项目经验
1. 数据库
- 数据表分类可以通过添加
parent_id以及“第几级分类”字段来进行级别划分,避免一个级别建一个数据表的操作。 - 使用业务无关自增 id 作为主键:
- 防止后期业务发生变化需要重构某个字段(方便业务扩展);
- 如果表使用自增主键,那么每次插入新的记录,记录就会顺序添加到当前索引节点的后续位置,当一页写满,就会自动开辟一个新的页。如果不是自增主键,那么可能会在中间插入,在中间插入,B+ 树为了维持平衡,引起B+ 树的节点分裂。 总的来说用自增主键是可以提高查询和插入的性能。(性能考量)
- 课程模块:
- 课程分类作为一张表
- 课程作为一个单独的表
- 课程内容表(一个课程对应多集课程内容)
- 课程练习表(一集对应多道练习题:选择、填空)
- 课程评价表
- 用户模块
- 用户信息表
- 用户订单表
- 用户观看历史表
- 用户答题信息表
- 题库模块
- 试卷信息表
- 题目信息表(所属试卷,题型题号,正确答案等)
- 选项信息表
2. 项目使用的技术
使用 Redis
项目中使用 Redis 实现短信验证码的存储验证以及观看视频历史缓存。
短信存储验证
使用 String 字符串,随机生成字符数字拼接后传入字符串。
public CommonResult generateAuthCode(String telephone) {
StringBuilder sb = new StringBuilder();
Random random = new Random();
for (int i = 0; i < 6; i++) {
sb.append(random.nextInt(10));
}
//验证码绑定手机号并存储到redis
redisService.set(REDIS_KEY_PREFIX_AUTH_CODE + telephone, sb.toString());
redisService.expire(REDIS_KEY_PREFIX_AUTH_CODE + telephone, AUTH_CODE_EXPIRE_SECONDS);
return CommonResult.success(sb.toString(), "获取验证码成功");
}
验证:
public CommonResult verifyAuthCode(String telephone, String authCode) {
if (StringUtils.isEmpty(authCode)) {
return CommonResult.failed("请输入验证码");
}
String realAuthCode = redisService.get(REDIS_KEY_PREFIX_AUTH_CODE + telephone);
boolean result = authCode.equals(realAuthCode);
if (result) {
return CommonResult.success(null, "验证码校验成功");
} else {
return CommonResult.failed("验证码不正确");
}
}
集数缓存
使用 Set 集合保存用户观看的集数,用数字表示(利用不允许有重复元素,并且集合中的元素是无序的)
存储:
if(Redis::exists('education2_video_number_usr:'.$user->id.'_number:'.$courseId)){
Redis::sAdd('education2_video_number_usr:'.$user->id.'_number:'.$courseId, $currentNumber);
}else{
Redis::sAdd('education2_video_number_usr:'.$user->id.'_number:'.$courseId, $currentNumber);
$course = Course::where('id',$courseId)->first();
$days = $course->days;
Redis::expire('education2_video_number_usr:'.$user->id.'_number:'.$courseId,60*60*24*$days+60*60*24*365);
}
获取:
$numbers = Redis::smembers('education2_video_number_usr:'.$user->id.'_number:'.$courseId);
热搜功能
使用 Zset 实现热搜功能:将<搜索词,词频>放到 Redis 缓存中,同时将搜索时间通过 String 存入<搜索词,时间>,通过 SpringTask 定时任务每五分钟进行一次获取,同时判断时间是否超过一周,超过一周热度归零。
//首先注入RedisTemplate
private RedisTemplate<Object, Object> template;
//入参每次搜索时输入的字符串,每次都放入ZSet中
if (StringUtils.isNotBlank(searchStr)) {
//将查询参数添加到redis的zset中
template.opsForZSet().incrementScore("hwords", searchStr, 1);
//时间存入
valueOperations.getAndSet(searchStr, now);
}
//获取热词
public List getRedisScoreMaxVal() {
List list = new ArrayList();
//参数1(redis的K值),参数2(从第几条开始),参数3(从0开始截取多少位)
Set<ZSetOperations.TypedTuple<Object>> typedTupleSet = template.opsForZSet().reverseRangeWithScores("hwords", 0, 4);
Iterator iterator = typedTupleSet.iterator();
while (iterator.hasNext()) {
ZSetOperations.TypedTuple<Object> typedTuple = (ZSetOperations.TypedTuple<Object>) iterator.next();
Object value = typedTuple.getValue();
if ((now - time) >= 2592000000L) {
//时间超过一个月没搜索就把这个词热度归0
zSetOperations.add("hwords", value, 0);
}
list.add(value);
//获取score值
double score = typedTuple.getScore();
}
return list;
}
SpringTask
在配置类中添加一个 @EnableScheduling 注解开启SpringTask的定时任务能力;
编写定时任务:
public class GetHotWordTask {
@Autowired
private SingleClass singleClass;//某一个存储热搜的单例对象
/**
* cron表达式:Seconds Minutes Hours DayofMonth Month DayofWeek [Year]
* 每5分钟扫描一次,扫描设定超时时间之前下的订单,如果没支付则取消该订单
*/
@@Scheduled(cron = "0 0/5 * ? * ?")
private void cancelTimeOutOrder() {
//这是一个单例的List
singleClass.hotWords = getRedisScoreMaxVal();
}
}
使用 SpringTask 的原因:SpringTask 是 Spring 自主研发的轻量级定时任务工具,相比于 Quartz 更加简单方便,且不需要引入其他依赖即可使用。将它看成一个轻量级的Quartz,使用起来比 Quartz 简单很多,在 Spring 应用中,直接使用 @Scheduled 注解即可,但对于集群项目比较麻烦,需要避免集群环境下任务被多次调用的情况,而且不能动态维护,任务启动以后不能修改、暂停等。
Timer:jdk自带的java.util.Timer类,这个类允许你调度一个java.util.TimerTask任务。使用这种方式可以让程序按照某一个频度执行,但不能在指定时间运行,一般很少使用,主要用于非Spring项目简单的任务调度。
使用 RabbitMQ进行异步处理
用于解决用户下单以后,订单超时如何取消订单的问题。
- 用户进行下单操作;
- 生成订单,获取订单的id;
- 获取到设置的订单超时时间(设置为30分钟不支付取消订单);
- 按订单超时时间发送一个延迟消息给RabbitMQ,让它在订单超时后触发取消订单的操作;
- 检查队列中订单的状态,如果为未付款,进行取消订单操作。
队列说明:
使用 Direct Exchange 处理路由键,之所以使用两个队列,是利用死信队列转发的特点实现延迟消费,不然到 MQ 里的消息如果不阻塞的话会被马上消费。
order.direct(取消订单消息队列所绑定的交换机):绑定的队列为order.cancel,一旦有消息以order.cancel为路由键发过来,会发送到此队列。direct.ttl(订单延迟消息队列所绑定的交换机):绑定的队列为order.cancel.ttl,一旦有消息以order.cancel.ttl为路由键发送过来,会转发到此队列,并在此队列保存一定时间,等到超时后会自动将消息发送到order.cancel(取消订单消息消费队列)。
设置 ttl 队列延迟转发到订单取消队列:
RabbitMQ 的 Queue 可以配置
x-dead-letter-exchange和x-dead-letter-routing-key(可选)两个参数,如果队列内出现了 dead letter,则按照这两个参数重新路由转发到指定的队列。
@Bean
public Queue orderTtlQueue() {
return QueueBuilder
.durable(QueueEnum.QUEUE_TTL_ORDER_CANCEL.getName())
.withArgument("x-dead-letter-exchange", QueueEnum.QUEUE_ORDER_CANCEL.getExchange())//到期后转发的交换机
.withArgument("x-dead-letter-routing-key", QueueEnum.QUEUE_ORDER_CANCEL.getRouteKey())//到期后转发的路由键
.build();
}
用户下单:
@Override
public CommonResult generateOrder(OrderParam orderParam) {
//todo 执行一系类下单操作,具体参考mall项目
LOGGER.info("process generateOrder");
//下单完成后开启一个延迟消息,用于当用户没有付款时取消订单(orderId应该在下单后生成)
//给延迟队列发送消息
amqpTemplate.convertAndSend(QueueEnum.QUEUE_TTL_ORDER_CANCEL.getExchange(), QueueEnum.QUEUE_TTL_ORDER_CANCEL.getRouteKey(), orderId, new MessagePostProcessor() {
@Override
public Message postProcessMessage(Message message) throws AmqpException {
//给消息设置延迟毫秒值
message.getMessageProperties().setExpiration(String.valueOf(delayTimes));
return message;
}
});
return CommonResult.success(null, "下单成功");
}
订单取消队列的操作:
@Component
@RabbitListener(queues = "mall.order.cancel")
public class CancelOrderReceiver {
private static Logger LOGGER =LoggerFactory.getLogger(CancelOrderReceiver.class);
@Autowired
private OmsPortalOrderService portalOrderService;
@RabbitHandler
public void handle(Long orderId){
LOGGER.info("receive delay message orderId:{}",orderId);
portalOrderService.cancelOrder(orderId);
}
}
优化:对于订单取消回滚,涉及到许多操作,以后业务扩展会有更多操作需要回滚,可以使用模版方法模式。
使用七牛云 CDN 存储视频、图片等文件
CDN 加速 (将一些静态资源比如图片、视频等等缓存到离用户最近的网络节点)
使用连接池(数据库连接池)
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="${jdbc.driver}"/>
<property name="url" value="${jdbc.url}"/>
<property name="username" value="${jdbc.username}"/>
<property name="password" value="${jdbc.password}"/>
</dataSource>
</environment>
</environments>
- POOLED: 使用连接池,可以设置
poolMaximumActiveConnection最大连接数量;poolMaximumIdleConnections最大空闲数;poolMaximumCheckoutTime在被强制返回之前连接超时时间,默认20000毫秒(20秒);poolTimeWait超时时间(默认20秒)等等
多线程开发(线程池)
后台管理系统用于上传课程文件,因为视频文件较大(几十兆到几百兆),所以使用多线程开发,在文件上传控制器上开一个子进程进行文件上传以及更新地址操作,主线程写入数据库信息后直接返回,同时后台管理系统状态栏显示“文件上传中”,当子线程完成后显示文件地址。
做登录业务时使用到 sms 短信网关业务,创建子线程,让子线程去调用 sms 服务,主线程则返回,提高用户的体验度
使用JWT进行单点登录
创建JWT token工具类,包括根据用户信息生成 token,从 token 中获取 jwt 的负载,从 token 中获取用户名,设置 token 过期时间,刷新 token 等等。
使用Spring Security进行相关配置
3. 如何提升网站性能,可用性以及并发量/如何设计一个高并发的系统
- 采用分布式开发,不同的服务部署在不同的机器节点上,并且一个服务也可以部署在多台机器上进行集群,然后利用 Nginx 负载均衡访问。这样就解决了单点部署(All In)的缺点,大大提高的系统并发量,扛住初步的并发压力
- 数据库分库分表(水平分表、垂直分表)+ 读写分离
- 使用缓存(本地缓存:本地可以使用JDK自带的 Map、Guava Cache.分布式缓存:Redis、Memcache.本地缓存不适用于提高系统并发量,一般是用在程序中。比如Spring是如何实现单例的呢?大家如果看过源码的话,应该知道,Spring把已经初始过的变量放在一个Map中,下次再要使用这个变量的时候,先判断Map中有没有,这也就是系统中常见的单例模式的实现。)大部分的高并发场景,都是读多写少,那完全可以在数据库和缓存里都写一份,然后读的时候大量走缓存就可以了。
- 消息队列 (解耦+削峰+异步)
- 提高硬件能力、增加系统服务器。(当服务器增加到某个程度的时候系统所能提供的并发访问量几乎不变,所以不能根本解决问题)
- CDN 加速 (将一些静态资源比如图片、视频等等缓存到离用户最近的网络节点)
- 浏览器缓存
- 使用合适的连接池(数据库连接池、线程池等等)
- 适当使用多线程进行开发。
4. 设计高可用系统的常用手段
- 降级: 服务降级是当服务器压力剧增的情况下,根据当前业务情况及流量对一些服务和页面有策略的降级,以此释放服务器资源以保证核心任务的正常运行。降级往往会指定不同的级别,面临不同的异常等级执行不同的处理。根据服务方式:可以拒接服务,可以延迟服务,也有时候可以随机服务。根据服务范围:可以砍掉某个功能,也可以砍掉某些模块。总之服务降级需要根据不同的业务需求采用不同的降级策略。主要的目的就是服务虽然有损但是总比没有好;
- 限流: 防止恶意请求流量、恶意攻击,或者防止流量超出系统峰值;
- 熔断:当一个服务因为各种原因停止响应时,调用方通常会等待一段时间,然后超时或者收到错误返回。如果调用链路比较长,可能会导致请求堆积,整条链路占用大量资源一直在等待下游响应。所以当多次访问一个服务失败时,应熔断,标记该服务已停止工作,直接返回错误。直至该服务恢复正常后再重新建立连接。
- 缓存: 避免大量请求直接落到数据库,将数据库击垮;
- 超时和重试机制: 避免请求堆积造成雪崩;
- 回滚机制: 快速修复错误版本。
- 进行资源隔离:使系统在故障的情况下,不会耗尽系统的所有资源,比如线程资源
- 服务监控
5. 现代互联网应用系统通常具有哪些特点?
- 高并发,大流量;
- 高可用:系统7×24小时不间断服务;
- 海量数据:需要存储、管理海量数据,需要使用大量服务器;
- 用户分布广泛,网络情况复杂:许多大型互联网都是为全球用户提供服务的,用户分布范围广,各地网络情况千差万别;
- 安全环境恶劣:由于互联网的开放性,使得互联网更容易受到攻击,大型网站几乎每天都会被黑客攻击;
- 需求快速变更,发布频繁:和传统软件的版本发布频率不同,互联网产品为快速适应市场,满足用户需求,其产品发布频率是极高的;
- 渐进式发展:与传统软件产品或企业应用系统一开始就规划好全部的功能和非功能需求不同,几乎所有的大型互联网网站都是从一个小网站开始,渐进地发展起来。
6. 项目遇到了什么问题
php开发和java开发问题
项目前期用的是 php 开发,后面因为我们使用的技术栈是java,所以在用户登录认证统一上存在问题;另外 PHP 使用的服务器是 nginx,Java使用的服务器是Tomcat。
解决方案:使用 JWT token 作为登录凭证,两者都可以都 token 进行解析,同时利用 Nginx 的反向代理配置访问 Java 模块后台接口。
跨域问题
项目前后端分析,前端使用 Nginx 作为服务器,后台使用 Tomcat,在对接接口时发现前端一直无法访问后台接口。
解决方案:通过 Nginx 反向代理访问后台接口,同时在 Nginx 中通过跨域资源共享 CORS 解决跨域问题。
# 表示允许全部站点
add_header 'Access-Control-Allow-Origin' '*';
# 为true的时候指请求时可带上Cookie
add_header 'Access-Control-Allow-Credentials' 'true';
# 表示允许哪些方式
add_header 'Access-Control-Allow-Methods' 'POST,GET,OPTION,DELETE';
# 允许的请求头
add_header 'Access-Control-Allow-Headers' 'X-Requested-With,Authorization';
后台管理系统上传视频文件速度慢问题
甲方反应后台管理系统在上传视频文件速度较慢,需要等的时间较长。
解决方案:在文件上传控制器上开一个子进程进行文件上传以及更新地址操作,主线程写入数据库信息后直接返回,同时后台管理系统状态栏显示“文件上传中”,当子线程完成后显示文件地址。
@RestController
@SpringBootApplication
public class UploadController {
@Autowired
private UploadService uploadService;
@RequestMapping("/Upload")
public String uploadQiniu(@RequestParam MultipartFile file, HttpServletRequest request) throws IOException {
//TODO:写入数据库,地址字段写"文件上传中..."
//TODO:优化:使用线程池
Thread uploadThrea = new Thread(new Runnable() {
@Override
public void run() {
String result;
if(file.isEmpty()) {
result = "文件为空";
} else {
try {
result = uploadService.uploadFileQiniu(file,request);
//TODO:将地址写入数据库
} catch (IOException e) {
e.printStackTrace();
}
}
}
});
uploadThrea.start();
return "文件上传中...";
}
}
热搜功能实现
- 使用 Redis 中 Zset 数据结构实现
- 使用 HashMap 进行
<搜索词,词频>存储,每五分钟通过SpringTask定时任务对 HashMap 进行一次堆(最小堆)排序,然后后序遍历最小堆。
敏感词汇过滤
有以下方法:
- 每次从 redis 中取出敏感词集合,然后做遍历操作,使用 indexOf 查看是否出现在聊天消息中
- 正则匹配
- KMP匹配
- DFA字典树实现(当敏感词库较大时,占用较大内存空间,效率上没问题)
DFA 简介
DFA 即 Deterministic Finite Automaton,也就是确定有穷自动机,它是是通过 event 和当前的 state 得到下一个 state,即 event+state=nextstate。下图展示了其状态的转换:
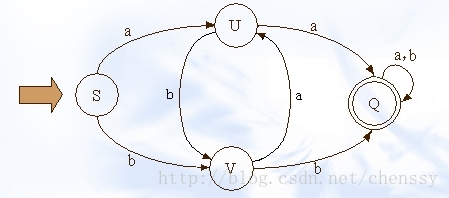
定义:一个确定有穷自动机(DFA)M 是一个五元组:M=(K,Σ,f,S,Z)其中
- K 是一个有穷集,它的每个元素称为一个状态;
- Σ 是一个有穷字母表,它的每个元素称为一个输入符号,所以也称 Σ 为输入符号字母表;
- f 是转换函数,是
K×Σ→K上的映射(且可以是部分函数),即,如 f(ki,a)=kj,(ki∈K,kj∈K)就意味着,当前状态为 ki,输入符为 a 时,将转换为下一个状态 kj,我们把 kj 称作 ki 的一个后继状态; S ∈ K是唯一的一个初态;Z ⊂ K是一个终态集,终态也称可接受状态或结束状态。
对于 Σ* 中的任何符号串 t,若存在一条从初态到某一终态的道路,且这条道路上所有弧的标记连接成的字符串等于 t,则称 t 可为 DFA M 所接受,若 M 的初态同时又是终态,则空字可为 M 所识别(接受)。
即:若 t∈ Σ* , f(S, t)=P, 其中 S 为 M 的开始状态,P∈Z,Z 为终态集。
则称 t 为 DFA M 所接受(识别)。
如果看懂了DFA的介绍,我们可以这么理解敏感词过滤系统。用需要被过滤的敏感词构建一个DFA(确定有穷自动机 ),然后遍历需要过滤的文本,判断文本中是否有 DFA 可接受(识别)的字符串即可。
字典树实现 DFA
见算法第 21 题。
字典树算法改进
防止出现有相同后缀的敏感词汇
如 fabcd,abc,当字符串最后 fabc, 此时指 begin 指 f, 此时 position指到 c, 根据循环中的判断 c 的 isKeywordsEnd 为 true, position++, 此时跳出循环, 然后将 fabc 加到StringBuilder 中, 但是 abc 这个敏感词没有被过滤掉
HashMap 实现方式
我们可以认为,通过 S query U、V,通过 U query V、P,通过 V query U P。通过这样的转变我们可以将状态的转换转变为使用Java集合的查找。
诚然,加入在我们的敏感词库中存在如下几个敏感词:日本人、日本鬼子、毛泽东。那么我需要构建成一个什么样的结构呢?
首先:query 日 ---> {本}、query 本 --->{人、鬼子}、query 人 --->{null}、query 鬼 ---> {子}。形如下结构:
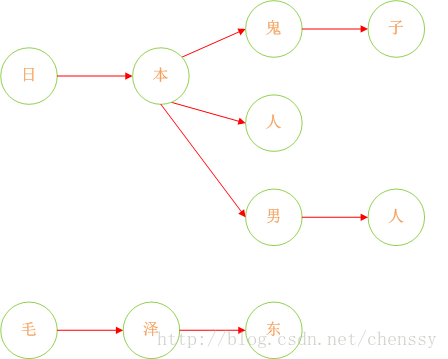
这样就将敏感词库构建成了一个类似于一颗一颗的树,这样判断一个词是否为敏感词时就大大减少了检索的匹配范围。比如要判断日本人,根据第一个字就可以确认需要检索的是那棵树,然后再在这棵树中进行检索。
但是如何来判断一个敏感词已经结束了呢?利用标识位来判断。
构建 DFA
所以对于这个关键是如何来构建一棵棵这样的敏感词树。下面以 Java 中的 HashMap 为例来实现 DFA 算法。具体过程如下:
日本人,日本鬼子为例:
- 在 hashMap 中查询”日”看其是否在 hashMap 中存在,如果不存在,则证明已”日”开头的敏感词还不存在,则我们直接构建这样的一棵树。跳至3。
- 如果在 hashMap 中查找到了,表明存在以“日”开头的敏感词,设置
hashMap = hashMap.get("日"),跳至1,依次匹配“本”、“人”。 - 判断该字是否为该词中的最后一个字。若是表示敏感词结束,设置标志位 isEnd = 1,否则设置标志位
isEnd = 0
private static void initSensitiveWordMap(Set<String> sensitiveWordSet) {
//初始化敏感词容器,减少扩容操作
sensitiveWordMap = new HashMap(sensitiveWordSet.size());
String key;
Map nowMap;
Map<String, String> newWorMap;
//迭代sensitiveWordSet
Iterator<String> iterator = sensitiveWordSet.iterator();
while (iterator.hasNext()) {
//关键字
key = iterator.next();
nowMap = sensitiveWordMap;
for (int i = 0; i < key.length(); i++) {
//转换成char型
char keyChar = key.charAt(i);
//库中获取关键字
Object wordMap = nowMap.get(keyChar);
//如果存在该key,直接赋值,用于下一个循环获取
if (wordMap != null) {
nowMap = (Map) wordMap;
} else {
//不存在则,则构建一个map,同时将isEnd设置为0,因为他不是最后一个
newWorMap = new HashMap<>();
//不是最后一个
newWorMap.put("isEnd", "0");
nowMap.put(keyChar, newWorMap);
nowMap = newWorMap;
}
if (i == key.length() - 1) {
//最后一个
nowMap.put("isEnd", "1");
}
}
}
}
查询过程
检索过程无非就是 hashMap 的 get 实现,找到就证明该词为敏感词,否则不为敏感词。过程如下:假如匹配“中国人民万岁”。
- 第一个字“中”,在 hashMap 中可以找到。得到一个新的
map = hashMap.get("中")。 - 如果map == null,则不是敏感词。否则跳至3
- 获取 map 中的 isEnd,通过 isEnd 是否等于1来判断该词是否为最后一个。如果 isEnd == 1 表示该词为敏感词,否则跳至 1。
通过这个步骤可以判断“中国人民”为敏感词,但是如果输入“中国女人”则不是敏感词了。
private static int checkSensitiveWord(String txt, int beginIndex, int matchType) {
//敏感词结束标识位:用于敏感词只有1位的情况
boolean flag = false;
//匹配标识数默认为0
int matchFlag = 0;
char word;
Map nowMap = sensitiveWordMap;
for (int i = beginIndex; i < txt.length(); i++) {
word = txt.charAt(i);
//获取指定key
nowMap = (Map) nowMap.get(word);
if (nowMap != null) {//存在,则判断是否为最后一个
//找到相应key,匹配标识+1
matchFlag++;
//如果为最后一个匹配规则,结束循环,返回匹配标识数
if ("1".equals(nowMap.get("isEnd"))) {
//结束标志位为true
flag = true;
//最小规则,直接返回,最大规则还需继续查找
if (MinMatchTYpe == matchType) {
break;
}
}
} else {//不存在,直接返回
break;
}
}
if (matchFlag < 2 || !flag) {//长度必须大于等于1,为词
matchFlag = 0;
}
return matchFlag;
}
两种实现方式对比
两种方法本质上是一样的,都是通过构造 HashMap,在 Map 中包含了另外一个子 Map,所以空间复杂度相等,O(n*m)(n的敏感词,每个m长),时间复杂度方面,如果敏感词的长度为 m,则每个敏感词的查找时间复杂度是 O(m),字符串的长度为 n,我们需要遍历 n 遍,所以敏感词查找这个过程的时间复杂度是 O(n * m)。如果有 t 个敏感词的话,构建 trie 树的时间复杂度是 O(t * m)。基于 Tire 树实现的方式,相对结构比较直观,实现方法上比较容易理解。
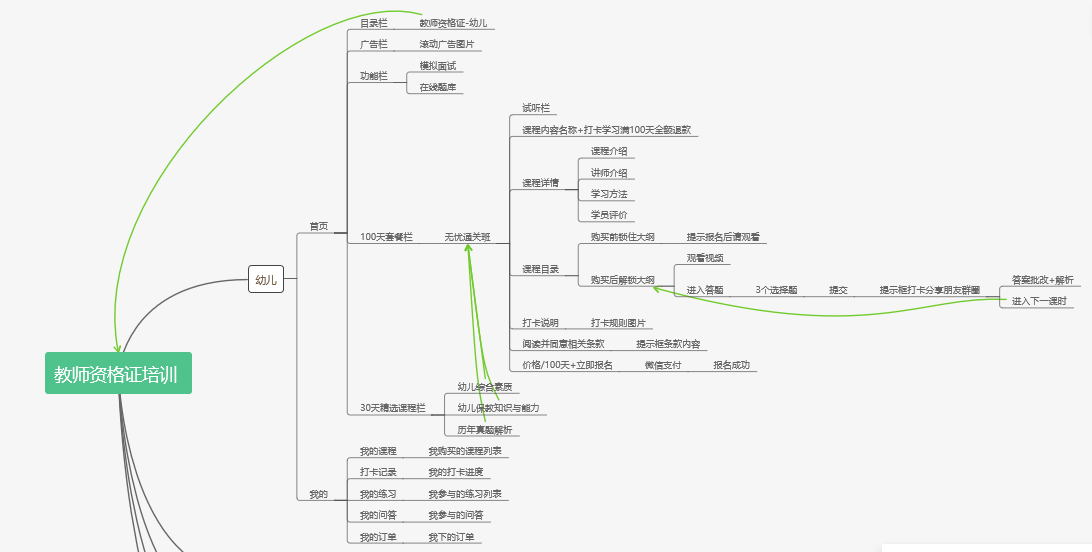
7. 项目架构
教师资格证培训平台:
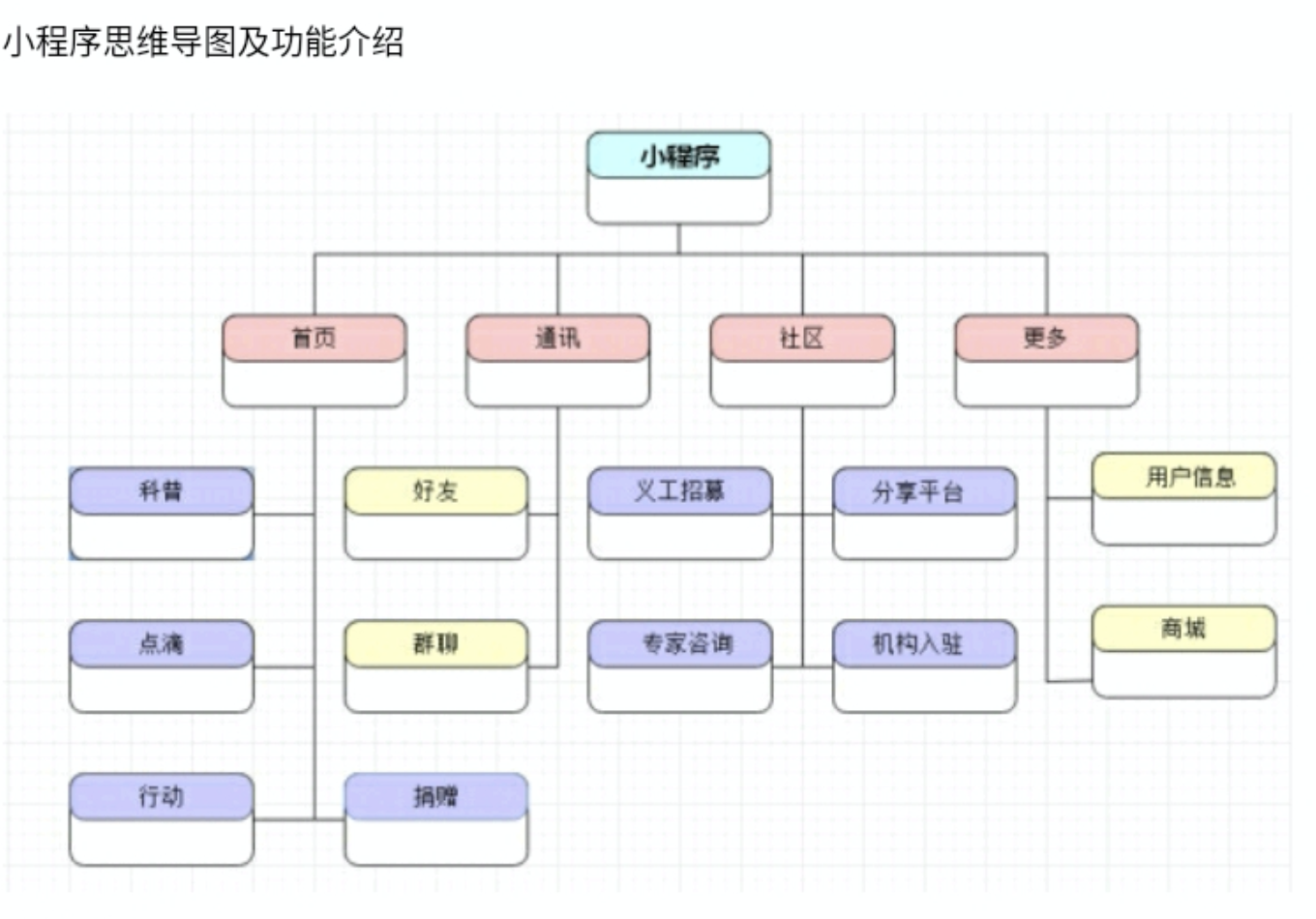
熠熠星光小程序:
8. Docker 部署项目流程
- 首先需要将项目打包
- 下载相关需要配置的镜像(Nginx,MySQL,AabbitMQ等等)
- 设置相应本地挂载的目录
- 编写 docker-compose 脚本构建项目并启动
- 开启防火墙既可以被访问:
systemctl stop firewalld
9. 订单功能使用 RabbitMQ,而注册、文件上传使用多线程的原因
订单功能考虑到实际业务场景可能出现抢购,这个时候并发量高,单纯使用线程池可能会导致大量阻塞,而使用消息队列可以达到削峰、减少响应所需时间的目的。而注册、视频文件上传等业务不会出现太高的并发量,主要是提高用户体验度。
之所以选用 RabbitMQ:性能好响应快,吞吐量到万级,而且开源版本就提供了非常完备的功能,包括监控界面等等,开源社区很活跃,特别适合中小型企业使用,不用承担社区黄掉的风险。
10. 后台接口防刷
实现:对 ip 访问速率进行限制
使用 Redis 中的 String 存储,以 ip 为 key,访问次数为值递增,同时设置过期时间。如果访问次数超过限制则加入黑名单 n 秒。每次访问先检查黑名单中是否存在,黑名单使用 zSet 结构,以 “blacklist” 为键,时间作为 score,ip 作为 value。
实现如下:
private String preventRefresh(HttpServletRequest request) {
//首先获取ip
String ip = request.getRemoteAddr();
//1秒内调用接口次数不超过5次
int limit = 5;
int expireTime = 1;
//限制5秒内不能再访问
int limitTime = 5000;
//获取当前时间(毫秒)
Long now = System.currentTimeMillis();
//判断ip地址是否在黑名单中
//获取当前 ip 地址在黑名单中的生成时间
Long createTime = redisService.zScore("blacklist",ip);
if(createTime != null) {
if(now - creteTime < limitTime) {
return "接口调用过于频繁";
} else {
//解除限制
redisService.zRem("blacklist",ip);
}
}
//获取当前ip访问次数
int count = redisService.get(ip);
if(count == null) {
count = redisService.incr(ip);
redisService.setExpire(ip,expireTime);
} else {
count = redisService.incr(ip);
}
if(count > limit) {
//访问次数过多
redisService.zAdd("blacklist",now,ip);
return "接口访问过于频繁";
}
return "正常访问";
}
其他实现方法:
- http 请求头信息校验,例如 host(请求资源所在服务器),User-Agent(HTTP 客户端程序的信息),Referer(对请求中 URI 的原始获取方)
- 验证码
- 令桶牌法:
- 假设有一个桶,不断的向桶中投放 token,并且我们也可以从桶中取出token。
- 投放token的速率是恒定的r1,桶满了token数量则不会再增长。
- 取出的速率是随机的r2。如果桶是空的,则无法取出token。
- 所有的请求都必须从桶中取出token才是有效的。否则该请求会被拒绝。
举个例子,假设桶的容量是 10,每秒放 2 个token进去。
如果现在每秒 2 个请求,那么所有这样的请求都是没有问题的,都会拿到 token。
如果现在每秒 4 个请求,10 + 2x = 4x。也就是 x=5 秒后请求就没法及时拿到 token,被丢弃。
总结出以下特点:
- 如果请求速率过快,到一段时间后会受到限制
- 允许突发请求
11. 如何设计一个秒杀系统
一个秒杀系统需要解决的问题:
- 高并发
- 超卖
- 恶意请求
- 链接暴露
- 数据库性能
针对高并发情况
资源静态化
秒杀一般都是特定的商品还有页面模板,现在一般都是前后端分离的,所以页面一般都是不会经过后端的,前端那就把能提前放入cdn服务器的东西都放进去,反正把所有能提升效率的步骤都做一下,减少真正秒杀时候服务器的压力。
按钮控制
没到秒杀前,按钮置灰,只有时间到了,才能点击。防止大家在时间快到的最后几秒秒疯狂请求服务器,然后还没到秒杀的时候基本上服务器就挂了。这个时候就需要前端的配合,定时去请求的后端服务器,获取最新的北京时间,到时间点再给按钮可用状态。
按钮可以点击之后也置灰几秒,从而限制流量
限流
限流这里应该分为前端限流和后端限流。
前端限流:这个很简单,一般秒杀不会让你一直点的,一般都是点击一下或者两下然后几秒之后才可以继续点击,这也是保护服务器的一种手段。
后端限流:秒杀的时候肯定是涉及到后续的订单生成和支付等操作,但是都只是成功的幸运儿才会走到那一步,那一旦100个产品卖光了,return 了一个 false,前端直接秒杀结束,然后后端也关闭后续无效请求的介入了。
另外 Nginx 负载均衡,Redis 集群、读写分离
MQ 削峰
对于写请求,做请求队列,每次只透有限的写请求去数据层,如果均成功再放下一批,如果库存不够则队列里的写请求全部返回“已售完” 。
针对链接暴露和恶意请求
设置后台接口防刷
数据库
使用非关系型的数据库Redis,开始秒杀前把商品的库存加载到 Redis 中去,让整个流程都在Redis里面去做,每卖出一件库存减一同时写入 MQ 队列,再异步的去修改库存就好了。
超卖问题
如果现在库存只剩下1个了,但是由于是高并发嘛,4个服务器一起查询了发现都是还有1个,那大家都觉得是自己抢到了,就都去扣库存,那结果就变成了-3,这就会出现超卖的情况。
解决方式是在 Redis 中使用乐观锁的方式,在存放库存的同时加一个 version 字段,每次读取后更改完,再读取一遍,只有当前 version == expectVersion 才能扣除成功,否则直接返回购买失败。
如果是在防不住,考虑熔断、降级。
12. 项目(接口)设计原则
单一原则
一个类只负责一个功能领域的相应职责,或者可以定义为,就一个类而言,应该只有一个引起它变化的原因。
说得比较官方一点就是:使这个类改变的因数只有唯一的一个时,那么这个类符合单一原则。
对应项目:每一个类一个功能,例如一个 User 表对应一个 User 类
开闭原则
软件实现应该对扩展开放,对修改关闭
一个软件产品只要在生命周期内,都会发生变化,即然变化是一个事实,我们就应该在设计时尽量适应这些变化,以提高项目的稳定性和灵活性,真正实现“拥抱变化”。开闭原则告诉我们应尽量通过扩展软件实体的行为来实现变化,而不是通过修改现有代码来完成变化,它是为软件实体的未来事件而制定的对现行开发设计进行约束的一个原则。
第一:抽象约束
抽象是对一组事物的通用描述,没有具体的实现,也就表示它可以有非常多的可能性,可以跟随需求的变化而变化。因此,通过接口或抽象类可以约束一组可能变化的行为,并且能够实现对扩展开放,其包含三层含义:
- 通过接口或抽象类约束扩散,对扩展进行边界限定,不允许出现在接口或抽象类中不存在的public方法。
- 参数类型,引用对象尽量使用接口或抽象类,而不是实现类,这主要是实现里氏替换原则的一个要求
- 抽象层尽量保持稳定,一旦确定就不要修改
第二:元数据(metadata)控件模块行为
编程是一个很苦很累的活,那怎么才能减轻压力呢?答案是尽量使用元数据来控制程序的行为,减少重复开发。什么是元数据?用来描述环境和数据的数据,通俗的说就是配置参数,参数可以从文件中获得,也可以从数据库中获得,同时也应该考虑数据库表的通用性和扩张性(配置文件)
第三:制定项目章程
在一个团队中,建立项目章程是非常重要的,因为章程是所有人员都必须遵守的约定,对项目来说,约定优于配置。这比通过接口或抽象类进行约束效率更高,而扩展性一点也没有减少。
第四:封装变化
对变化封装包含两层含义:
- 将相同的变化封装到一个接口或抽象类中
- 将不同的变化封装到不同的接口或抽象类中,不应该有两个不同的变化出现在同一个接口或抽象类中。
封装变化,也就是受保护的变化,找出预计有变化或不稳定的点,我们为这些变化点创建稳定的接口。
伯斯塔尔原则
按照伯斯塔尔法则的思想来设计实现服务调用时,发送的数据要更保守,意味着最小化的传送必要的信息,接收时更开放意味着要最大限度的容忍信息的兼容性。多余的信息不认识可以忽略,而不应该拒绝或抛出错误。
里氏替换原则
所有引用父类的地方,必须能透明的使用其子类对象
父类的一个方法的返回值是一个类型 T,子类的相同方法的返回值为 S,那么里氏替换原则就要求 S 必须小于等于 T。采用里氏替换原则的目的就是增强程序的健壮性,版本升级时也可以保持非常好的兼容性。即使增加子类,原有的子类还可以继续运行。在实际项目中,每个子类对应不同的业务含义,使用父类作为参数,传递不同的子类完成不同的业务逻辑,非常完美。
接口隔离原则
使用多个专门的接口,而不使用单一的总接口。 其实接口隔离原则说白了就是单一职责的扩展,或者说细化,将单一的概念扩展至接口,或者说具体的函数。对于一个个比较细化的接口,优点简洁且明显,那就是更小的接口,更有利于书写单元测试,也更有利于调试。
而如果能有比较多专门的接口,无疑会极大降低阅读理解代码的成本,阅读者往往只需要了解任务的分发逻辑就好,不需要一不小心就沉到底层繁琐的逻辑中,一个大的接口在阅读的时候,往往是任务分发逻辑和任务执行逻辑严重耦合在一起的,当你以为你在了解任务分发部分的逻辑的时候,你可能已经在读具体业务处理逻辑了。然而其实往往你根本不需要关系具体的某个功能的逻辑,多数时候,你只是需要修改一点分发逻辑。这个时候细粒度的接口就体现出优点,更为细粒度的接口,有利于隔离业务处理和业务分发的逻辑,可以提高阅读代码效率。不要小瞧这点,试想一个团队招来的新人,全部都在解决老坑的路上步履蹒跚,拖累了开发新功能进度,而这些老的东西很难再创造价值了,而能创造价值的东西,却总是在拖延中,拖过了市场,再来价值就缩水的厉害了。
合成复用原则
优先使用组合而不是继承。继承必须在 is-a 的关系成立的时候才能使用,否则使用组合,之所以不使用继承,是因为继承会将基类的实现细节暴露给子类,这个就导致如果基类发生改变,那么子类也不得不改变,相对而言,使用组合,可以有更好的封装性。
适用场景:对于数据库连接,可能存在多个中数据库,则可以把 getConnection 抽象出来,适用如下组合实现:
public abstract class DBConnection {
public abstract String getConnection();
}
public class ProductDao {
private DBConnection dbConnection;
public void setDbConnection(DBConnection dbConnection) {
this.dbConnection = dbConnection;
}
public void addProduct() {
String conn = dbConnection.getConnection();
System.out.println("使用" + conn + "增加产品");
}
}
依赖倒置原则
抽象不依赖于细节,细节应该依赖于抽象。
在实现依赖倒转的原则的时候,我们最常使用的技术就是依赖注入(Dependency Injection,DI),通过依赖注入来对一个抽象的对象注入一个具体的实例。 对于设计模式来说,尽可能的开闭是目标,里氏替换是实现开闭的基础,而依赖倒转是具体的手段。
迪米特法则
一个软件实体应当尽可能少的与其它实体发生相互作用。 最能体现这种思想是中介者模式,在中介者模式中,各个对象之间存在通信,但是对象之间并不会互相引用,而是维持一个中介者的引用,当我们需要添加一个成员的时候,我们往往增加一个对象再修改一下中介者就好了,大部分的时候,其它对象是无感知的。 迪米特法则的好处,在于满足迪米特法则的类,通常都是可测试的类。不过想写出这样的类可不容易,这个时候可以考虑 TDD 的方法,不过这就是另一个话题了。
13. 为什么使用前后端分离
- 可以实现真正的前后端解耦,前端服务器使用nginx。前端/WEB服务器放的是css,js,图片等等一系列静态资源(甚至你还可以css,js,图片等资源放到特定的文件服务器,例如阿里云的oss,并使用cdn加速),前端服务器负责控制页面引用,跳转或路由,前端页面异步调用后端的接口,后端/应用服务器使用tomcat(把tomcat想象成一个数据提供者),加快整体响应速度。(这里需要使用一些前端工程化的框架比如nodejs,react,router,react,redux,webpack)
- 发现 bug,可以快速定位是谁的问题,不会出现互相踢皮球的现象。页面逻辑,跳转错误,浏览器兼容性问题,脚本错误,页面样式等问题,全部由前端工程师来负责。接口数据出错,数据没有提交成功,应答超时等问题,全部由后端工程师来解决。双方互不干扰,前端与后端是相亲相爱的一家人。
- 在大并发情况下,我可以同时水平扩展前后端服务器,比如淘宝的一个首页就需要 2000+ 台前端服务器做集群来抗住日均多少亿+的日均 pv。(阿里的 web 容器都是自己写的,就算他单实例抗 10 万 http 并发,2000 台是 2 亿 http 并发,并且他们还可以根据预知洪峰来无限拓展。)
- 减少后端服务器的并发/负载压力。除了接口以外的其他所有 http 请求全部转移到前端 nginx 上,接口的请求调用 tomcat,参考 nginx 反向代理 tomcat。且除了第一次页面请求外,浏览器会大量调用本地缓存。- 即使后端服务暂时超时或者宕机了,前端页面也会正常访问,只不过数据刷不出来而已。也许你也需要有微信相关的轻应用,那样你的接口完全可以共用,如果也有 app 相关的服务,那么只要通过一些代码重构,也可以大量复用接口,提升效率。(多端应用)
- 页面显示的东西再多也不怕,因为是异步加载。
- nginx 支持页面热部署,不用重启服务器,前端升级更无缝。
- 增加代码的维护性&易读性(前后端耦在一起的代码读起来相当费劲)。
- 提升开发效率,因为可以前后端并行开发,而不是像以前的强依赖。
- 在nginx中部署证书,外网使用https访问,并且只开放 443 和 80 端口,其他端口一律关闭(防止黑客端口扫描),内网使用http,性能和安全都有保障。
- 前端大量的组件代码得以复用,组件化,提升开发效率,抽出来!
14. 如果线上用户出现502错误怎么排查?
通过查看日志分析问题,Nginx 中有 error 日志和 access 日志。还可以查看服务器的负载情况。
以 php 为例,
- php问题:
- 进程数不够 (max_children最大子进程数)
- 最长执行时间(request_terminate_timeout)
- nginx问题
- FastCGI 进程是否已经启动
- FastCGI worker进程数是否不够
- FastCGI 执行时间过长:nginx.conf 里的
fastcgi_connect_timeout,fastcgi_send_timeout,fastcgi_read_timeout都调大一点。 - FastCGI Buffer 不够,nginx和apache一样,有前端缓冲限制,可以调整缓冲参数
fastcgi_buffer_size 32k;
fastcgi_buffers 8 32k;
- Proxy Buffer 不够 如果用了 Proxying,调整:
proxy_buffer_size 16k;
proxy_buffers 4 16k;
- 数据库
- 代理有问题
解决方案:
- 提高 Web 服务器的响应速度,也即减少内部的调用关系,可以把需要的页面、素材或数据,缓存在内存中,可以是专门的缓存服务器 ,也可以Web服务器自身的缓存,提高响应速度;
- 网络带宽的问题,则对传输的数据包进行压缩处理,或者向IDC申请增加带宽;
- 属于内部网络的故障或设置问题,也即内部网络拥塞,可能内部存在大量的数据调用或交互造成的,则需要优化内部网络传输或协议;
- 数据库的数据读取造成前端服务器 ,响应用户的请求变慢,那么必须提高数据库的处理能力,若是只读业务可以增加数据缓存的模式 或者增加数据库备机,分散读压力;若是写的压力,则可以考虑延迟写的模式。
15. 接口规范定义
协议规范
为了确保不同系统/模块间的数据交互,需要事先约定好通讯协议,如:TCP、HTTP、HTTPS协议。为了确保数据交互安全,建议使用HTTPS协议。
接口路径规范
作为接口路径,为了方便清晰的区分来自不同的系统,可以采用不同系统/模块名作为接口路径前缀。
格式规范如下:
- 支付模块 /pay/xx
- 订单模块 /order/xx
版本控制规范
为了便于后期接口的升级和维护,在接口路径中加入版本号,便于管理,实现接口多版本的可维护性。如果细心留意过的话,会发现好多框架对外提供的API接口中(如:Eureka),都带有版本号的。如:接口路径中添加类似”v1”、”v2”等版本号。
格式规范如下:
- /xx/v1/xx
更新版本后可以使用 v2、v3 等、依次递加。
接口命名规范
和Java命名规范一样,好的、统一的接口命名规范,不仅可以增强其可读性,而且还会减少很多不必要的口头/书面上的解释。
可结合【接口路径规范】、【版本控制规范】,外加具体接口命名(路径中可包含请求数据,如:id等),建议具体接口命名也要规范些,可使用”驼峰命名法”按照实现接口的业务类型、业务场景等命名,有必要时可采取多级目录命名,但目录不宜过长,两级目录较为适宜。
格式规范如下:
- /user/v1/sys/login 用户服务/模块的系统登录接口
- /zoo/v1/zoos/{ID} 动物园服务/模块中,获取id为ID的动物
具体接口命名,通常有以下两种方式:
- 接口名称动词前/后缀化(项目采用这种)
接口名称以接口数据操作的动词为前/后缀,常见动词有:add、delete、update、query、get、send、save、detail、list 等,如:新建用户 addUser、查询订单详情 queryOrderDetail。
- 接口名称动词+请求方式
接口路径中包含具体接口名称的名词,接口数据操作动作以HTTP请求方式来区分。常用的HTTP请求方式有:
- GET:从服务器取出资源(一项或多项)。
- POST:在服务器新建一个资源。
- PUT:在服务器更新资源(客户端提供改变后的完整资源)。
- PATCH:在服务器更新资源(客户端提供改变的属性)。
- DELETE:从服务器删除资源。
如:
- GET /zoo/v1/zoos:列出所有动物园
- POST /zoo/v1/zoos:新建一个动物园
- GET /zoo/v1/zoos/{ID}:获取某个指定动物园的信息
- PUT /zoo/v1/zoos/{ID}:更新某个指定动物园的信息(提供该动物园的全部信息)
- PATCH /zoo/v1/zoos/{ID}:更新某个指定动物园的信息(提供该动物园的部分信息)
- DELETE /zoo/v1/zoos/{ID}:删除某个动物园
- GET /zoo/v1/zoos/{ID}/animals:列出某个指定动物园的所有动物
- DELETE /zoo/v1/zoos/ID/animals/ID:删除某个指定动物园的指定动物
请求参数规范
请求方式:按照 GET、POST、PUT 等含义定义,避免出现不一致现象,对人造成误解、歧义。
请求头:请求头根据项目需求添加配置参数。如:请求数据格式,accept='application/json'等。请求头根据项目需求要求传入用户 token、唯一验签码等加密数据。
请求参数/请求体:请求参数字段,尽可能与数据库表字段、对象属性名等保持一致,因为保持一致最省事,最舒服的一件事。
返回数据规范
统一规范返回数据的格式,对前端后台接口对接都有好处,此处以 json 格式为例。返回数据应包含:返回状态码、返回状态信息、具体数据。
返回数据中的状态码、状态信息,常指具体的业务状态,不建议和 HTTP 状态码混在一起。HTTP 状态,是用来体现 HTTP 链路状态情况,如:404-Not Found。HTTP 状态码和 json 结果中的状态码,并存尚可,用于体现不同维度的状态。
接口管理工具
使用 RAP2,RAP是阿里开源的一套接口管理系统,RAP 可以比较方便的管理公司所有系统的接口,同时还有比较完善的权限管理,还可以做接口 mock,方便开发人员在接口功能还没有完成的时候能够及时发布出去,给调用方去使用。但是 RAP 的缺点就是每个接口都需要维护进去,接口修改后也需要及时维护,当时我们在使用的时候遇到的最大的问题也是经常碰到接口没有及时维护的问题。
参考内容
主要参考以来两篇博客以及相关博客推荐,因找的博客比较多,没注意记录,最后好多忘了在哪2333,如果有侵权,请及时联系我,非常抱歉。
https://github.com/Snailclimb/JavaGuide
https://github.com/CyC2018/CS-Notes
中华石杉–互联网Java进阶面试训练营
接口请求速率(接口防刷)限制方案
关于接口安全 接口防刷 RSA 鉴权 签名 实现
第 131 题:接口如何防刷
使用自增主键是否总是最佳实践?
如何设计秒杀系统?
接口设计原则
你不得不了解的前后端分离原理!
502 Bad Gateway 怎么解决?
502 Bad Gateway 错误排查
怎么设计高效的敏感词过滤系统(一)
敏感词过滤的算法原理之DFA算法
Java实现敏感词过滤 - DFA算法
Nginx 是如何实现高并发?常见的优化手段有哪些?
如何写出完美的接口:接口规范定义、接口管理工具推荐
设计模式 - 七大设计原则(四)- 合成复用原则与设计原则总结