置的运行时 runtime 优雅地解决了这个问题, 每个routine(g0除外)在初始化时 stack 大小都为 2KB, 运行过程中会根据不同的场景做动态的调整。
栈中的基本要素
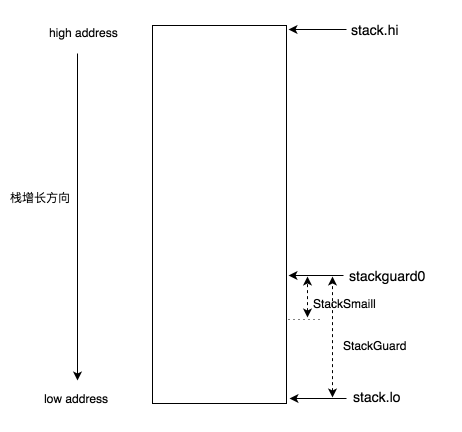
stack.lo:栈空间的低地址stack.hi:栈空间的高地址stackguard0:stack.lo + StackGuard, 用于stack overlow的检测StackGuard: 保护区大小,常量,Linux 上为 880 字节StackSmall:常量,大小为 128 字节,用于小函数调用的优化
在判断栈空间是否需要扩容的时候,可以根据被调用函数栈帧的大小, 分为以下两种情况:
小于
StackSmall:SP 小于stackguard0, 执行栈扩容,否则直接执行。大于
StackSamll:SP - Function’s Stack Frame Size + StackSmall小于stackguard0,执行栈扩容,否则直接执行。
此外,runtime 中还有个 StackBig 的常量,默认为 4096,被调用函数栈帧大小大于 StackBig 的时候, 一定会发生栈的扩容。
Go 中的逃逸分析
在 C 语言和 C++ 这类需要手动管理内存的编程语言中,将对象或者结构体分配到栈上或者堆上是由工程师自主决定的,这也为工程师的工作带来的挑战,如果工程师能够精准地为每一个变量分配最合理的空间,那么整个程序的运行效率和内存使用效率一定是最高的,但是手动分配内存会导致如下的两个问题:
- 不需要分配到堆上的对象分配到了堆上,浪费内存空间;
- 需要分配到堆上的对象分配到了栈上,造成悬挂指针、影响内存安全;
与悬挂指针相比,浪费的内存空间反而是小问题。在 C 语言中,栈上的变量被函数作为返回值返回给调用方是一个常见的错误,在如下所示的代码中,栈上的变量 i 被错误地返回:
int *dangling_pointer() {
int i = 2;
return &i;
}
当 dangling_pointer 函数返回后,它的本地变量就会被编译器直接回收,调用方获取的是危险的悬挂指针,这种情况下开发者无法确认当前指针指向的值是否合法,这种问题在大型项目中是比较难以发现和定位的。
在编译器优化中,逃逸分析(Escape analysis)是用来决定指针动态作用域的方法。它同编译器优化原理的指针分析和外形分析相关联。当变量(或者对象)在方法中分配后,其指针有可能被返回或者被全局引用,这样就会被其他过程或者线程所引用,这种现象称作指针(或者引用)的逃逸(Escape)。
像在 Java 中,在编译期间,如果 JIT 经过逃逸分析,发现有些对象没有逃逸出方法,那么有可能堆内存分配会被优化为栈内存分配。但这并不是绝对的。
Golang的逃逸分析只针对指针。一个值引用变量如果没有被取址,那么它永远不可能逃逸。Go 语言的编译器使用逃逸分析决定哪些变量应该在栈上分配,哪些变量应该在堆上分配,其中包括使用 new、make 和字面量等方法隐式分配的内存。对于未发生逃逸的变量,则直接在栈上分配内存。因为栈上内存由在函数返回时自动回收,因此能减小gc压力。Go 语言的逃逸分析遵循以下两个不变性:
- 指向栈对象的指针不能存在于堆中;
- 指向栈对象的指针不能在栈对象回收后存活;
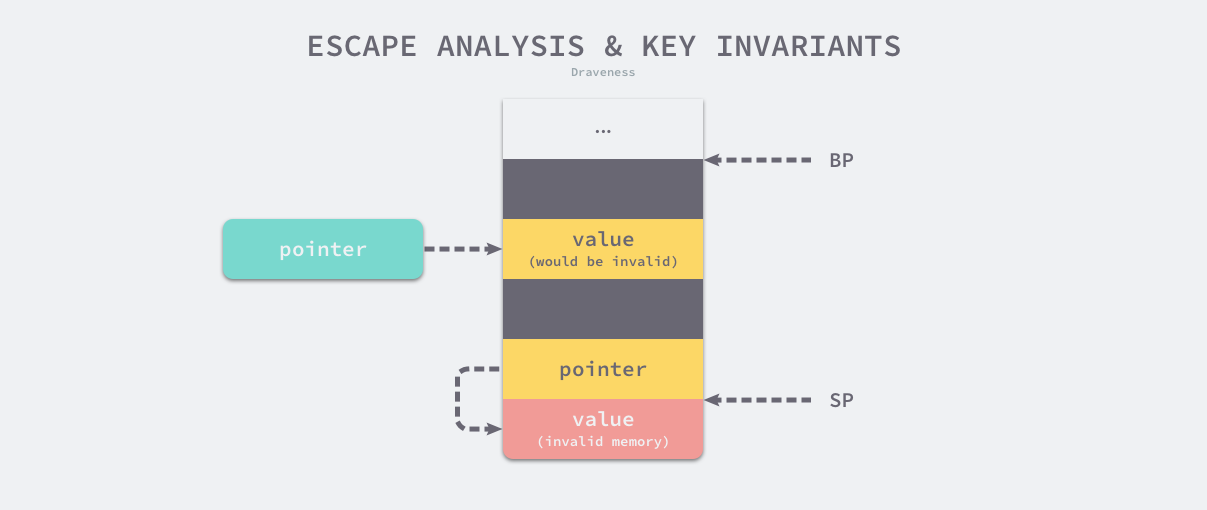
上图展示两条不变性存在的意义,当违反了第一条不变性,堆上的绿色指针指向了栈中的黄色内存,一旦当前函数返回函数栈被回收,该绿色指针指向的值就不再合法;如果违反了第二条不变性,因为寄存器 SP 下面的内存由于函数返回已经被释放掉,所以黄色指针指向的内存已经不再合法。
逃逸分析是静态分析的一种,在编译器解析了 Go 语言源文件后,它可以获得整个程序的抽象语法树(Abstract syntax tree,AST),编译器可以根据抽象语法树分析静态的数据流,会通过以下几个步骤实现静态分析的全过程:
- 构建带权重的有向图,其中顶点表示被分配的变量,边表示变量之间的分配关系,权重表示寻址和取地址的次数;
- 遍历对象分配图并查找违反两条不变性的变量分配关系,如果堆上的变量指向了栈上的变量,那么栈上的变量就需要分配在堆上;
- 记录从函数的调用参数到堆以及返回值的数据流,增强函数参数的逃逸分析。
逃逸分析测试
检验方式
go run -gcflags "-m -l" xxx.go(-m打印逃逸分析信息,-l禁止内联编译);例:
➜ go run -gcflags "-m -l" internal/test1/main.go
# command-line-arguments
internal/test1/main.go:4:2: moved to heap: a
internal/test1/main.go:5:11: main make([]*int, 1) does not escape
关于 -gcflags "-m -l" 的输出,有两种情况:
moved to heap:xxx:当xxx变量为值类型时,对其取地址操作导致的逃逸会是这种格式xxx escapes to heap:当xxx变量类型为指针时,发生逃逸会是这种格式
逃逸情况分析
情况一
首先说一种最基本的情况:
在某个函数中 new 或字面量创建出的变量,将其指针作为函数返回值,则该变量一定发生逃逸。
这是 golang 基础教程中经常举的,用于区别 c/c++ 例子:
func test() *User{
a := User{}
return &a
}
这种情况较为基础。
情况二
验证当某个值取指针传给另一个函数,该值是否发生逃逸:
example 1:
package main
import "fmt"
type User struct {
Username string
Password string
Age int
}
func main() {
a := "aaa"
u := &User{a, "123", 12}
Call1(u)
}
func Call1(u *User) {
fmt.Printf("%v", u)
}
看一下逃逸情况:
go run -gcflags "-m -l" demo/escape_analysis.go
# command-line-arguments
demo/escape_analysis.go:17:12: leaking param: u
demo/escape_analysis.go:18:12: ... argument does not escape
demo/escape_analysis.go:13:7: &User literal escapes to heap
&{aaa 123 12}%
这里变量 u 发生了逃逸,这里将指针传给一个函数 Call1并打印。
如果不打印,只对 u进行读写呢?修改一下 Call1
example 2:
package main
type User struct {
Username string
Password string
Age int
}
func main() {
a := "aaa"
u := &User{a, "123", 12}
Call1(u)
}
func Call1(u *User) int {
u.Username = "bbb"
return u.Age * 20
}
结果:
go run -gcflags "-m -l" demo/escape_analysis.go
# command-line-arguments
demo/escape_analysis.go:15:12: u does not escape
demo/escape_analysis.go:11:7: &User literal does not escape
这里变量 u 没有逃逸,变量为什么 example1 发生了逃逸呢?再将 Call1 多传几次,但还是只对 u 进行读写:
example 3:
func main() {
a := "aaa"
u := &User{a, "123", 12}
Call1(u)
}
func Call1(u *User) int {
return Call2(u)
}
func Call2(u *User) int {
return Call3(u)
}
func Call3(u *User) int {
u.Username = "bbb"
return u.Age * 20
}
结果:
go run -gcflags "-m -l" demo/escape_analysis.go
# command-line-arguments
demo/escape_analysis.go:23:12: u does not escape
demo/escape_analysis.go:19:12: u does not escape
demo/escape_analysis.go:15:12: u does not escape
demo/escape_analysis.go:11:7: &User literal does not escape
可以看到,依然没有发生逃逸。
那究竟为什么 example1 会逃逸呢?
其原因在于,在 fmt.Printf 的源码中,会将传入的 u 被赋值给了 pp 指针的一个成员变量:
// format 即为传入的变量 u
func Fprintf(w io.Writer, format string, a ...interface{}) (n int, err error) {
p := newPrinter()
p.doPrintf(format, a)
n, err = w.Write(p.buf)
p.free()
return
}
// 这里按照情况 1 会发生逃逸
func newPrinter() *pp {
p := ppFree.Get().(*pp)
p.panicking = false
p.erroring = false
p.wrapErrs = false
p.fmt.init(&p.buf)
return p
}
func (p *pp) doPrintf(format string, a []interface{}) {
//...
p.printArg(a[argNum], rune(c))
//...
}
func (p *pp) printArg(arg interface{}, verb rune) {
p.arg = arg
p.value = reflect.Value{}
//...
}
而这个 pp 类型的指针 p 是由构造函数 newPrinter 返回的,根据情况1,p一定发生逃逸,而 p 引用了传入指针,由此我们可以总结:被已经逃逸的变量引用的指针,一定发生逃逸。
情况三
再看下面的例子:
func main() {
a := make([]*int,1)
b := 12
a[0] = &b
}
结果:
go run -gcflags "-m -l" demo/escape_analysis.go
# command-line-arguments
demo/escape_analysis.go:5:2: moved to heap: b
demo/escape_analysis.go:4:11: make([]*int, 1) does not escape
sliace a 并没有发生逃逸,但是被 a 引用的 b 依然逃逸了。类似的情况同样发生在 map 和 chan 中:
func main() {
a := make([]*int,1)
b := 12
a[0] = &b
c := make(map[string]*int)
d := 14
c["aaa"]=&d
e := make(chan *int,1)
f := 15
e <- &f
}
结果:
go run -gcflags "-m -l" demo/escape_analysis.go
# command-line-arguments
demo/escape_analysis.go:5:2: moved to heap: b
demo/escape_analysis.go:9:2: moved to heap: d
demo/escape_analysis.go:13:2: moved to heap: f
demo/escape_analysis.go:4:11: make([]*int, 1) does not escape
demo/escape_analysis.go:8:11: make(map[string]*int) does not escape
由此可以得出结论:被指针类型的 slice、map 和 chan 引用的指针一定发生逃逸
备注:stack overflow 上有人提问为什么使用指针的
chan比使用值的chan慢30%,答案就在这里:使用指针的chan发生逃逸,gc 拖慢了速度
逃逸分析总结
指针必然发生逃逸的三种情况:
- 在某个函数中 new 或字面量创建出的变量,将其指针作为函数返回值,则该变量一定发生逃逸(构造函数返回的指针变量一定逃逸);
- 被已经逃逸的变量引用的指针,一定发生逃逸;
- 被指针类型的
slice、map和chan引用的指针,一定发生逃逸
同时也得出一些必然不会逃逸的情况:
- 指针被未发生逃逸的变量引用;
- 仅仅在函数内对变量做取址操作,而未将指针传出;
有一些情况可能发生逃逸,也可能不会发生逃逸:
- 将指针作为入参传给别的函数,这里还是要看指针在被传入的函数中的处理过程,如果发生了上边的三种情况,则会逃逸;否则不会逃逸
另外,决定变量是在栈上还是堆上虽然重要,但是这是一个定义相对清晰的问题,可以通过编译器在统一作出决策。为了保证内存的绝对安全,编译器可能会将一些变量错误地分配到堆上,但是因为这些对也会被垃圾收集器处理,所以不会造成内存泄露以及悬挂指针等安全问题,解放了工程师的生产力。
Go 栈内存空间管理
Goroutine 栈内存空间、结构和初始大小在最开始并不是2KB,也是经过了几个版本的更迭
- v1.0 ~ v1.1 — 最小栈内存空间为 4KB;
- v1.2 — 将最小栈内存提升到了 8KB;
- v1.3 — 使用连续栈替换之前版本的分段栈;
- v1.4 — 将最小栈内存降低到了 2KB;
分段栈
分段栈是 Go 语言在 v1.3 版本之前的实现,所有 Goroutine 在初始化时都会分配一块固定大小的内存空间,这块内存的大小在 v1.2 版本中为 8KB。
如果申请的内存大小为固定的 8KB 或者满足其他的条件,运行时会在全局的栈缓存链表中找到空闲的内存块并作为新 Goroutine 的栈空间返回;在其余情况下,栈内存空间会从堆上申请一块合适的内存。
当 Goroutine 调用的函数层级或者局部变量需要的越来越多时,运行时会调用 runtime.morestack 和 runtime.newstack 创建一个新的栈空间,这些栈空间虽然不连续,但是当前 Goroutine 的多个栈空间会以链表的形式串联起来,运行时会通过指针找到连续的栈片段:
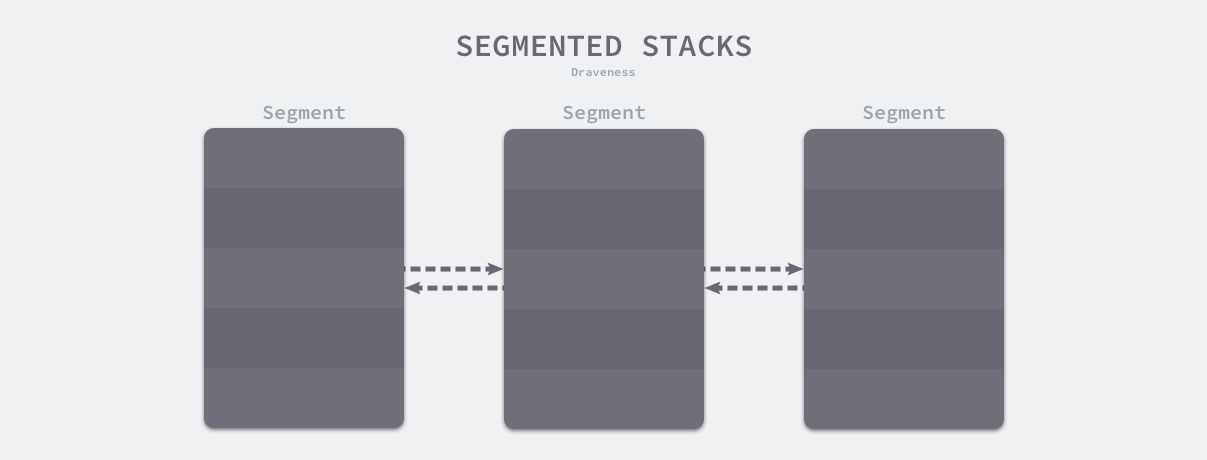
一旦 Goroutine 申请的栈空间不在被需要,运行时会调用 runtime.lessstack 和 runtime.oldstack 释放不再使用的内存空间。
分段栈机制虽然能够按需为当前 Goroutine 分配内存并且及时减少内存的占用,但是它也存在两个比较大的问题:
- 如果当前 Goroutine 的栈几乎充满,那么任意的函数调用都会触发栈的扩容,当函数返回后又会触发栈的收缩,如果在一个循环中调用函数,栈的分配和释放就会造成巨大的额外开销,这被称为热分裂问题(Hot split);
- 一旦 Goroutine 使用的内存越过了分段栈的扩缩容阈值,运行时就会触发栈的扩容和缩容,带来额外的工作量;
为了解决这个问题,Go在 1.2 版本的时候不得不将栈的初始化内存从 4KB 增大到了 8KB。后来把采用连续栈结构后,又把初始栈大小减小到了 2KB。
连续栈
连续栈可以解决分段栈中存在的两个问题,其核心原理就是每当程序的栈空间不足时,初始化一片更大的栈空间,并将原栈中的所有值都迁移到新的栈中,新的局部变量或者函数调用就有了充足的内存空间。使用连续栈机制时,栈空间不足导致的扩容会经历以下几个步骤:
- 在内存空间中分配更大的栈内存空间;
- 将旧栈中的所有内容复制到新的栈中;
- 将指向旧栈对应变量的指针重新指向新栈;
- 销毁并回收旧栈的内存空间;
在扩容的过程中,最重要的是调整指针的第三步,这一步能够保证指向栈的指针的正确性,因为栈中的所有变量内存都会发生变化,所以原本指向栈中变量的指针也需要调整,如下图:
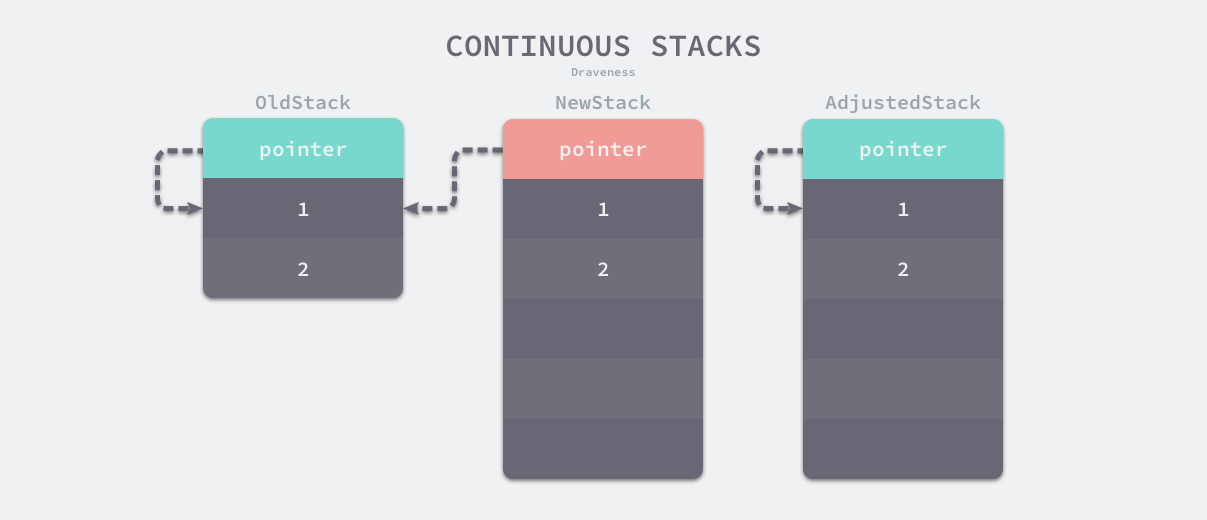
复制出来的 NewStack 的指针还是会指向原来的地址,需要重新调整将指向旧栈对应变量的指针重新指向新栈。
下面的例子就验证了栈扩容后同一变量的内存地址也会发生变化,在下面的例子中,由于变量没有逃逸出去,始终分配在栈内存上,所以一直增大最终会导致栈内存的扩容:
package main
func main() {
var x [10]int
println(&x)
a(x)
println(&x)
}
func a(x [10]int) {
println(`func a`)
var y [100]int
b(y)
}
func b(x [100]int) {
println(`func b`)
var y [1000]int
c(y)
}
func c(x [1000]int) {
println(`func c`)
}
程序的输出可以看到在栈扩容前后,变量 x 的内存地址的变化:
0xc00002e728
func a
func b
func c
0xc0000adf28
因为需要拷贝变量和调整指针,连续栈增加了栈扩容时的额外开销,但是通过合理栈缩容机制就能避免热分裂带来的性能问题,在 GC 期间如果 Goroutine 使用了栈内存的四分之一,那就将其内存减少一半,这样在栈内存几乎充满时也只会扩容一次,不会因为函数调用频繁扩缩容。
Go 栈的管理操作
栈初始化
栈空间在运行时中包含两个重要的全局变量,分别是 runtime.stackpool 和 runtime.stackLarge,这两个变量分别表示全局的栈缓存和大栈缓存,前者可以分配小于 32KB 的内存,后者用来分配大于 32KB 的栈空间:
// 全局栈缓存
var stackpool [_NumStackOrders]struct {
item stackpoolItem
_ [cpu.CacheLinePadSize - unsafe.Sizeof(stackpoolItem{})%cpu.CacheLinePadSize]byte
}
//go:notinheap
type stackpoolItem struct {
mu mutex
span mSpanList
}
// 大栈缓存
var stackLarge struct {
lock mutex
free [heapAddrBits - pageShift]mSpanList // free lists by log_2(s.npages)
}
这两个用于分配空间的全局变量都与内存管理单元 runtime.mspan 有关,可以认为 Go 语言的栈内存都是分配在堆上的,运行时初始化时通过调用的 runtime.stackinit 函数会在初始化这些全局变量:
func stackinit() {
if _StackCacheSize&_PageMask != 0 {
throw("cache size must be a multiple of page size")
}
for i := range stackpool {
// 初始化全局栈缓存中的 mSpanList
stackpool[i].item.span.init()
}
for i := range stackLarge.free {
// 初始化大栈缓存中的 mSpanList
stackLarge.free[i].init()
}
}
另外,从调度器和内存分配的角度来看,如果运行时只使用全局变量来分配内存的话,势必会造成线程之间的锁竞争进而影响程序的执行效率,栈内存由于与线程关系比较密切,所以在每一个线程缓存 runtime.mcache 中都加入了栈缓存减少锁竞争影响。
// linux/darwin/bsd | 2KB | 4
// windows/32 | 4KB | 3
// windows/64 | 8KB | 2
// plan9 | 4KB | 3
_NumStackOrders = 4 - sys.PtrSize/4*sys.GoosWindows - 1*sys.GoosPlan9
type mcache struct {
stackcache [_NumStackOrders]stackfreelist
}
type stackfreelist struct {
list gclinkptr
size uintptr
}
所以全局缓存池的结构如下,一个全局缓存池下会有 _NumStackOrders 个栈缓存。栈内容的申请也是跟前面 go 内存管理中的一样,先去当前线程的对应尺寸的 mcache 里去申请,不够的时候 mache 会从全局的 mcental 里取内存。
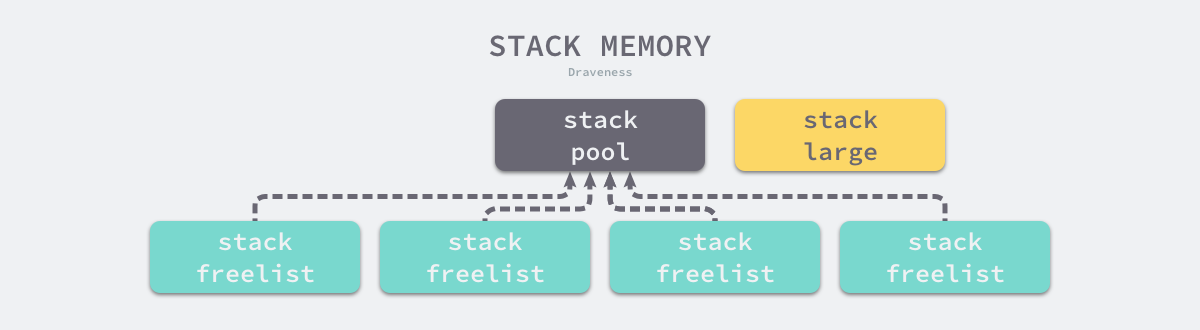
综上,运行时使用全局的 runtime.stackpool 和线程缓存中的空闲链表分配 32KB 以下的栈内存,使用全局的 runtime.stackLarge 和堆内存分配 32KB 以上的栈内存,提高本地分配栈内存的性能。
栈分配
运行时会在 Goroutine 的初始化函数分配一个大小足够栈内存空间,根据线程缓存和申请栈的大小,会通过三种不同的方法分配栈空间:
- 如果栈空间较小,使用全局栈缓存或者线程缓存上固定大小的空闲链表分配内存;
- 如果栈空间较大,从全局的大栈缓存
runtime.stackLarge中获取内存空间; - 如果栈空间较大并且
runtime.stackLarge空间不足,在堆上申请一片大小足够内存空间。
栈扩容
编译器会为函数调用插入运行时检查 runtime.morestack,它会在几乎所有的函数调用之前检查当前 goroutine 的栈内存是否充足,如果当前栈需要扩容,会保存一些栈的相关信息并调用 runtime.newstack 创建新的栈。
runtime.newstack 会先做一些准备工作并检查当前 Goroutine 是否发出了抢占请求,如果发出了抢占请求:
- 当前线程可以被抢占时,直接调用
runtime.gogo触发调度器的调度; - 如果当前 Goroutine 在垃圾回收被
runtime.scanstack函数标记成了需要收缩栈,调用runtime.shrinkstack; - 如果当前 Goroutine 被
runtime.suspendG函数挂起,调用runtime.preemptPark被动让出当前处理器的控制权并将 Goroutine 的状态修改至_Gpreempted; - 调用
runtime.gopreempt_m主动让出当前处理器的控制权;
如果当前 Goroutine 不需要被抢占,也就意味着需要新的栈空间来支持函数调用和本地变量的初始化,运行时会先检查目标大小的栈是否会溢出。如果目标栈的大小没有超出程序的限制,我们会将 Goroutine 切换至 _Gcopystack 状态并开始栈的拷贝,在拷贝栈的内存之前,运行时会分配新的栈空间。
新栈的初始化和数据的复制是一个比较简单的过程,需要注意这里还需要将指向源栈中内存指向新的栈。
栈缩容
如果要触发栈的缩容,新栈的大小会是原始栈的一半,不过如果新栈的大小低于程序的最低限制 2KB,那么缩容的过程就会停止。运行时只会在栈内存使用不足 1/4 时进行缩容,缩容也会调用扩容时使用的 runtime.copystack 函数开辟新的栈空间,将旧栈的数据拷贝到新栈以及调整原来指针的指向。
参考文档