goroutine 调度器原理
goroutine 调度器的概念
说到“调度”,首先会想到操作系统对进程、线程的调度。操作系统调度器会将系统中的多个线程按照一定算法调度到物理 CPU 上去运行。传统的编程语言比如 C、C++ 等的并发实现实际上就是基于操作系统调度的,即程序负责创建线程,操作系统负责调度。
尽管线程的调度方式相对于进程来说,线程运行所需要资源比较少,在同一进程中进行线程切换效率会高很多,但实际上多线程开发设计会变得更加复杂,要考虑很多同步竞争等问题,如锁、竞争冲突等。
线程是操作系统调度时的最基本单元,而 Linux 在调度器并不区分进程和线程的调度,只是说线程调度因为资源少,所以切换的效率比较高。
使用多线程编程会遇到以下问题:
- 并发单元间通信困难,易错:多个 thread 之间的通信虽然有多种机制可选,但用起来是相当复杂;并且一旦涉及到共享内存,就会用到各种 lock,一不小心就会出现死锁的情况。
- 对于线程池的大小不好确认,在请求量大的时候容易导致 OOM 的情况
- 虽然线程比较轻量,但是在调度时也有比较大的额外开销。每个线程会都占用 1 兆以上的内存空间,在对线程进行切换时不仅会消耗较多的内存,恢复寄存器中的内容还需要向操作系统申请或者销毁对应的资源,每一次线程上下文的切换仍然需要一定的时间(us 级别)
- 对于很多网络服务程序,由于不能大量创建 thread,就要在少量 thread 里做网络多路复用,例如 JAVA 的Netty 框架,写起这样的程序也不容易。
这便有了“协程”,线程分为内核态线程和用户态线程,用户态线程需要绑定内核态线程,CPU 并不能感知用户态线程的存在,它只知道它在运行1个线程,这个线程实际是内核态线程。
用户态线程实际有个名字叫协程(co-routine),为了容易区分,使用协程指用户态线程,使用线程指内核态线程。
协程跟线程是有区别的,线程由 CPU 调度是抢占式的,协程由用户态调度是协作式的,一个协程让出 CPU 后,才执行下一个协程。
Go 中,协程被称为 goroutine(但其实并不完全是协程,还做了其他方面的优化),它非常轻量,一个 goroutine 只占几 KB,并且这几 KB 就足够 goroutine 运行完,这就能在有限的内存空间内支持大量 goroutine,支持了更多的并发。虽然一个 goroutine 的栈只占几 KB,但实际是可伸缩的,如果需要更多内容,runtime 会自动为 goroutine 分配。
而将所有的 goroutines 按照一定算法放到 CPU 上执行的程序就称为 goroutine 调度器或 goroutine scheduler。
不过,一个 Go 程序对于操作系统来说只是一个用户层程序,对于操作系统而言,它的眼中只有 thread,它并不知道有什么叫 Goroutine 的东西的存在。goroutine 的调度全要靠 Go 自己完成,所以就需要 goroutine 调度器来实现 Go 程序内 goroutine 之间的 CPU 资源调度。
在操作系统层面,Thread 竞争的 CPU 资源是真实的物理 CPU,但对于 Go 程序来说,它是一个用户层程序,它本身整体是运行在一个或多个操作系统线程上的,因此 goroutine 们要竞争的所谓 “CPU” 资源就是操作系统线程。这样 Go scheduler 的要做的就是:将 goroutines 按照一定算法放到不同的操作系统线程中去执行。这种在语言层面自带调度器的,称之为原生支持并发。
groutine 结构体
我们在代码中 go 一个 func 时一般这样写:
go func1(arg1 type1,arg2 type2){....}(a1,a2)
一个协程代表了一个执行流,执行流有需要执行的函数(对应上面的func1),有函数的入参(a1, a2),有当前执行流的状态和进度(对应CPU的PC寄存器和SP寄存器),当然也需要有保存状态的地方,用于执行流恢复。
真正代表协程的是 runtime.g 结构体(仅列出部分字段)
type g struct {
stack stack // offset known to runtime/cgo
sched gobuf // 切换协程时的上下文信息
startfunc uintptr // 程序地址
goid int64 // 协程id
status uint32 // 协程状态
}
type stack struct {
lo uintptr // 该协程拥有的栈低位
hi uintptr // 该协程拥有的栈高位
}
type gobuf struct {
sp uintptr // 栈指针位置
pc uintptr // 运行到的程序位置
}
每个 go func 都会编译成 runtime.newproc 函数,最终有一个 runtime.g 对象放入调度队列。上面的 func1 函数的指针设置在 runtime.g 的 startfunc 字段,参数会在 newproc 函数里拷贝到 stack 中,sched 用于保存协程切换时的 pc 位置和栈位置。协程切换出去和恢复回来需要保存上下文,恢复上下文,这些由 gobuf 结构体来存储相关信息。以上就能实现协程这种执行流,并能进行切换和恢复。
goroutine 调度器的演进
调度器的任务是在用户态完成 goroutine 的调度,而调度器的实现好坏,对并发实际有很大的影响。
G-M模型
现在的 Go语言调度器是 2012 年重新设计的,在这之前的调度器称为老调度器,老调度器采用的是 G-M 模型,在这个调度器中,每个 goroutine 对应于 runtime 中的一个抽象结构:G,而 os thread 作为物理 CPU 的存在而被抽象为一个结构:M(machine)。M 想要执行 G、放回 G 都必须访问全局 G 队列,并且 M 有多个,即多线程访问同一资源需要加锁进行保证互斥/同步,所以全局 G 队列是有互斥锁进行保护的。
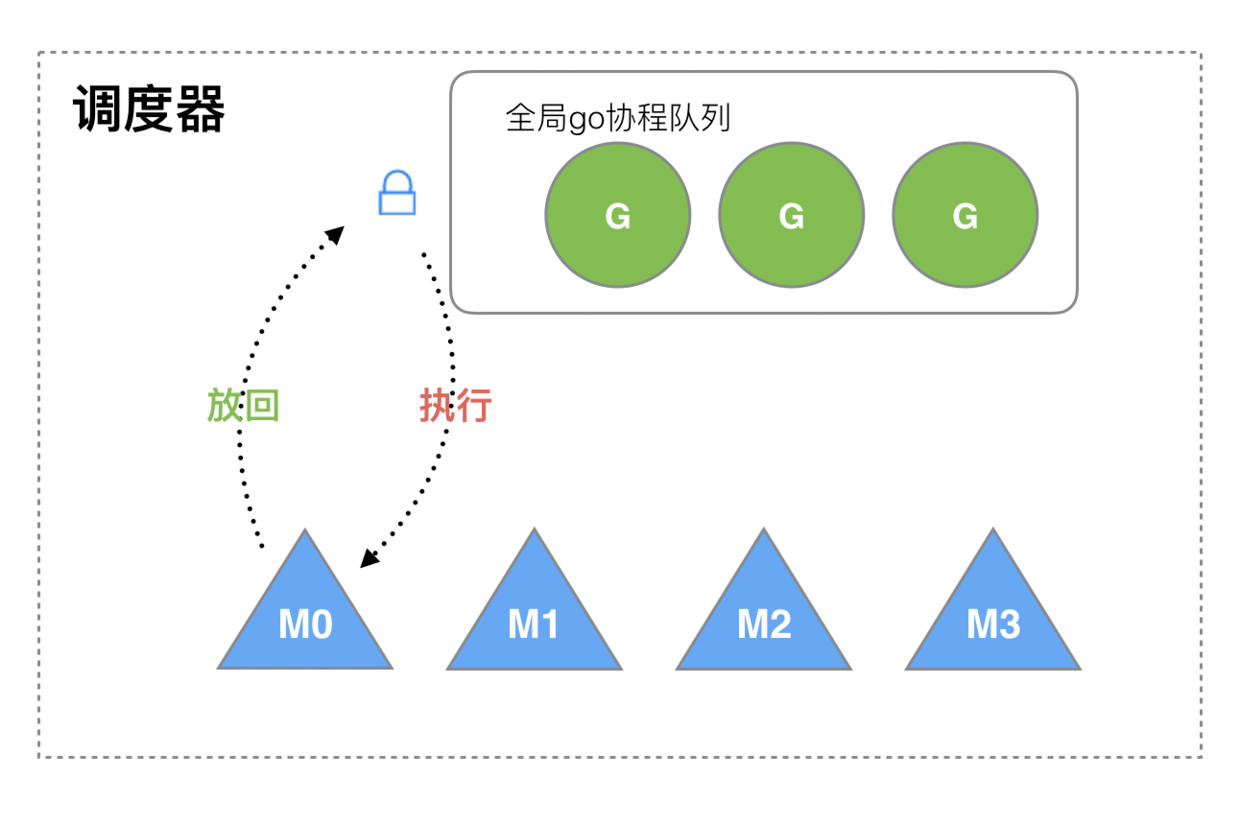
这个结构虽然简单,但是却存在着许多问题。它限制了 Go 并发程序的伸缩性,尤其是对那些有高吞吐或并行计算需求的服务程序。主要体现在如下几个方面:
- 单一全局互斥锁(Sched.Lock)和集中状态存储的存在导致所有 goroutine 相关操作,比如:创建、重新调度等都要上锁,这会造成激烈的锁竞争
- goroutine 传递问题:M 经常在 M 之间传递可运行的 goroutine,这导致调度延迟增大以及额外的性能损耗。新生成的协程也会放入全局的队列,大概率是被其他m(可以理解为底层线程的一个表示)运行了,内存亲和性不好。当前协程 A 新生成了协程 B,协程 A 比较大概率会结束或者阻塞,如果这时候 m 直接去执行协程B,内存的亲和性会好很多。
- 每个 M 做内存缓存,导致内存占用过高,数据局部性较差。因为 mcache 与 m 绑定,在一些应用中(比如文件操作或其他可能会阻塞线程的系统调用比较多),m 的个数可能会远超过活跃的 m 个数, 导致比较大的内存浪费..
- 系统调用导致频繁的线程阻塞和取消阻塞操作增加了系统开销
所以用了 4 年左右就被替换掉了。
G-P-M 模型
面对之前调度器的问题,Go 设计了新的调度器,并在其中引入了 P(Processor),将 Memory Cache 放到了 P 中,另外还引入了任务窃取调度的方式(work stealing)
- P:Processor,它包含了运行 goroutine 的资源,如果线程想运行 goroutine,必须先获取 P,P 中还包含了可运行的 G 队列。
- work stealing:当 M 绑定的 P 没有可运行的 G 时,它可以从其他运行的 M 那里偷取G。
G-P-M 模型的结构如下图:
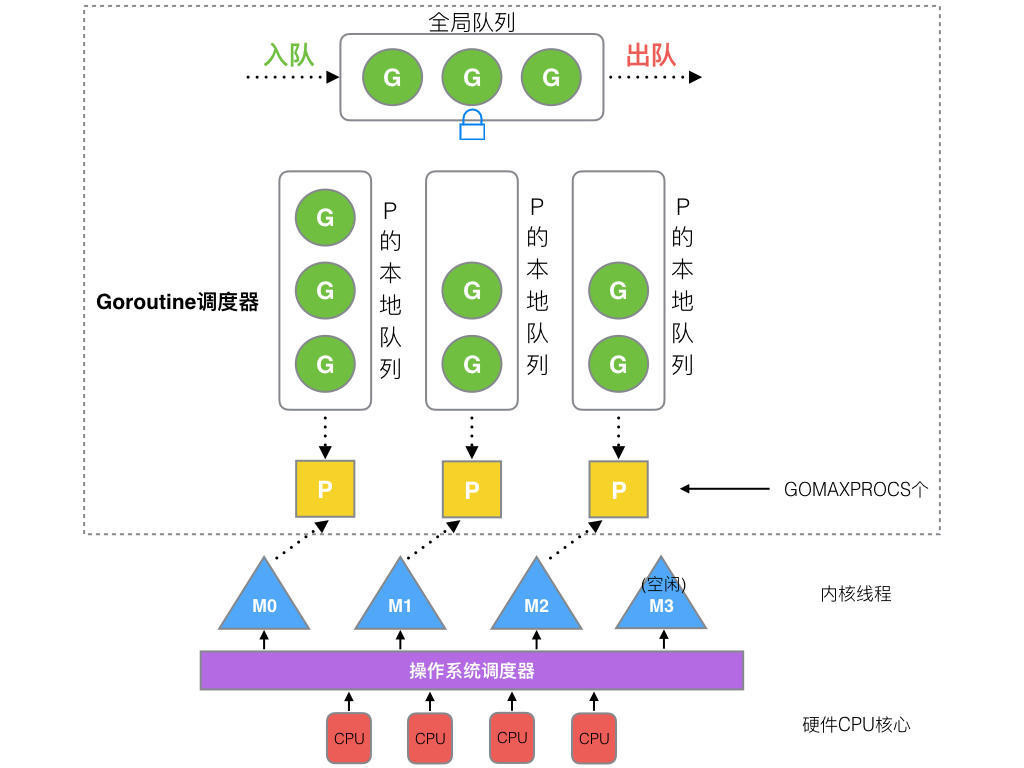
从上往下是调度器的4个部分:
- 全局队列(Global Queue):存放等待运行的 G。
- P 的本地队列:同全局队列类似,存放的也是等待运行的G,存的数量有限,不超过256个。新建 G 时,G 优先加入到 P 的本地队列,如果队列满了,则会把本地队列中一半的 G 移动到全局队列。
- P列表:所有的 P 都在程序启动时创建,并保存在数组中,最多有
GOMAXPROCS个。 - M:线程想运行任务就得获取 P,从 P 的本地队列获取 G,P 队列为空时,M 也会尝试从全局队列拿一批 G放到 P 的本地队列,或从其他 P 的本地队列偷一半放到自己 P 的本地队列。M 运行 G,G 执行之后,M 会从 P 获取下一个 G,不断重复下去。
Goroutine 调度器和 OS 调度器是通过 M 结合起来的,每个 M 都代表了1个内核线程,OS 调度器负责把内核线程分配到 CPU 的核上执行。
有关 P 和 M 的个数问题
P 的数量
- 由启动时环境变量
$GOMAXPROCS或者是由runtime的方法GOMAXPROCS()决定。这意味着在程序执行的任意时刻都只有$GOMAXPROCS个 goroutine 在同时运行。
M 的数量
- go 语言本身的限制:go 程序启动时,会设置 M 的最大数量,默认 10000。但是内核很难支持这么多的线程数,所以这个限制可以忽略。
runtime/debug中的SetMaxThreads函数,可以设置 M 的最大数量- 一个 M 阻塞了,会创建新的 M。
M 与 P 的数量没有绝对关系,一个 M 阻塞,P 就会去创建或者切换另一个 M,所以,即使 P 的默认数量是 1,也有可能会创建很多个 M 出来。
调度
golang 调度的职责就是为需要执行的Go代码(G)寻找执行者(M)以及执行的准许和资源(P)。并没有一个调度器的实体, 调度是需要发生调度时由 m 执行 runtime.schedule 方法进行的。
发生调度的时机:
- lchannel,mutex 等 sync 操作发生了协程阻塞
- time.sleep
- 网络操作暂时未ready
- gc
- 主动yield
- 运行过久或系统调用过久等等
Sysmon 协程
sysmon 协程是在 go runtime 初始化之后,执行用户编写的代码之前,由 runtime 启动的不与任何 P 绑定,直接由一个 M 执行的协程。类似于linux中的执行一些系统任务的内核线程。
可认为是10ms执行一次。(初始运行间隔为20us,sysmon运行 1ms 后逐渐翻倍,最终每10ms运行一次。如果有发生过抢占成功, 则又恢复成初始20us的运行间隔,如此循环)
以下代码来自 1.15.7 版本的 runtime/proc.go:
if idle == 0 {
// start with 20us sleep...
delay = 20
} else if idle > 50 {
// start doubling the sleep after 1ms...
delay *= 2
}
if delay > 10*1000 {
// up to 10ms
delay = 10 * 1000
}
P 的数量影响了同时运行 go 代码的协程数。如果 P 被占用很久,就会影响调度。
sysmon 协程的一个功能就是进行抢占。
sysmon 协程的功能如下:
- 每 sysmon tick 进行一次 netpoll(在STW结束,和 M 执行查找可运行的 G 时也会执行 netpoll)获取 fd 事件,将与之相关的 G 放入全局 runqueue
- 每次sysmon运行都执行一次抢占, 如果某个 P 的 G 执行超过1个 sysmon tick,则执行抢占。正在执行系统调用的话, 将 P 与 M 脱离(handoffp); 正在执行 Go 代码,则通知抢占(preemptone).
- 每2分钟如果没有执行过GC, 则通知 gchelper 协程执行一次GC
- 如果开启schdule trace的debug信息(例如GODEBUG=schedtrace=5000,scheddetail=1),则按照给定的间隔打印调度信息
- 每5分钟归还 GC 后不再使用的 span 给操作系统,释放自由列表中多余的项减少内存占用(scavenge heap)
抢占式调度
G-P-M 模型中还实现了抢占式调度,所谓抢占式调度指的是在 coroutine 中要等待一个协程主动让出 CPU 才执行下一个协程,在 Go 中,一个 goroutine 最多占用 CPU 10ms,防止其他 goroutine 被饿死,这也是 goroutine 不同于 coroutine 的一个地方。在 goroutine 中先后实现了两种抢占式调度算法,分别是基于协作的方式和基于信号的方式。
基于协作的抢占式调度
G-P-M 模型的实现是 Go scheduler 的一大进步,但此时的调度器仍然有一个问题,那就是不支持抢占式调度,导致一旦某个 G 中出现死循环或永久循环的代码逻辑,那么 G 将永久占用分配给它的 P 和 M,位于同一个 P 中的其他 G 将得不到调度,出现“饿死”的情况。当只有一个 P 时(GOMAXPROCS=1)时,整个 Go 程序中的其他 G 都会被饿死。所以后面 Go 设计团队在 Go 1.2 中实现了基于协作的抢占式调度。
这种抢占式调度的原理则是在每个函数或方法的入口,加上一段额外的代码,让 runtime 有机会检查是否需要执行抢占调度。
基于协作的抢占式调度的工作原理大致如下:
- 编译器会在调用函数前插入一个
runtime.morestack函数 - Go 语言运行时会在垃圾回收暂停程序、系统监控发现 Goroutine 运行超过 10ms 时发出抢占请求(由 sysmon 协程触发),此时会设置一个
StackPreempt字段值为StackPreempt,标示当前 Goroutine 发出了抢占请求。 - 当发生函数调用时,可能会执行编译器插入的
runtime.morestack函数,它调用的runtime.newstack会检查 Goroutine 的stackguard0字段是否为StackPreempt - 如果
stackguard0是StackPreempt,就会触发抢占让出当前线程
这种实现方式虽然增加了运行时的复杂度,但是实现相对简单,也没有带来过多的额外开销,所以在 Go 语言中使用了 10 几个版本。因为这里的抢占是通过编译器插入函数实现的,还是需要函数调用作为入口才能触发抢占,所以这是一种协作式的抢占式调度。这种解决方案只能说局部解决了“饿死”问题,对于没有函数调用,纯算法循环计算的 G,scheduler 依然无法抢占。
基于信号的抢占式调度
Go 语言在 1.14 版本中实现了非协作的抢占式调度,在实现的过程中重构已有的逻辑并为 Goroutine 增加新的状态和字段来支持抢占。
基于信号的抢占式调度的工作原理大致如下:
程序启动时,在
runtime.sighandler函数中注册一个SIGURG信号的处理函数runtime.doSigPreempt在触发垃圾回收的栈扫描时会调用函数
runtime.suspendG挂起 Goroutine,此时会执行下面的逻辑:将处于运行状态(
_Grunning)的 Goroutine 标记成可以被抢占,即将 Goroutine 的字段preemptStop设置成true;调用
runtime.preemptM函数, 它可以通过SIGURG信号向线程发送抢占请求触发抢占;
runtime.preemptM会调用runtime.signalM向线程发送信号SIGURG;操作系统收到信号后会中断正在运行的线程并执行预先在第 1 步注册的信号处理函数
runtime.doSigPreempt;runtime.doSigPreempt函数会处理抢占信号,获取当前的 SP 和 PC 寄存器并调用runtime.sigctxt.pushCall;runtime.sigctxt.pushCall会修改寄存器并在程序回到用户态时执行runtime.asyncPreempt;汇编指令
runtime.asyncPreempt会调用运行时函数runtime.asyncPreempt2;runtime.asyncPreempt2会调用runtime.preemptPark;runtime.preemptPark会修改当前 Goroutine 的状态到_Gpreempted并调用runtime.schedule让当前函数陷入休眠并让出线程,调度器会选择其它的 Goroutine 继续执行_Gpreempted状态表示当前 groutine 由于抢占而被阻塞,没有执行用户代码并且不在运行队列上,等待唤醒调度器在
runtime.sysmon方法中会调用retake方法处理两种场景的抢占:
- 抢占阻塞在系统调用上的 P
- 抢占运行时间过长的 G
该方法会检测符合场景的 P,当满足上述两个场景之一时,就会发送信号给 M。M 收到信号后将会休眠正在阻塞的 Goroutine,调用绑定的信号方法,并进行重新调度。
简单来说,上述流程就是说 Goroutine 通过 SIGURG 信号标记自己可以被抢占,操作系统收到此信号后,会进行保存现场的处理,然后让出线程给调度器选择其他 Goroutine 执行。
在上面的选择 SIGURG 作为触发异步抢占的信号:
- 该信号需要被调试器透传;
- 该信号不会被内部的 libc 库使用并拦截;
- 该信号可以随意出现并且不触发任何后果;
- 需要处理多个平台上的不同信号;
垃圾回收过程中需要暂停整个程序(Stop the world,STW),有时候可能需要几分钟的时间,这会导致整个程序无法工作。所以 STW 和栈扫描是一个可以抢占的安全点(Safe-points), Go 语言在这里先加入抢占功能。基于信号的抢占式调度只解决了垃圾回收和栈扫描时存在的问题,它到目前为止没有解决全部问题。
抢占调度示例
假设在一个单核 CPU 的机器上开两个 Goroutine,其中一个执行死循环,运行结果会是怎么样的呢?
在单核 CPU 的情况下,此时 P 只有一个,两个 Goroutine 可以理解为 Main Goroutine + 一个新的 Goroutine 死循环,类似如下:
func main() {
// 模拟单核 CPU
runtime.GOMAXPROCS(1)
go func() {
for {
}
}()
time.Sleep(time.Millisecond)
fmt.Println("能不能运行到这里呢?")
}
在 Go1.14 之前,不会输出任何结果;在 Go1.14 之后,由于引入了基于信号的抢占式调度,能够正常输出结果。
在 1.14 前,基于协作的抢占式调度,需要发生函数调用时才能够抢占,这段程序中没有涉及主动放弃执行权的调用(runtime.Gosched),又或是其他调用(可能会导致执行权转移)的行为。因此这个 Goroutine 是没机会溜号的,只能一直打工…
那为什么主协程(Main Goroutine)会无法运行呢,其实原因是会优先调用休眠,但由于单核 CPU,其只有唯一的 P。唯一的 P 又一直在打工不愿意下班(执行 for 死循环,被迫无限加班)。
因此主协程永远没有机会被调度,所以这个 Go 程序自然也就一直阻塞在了执行死循环的 Goroutine 中,永远无法下班(执行完毕,退出程序)。
网络同步非阻塞的实现
go 写后台最舒服的就是能够以同步写代码的方式操作网络,但是网络操作不阻塞线程。这里主要是用户态的协程结合 epoll, nonblock 模式的fd操作,在网络操作未 ready 时切换协程,ready 后把相关协程添加到待运行队列。从而使网络操作达到既不阻塞线程,又是同步执行流的效果。
Go 在这里实现了以下几个点:
- 封装epoll, 有网络操作时会 epollcreate 一个 epfd
- 所有网络 fd 均通过 fcntl 设置为 NONBLOCK 模式,以边缘触发模式放入 epoll 节点中
- 对网络 fd 执行 Accept(syscall.accept4),Read(syscall.read),Write(syscall.write)操作时,相关操作未 ready,则系统调用会立即返回EAGAIN;使用gopark切换该协程
- 在不同的时机, 通过 epollwait 来获取 ready 的 epollevents,通过其中 data 指针可获取对应的 g,将其置为待运行状态, 添加到 runq
综上,通过结合非阻塞的fd,epoll,以及协程的切换和恢复,Go实现了网络的非阻塞操作。linux提供了网络 fd 的非阻塞模式,对于没有 ready 的非阻塞 fd 执行网络操作时,linux内核不阻塞线程,会直接返回EAGAIN,这个时候将协程状态设置为wait,然后 m 去调度其他协程。go 在初始化一个网络 fd 的时候,就会把这个 fd 使用 epollctl 加入到全局的 epoll 节点中,同时放入 epoll 中的还有 polldesc 的指针。
func netpollopen(fd uintptr, pd *pollDesc) int32 {
var ev epollevent
ev.events = _EPOLLIN | _EPOLLOUT | _EPOLLRDHUP | _EPOLLET
*(**pollDesc)(unsafe.Pointer(&ev.data)) = pd
return -epollctl(epfd, _EPOLL_CTL_ADD, int32(fd), &ev)
}
在 sysmon 协程中,schedule函数被调用,start the world 等三种情况下,会执行 netpoll 调用 epollwait 系统调用,把 ready 的网络事件从 epoll 中取出来,每个网络事件可以通过前面传入的 polldesc 获取到阻塞在该网络事件上的协程,以此恢复协程为 runnable。
go func() 调度流程
基于上面的模型,当我们使用 go func() 创建一个新的 goroutine 的时候,其调度流程如下:
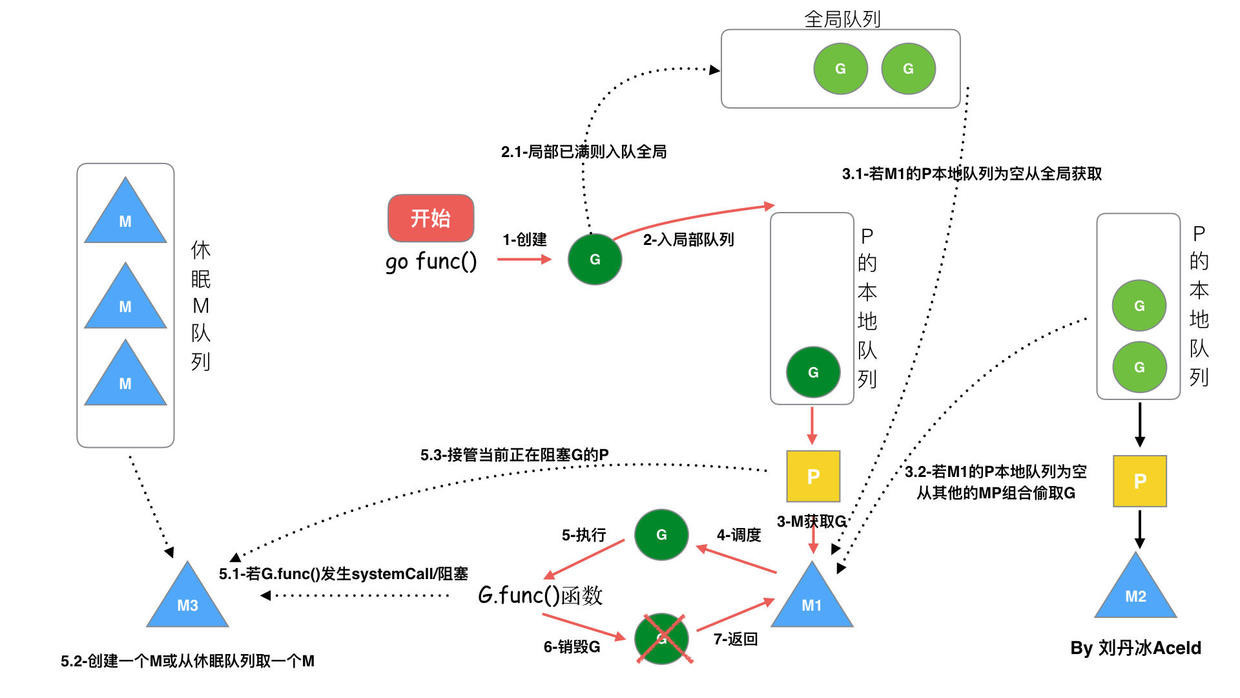
通过
go func ()来创建一个 goroutine;有两个存储 G 的队列,一个是局部调度器 P 的本地队列、一个是全局 G 队列。新创建的 G 会先保存在 P 的本地队列中,如果 P 的本地队列已经满了就会保存在全局的队列中;
G 只能运行在 M 中,一个 M 必须持有一个 P,M 与 P 是 1:1 的关系。M 会从 P 的本地队列弹出一个可执行状态的 G 来执行,如果 P 的本地队列为空,就会想其他的 MP 组合偷取一个可执行的 G 来执行;
一个 M 调度 G 执行的过程是一个循环机制;
当 M 执行某一个 G 时候如果发生了 syscall 或则其余阻塞操作,M 会阻塞,如果当前有一些 G 在执行,runtime 会把这个线程 M 从 P 中摘除 (detach),然后再创建一个新的操作系统的线程 (如果有空闲的线程可用就复用空闲线程) 来服务于这个 P,从而可以执行其他的 G;
当 M 系统调用结束时候,这个 G 会尝试获取一个空闲的 P 执行,并放入到这个 P 的本地队列。如果获取不到 P,那么这个线程 M 变成休眠状态, 加入到空闲线程中,然后这个 G 会被放入全局队列中。
Goroutine 生命周期
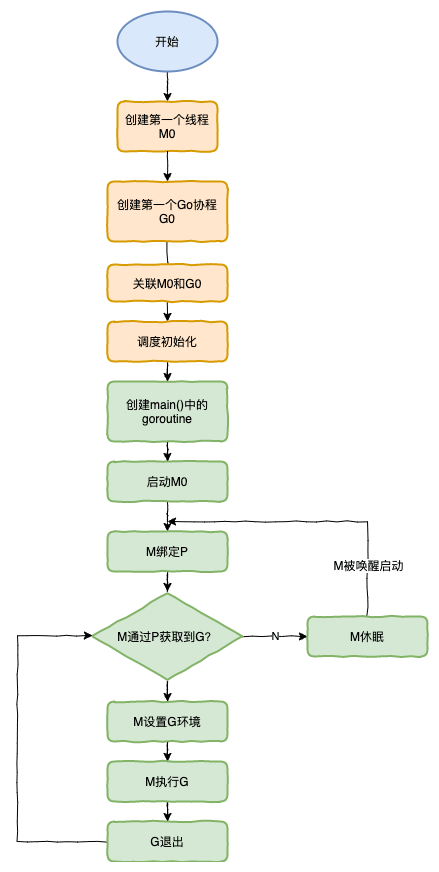
在这里有一个线程和一个 groutine 比较特殊,那就是 M0 和 G0:
M0:
M0是启动程序后的编号为 0 的主线程,这个 M 对应的实例会在全局变量runtime.m0中,不需要在 heap 上分配,M0 负责执行初始化操作和启动第一个 G, 在之后 M0 就和其他的 M 一样了。G0 :
G0是每次启动一个 M 都会第一个创建的 gourtine,G0 仅用于负责调度的 G,G0 不指向任何可执行的函数,每个 M 都会有一个自己的 G0。在调度或系统调用时会使用 G0 的栈空间,全局变量的 G0 是 M0 的 G0。
对于下面的简单代码:
package main
import "fmt"
// main.main
func main() {
fmt.Println("Hello scheduler")
}
其运行时所经历的过程跟上面的生命周期相对应:
- runtime 创建最初的线程 m0 和 goroutine g0,并把 2 者关联。
- 调度器初始化:初始化 m0、栈、垃圾回收,以及创建和初始化由 GOMAXPROCS 个 P 构成的 P 列表。
- 示例代码中的 main 函数是
main.main,runtime中也有 1 个 main 函数——runtime.main,代码经过编译后,runtime.main会调用main.main,程序启动时会为runtime.main创建 goroutine,称它为main goroutine,然后把main goroutine加入到P的本地队列。 - 启动 m0,m0 已经绑定了 P,会从 P 的本地队列获取 G,获取到
main goroutine。 - G 拥有栈,M 根据 G 中的栈信息和调度信息设置运行环境
- M 运行 G
- G 退出,再次回到 M 获取可运行的 G,这样重复下去,直到
main.main退出,runtime.main执行 Defer 和 Panic 处理,或调用runtime.exit退出程序。
调度器的生命周期几乎占满了一个Go程序的一生,runtime.main 的 goroutine 执行之前都是为调度器做准备工作,runtime.main 的 goroutine 运行,才是调度器的真正开始,直到 runtime.main 结束而结束。
Goroutine 调度器场景分析
场景一
p1 拥有 g1,m1 获取 p1 后开始运行g1,g1 使用 go func() 创建了 g2,为了局部性 g2 优先加入到 p1 的本地队列:
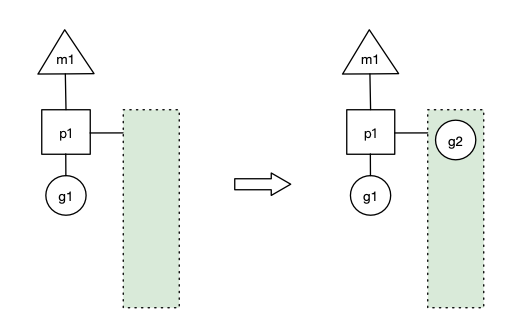
场景二
g1运行完成后(函数:goexit),m 上运行的 goroutine 切换为 g0,g0 负责调度时协程的切换(函数:schedule)。从 p1 的本地队列取 g2,从 g0 切换到 g2,并开始运行 g2 (函数:execute)。实现了线程 m1 的复用。
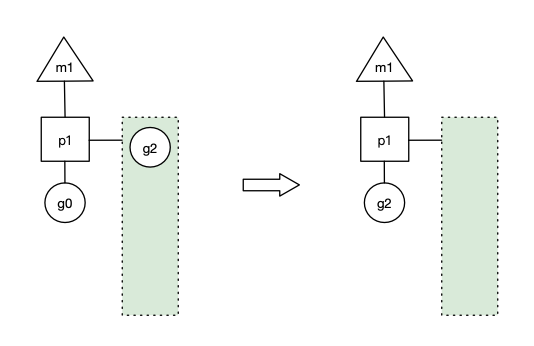
场景三
假设每个 p 的本地队列只能存 4 个 g。g2 要创建 6 个 g,前 4 个g(g3, g4, g5, g6)已经加入 p1 的本地队列,p1 本地队列满了。
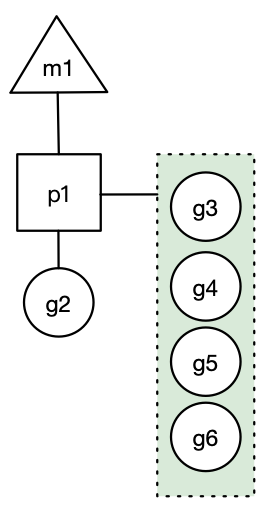
g2 在创建 g7 的时候,发现 p1 的本地队列已满,需要执行负载均衡,把 p1 中本地队列中前一半的 g,还有新创建的 g 转移到全局队列
实现中并不一定是新的 g,如果 g 是 g2 之后就执行的,会被保存在本地队列,利用某个老的 g 替换新 g 加入全局队列),这些 g 被转移到全局队列时,会被打乱顺序。
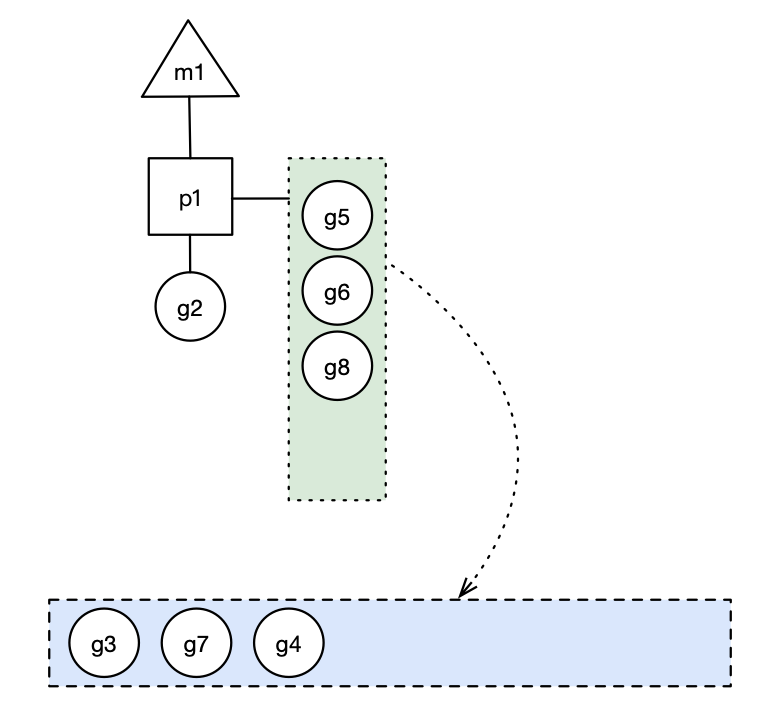
所以 g3,g4,g7 被转移到全局队列。
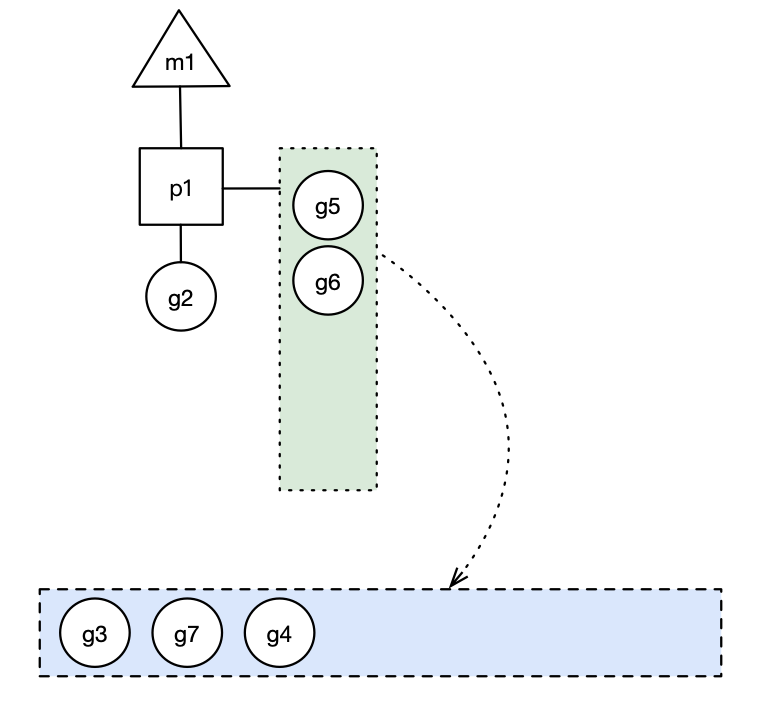
蓝色长方形代表全局队列。
如果此时 G2 创建 G8 时,P1 的本地队列未满,所以 G8 会被加入到 P1 的本地队列:
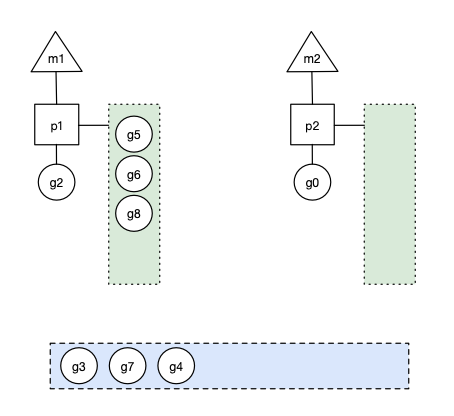
场景四
在创建 g 时,运行的 g 会尝试唤醒其他空闲的 p 和 m 组合去执行。假定 g2 唤醒了 m2,m2 绑定了 p2,并运行 g0,但 p2 本地队列没有 g,m2 此时为自旋线程(没有 G 但为运行状态的线程,不断寻找 g)。
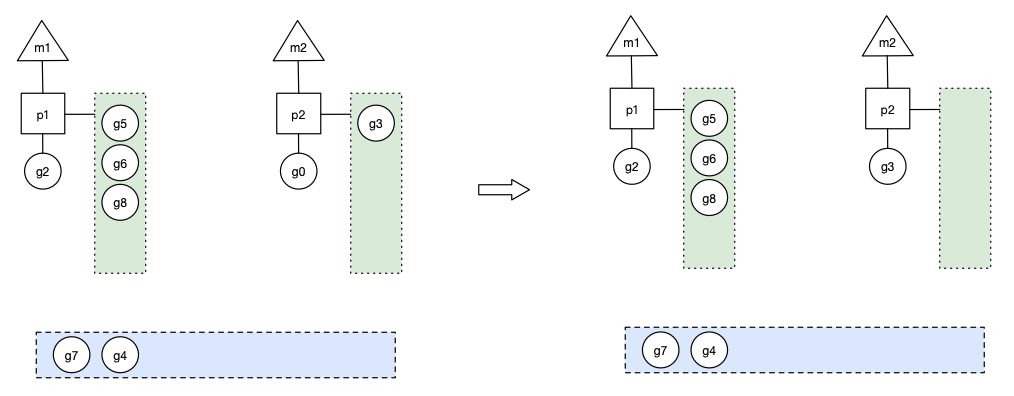
m2 接下来会尝试从全局队列 (GQ) 取一批 g 放到 p2 的本地队列(函数:findrunnable)。m2 从全局队列取的 g 数量符合下面的公式:
n = min(len(GQ)/GOMAXPROCS + 1, len(GQ/2))
公式的含义是,至少从全局队列取 1 个 g,但每次不要从全局队列移动太多的 g 到 p 本地队列,给其他 p 留点。这是从全局队列到 P 本地队列的负载均衡。
假定场景中一共有 4 个 P(GOMAXPROCS=4),所以 m2 只从能从全局队列取 1 个 g(即 g3)移动 p2 本地队列,然后完成从 g0 到 g3 的切换,运行 g3:
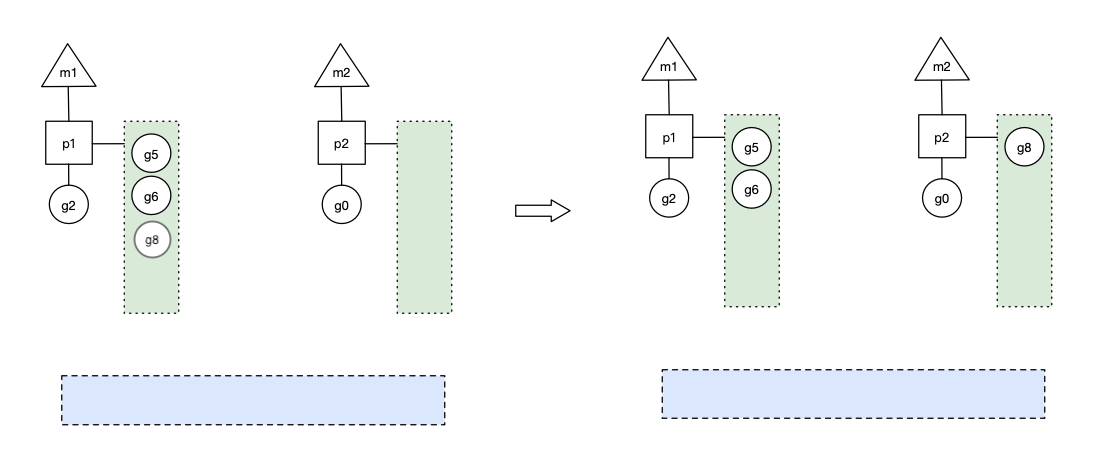
场景五
假设 g2 一直在 m1上运行,经过 2 轮后,m2 已经把 g7、g4 也挪到了p2的本地队列并完成运行,全局队列和 p2 的本地队列都空了,如下图左边所示。
全局队列已经没有 g,那 m 就要执行 work stealing:从其他有 g 的 p 哪里偷取一半 g 过来,放到自己的 P 本地队列。p2 从 p1 的本地队列尾部取一半的 g,本例中一半则只有 1 个 g8,放到 p2 的本地队列,情况如下图右边:
场景六
p1 本地队列 g5、g6 已经被其他 m 偷走并运行完成,当前 m1 和 m2 分别在运行 g2 和 g8,m3 和 m4 没有goroutine 可以运行,m3 和 m4 处于自旋状态,它们不断寻找 goroutine。
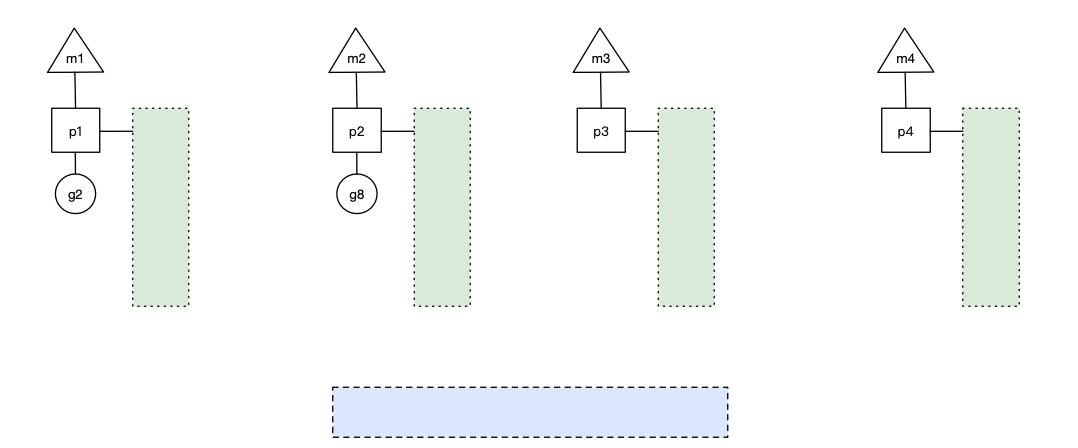
这里有一个问题,为什么要让 m3 和 m4 自旋?自旋本质是在运行,线程在运行却没有执行 g,就变成了浪费CPU,销毁线程可以节约CPU资源不是更好吗?实际上,创建和销毁CPU都是浪费时间的,我们希望当有新 goroutine 创建时,立刻能有 m 运行它,如果销毁再新建就增加了时延,降低了效率。当然也考虑了过多的自旋线程是浪费 CPU,所以系统中最多有 GOMAXPROCS 个自旋的线程,多余的没事做的线程会让他们休眠(函数:notesleep() 实现了这个思路)。
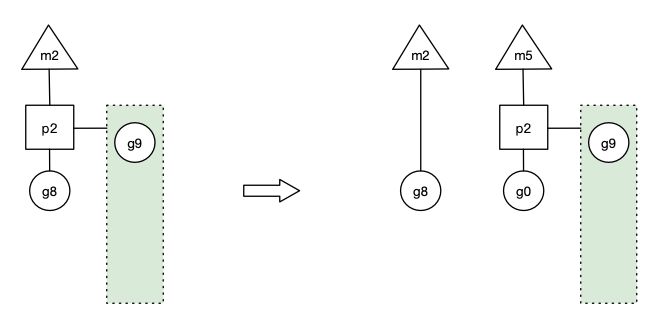
场景七
假定当前除了 m3 和 m4 为自旋线程,还有 m5 和 m6 为自旋线程,g8 创建了 g9,g9 会放入本地队列。假如此时g8 进行了阻塞的系统调用,m2 和 p2 立即解绑,p2 会执行以下判断:如果 p2 本地队列有 g、全局队列有 g 或有空闲的 m,p2 都会立马唤醒1个 m 和它绑定,否则 p2 则会加入到空闲 P 列表,等待 m 来获取可用的 p。本场景中,p2 本地队列有 g,可以和其他自旋线程 m5 绑定。
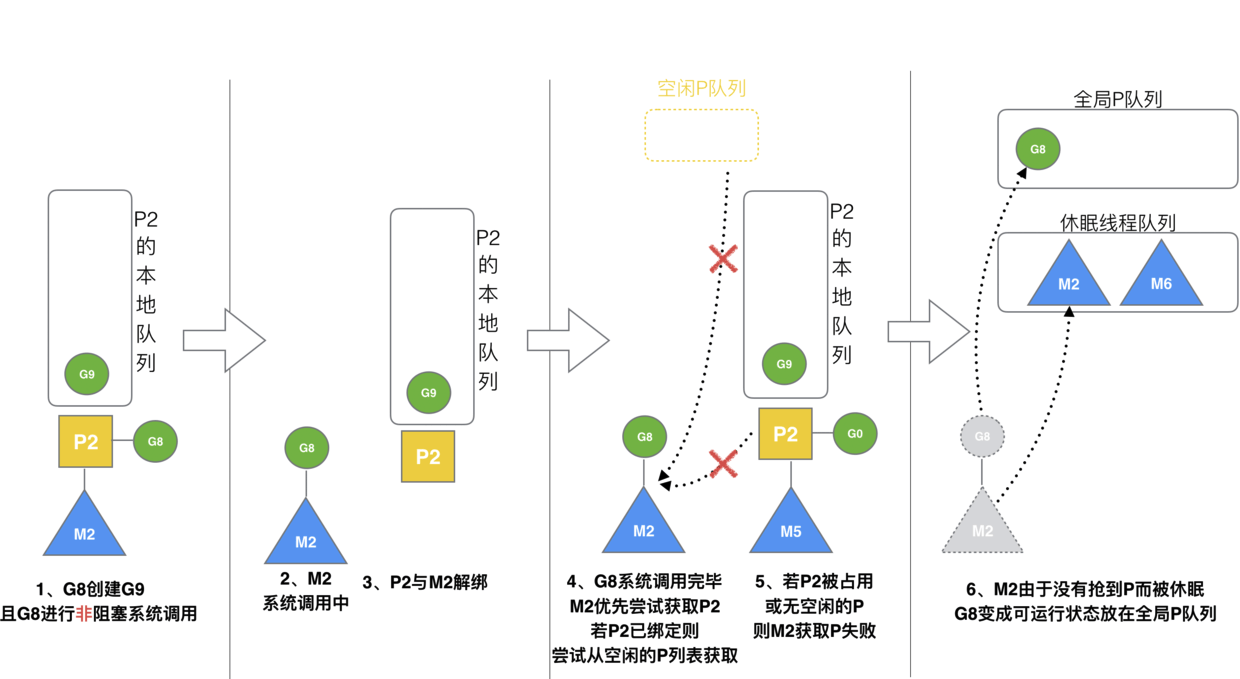
场景八
假设 g8 创建了 g9,假如 g8 进行了非阻塞系统调用(CGO会是这种方式,见cgocall()),m2 和 p2 会解绑,但 m2 会记住 p,然后 g8 和 m2 进入系统调用状态。当 g8 和 m2 退出系统调用时,会尝试获取 p2,如果无法获取,则获取空闲的 p,如果依然没有,g8 会被记为可运行状态,并加入到全局队列。
场景九
前面说过,Go 调度在 go1.12 实现了抢占,应该更精确的称为基于协作的请求式抢占,那是因为 go 调度器的抢占和 OS 的线程抢占比起来很柔和,不暴力,不会说线程时间片到了,或者更高优先级的任务到了,执行抢占调度。go 的抢占调度柔和到只给 goroutine 发送 1 个抢占请求,至于 goroutine 何时停下来,那就管不到了。抢占请求需要满足2个条件中的1个:
- G 进行系统调用超过 20us
- G 运行超过 10ms。调度器在启动的时候会启动一个单独的线程 sysmon,它负责所有的监控工作,其中 1 项就是抢占,发现满足抢占条件的 G 时,就发出抢占请求。
状态汇总
从上面的场景中可以总结各个模型的状态:
G状态
G的主要几种状态:
| 状态 | 描述 |
|---|---|
_Gidle |
刚刚被分配并且还没有被初始化,值为0,为创建goroutine后的默认值 |
_Grunnable |
没有执行代码,没有栈的所有权,存储在运行队列中,可能在某个P的本地队列或全局队列中 |
_Grunning |
正在执行代码的goroutine,拥有栈的所有权 |
_Gsyscall |
正在执行系统调用,拥有栈的所有权,没有执行用户代码,被赋予了内核线程 M 但是不在运行队列上 |
_Gwaiting |
由于运行时而被阻塞,没有执行用户代码并且不在运行队列上,但是可能存在于 Channel 的等待队列上 |
_Gdead |
当前goroutine未被使用,没有执行代码,可能有分配的栈,分布在空闲列表 gFree,可能是一个刚刚初始化的 goroutine,也可能是执行了 goexit 退出的 goroutine |
_Gcopystack |
栈正在被拷贝,没有执行代码,不在运行队列上 |
_Gpreempted |
由于抢占而被阻塞,没有执行用户代码并且不在运行队列上,等待唤醒 |
_Gscan |
GC 正在扫描栈空间,没有执行代码,可以与其他状态同时存在 |
P 状态
| 状态 | 描述 |
|---|---|
_Pidle |
处理器没有运行用户代码或者调度器,被空闲队列或者改变其状态的结构持有,运行队列为空 |
_Prunning |
被线程 M 持有,并且正在执行用户代码或者调度器 |
_Psyscall |
没有执行用户代码,当前线程陷入系统调用 |
_Pgcstop |
被线程 M 持有,当前处理器由于垃圾回收被停止 |
_Pdead |
当前处理器已经不被使用 |
M 状态
自旋线程:处于运行状态但是没有可执行 goroutine 的线程,数量最多为 GOMAXPROC,若是数量大于 GOMAXPROC 就会进入休眠。
非自旋线程:处于运行状态有可执行 goroutine 的线程。
调度器设计
从上面的流程可以总结出 goroutine 调度器的一些设计思路:
调度器设计的两大思想
复用线程:协程本身就是运行在一组线程之上,所以不需要频繁的创建、销毁线程,而是对线程进行复用。在调度器中复用线程还有2个体现:
- work stealing,当本线程无可运行的 G 时,尝试从其他线程绑定的 P 偷取 G,而不是销毁线程。
- hand off,当本线程因为 G 进行系统调用阻塞时,线程释放绑定的 P,把 P 转移给其他空闲的线程执行。
利用并行:GOMAXPROCS 设置 P 的数量,当 GOMAXPROCS 大于 1 时,就最多有 GOMAXPROCS 个线程处于运行状态,这些线程可能分布在多个 CPU 核上同时运行,使得并发利用并行。另外,GOMAXPROCS 也限制了并发的程度,比如 GOMAXPROCS = 核数/2,则最多利用了一半的 CPU 核进行并行。
调度器设计的两小策略
抢占:在 coroutine 中要等待一个协程主动让出 CPU 才执行下一个协程,在 Go 中,一个 goroutine 最多占用CPU 10ms,防止其他 goroutine 被饿死,这就是 goroutine 不同于 coroutine 的一个地方。
全局G队列:在新的调度器中依然有全局 G 队列,但功能已经被弱化了,当 M 执行 work stealing 从其他 P 偷不到 G 时,它可以从全局 G 队列获取 G。
总结
- 轻量级的协程, 栈初始2KB, 调度不涉及系统调用
- 调度在计算机中是分配工作所需资源的方法。linux的调度为CPU找到可运行的线程,而Go的调度是为M(线程)找到P(内存, 执行票据)和可运行的G.
- 用户函数调用前会检查栈空间是否足够, 不够的话, 会进行*2 栈扩容. 最大栈1G, 超出panic.
- 用户代码中的协程同步造成的阻塞, 仅仅是切换(gopark)协程, 而不阻塞线程, m和p仍结合, 去寻找新的可执行的g.
- 每个P均有local runq, 大多数时间仅与local runq无锁交互. 新生成的g, 放入到local runq中.
- 调度时会随机从全局runq取g. 然后local runq, global runq… 均没有g的话, work stealing从其他P中取.
- sysmon: 对于运行过久的g设置抢占标识; 对于过久syscall的p, 进行m和p的分离. 防止p被占用过久影响调度.
- 封装了epoll, 网络fd会设置成NonBlocking模式, 网络fd的read, write, accept操作, 会以NonBlocking模式操作, 返回EAGAIN则gopark当前协程. 在m调度, sysmon中, gc start the world等阶段均会poll出ready的协程进行运行或者添加到全局runq中
GPM 可视化调试
有 2 种方式可以查看一个程序 GPM 的数据:
go tool trace
trace 记录了运行时的信息,能提供可视化的Web页面。
简单测试代码:main 函数创建 trace,trace 会运行在单独的 goroutine 中,然后 main 打印 “Hello trace” 退出。
func main() {
// 创建trace文件
f, err := os.Create("trace.out")
if err != nil {
panic(err)
}
defer f.Close()
// 启动trace goroutine
err = trace.Start(f)
if err != nil {
panic(err)
}
defer trace.Stop()
// main
fmt.Println("Hello trace")
}
运行程序和运行trace:
$ go run trace.go
Hello World
会得到一个 trace.out 文件,然后可以用一个工具打开,来分析这个文件:
$ go tool trace trace.out
2020/12/07 23:09:33 Parsing trace...
2020/12/07 23:09:33 Splitting trace...
2020/12/07 23:09:33 Opening browser. Trace viewer is listening on http://127.0.0.1:56469
接下来通过浏览器打开 http://127.0.0.1:33479 网址,点击 view trace 能够看见可视化的调度流程:

g 信息
点击 Goroutines 那一行的数据条,会看到一些详细的信息:
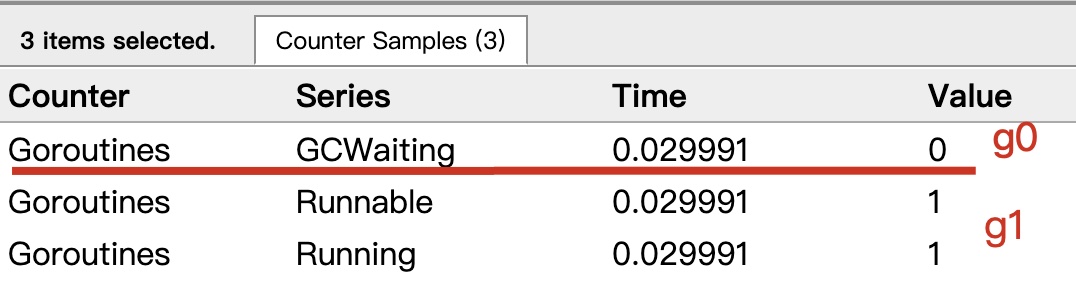
上面表示一共有两个 G 在程序中,一个是特殊的 G0,是每个 M 必须有的一个初始化的 G。其中 G1 就是 main goroutine (执行 main 函数的协程),在一段时间内处于可运行和运行的状态。
m 信息
点击 Threads 那一行可视化的数据条,会看到一些详细的信息:
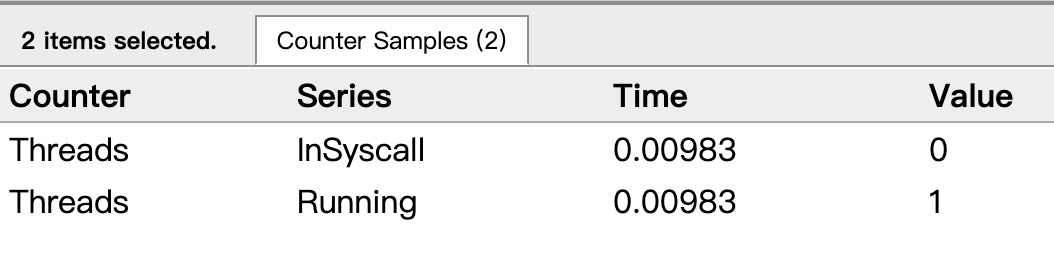
这里一共有两个 M 在程序中,一个是特殊的 M0,用于初始化使用。
p 信息

G1 中调用了 main.main,创建了 trace goroutine g6。G1 运行在 P0 上,G6运行在 P1 上。
这里有三个 P。
在看看上面的 M 信息:

可以看到确实 G6 在 P1 上被运行之前,确实在 Threads 行多了一个 M 的数据,点击查看如下:
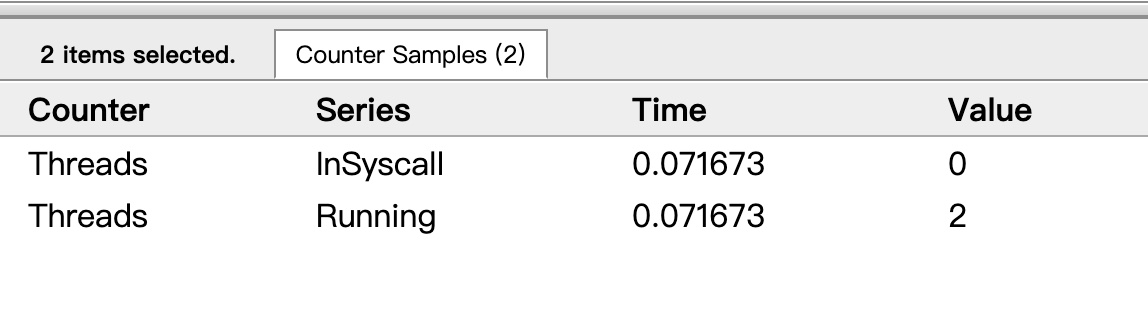
多了一个 M2 应该就是 P1 为了执行 G6 而动态创建的 M2。
Debug trace
示例代码:
// main.main
func main() {
for i := 0; i < 5; i++ {
time.Sleep(time.Second)
fmt.Println("Hello scheduler")
}
}
编译后通过 Debug 方式运行,运行过程会打印trace:
➜ go build .
➜ GODEBUG=schedtrace=1000 ./one_routine2
结果:
SCHED 0ms: gomaxprocs=4 idleprocs=2 threads=3 spinningthreads=1 idlethreads=0 runqueue=0 [1 0 0 0]
Hello scheduler
SCHED 1003ms: gomaxprocs=4 idleprocs=4 threads=5 spinningthreads=0 idlethreads=3 runqueue=0 [0 0 0 0]
Hello scheduler
SCHED 2007ms: gomaxprocs=4 idleprocs=4 threads=5 spinningthreads=0 idlethreads=3 runqueue=0 [0 0 0 0]
Hello scheduler
SCHED 3010ms: gomaxprocs=4 idleprocs=4 threads=5 spinningthreads=0 idlethreads=3 runqueue=0 [0 0 0 0]
Hello scheduler
SCHED 4013ms: gomaxprocs=4 idleprocs=4 threads=5 spinningthreads=0 idlethreads=3 runqueue=0 [0 0 0 0]
Hello scheduler
各个字段的含义如下:
SCHED:调试信息输出标志字符串,代表本行是 goroutine 调度器的输出;0ms:即从程序启动到输出这行日志的时间;gomaxprocs: P的数量,本例有 4 个P;idleprocs: 处于 idle (空闲)状态的 P 的数量;通过gomaxprocs和idleprocs的差值,就可以知道执行 go 代码的 P 的数量;threads: os threads/M 的数量,包含 scheduler 使用的 m 数量,加上 runtime 自用的类似 sysmon 这样的 thread 的数量;spinningthreads: 处于自旋状态的 os thread 数量;idlethread: 处于 idle 状态的 os thread 的数量;runqueue=0: Scheduler 全局队列中 G 的数量;[0 0 0 0]: 分别为 4 个 P 的 local queue 中的 G 的数量。
看第一行,含义是:刚启动时创建了 4 个P,其中 2 个空闲的 P,共创建 3 个M,其中 1 个 M 处于自旋,没有 M 处于空闲,第一个 P 的本地队列有一个 G。
另外,可以加上 scheddetail=1 可以打印更详细的 trace 信息。
命令:
➜ GODEBUG=schedtrace=1000,scheddetail=1 ./one_routine2
参考文档: