数据结构
队列
队列是数据结构中比较重要的一种类型,它支持 FIFO,尾部添加、头部删除(先进队列的元素先出队列),跟我们生活中的排队类似。
队列有两种:
- 单队列(单队列就是常见的队列,每次添加元素时,都是添加到队尾,存在“假溢出”的问题,也就是明明有位置却不能添加的情况)
- 循环队列(避免了“假溢出”的问题)
单队列就是常见的队列, 每次添加元素时,都是添加到队尾:
初始时,front和rear都为0,每添加一个元素,rear后移一位,没删除一个元素,front后移一位。当出现一下这种情况:
当再往里添加两个元素,rear后移两位后越界,就会出现明明有三个空位,却只能插入一个的情况,这种情况称为假溢出。
针对这种情况,可以采用循环队列解决。循环队列中,入队操作为rear = (rear+1) % size,出队操作为front = (front+1) % size。
此时不能再使用front == rear来判断队列空还是满,可以使用以下方法:
- 设一标志域标识队列空或满
- 设一个长度域记录队列中元素的个数
- 少用一个元素空间,当
front == (rear+1) % size时认为队列已满
在第三种方法条件下,当rear > front时,队列中元素个数为rear-front;当rear < front时,队列中元素分为两部分:size-front和rear。
Java集合中有
Queue接口,一般情况下Queue的实现类都不允许添加null元素,因为poll(),peek()方法在异常的时候会返回null,添加了null 以后,当获取时不好分辨究竟是否正确返回。
Stack栈
栈是一种用于存储数据的简单数据结构,有点类似链表或者顺序表(统称线性表),栈与线性表的最大区别是数据的存取的操作,我们可以这样认为栈(Stack)是一种特殊的线性表,其插入和删除操作只允许在线性表的一端进行,一般而言,把允许操作的一端称为栈顶(Top),不可操作的一端称为栈底(Bottom),同时把插入元素的操作称为入栈(Push),删除元素的操作称为出栈(Pop)。若栈中没有任何元素,则称为空栈
栈(Stack)是一种有序特殊的线性表,只能在表的一端(称为栈顶,top,总是指向栈顶元素)执行插入和删除操作,最后插入的元素将第一个被删除,因此栈也称为后进先出(Last In First Out,LIFO)或先进后出(First In Last Out FILO)的线性表。栈的基本操作创建栈,判空,入栈,出栈,获取栈顶元素等,注意栈不支持对指定位置进行删除,插入。
顺序栈的整体实现
顺序栈,顾名思义就是采用顺序表实现的的栈,顺序栈的内部以顺序表为基础,实现对元素的存取操作,当然还可以采用内部数组实现顺序栈,在这里使用内部数据组来实现栈。
import java.io.Serializable;
import java.util.EmptyStackException;
public class SeqStack<T> implements Serializable {
private static final long serialVersionUID = -7004488644657135624L;
/**
* 栈顶指针,-1代表空栈
*/
private int top = -1;
/**
* 容量大小默认为10
*/
private int capacity = 10;
/**
* 存放元素的数组
*/
private T[] array;
private int size;
public SeqStack(int capacity){
array = (T[]) new Object[capacity];
}
public SeqStack(){
array= (T[]) new Object[this.capacity];
}
public int size(){
return size;
}
public boolean isEmpty() {
return this.top==-1;
}
/**
* 添加元素,从栈顶(数组尾部)插入
* @param data
*/
public void push(T data) {
//判断容量是否充足
if(array.length==size)
ensureCapacity(size*2+1);//扩容
//从栈顶添加元素
array[++top]=data;
size++;
}
/**
* 获取栈顶元素的值,不删除
* @return
*/
public T peek() {
if(isEmpty())
new EmptyStackException();
return array[top];
}
/**
* 从栈顶(顺序表尾部)删除
* @return
*/
public T pop() {
if(isEmpty())
new EmptyStackException();
size--;
return array[top--];
}
/**
* 扩容的方法
* @param capacity
*/
public void ensureCapacity(int capacity) {
//如果需要拓展的容量比现在数组的容量还小,则无需扩容
if (capacity<size)
return;
T[] old = array;
array = (T[]) new Object[capacity];
//复制元素
for (int i=0; i<size ; i++)
array[i]=old[i];
}
public static void main(String[] args){
SeqStack<String> s=new SeqStack<>();
s.push("A");
s.push("B");
s.push("C");
System.out.println("size->"+s.size());
int l=s.size();//size 在减少,必须先记录
for (int i=0;i<l;i++){
System.out.println("s.pop->"+s.pop());
}
System.out.println("s.peek->"+s.peek());
}
}
链式栈的整体实现
所谓的链式栈(Linked Stack),就是采用链式存储结构的栈,由于操作的是栈顶一端,因此采用单链表(不带头结点)作为基础,直接实现栈的添加,获取,删除等主要操作即可。
public class LinkedStack<T> implements Serializable {
private static final long serialVersionUID = -7754751623529062156L;
private Node<T> top;
private int size;
public LinkedStack(){
this.top = new Node<>();
}
public int size(){
return size;
}
public boolean isEmpty() {
return top==null || top.data==null;
}
public void push(T data){
if (data==null){
throw new StackException("data can't be null");
}
if(this.top==null){//调用pop()后top可能为null
this.top=new Node<>(data);
}else if(this.top.data==null){
this.top.data=data;
}else {
Node<T> p=new Node<>(data,this.top);
top=p;//更新栈顶
}
size++;
}
public T peek() {
if(isEmpty()){
throw new EmptyStackException("Stack empty");
}
return top.data;
}
public T pop() {
if(isEmpty()){
throw new EmptyStackException("Stack empty");
}
T data=top.data;
top=top.next;
size--;
return data;
}
}
两种实现方法的空间复杂度(用于N次push)上都是O(n),在pop,push,peek,isEmpty的时间复杂度上都是O(1),由此可知栈的主要操作都可以在常数时间内完成,这主要是因为栈只对一端进行操作,而且操作的只是栈顶元素。
栈的常用应用
- 符号匹配
- 中缀表达式转换为后缀表达式
- 计算后缀表达式
- 实现函数的嵌套调用
- HTML和XML文件中的标签匹配
- 网页浏览器中已访问页面的历史记录
括号匹配和中缀转后缀实现见算法章
线性表
线性表是由n(n>=0)个类型相同的数据元素a0,a1,…,an-1组成的有限的序列,在数学中记作(a0,a1,…,an-1),其中ai的数据类型可以是基本数据类型(int,float等)、字符或类。n代表线性表的元素个数,也称其为长度(Length)。若n=0,则为空表;若n > 0,则ai(0 < i < n-1)有且仅有一个前驱(Predecessor)元素ai-1和一个后继(Successor)元素ai+1,a0没有前驱元素,ai没有后继元素。 ——《java数据结构》
线性表的顺序存储结构(顺序表)
线性表的顺序存储结构称之为顺序表(Sequential List),它使用一维数组依次存放从a0到an-1的数据元素(a0,a1,…,an-1),将ai(0< i <> n-1)存放在数组的第i个元素,使得ai与其前驱ai-1及后继ai+1的存储位置相邻,因此数据元素在内存的物理存储次序反映了线性表数据元素之间的逻辑次序。
数组访问操作的时间复杂度为O(1),整个过程需要一次乘法和一次加法运算,因为两个操作的执行时间都是常数时间,所以可以认为数组访问操作能在常数时间内完成。这种存取任何一个元素的时间复杂度为O(1)的数据结构称之为随机存取结构。
对于在顺序表中插入或者删除元素,从效率上则显得不太理想了,由于插入或者删除操作是基于位置的,需要移动数组中的其他元素,所以顺序表的插入或删除操作,算法所花费的时间主要是用于移动元素,如在顺序表头部插入或删除时,效率就显得相当糟糕。若在最前插入或删除,则需要移动n(这里假设长度为n)个元素;若在最后插入或删除,则需要移动的元素为0。也就是说,在等概率的情况下,插入或者删除一个顺序表的元素平均需要移动顺序表元素总量的一半,其时间复杂度是O(n)。当然如果在插入时,内部数组容量不足时,也会造成其他开销,如复制元素的时间开销和新建数组的空间开销。
线性表的链式存储结构(链表)
链表在初始化时仅需要分配一个元素的存储空间,并且插入和删除新的元素也相当便捷,同时链表在内存分配上可以是不连续的内存,也不需要做任何内存复制和重新分配的操作线性链表的存储结构是用若干个地址分散的存储单元存放数据元素的,逻辑上相邻的数据元素在物理位置上不一定相邻,因此每个存储单元中都会有一个地址指向域,这个地址指向域指明其后继元素的位置。在链表中存储数据的单元称为结点(Node),一个结点至少包含了数据域和地址域,其中数据域用于存储数据,而地址域用于存储前驱或后继元素的地址。链表的插入和删除都相当便捷,这是由于链表中的结点的存储空间是在插入或者删除过程中动态申请和释放的,不需要预先给单链表分配存储空间的,从而避免了顺序表因存储空间不足需要扩充空间和复制元素的过程,提高了运行效率和存储空间的利用率。
在链表中还可以设置带特殊头节点(没有值)的链表,这样单链表的插入和删除不再区分操作的位置,也就是说头部、中间、尾部插入都可以视为一种情况处理了,这是因为此时头部插入和头部删除无需改变head的指向。
此外,还可以将尾指针的下一个节点指向头指针构成循环链表。处理循环单链表时,需要注意在遍历循环链表时,避免进入死循环即可,也就是在判断循环链表是否到达结尾时条件为:
while(p != this.head){
p = p.next;
}
由于单链表并不是随机存取结构,即使单链表在访问第一个结点时花费的时间为常数时间,但是如果需要访问第i(0<i<n)个结点,需要从头结点head开始遍历部分链表,进行i次的p=p.next操作,这种情况类似于前面计算顺序表需要平均移动元素的总数,因此链表也需要平均进行n/2次的p=p.next操作,也就是说get(i)和set(i,x)的时间复杂度都为O(n)。
由于链表在插入和删除结点方面十分高效的,因此链表比较适合那些插入删除频繁的场景使用,单纯从插入操作来看,假设front指向的是单链表中的一个结点,此时插入front的后继结点所消耗的时间为常数时间O(1),但如果此时需要在front的前面插入一个结点或者删除结点自己时,由于front并没有前驱指针,单凭front根本无法知道前驱结点,所以必须从链表的表头遍历至front的前一个结点再执行插入或者删除操作,而这个查询操作所消耗的时间为O(n),因此在已知front结点需要插入前驱结点或者删除结点自己时,消耗的时间为O(n)。当然这种情况并不是无法解决的,可以使用双链表就可以解决这个问题,双链表是每个结点都同时拥有前后继结点的链表,这样的话上面的问题就迎刃而解了。
从前面单链表的插入删除的代码实现上来说,front结点每次插入和删除结点,都需要从表头开始遍历至要插入或者删除结点的前一个结点,而这个过程所花费的时间和访问结点所花费的时间是一样的,即O(n),也就是说从实现上来说确实单链表的插入删除操作花费时间也是O(n),而顺序表插入和删除的时间也是O(n),为什么说单链表的插入和删除的效率高?
链表的插入和删除之所以是O(N),是因为查询插入点所消耗的,找到插入点后插入操作消耗时间只为O(1),而顺序表查找插入点的时间为O(1),但要把后面的元素全部后移一位,消耗时间为O(n)。问题是大部分情况下查找所需时间比移动短多了,还有就是链表不需要连续空间也不需要扩容操作,因此即使时间复杂度都是O(n),所以相对来说链表更适合插入删除操作。
堆
堆是一类完全二叉树,常用于实现排序。在一个二叉堆的数组中,每一个元素都要保证大于等于另外两个特定位置的元素。同时相应的,这些元素又要大于等于另外两个相应位置的元素,整个数据结构以此类推。若堆中所有非叶子结点均不大于其左右孩子节点,则称为小顶堆;若堆中所有非叶子结点均不小于其左右孩子节点,则称为大顶堆。
public class MaxPQ {
private List<Integer> arr; //定义一个数组,
private int N; //定义队列中的元素个数
public MaxPQ() {
arr = new ArrayList();
arr.add(1);
N = 0;
}
public boolean isEmpty() { //方法,返回队列是否为空
return N == 0;
}
public int size() { //方法,返回队列中元素的个数
return N;
}
public void inSert(int number) { //添加方法,添加元素到结合末尾,并且使用上浮方法到指定的位置
arr.add(number);
swim(++N);
}
public int deleteMax() { //删除方法,删除最大元素并把最小的元素放到第一个,然后使用下浮方法
int max = arr.get(1);
int min = arr.get(N);
arr.set(1, min);
arr.remove(N--);
sink(1);
return max;
}
//添加到最后然后上浮算法
public void swim(int N) {
while(N > 1 && (arr.get(N/2) < arr.get(N))){
int max = arr.get(N);
int min = arr.get(N/2);
arr.set(N,min );
arr.set(N/2, max);
N = N/2;
}
}
//删除后将最小的移到最上面然后下沉算法
public void sink(int number) {
while(number*2 <= N) {
int index = number*2;
if(index < N && (arr.get(index) < arr.get(index + 1))) {
index++;
}
if(!(arr.get(number) < arr.get(index))) {
break;
}
int max = arr.get(index);
int min = arr.get(number);
arr.set(number, max);
arr.set(index, min);
number = index;
}
}
@Override
public String toString() {
return "MaxPQ [arr=" + arr + ", N=" + N + "]";
}
}
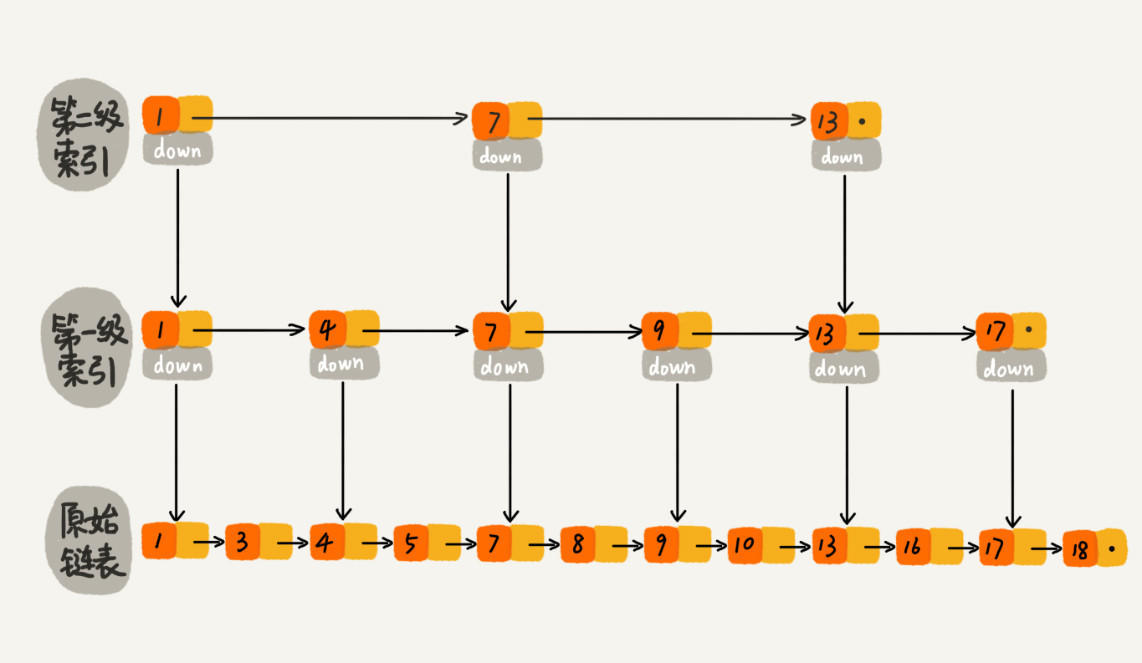
跳表
跳表查找时间复杂度为平均 O(logN),最差 O(N),在大部分情况下效率可与平衡树相媲美,但实现比平衡树简单的多,跳表是一种典型的以空间换时间的数据结构。
跳表具有以下几个特点:
- 由许多层结构组成。
- 每一层都是一个有序的链表。
- 最底层 (Level 1) 的链表包含所有元素。
- 如果一个元素出现在 Level i 的链表中,则它在 Level i 之下的链表也都会出现。
- 每个节点包含两个指针,一个指向同一链表中的下一个元素,一个指向下面一层的元素。
跳表的查找会从顶层链表的头部元素开始,然后遍历该链表,直到找到元素大于或等于目标元素的节点,如果当前元素正好等于目标,那么就直接返回它。如果当前元素小于目标元素,那么就垂直下降到下一层继续搜索,如果当前元素大于目标或到达链表尾部,则移动到前一个节点的位置,然后垂直下降到下一层。正因为 Skiplist 的搜索过程会不断地从一层跳跃到下一层的,所以被称为跳跃表。
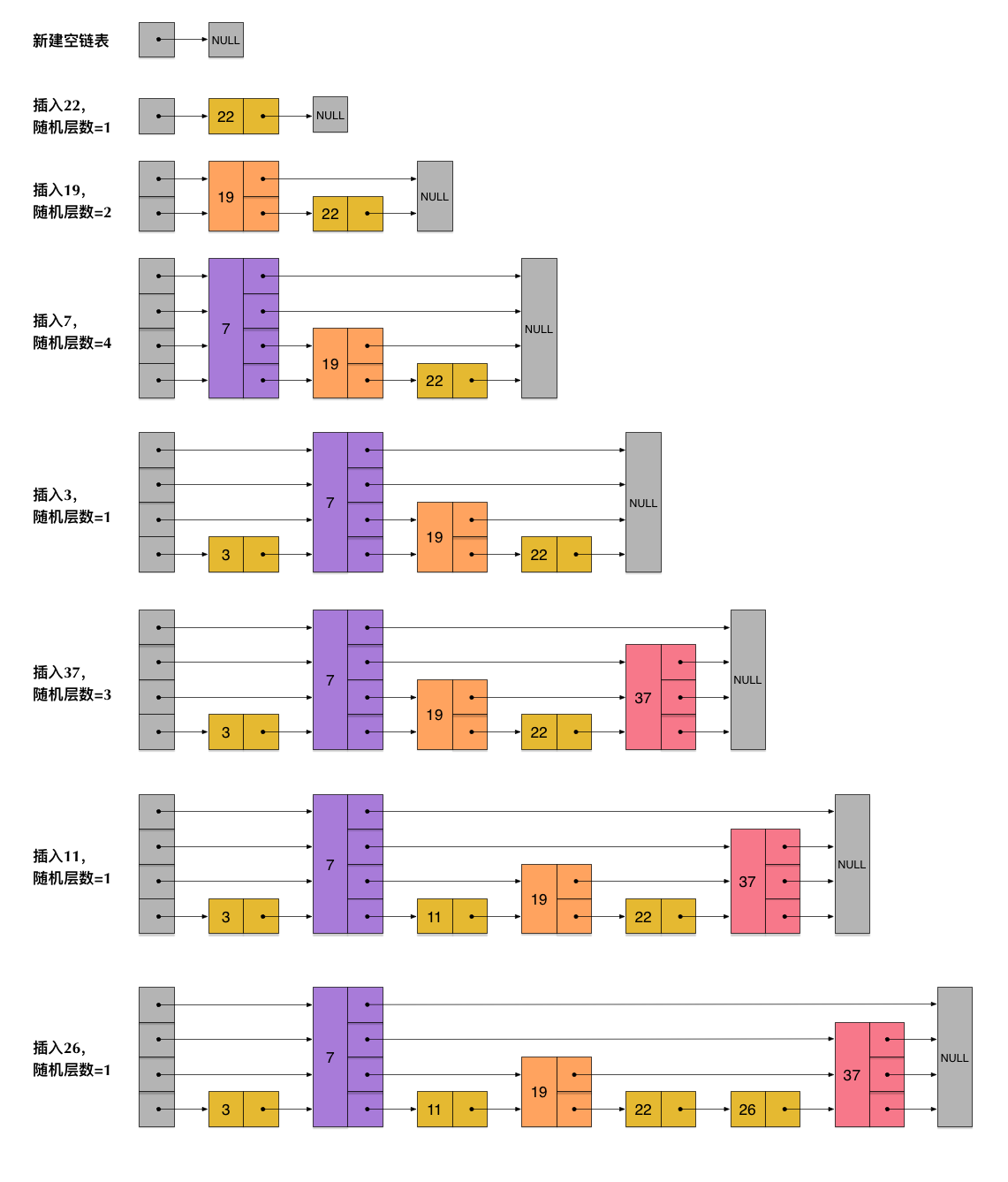
跳表是一个“概率型”的数据结构,指的就是跳表在插入操作时,元素的插入层数完全是随机指定的。实际上该决定插入层数的随机函数对跳表的查找性能有着很大影响,这并不是一个普通的服从均匀分布的随机数,它的计算过程如下:
- 指定一个节点最大的层数 MaxLevel,指定一个概率 p, 层数 lvl 默认为 1 。
- 生成一个 0~1 的随机数 r,若 r < p,且 lvl < MaxLevel ,则执行 lvl++。
- 重复第 2 步,直至生成的 r > p 为止,此时的 lvl 就是要插入的层数。
Skiplist 与平衡树、哈希表的比较
- Skiplist 和各种平衡树(如AVL、红黑树等)的元素是有序排列的,而哈希表不是有序的。因此,在哈希表上只能做单个 key 的查找,不适宜做范围查找。
- 在做范围查找的时候,平衡树比 Skiplist 操作要复杂。在平衡树上,我们找到指定范围的小值之后,还需要以中序遍历的顺序继续寻找其它不超过大值的节点。如果不对平衡树进行一定的改造,这里的中序遍历并不容易实现。而在 skiplist 上进行范围查找就非常简单,只需要在找到小值之后,对第 1 层链表进行若干步的遍历就可以实现。
- 平衡树的插入和删除操作可能引发子树的调整,逻辑复杂,而 Skiplist 的插入和删除只需要修改相邻节点的指针,操作简单又快速。
- 从内存占用上来说,Skiplist 比平衡树更灵活一些。一般来说,平衡树每个节点包含 2 个指针(分别指向左右子树),而 Skiplist 每个节点包含的指针数目平均为 1/(1−p),具体取决于参数 p 的大小。如果像 Redis 里的实现一样,取 p=1/4,那么平均每个节点包含 1.33 个指针,比平衡树更有优势。
- 查找单个 key,Skiplist 和平衡树的时间复杂度都为 O(logN);而哈希表在保持较低的哈希值冲突概率的前提下,查找时间复杂度接近 O(1),性能更高一些。
- 从算法实现难度上来比较,Skiplist 比平衡树要简单得多。
二叉查找树
二叉查找树(Binary Search Tree),也称有序二叉树(ordered binary tree),排序二叉树(sorted binary tree),是指一棵空树或者具有下列性质的二叉树:
- 若左子树不空,则左子树上所有节点的值均小于根节点的值
- 若右子树不空,则右子树上所有节点的值均大于根节点的值
- 左、右子树也分别是二叉树
二叉树的类型定义
public class BSTree{
private Node root;
private class Node{
public Node Left;
public Node Right;
public int Number; //记录该节点和所有子节点个数的值
public TKey Key; //节点的key
public TValue value; //节点的值
}
}
二叉树的查找
查找操作和二分查找类似,将key和节点的key比较,如果小于,那么就在Left Node节点查找,如果大于,则在Right Node节点查找,如果相等,直接返回Value。
递归方式:
public TValue searchBST(Node root,TKey key) {
if(T == null) return nulll;
if(T.node.key == key) return T.node.value;
if(T.node.key < key) return searchBST(root.Right,key);
else return searchBST(root.Left,key);
}
迭代方式:
public TValue searchBST(TKey key) {
Node node = root;
while(node != null){
if(node.key == key) return node.value;
else if(node.key < key) node = node.Right;
else node = node.Left;
}
return null;
}
插入
插入和查找类似,首先查找有没有和key相同的,如果有,更新;如果没有找到,那么创建新的节点,并更新每个节点的Number值。
public void put(Tkey key,TValue value){
root = put(root,key,value);
}
private Node put(Node node,TKey key,TValue value) {
if(node == null) {
return new Node(key,value,1);
}
if(node.Key < key) {
node.Right = put(node.Right,key,value);
}
else if(node.Key > key) {
node.Left = put(node.Left,key,value);
}
else node.Value = value;
x.Number = size(x.Left) + size(x.Right) +1;
return node;
}
private int size(Node node){
if(node == nulll) return 0;
else return node.Number;
}
最大值和最小值
二叉查找树中,最左和最右节点即为最小值和最大值。
迭代方式:
public TKey getMax(){
TKey maxItem = null;
Node node = root;
while(node.Right != null){
node = node.Right;
}
maxItem = node.Key;
return maxItem;
}
public Tkey getMin(){
TKey minItem = null;
Node node = root;
while(node.Left != null){
node = node.Left;
}
minItem = node.Key;
return minItem;
}
递归方式:
public TKey GetMaxRecursive()
{
return GetMaxRecursive(root);
}
private TKey GetMaxRecursive(Node root)
{
if (root.Right == null) return root.Key;
return GetMaxRecursive(root.Right);
}
public TKey GetMinRecursive()
{
return GetMinRecursive(root);
}
private TKey GetMinRecursive(Node root)
{
if (root.Left == null) return root.Key;
return GetMinRecursive(root.Left);
}
删除
删除需要分一下情况:
- 如果删除的是叶子结点,则删除后仍然为二叉树。
- 如果被删除的结点只有左、右子树之一为空,只需要将被删除结点的非空子树直接置为其双亲结点的相应子树
- 如果被删除结点的左右子树均不为空,则找到被删结点的直接前驱(位于被删结点左子树右下角右子树为空的结点),并将其值赋给被删结点,然后删除该前驱结点。
public void delete(TKey key){
root = delete(root,key);
}
/**
* 返回删除的节点
*/
private Node delete(Node node,Tkey key){
if(node == null) return null;
if(key == node.Key){
node = deleteNode(node);
}
else if(key < node.Key) {
node.left = delete(node.Left,key);
} else {
node.Right = delete(node.Right,key);
}
return node;
}
private Node deleteNode(Node p) {
Node q = null;
Node s = null;
q = p;//令q结点指向要删除的p结点
if(null == p.Right){ //被删结点的右子树为空
p = p.Left;//将P结点的左子树作为p结点的双亲结点的相应子树
}
else if(null == p.Left){ //被删结点的左子树为空
p = p.Right;
}
else { //左右子树均不为空
s = p.Left;
while(s.Right != null){
q = s;
s = s.Right;
}
p.Value = s.Value;//将直接前驱s结点的值赋给被删结点
if(q == p){
//p结点没有前驱结点,即左孩子没有右结点,此时s结点是p的左孩子
q.Left = s.Left; //删除s结点只需要将其左子树作为q的左子树
}
else {
q.Right = s.Left; //删除s结点只需要将其左子树置为q结点的右子树
}
}
return p;
}
性能
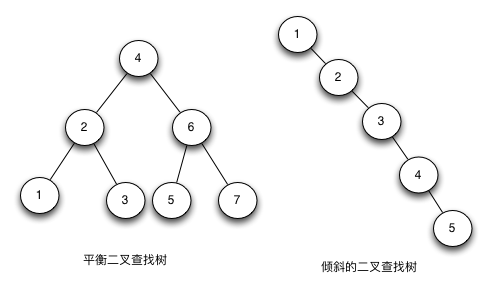
二叉查找树的运行时间和树的形状有关,树的形状又和插入元素的顺序有关。在最好的情况下,节点完全平衡,从根节点到最底层叶子节点只有lgN个节点,时间复杂度为O(logn)。在最差的情况下,根节点到最底层叶子节点会有N各节点,此时时间复杂度为O(n)。
缺陷
数在插入的时候会导致树倾斜,不同的插入顺序会导致树的高度不一样,而树的高度直接的影响了树的查找效率。理想的高度是logN,最坏的情况是所有的节点都在一条斜线上,这样的树的高度为N,此时查找特性几乎成了线性。
红黑树
红黑树是一种自平衡二叉查找树,是在计算机科学中用到的一种数据结构,典型的用途是实现关联数组。它是复杂的,但它的操作有着良好的最坏情况运行时间,并且在实践中是高效的:它可以在O(logn)时间内做查找,插入和删除,这里的n是树中元素的数目。红黑树查找的最坏时间复杂度也是O(logN)。
红黑树的特点:
- 每个节点不是红色就是黑色的;
- 根节点总是黑色的;
- 所有的叶节点都是是黑色的(红黑树的叶子节点都是空节点(NIL或者NULL)
- 如果结点是红色的,则它的子结点必须是黑色的(反之不一定)
- 从根节点到叶结点或空字节点的每条路径,必须包含相同数目的黑色结点(即相同的黑色高度)
特性3中的叶子结点,是只为空(NIL或null)的结点
特性5确保没有一条路径会比其他路径长出两倍,因而,红黑树是相对接近平衡的二叉树。
红黑树的结构
public class RBTree<T extends Comparable<T>> {
public RBNode<T> mRoot = null;//根结点
public static boolean RED = true;
public static boolean BLACK = false;
class RBNode<T extends Comparable<T>> {
//颜色
boolean color;
//关键字
T key;
//左子节点
RBNode<T> left;
//右子节点
RBNode<T> right;
//父节点
RBNode<T> parent;
public RBNode(boolean color, T key, RBNode<T> left, RBNode<T> right, RBNode<T> parent) {
this.color = color;
this.key = key;
this.left = left;
this.right = right;
this.parent = parent;
}
public T getKey() {
return key;
}
@Override
public String toString() {
return "" + key + (this.color == RED ? "RED" : "BLACK");
}
}
}
红黑树的修正
变色、左旋、右旋是红黑树在二叉树上的扩展操作,同时也是基于这三个操作才能遵守红黑树的五个特性。
变色
变色仅仅指的是红黑树节点的变色。因为红黑树节点必须是【红】或者【黑】这两种颜色,所以变色只是将当前的节点颜色进行变化,以满足特性(2,3,4,5)。
左旋
通常左旋操作用于将一个向右倾斜的红色链接旋转为向左链接。
/*************对红黑树节点x进行左旋操作 ******************/
/*
* 左旋示意图:对节点x进行左旋
* p p
* / /
* x y
* / \ / \
* lx y -----> x ry
* / \ / \
* ly ry lx ly
* 左旋做了三件事:
* 1. 将y的左子节点赋给x的右子节点,并将x赋给y左子节点的父节点(y左子节点非空时)
* 2. 将x的父节点p(非空时)赋给y的父节点,同时更新p的子节点为y(左或右)
* 3. 将y的左子节点设为x,将x的父节点设为y
*/
public void leftRotate(RBNode<T> x) {
if(x == null) return;
//1. 将y的左子节点赋给x的右子节点,并将x赋给y左子节点的父节点(y左子节点非空时)
RBNode<T> y = x.right;
x.right = y.left;
if(y.left != null) {
y.left.parent = x;
}
//2. 将x的父节点p(非空时)赋给y的父节点,同时更新p的子节点为y(左或右)
y.parent = x.parent;
if(x.parent == null) {
//x是根结点时,将根结点改为y
this.mRoot = y;
} else {
if(x == x.parent.left) {
x.parent.left = y;
} else {
x.parent.right = y;
}
}
//3. 将y的左子节点设为x,将x的父节点设为y
y.left = x;
x.parent = y;
}
右旋
/*************对红黑树节点y进行右旋操作 ******************/
/*
* 右旋示意图:对节点y进行右旋
* p p
* / /
* y x
* / \ / \
* x ry -----> lx y
* / \ / \
* lx rx rx ry
* 右旋做了三件事:
* 1. 将x的右子节点赋给y的左子节点,并将y赋给x右子节点的父节点(x右子节点非空时)
* 2. 将y的父节点p(非空时)赋给x的父节点,同时更新p的子节点为x(左或右)
* 3. 将x的右子节点设为y,将y的父节点设为x
*/
public void rightRotate(RBNode<T> y) {
if(y == null) return;
//1. 将x的右子节点赋给y的左子节点,并将y赋给x右子节点的父节点(x右子节点非空时)
RBNode<T> x = y.left;
y.left = x.right;
if(x.right != null){
x.right.parent = y;
}
//2. 将y的父节点p(非空时)赋给x的父节点,同时更新p的子节点为x(左或右)
x.parent = y.parent;
if(y.parent == null) {
this.mRoot = x;
} else {
if(y == y.parent.left) {
y.parent.left = x;
} else {
y.parent.right = x;
}
}
//3. 将x的右子节点设为y,将y的父节点设为x
x.right = y;
y.parent = x;
}
红黑树结点的添加
红黑树是在二叉树的基础上进行扩展的,其添加节点也是像二叉树一样进行添加,然后再做调整。
红黑树的第 5 条特征规定,任一节点到它子树的每个叶子节点的路径中都包含同样数量的黑节点。也就是说当我们往红黑树中插入一个黑色节点时,会违背这条特征。
同时第 4 条特征规定红色节点的左右孩子一定都是黑色节点,当我们给一个红色节点下插入一个红色节点时,会违背这条特征。
插入黑色节点的时候担心违背第5条,插入红色节点时担心违背第4条,所以将插入的节点改为红色,然后判断插入的节点的父亲是不是红色,是的话进行修改调整(变色、左旋、右旋)。同时在调整的过程中需要遵守5条特性。
以添加结点的父节点是祖父结点的左孩子的情况分析,分为以下几种情况:
- 如果添加的【红色节点】的【父节点】是黑色,那么树不需要做调整。
- 如果添加的【红色节点】的【父节点】是红色,那么树需要做调整。
- 父节点是红色,叔叔节点(父节点的兄弟节点)是红色的。
- 父节点是红色,叔叔节点是黑色,添加的节点是父节点的左孩子。
- 父节点是红色,叔叔节点是黑色,添加的节点是父节点的右孩子。
情况1:父节点是红色,叔叔节点(父节点的兄弟节点)是红色的。
修改过程如下:
- 将父节点和叔叔节点全部染成黑色(新增结点满足特性4),但是这样父亲和叔叔的分支多了一个黑色结点。
- 将祖父节点染成红色,这样祖父节点的两个分支满足了所有特性,但是需要继续检验祖父结点是否满足红黑树的特性
- 将祖父节点作为当前插入结点,继续向树根方向进行修改,循环向上直到父节点变为黑色或者到达树根为止。
情况2:父节点是红色,叔叔节点是黑色,添加的节点是父节点的左孩子。
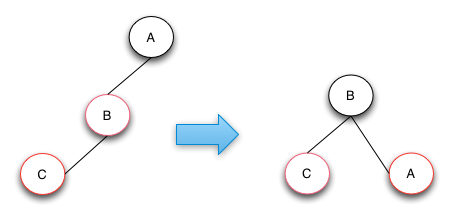
修改过程如下:
- 将父节点染成黑色;
- 将祖父节点染成红色;
- 将祖父节点进行右旋;
仅通过以上3个步骤就可以调整完使整个红黑树的结点满足5个特性。
情况3: 父节点是红色,叔叔节点是黑色,添加的节点是父节点的右孩子
修改过程如下:
通过对父节点进行左旋操作,就变成了情况2,再按照情况2继续调整。
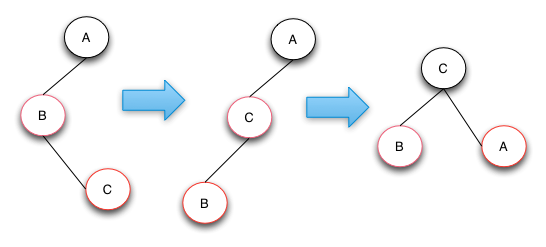
代码实现
/*********************** 向红黑树中插入节点 **********************/
public void insert(T key) {
RBNode<T> node = new RBNode<>(BLACK, key,null,null,null);
insert(node);
}
/**
* 1、将节点插入到红黑树中,这个过程与二叉搜索树是一样的
* 2、将插入的节点着色为"红色";将插入的节点着色为红色,不会违背"特性5"!
* 少违背了一条特性,意味着需要处理的情况越少。
* 3、通过一系列的旋转或者着色等操作,使之重新成为一颗红黑树。
* @param node 插入的节点
*/
public void insert(RBNode<T> node) {
RBNode<T> current = null;
RBNode<T> x = mRoot;
while(x != null) {
current = x;//跟踪父节点
int cmp = node.key.compareTo(x.key);
if(cmp < 0 ) {
x = x.left;
} else {
x = x.right;
}
}
//找到位置,将当前current作为node的父节点
node.parent = current;
//接下来判断node是插在左子节点还是右子节点
if(current != null) {
int cmp = node.key.compareTo(current.key);
if(cmp < 0) {
current.left = node;
} else {
current.right = node;
}
node.color = RED;
insertFixUp(node);//调整
} else {
this.mRoot = node;
}
}
/**
* 修改整插入node节点之后的红黑树
* @param node
*/
public void insertFixUp(RBNode<T> node) {
//定义父节点和祖父节点
RBNode<T> parent,gparent;
//需要修整的条件:父节点存在,且父节点的颜色是红色
while (((parent = node.parent) != null) && isRed(parent)) {
//祖父节点
gparent = parent.parent;
//若父节点是祖父节点的左子节点
if(parent == gparent.left) {
//获取叔叔节点
RBNode<T> uncle = gparent.right;
//case1:叔叔节点是红色
if(uncle != null && isRed(uncle)) {
//把父亲和叔叔节点涂成黑色
parent.color = BLACK;
uncle.color = BLACK;
//把祖父节点涂成红色
gparent.color = RED;
//向上修改
node = gparent;
continue;
}
//case2:叔叔节点是黑色,且当前节点是右子节点
if(node == parent.right) {
//对父节点左旋
leftRotate(parent);
//将父节点和当前节点对调,方便接下来的右旋
RBNode<T> tmp = parent;
parent = node;
node = tmp;
}
//case3:叔叔节点是红色,且当前节点是左子节点
parent.color = BLACK;
gparent.color = RED;
rightRotate(gparent);
} else {
//若父亲节点是祖父节点的右子节点,与上面完全相反
RBNode<T> uncle = gparent.left;
//case1:叔叔节点也是红色
if (uncle != null & isRed(uncle)) {
parent.color = BLACK;
uncle.color = BLACK;
gparent.color = RED;
node = gparent;
continue;
}
//case2: 叔叔节点是黑色的,且当前节点是左子节点
if (node == parent.left) {
rightRotate(parent);
RBNode<T> tmp = parent;
parent = node;
node = tmp;
}
//case3: 叔叔节点是黑色的,且当前节点是右子节点
parent.color = BLACK;
gparent.color = RED;
leftRotate(gparent);
}
}
//将根结点设置为黑色
this.mRoot.color = BLACK;
}
红黑树的删除
红黑树的删除同样是在二叉树进行删除的操作基础上进行调整的。
- 如果删除节点的左孩子或者右孩子不同时为null,只需要让其子树继承删除该节点的位置
- 如果删除的节点是叶子结点,直接进行调整
- 如果删除的节点左右孩子都不为null,需要后继节点替换被删除的节点的值和颜色,这样才不会引起红黑树平衡的破坏,只需要对后继节点删除后进行调整,回归到情况1和2:
- 后继节点为左子树最右边的叶子结点
- 后继节点为右子树最左边的叶子结点
如果需要删除的节点颜色为红色,那么红黑树的结构不被破坏,也就不需要进行调整。如果判断删除节点的颜色为黑色,那么就进行调整;
删除代码
/*********************** 删除红黑树中的节点 **********************/
public void remove(T key) {
RBNode<T> node;
if((node = search(mRoot,key)) != null) {
remove(node);
}
}
/**
* 1、被删除的节点没有儿子,即删除的是叶子节点。那么,直接删除该节点。
* 2、被删除的节点只有一个儿子。那么直接删除该节点,并用该节点的唯一子节点顶替它的初始位置。
* 3、被删除的节点有两个儿子。那么先找出它的后继节点(右孩子中的最小的,该孩子没有子节点或者只有一右孩子)。
* 然后把"它的后继节点的内容"复制给"该节点的内容";之后,删除"它的后继节点"。
* 在这里后继节点相当与替身,在将后继节点的内容复制给"被删除节点"之后,再将后继节点删除。
* ------这样问题就转化为怎么删除后继即节点的问题?
* 在"被删除节点"有两个非空子节点的情况下,它的后继节点不可能是双子都非空。
* 注:后继节点为补充被删除的节点;
* 即:意味着"要么没有儿子,要么只有一个儿子"。
* 若没有儿子,则回归到(1)。
* 若只有一个儿子,则回归到(2)。
*
* @param node 需要删除的节点
*/
public void remove(RBNode<T> node) {
RBNode<T> child,parent;
boolean color;
//删除节点的左右孩子都不为空
if((node.left != null) && (node.right != null)) {
//先找到被删除节点的后继节点,用它来取代别删除节点的位置
RBNode<T> replace = node;
//1. 获取后继节点(右孩子中最小)
replace = replace.right;
while(replace.left != null){
replace = replace.left;
}
//2. 处理后继节点和被删除节点的父节点之间的关系
if(node.parent != null) {
//被删除节点不是根结点
if(node == node.parent.left){
node.parent.left = replace;
} else {
node.parent.right = replace;
}
} else {
mRoot = replace;
}
//3. 处理后继节点的字节点和被删除节点的字节点之间的关系
//后继节点肯定不存在左子节点
child = replace.right;
parent = replace.parent;
//保存后继节点的颜色
color = replace.color;
//后继节点是被删除的节点的字节点
if(parent == node) {
parent = replace;
} else {
if(child != null) {
child.parent = parent;
}
parent.left = child;
replace.right = node.right;
node.right.parent = replace;
}
replace.parent = node.parent;
replace.color = node.color;
replace.left = node.left;
node.right.parent = replace;
//4. 如果移走的后继节点颜色是黑色,需要进行红黑树修正
if(color == BLACK) {
removeFixUp(child,parent);
}
node = null;
} else {
//被删除的节点是叶子节点或者只有一个孩子
if(node.left != null) {
child = node.left;
} else {
child = node.right;
}
parent = node.parent;
color = node.color;
if(child != null){
child.parent = parent;
}
//node节点不是根节点
if(parent != null) {
if(parent.left == node) {
parent.left = child;
} else {
parent.right = child;
}
} else {
mRoot = child;
}
if(color == BLACK) {
removeFixUp(child,parent);
}
node = null;
}
}
红黑树删除后节点调整
删除之后需要修整的节点就是后继节点的子节点(因为此时后继节点已经移走,往下一层会违反红黑树规则的就是后继节点原先的子节点)
删除修复操作是针对删除黑色节点才有的,当黑色节点被删除后会让整个树不符合RBTree的定义的第四条。需要做的处理是从兄弟节点上借调黑色的节点过来,如果兄弟节点没有黑节点可以借调的话,就只能往上追溯,将每一级的黑节点数减去一个,使得整棵树符合红黑树的定义。
删除操作的总体思想是从兄弟节点借调黑色节点使树保持局部的平衡,如果局部的平衡达到了,就看整体的树是否是平衡的,如果不平衡就接着向上追溯调整。
分为以下几种情况:
- 当前节点是黑色的,且兄弟节点是红色的(那么父节点和兄弟节点的子节点肯定是黑色的)
- 当前节点是黑色的,且兄弟节点是黑色的:
- 兄弟节点的两个子节点都是黑色的
- 兄弟节点的左子节点是红色,右子节点是黑色的
- 兄弟节点的左子节点是任意颜色,右子节点是红色的
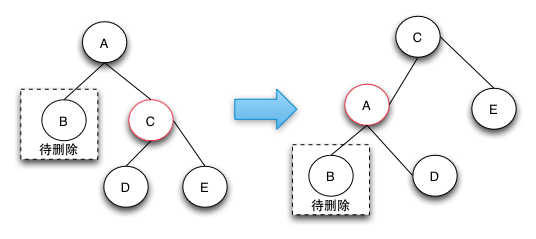
调整情况1:当前节点是黑色的,且兄弟节点是红色的
将父节点涂红,将兄弟节点涂黑,然后将当前节点的父节点进行支点左旋,这样会转换为情况2中的某种情况
调整情况2:当前节点是黑色,兄弟节点是黑色
兄弟节点的两个节点均为黑色
由于兄弟节点可以消除一个黑色节点,因为兄弟节点和兄弟节点的子节点都是黑色的,所以可以将兄弟节点变红,这样就可以保证树的局部的颜色符合定义了。这个时候需要将父节点A变成新的节点,继续向上调整,直到整颗树的颜色符合RBTree的定义为止。
这种情况下之所以要将兄弟节点变红,是因为如果把兄弟节点借调过来,会导致兄弟的结构不符合RBTree的定义,这样的情况下只能是将兄弟节点也变成红色来达到颜色的平衡。当将兄弟节点也变红之后,达到了局部的平衡了,但是对于祖父节点来说是不符合定义4的。这样就需要回溯到父节点,接着进行修复操作。
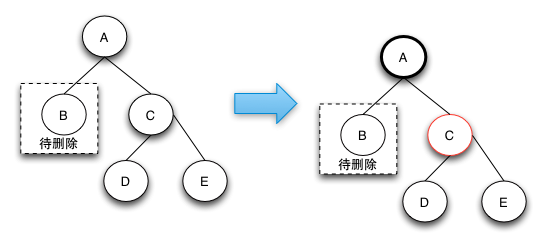
把当前节点的兄弟节点涂红,将当前节点指向其父节点,将其父节点指向当前节点的祖父节点,继续往树根递归判断以及调整
兄弟节点的左子节点是红色,右子节点时黑色的
把当前节点的兄弟节点涂红,把兄弟节点的左子节点涂黑,然后以兄弟节点作为支点做右旋操作,使之符合下一种情况
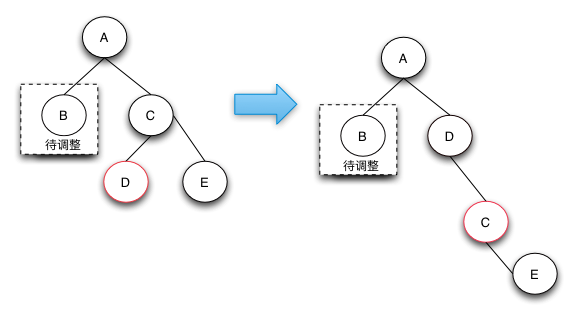
兄弟节点的右子节点是红色,左子节点任意颜色
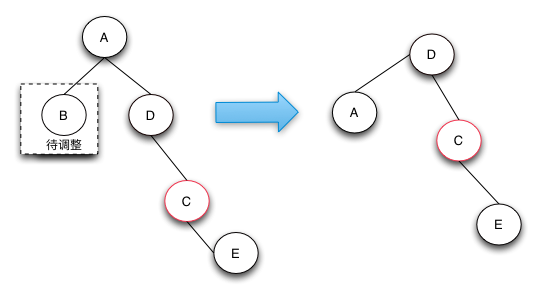
把兄弟节点涂成父节点的颜色,再把父节点涂黑,把兄弟节点的左子节点涂黑,然后以当前节点的父节点为支点做左旋操作。
代码实现
/**
* 红黑树删除修正函数
*
* 在从红黑树中删除插入节点之后(红黑树失去平衡),再调用该函数;
* 目的是将它重新塑造成一颗红黑树。
* 如果当前待删除节点是红色的,它被删除之后对当前树的特性不会造成任何破坏影响。
* 而如果被删除的节点是黑色的,这就需要进行进一步的调整来保证后续的树结构满足要求。
* 这里我们只修正删除的节点是黑色的情况:
*
* 调整思想:
* 为了保证删除节点的父节点左右两边黑色节点数一致,需要重点关注父节点没删除的那一边节点是不是黑色。
* 如果删除后父亲节点另一边比删除的一边黑色多,就要想办法搞到平衡。
* 1、把父亲节点另一边(即删除节点的兄弟树)其中一个节点弄成红色,也少了一个黑色。
* 2、或者把另一边多的节点(染成黑色)转过来一个
*
* 1)、当前节点是黑色的,且兄弟节点是红色的(那么父节点和兄弟节点的子节点肯定是黑色的);
* 2)、当前节点是黑色的,且兄弟节点是黑色的,且兄弟节点的两个子节点均为黑色的;
* 3)、当前节点是黑色的,且兄弟节点是黑色的,且兄弟节点的左子节点是红色,右子节点时黑色的;
* 4)、当前节点是黑色的,且兄弟节点是黑色的,且兄弟节点的右子节点是红色,左子节点任意颜色。
*
* 以上四种情况中,2,3,4都是(当前节点是黑色的,且兄弟节点是黑色的)的子集。
*
* 参数说明:
* @param node 删除之后代替的节点(后序节点)
* @param parent 后序节点的父节点
*/
private void removeFixUp(RBNode<T> node,RBNode<T> parent) {
RBNode<T> other;
RBNode<T> root = mRoot;
while ((node == null || node.color == BLACK) && node != root) {
if (parent.left == node) {
other = parent.right;
if (other.color == RED) {
//case 1:x的兄弟w是红色的【对应状态1,将其转化为2,3,4】
other.color = BLACK;
parent.color = RED;
leftRotate(parent);
other = parent.right;
}
if ((other.left == null || other.left.color == BLACK)
&& (other.right == null || other.right.color == BLACK)) {
//case 2:x的兄弟w是黑色,且w的两个孩子都是黑色的【对应状态2,利用调整思想1网树的根部做递归】
other.color = RED;
node = parent;
parent = node.parent;
} else {
if (other.right == null || other.right.color == BLACK) {
//case 3:x的兄弟w是黑色的,并且w的左孩子是红色的,右孩子是黑色的【对应状态3,调整到状态4】
other.left.color = BLACK;
other.color = RED;
rightRotate(other);
other = parent.right;
}
//case 4:x的兄弟w是黑色的;并且w的右孩子是红色的,左孩子任意颜色【对应状态4,利用调整思想2做调整】
other.color = parent.color;
parent.color = BLACK;
other.right.color = BLACK;
leftRotate(parent);
node = root;
break;
}
} else {
other = parent.left;
if (other.color == RED) {
//case 1:x的兄弟w是红色的
other.color = BLACK;
parent.color = RED;
rightRotate(parent);
other = parent.left;
}
if ((other.left == null || other.left.color == BLACK)
&& (other.right == null || other.right.color == BLACK)) {
//case 2:x兄弟w是黑色,且w的两个孩子也都是黑色的
other.color = RED;
node = parent;
parent = node.parent;
} else {
if (other.left == null || other.left.color == BLACK) {
//case 3:x的兄弟w是黑色的,并且w的左孩子是红色,右孩子为黑色。
other.right.color = BLACK;
other.color = RED;
leftRotate(other);
other = parent.left;
}
//case 4:x的兄弟w是黑色的;并且w的右孩子是红色的,左孩子任意颜色。
other.color = parent.color;
parent.color = BLACK;
other.left.color = BLACK;
rightRotate(parent);
node = root;
break;
}
}
}
if (node != null) {
node.color = BLACK;
}
}
B树
B树是一种平衡多叉查找树,主要用于构建磁盘文件索引。
一颗m阶B树,或为空树,或者必须满足以下特性的m叉树:
- 树中的每个结点最多含有m棵子树
- 若根结点是非终端节点,则至少有两颗子树
- 除根结点之外的所有非终端节点至少有
m/2(向上取整)棵子树 - 每个非终端节点中包含信息:
n,A0,K1,A1,K2,...,Kn,An。其中:
n表示关键字的个数,必须满足(m/2) -1 <= n <= (m-1)(m/2向上取整)Ki(1<=i<=n)为关键字,且关键字按升序排序- 指针
Ai(0<=i<=n)指向子树的根节点,Ai-1指向子树中所有节点的关键字均小于Ki,且大于Ki-1。
- 所有的叶子结点都出现再同一层,叶子结点不包含任何信息
以M=3的3阶B树为例:
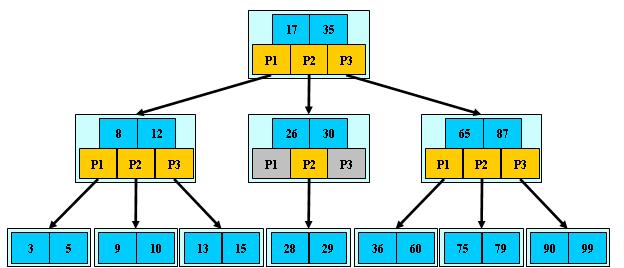
类型定义如下:
#define Max 1000 //节点中关键字的最大数目:Max=m-1,m是B树的阶
#define Min 500 //非根节点中关键字的最小数目:Min=m/2-1
typedef struct BTNode {
int keynum;//节点当前的关键字个数
KeyType key[Max+1];//关键字数组,key[0]未用
struct BTNode *parent;//双亲节点指针
struct BTNode *ptr[m+1];//孩子节点指针数组
Record *recptr[m+1];//记录指针向量,0号单元未用
} BTNode,*BTree; //B树的结点及指针类型
B树的查找
在B-树中查找给定关键字的方法类似于二叉排序树上的查找。不同的是在每个结点上确定向下查找的路径不一定是二路而是keynum+1路的。
对结点内的存放有序关键字序列的向量key[1..keynum]用顺序查找或折半查找方法查找。若在某结点内找到待查的关键字K,则返回该结点的地址及K在key[1..keynum]中的位置;否则,确定K在某个key[i]和key[i+1]之间结点后,从磁盘中读son[i]所指的结点继续查找。直到在某结点中查找成功;或直至找到叶结点且叶结点中的查找仍不成功时,查找过程失败。
时间开销:
B树的高度是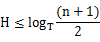 ,而不是其他几种树的
,而不是其他几种树的H=log2n,其中T为度数(每个节点包含的元素个数),即所谓的阶数,n为总元素个数或总关键字树。
B树查找的时间复杂度为O(Log2-N)。
B树的插入
B树的插入首先需要查找关键字k的插入位置,若找到,说明关键字已经存在,直接返回;否则查找操作必然在某个叶子节点处结束,在该节点插入后,若其关键字总数未达到m,算法结束,否则需要分裂结点。
分裂的方法是,生成一新结点,从中间位置把结点(不包括中间位置的关键字)分成两部分。前半部分留在旧节点中,后半部分复制到新节点中,中间部分的关键字连同新节点的存储位置插入到父节点中。如果插入后父节点的关键字个数也超过m-1,则继续分裂。这个向上分裂过程如果持续到根节点,则会产生新的根节点。
B树的删除
在B树上删除关键字k的过程可利用前述的查找过程找出该关键字所在的结点,然后根据k所在结点是否为最下层非终端结点进行不同的处理。
该节点为最下层非终端结点
首先直接从该节点删除关键字k,然后根据以下3种情况分别作相应的处理:
- 如果被删关键字所在结点的原关键字个数
n>=(m/2)(向上取整),则删除该关键字后仍然满足B树定义
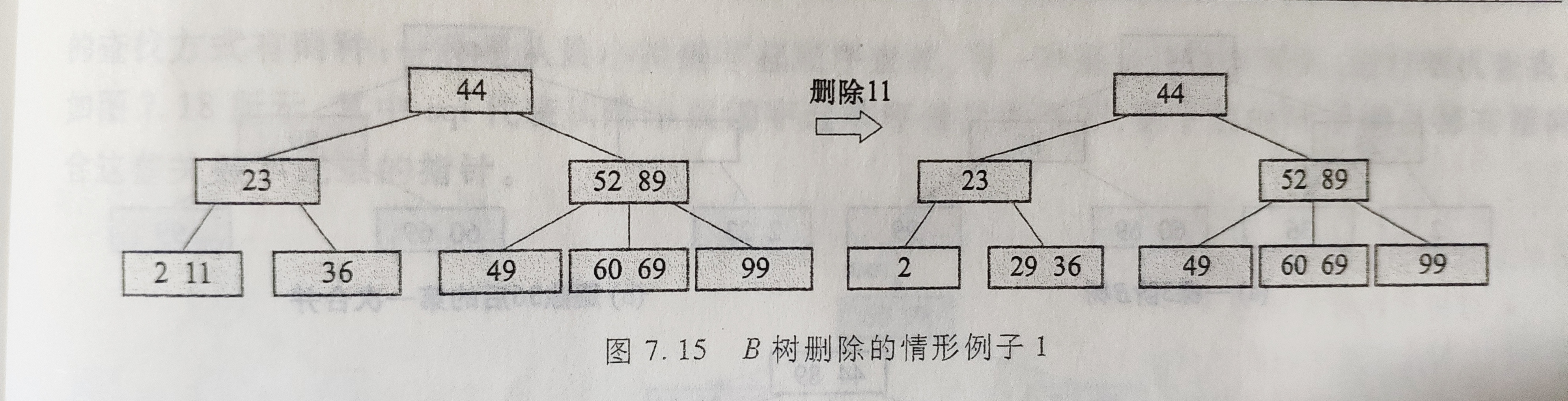
- 如果被删关键字所在结点的关键字个数n等于
m/2-1(向上取整),则删去该关键字后该节点将不满足B树的定义,需要调整:如果其左右兄弟结点中有“富余”的关键字,即与该节点相邻的右(或左)兄弟结点中的关键字数目大于m/2-1(向上取整),则可将右(左)兄弟结点中最小(大)关键字上移至双亲结点。而将双亲结点中小(大)于该上移关键字的关键字下移至被删关键字所在节点中。
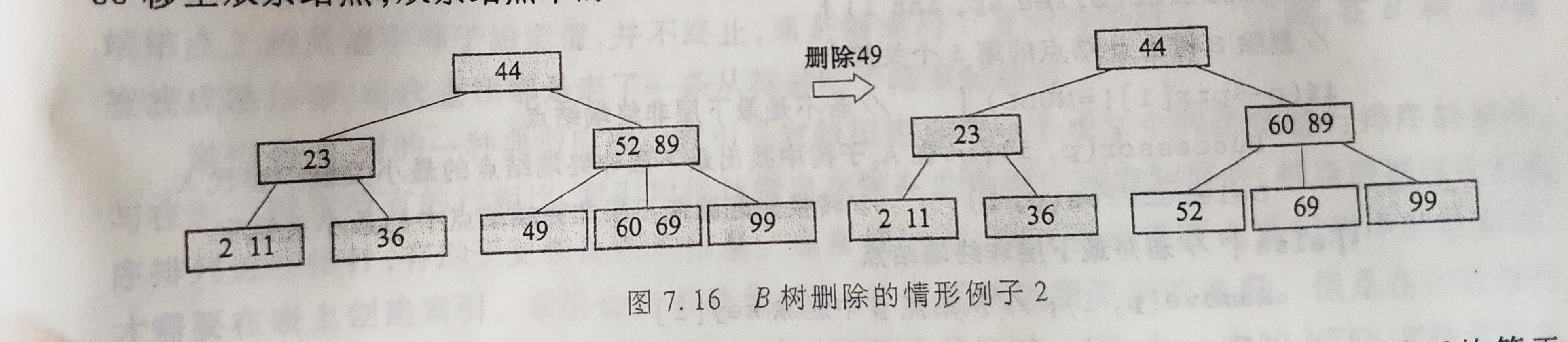
- 如果相邻兄弟结点中没有多余的关键字,即相邻兄弟结点中的关键字数目均等于
m/2-1(向上取整),此时需要把要删除关键字的结点与其左(或右)兄弟结点以及双亲结点中分割两者的关键字合并成一个节点,即在删除关键字后,该节点中剩余的关键字和指针,加上双亲结点中的关键字Ki一起,合并到Ai-1(或Ai)结点,即删除该关键字结点的左(右)兄弟结点。如果导致双亲结点中关键字个数小于m/2-1(向上取整),则对此双亲结点做同样的处理。如果直到对根节点也做合并处理,则整棵树减少一层。
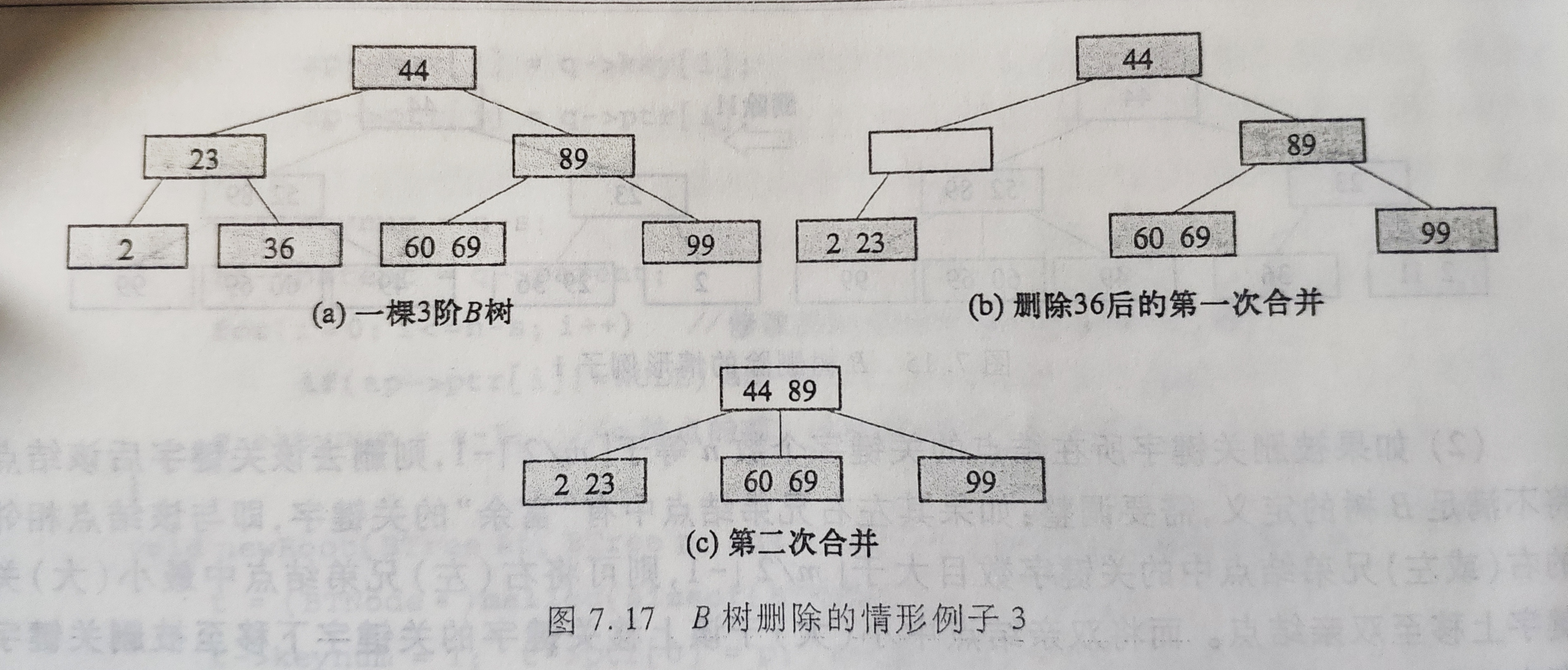
该节点不是最下面非终端节点
假设被删关键字为该节点中第i个关键字Ki,则可以从指针Ai所指的子树中找出位于最下层非终端节点的最小关键字替代Ki,并将其删除,于是这种情况转化为第1种情况。
B+树
B+树是应文件系统所需而提出的一种B树的类型。一颗m阶B+树和m阶B树的差异在于:
- 在n棵子树的结点中含有n个关键字
- 所有的叶子结点中包含了全部关键字的信息,以及指向含这些关键字记录的指针,且叶子结点本身依关键字的大小自小而大顺序链接。
- 所有的非终端结点可以看作索引部分,节点中仅含其子树(根节点)中的最大(或最小)关键字。
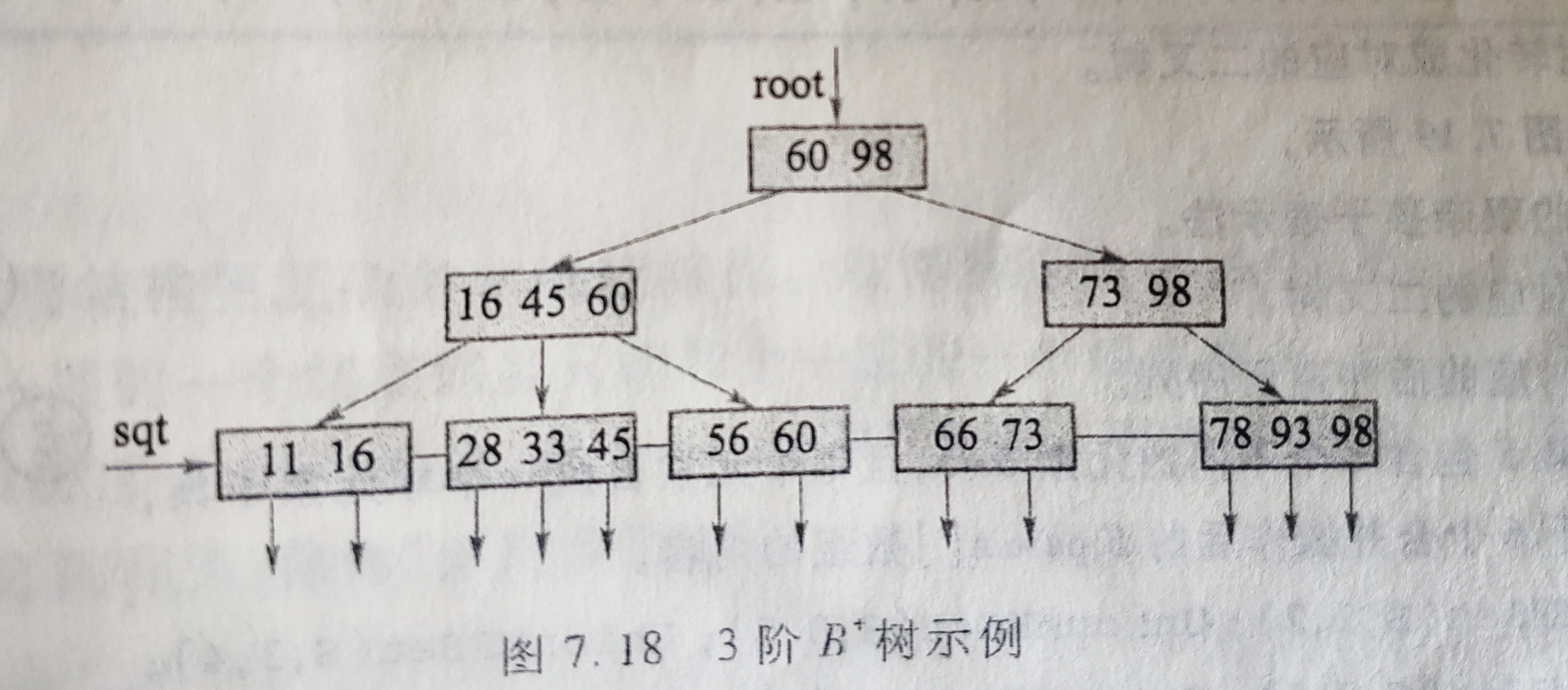
通常B+树有两个头指针,一个指向根节点,一个指向关键字最小的叶子结点。因此B+树查找方式有两种:一种是从最小关键字起顺序查找,另一种是从根节点开始,进行随机查找。
为什么说B+树比B树更适合实际应用中操作系统的文件索引和数据库索引?
B+树的磁盘读写代价更低
B+-tree的内部结点并没有指向关键字具体信息的指针。因此其内部结点相对B 树更小。
如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。
一次性读入内存中的需要查找的关键字也就越多。相对来说IO读写次数也就降低了。
举个例子,假设磁盘中的一个盘块容纳16bytes,而一个关键字2bytes,一个关键字具体信息指针2bytes。
一棵9阶B-tree(一个结点最多8个关键字)的内部结点需要2个盘快。而B+ 树内部结点只需要1个盘快。当需要把内部结点读入内存中的时候,B 树就比B+ 树多一次盘块查找时间(在磁盘中就是盘片旋转的时间)。B+树的查询效率更加稳定
由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
B*树
B*树是B+树的变体,在B+树的基础上(所有的叶子结点包含了全部关键字的信息,以及指向含有这些关键字记录的指针),还具有以下特点:
B*树中非根和非叶子结点再增加指向兄弟的指针;
B*树定义了非叶子结点关键字个数至少为 (2/3) * M,即块的最低使用率为2/3(代替B+树的1/2)
B+树和B*树的分裂:
B+树的分裂:当一个结点满时,分配一个新的结点,并将原结点中1/2的数据复制到新结点,最后在父结点中增加新结点的指针;B+树的分裂只影响原结点和父结点,而不会影响兄弟结点,所以它不需要指向兄弟的指针;
B*树的分裂:当一个结点满时,如果它的下一个兄弟结点未满,那么将一部分数据移到兄弟结点中,再在原结点插入关键字,最后修改父结点中兄弟结点的关键字(因为兄弟结点的关键字范围改变了);如果兄弟也满了,则在原结点与兄弟结点之间增加新结点,并各复制1/3的数据到新结点,最后在父结点增加新结点的指针;
所以,B*树分配新结点的概率比B+树要低,空间使用率更高;
LSM树
B+树最大的性能问题是会产生大量的随机IO,随着新数据的插入,叶子节点会慢慢分裂,逻辑上连续的叶子节点在物理上往往不连续,甚至分离的很远,但做范围查询时,会产生大量读随机IO。
对于大量的随机写也一样,举一个插入key跨度很大的例子,如7->1000->3->2000 ...,新插入的数据存储在磁盘上相隔很远,会产生大量的随机写IO.
从上面可以看出,低下的磁盘寻道速度严重影响性能(近些年来,磁盘寻道速度的发展几乎处于停滞的状态)。
为了克服B+树的弱点,HBase引入了LSM树的概念,即Log-Structured Merge-Trees。
为了更好的说明LSM树的原理,下面举个比较极端的例子:
现在假设有1000个节点的随机key,对于磁盘来说,肯定是把这1000个节点顺序写入磁盘最快,但是这样一来,读就悲剧了,因为key在磁盘中完全无序,每次读取都要全扫描;
那么,为了让读性能尽量高,数据在磁盘中必须得有序,这就是B+树的原理,但是写就悲剧了,因为会产生大量的随机IO,磁盘寻道速度跟不上。
LSM树本质上就是在读写之间取得平衡,和B+树相比,它牺牲了部分读性能,用来大幅提高写性能。
它的原理是把一颗大树拆分成N棵小树, 它首先写入到内存中(内存没有寻道速度的问题,随机写的性能得到大幅提升),在内存中构建一颗有序小树,随着小树越来越大,内存的小树会flush到磁盘上。当读时,由于不知道数据在哪棵小树上,因此必须遍历所有的小树,但在每颗小树内部数据是有序的。
关于LSM Tree,对于最简单的二层LSM Tree而言,内存中的数据和磁盘中的数据merge操作,如下图
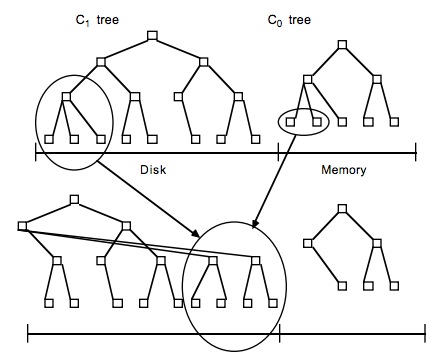
BFS和DFS
二叉树的广度优先遍历
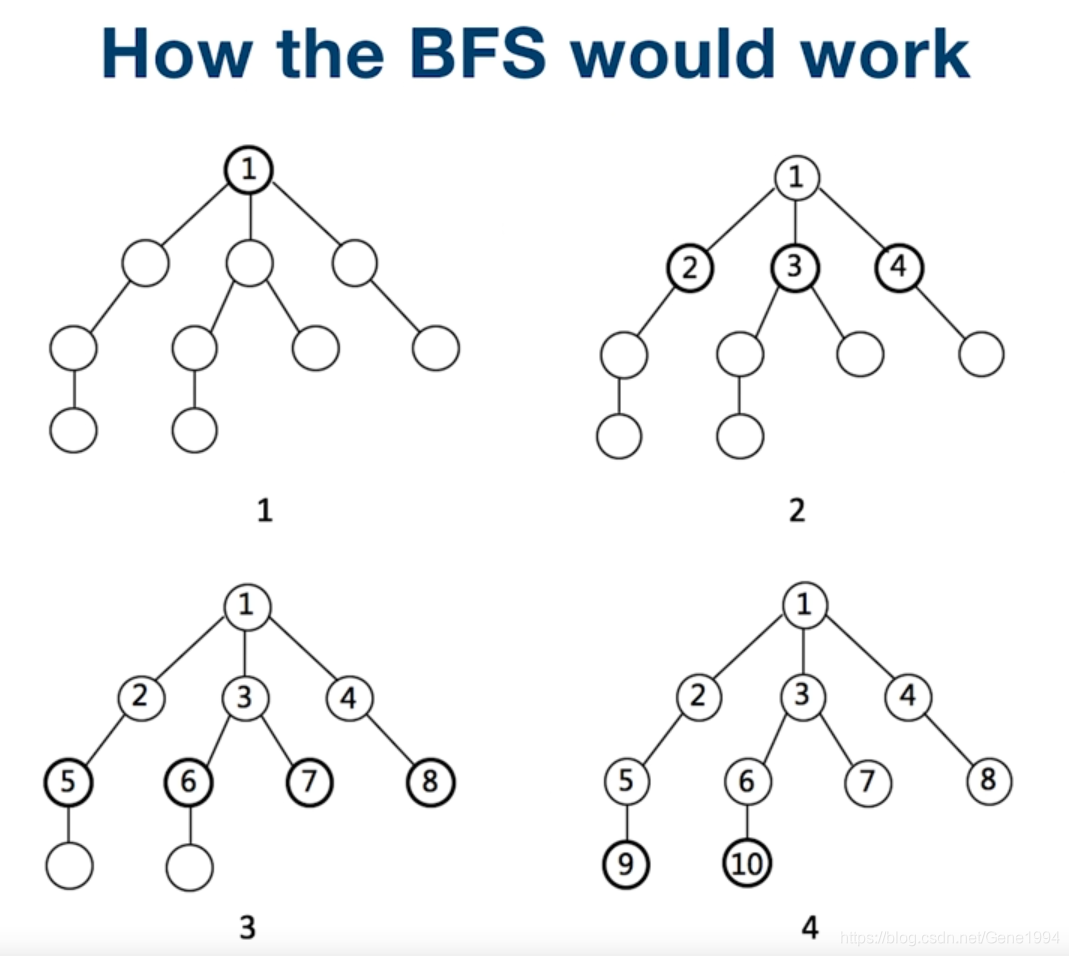
实现的基本思路是使用队列,首先将根节点入队。之后循环从队列中弹出最早进入的结点,每弹出一个,若该结点有左右子树,则将左、右子树分别入队。循环直到队列为空。
如果需要确定对应的层次,可以在每次左右子节点入队后再就如一个 null 表示当前 一层结束,弹出时判断是 null 说明当前层结束,继续弹出下一层。
//定义二叉树
public class TreeNode {
int val;
TreeNode left;
TreeNode right;
TreeNode(int x) {
this.val = x;
}
}
//使用队列实现BFS
public void BFSWithQueue(TreeNode root) {
Queue<TreeNode> queue = new LinkedList<>();
if(root!=null) {
queue.add(root);
}
while(!queue.isEmpty()) {
TreeNode treeNode = queue.poll();
if(treeNode.left != null){
queue.add(treeNode.left);
}
if(treeNode.right != null){
queue.add(treeNode.right);
}
}
}
二叉树的深度优先遍历
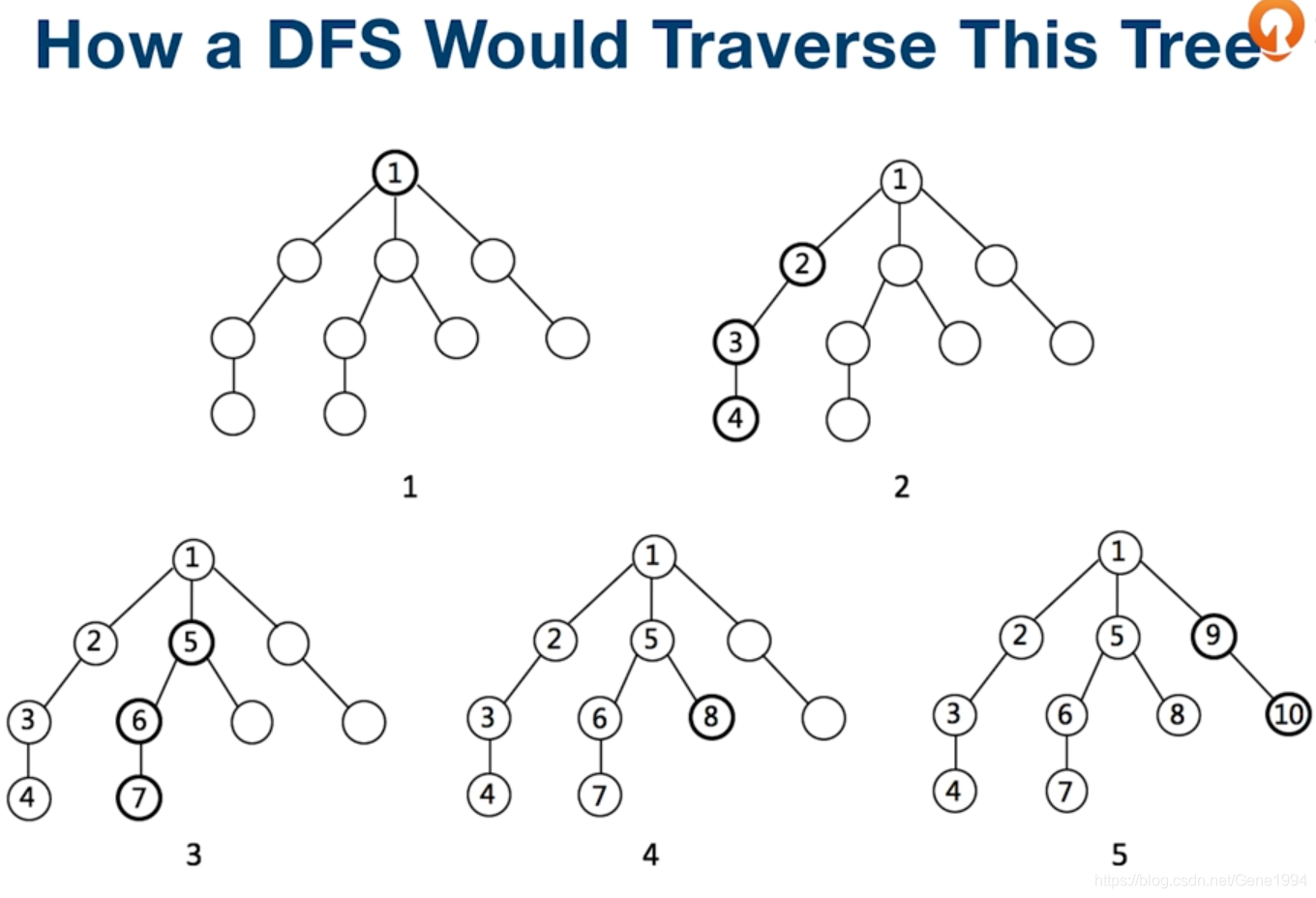
DFS遍历可以使用递归或者栈来实现:
使用递归实现:
public void DFSWithRecursion(TreeNode root) {
if(root == null) return;
if(root.left != null)
DFSWithRecursion(root.left);
if(root.right != null)
DFSWithRecursion(root.right);
}
使用栈实现:首先将根节点入栈。然后循环出栈。每弹出一个结点,如果其存在左右子树,先将右子树入栈,再将左子树入栈,循环直到栈为空。
public void DFSWithStack(TreeNode root) {
if(root == null)
return;
Stack<TreeNode> stack = new Stack<>();
stack.push(root);
while(!stack.isEmpty()) {
TreeNode treeNode = stack.pop();
if(treeNode.right != null)
stack.push(treeNode.right);
if(treeNode.left != null)
stack.push(treeNode.left);
}
}
图的遍历
图和树的最大区别在于图的下一个节点可能指向已访问过的节点。因此在使用BFS及DFS遍历时,应维护一个Set,Set中存放已被访问过的节点,在遍历时先判断节点未被访问过再遍历即可。
树的先序、中序、后序遍历
树的先序、中序、后序遍历是指对根节点的访问次序,三种遍历的顺序为:
- 前序遍历:根结点 —> 左子树 —> 右子树
- 中序遍历:左子树—> 根结点 —> 右子树
- 后序遍历:左子树 —> 右子树 —> 根结点
先序遍历
递归实现:
//定义二叉树
public class TreeNode {
int val;
TreeNode left;
TreeNode right;
TreeNode(int x) {
this.val = x;
}
}
//先序遍历(递归实现)
public void preOrderTraverse1(TreeNode root) {
if(root != null) {
System.out.println(root.val);
}
preOrderTraverse1(root.left);
preOrderTraverse1(root.right);
}
使用非递归实现:首先将根节点入栈。然后循环出栈。每弹出一个结点,如果其存在左右子树,先将右子树入栈,再将左子树入栈,循环直到栈为空。)
public void preOrderTraverse2(TreeNode root) {
if(root == null)
return;
Stack<TreeNode> stack = new Stack<>();
stack.push(root);
while(!stack.isEmpty()) {
TreeNode treeNode = stack.pop();
if(treeNode.right != null)
stack.push(treeNode.right);
if(treeNode.left != null)
stack.push(treeNode.left);
}
}
中序遍历
递归实现:
public void inOrderTraverse1(TreeNode root) {
if (root != null) {
inOrderTraverse1(root.left);
System.out.println(root.val);
inOrderTraverse1(root.right);
}
}
非递归实现:使用栈
public void inOrderTraverse2(TreeNode root) {
Stack<TreeNode> stack = new Stack<>();
TreeNode pnode = root;
while(pnode != null || !stack.isEmpty()) {
if(pnode != null) {
stack.push(pnode);
pnode = pnode.left;
} else {
pnode = stack.pop();
System.out.println(pnode.val);
pnode = pnode.right;
}
}
}
后序遍历
递归实现:
public void postOrderTraverse1(TreeNode root) {
if (root != null) {
postOrderTraverse1(root.left);
postOrderTraverse1(root.right);
System.out.print(root.val);
}
}
非递归实现:根结点先入栈,然后左子结点或右子结点,特别是右子结点弹出来之后,再弹出根结点,lastVisited 这个结点指针用于指示右子结点已经被访问完了,可以弹出根结点了。
public void postOrderTraverse2(TreeNode root) {
Stack<TreeNode> stack = new Stack<>();
TreeNode lastNodeVisited = null;
while(!stack.isEmpty() || root != null) {
if(root != null) {
stack.push(root);
root = root.left;
} else {
TreeNode pnode = stack.peek();
if(pnode.right != null && lastNodeVisited != pnode.right) {
root = pnode.right;
} else {
System.out.println(pnode.val);
lastNodeVisited = stack.pop();
}
}
}
}
布隆过滤器
布隆过滤器(Bloom Filter)是一个叫做 Bloom 的老哥于1970年提出的。可以把它看作由二进制向量(或者说位数组)和一系列随机映射函数(哈希函数)两部分组成的数据结构。相比于平时常用的的 List、Map 、Set 等数据结构,它占用空间更少并且效率更高,但是缺点是其返回的结果是概率性的,而不是非常准确的。理论情况下添加到集合中的元素越多,误报的可能性就越大。并且,存放在布隆过滤器的数据不容易删除。
位数组中的每个元素都只占用 1 bit ,并且每个元素只能是 0 或者 1。这样申请一个 100w 个元素的位数组只占用 1000000Bit / 8 = 125000 Byte = 125000/1024 kb ≈ 122kb 的空间。
原理
当一个元素加入布隆过滤器中的时候,会进行如下操作:
- 使用布隆过滤器中的哈希函数对元素值进行计算,得到哈希值(有几个哈希函数得到几个哈希值)。
- 根据得到的哈希值,在位数组中把对应下标的值置为 1。
当我们需要判断一个元素是否存在于布隆过滤器的时候,会进行如下操作:
- 对给定元素再次进行相同的哈希计算;
- 得到值之后判断位数组中的每个元素是否都为 1,如果值都为 1,那么说明这个值在布隆过滤器中,如果存在一个值不为 1,说明该元素不在布隆过滤器中。
举个简单的例子:
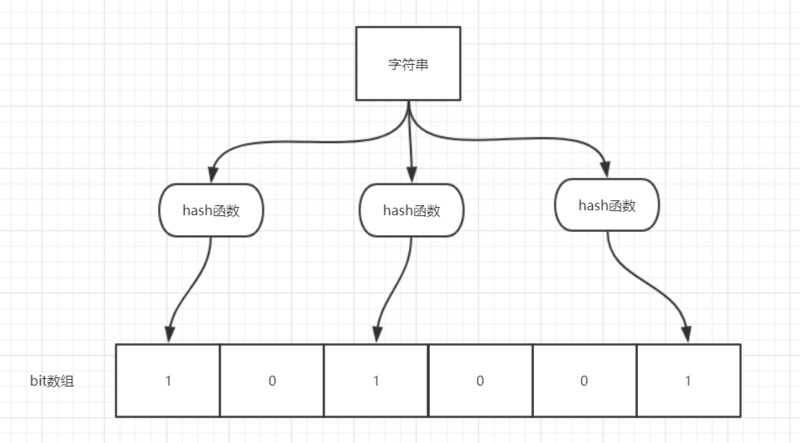
如图所示,当字符串存储要加入到布隆过滤器中时,该字符串首先由多个哈希函数生成不同的哈希值,然后在对应的位数组的下表的元素设置为 1(当位数组初始化时 ,所有位置均为0)。当第二次存储相同字符串时,因为先前的对应位置已设置为1,所以很容易知道此值已经存在(去重非常方便)。
如果需要判断某个字符串是否在布隆过滤器中时,只需要对给定字符串再次进行相同的哈希计算,得到值之后判断位数组中的每个元素是否都为 1,如果值都为 1,那么说明这个值在布隆过滤器中,如果存在一个值不为 1,说明该元素不在布隆过滤器中。
不同的字符串可能哈希出来的位置相同,这种情况可以适当增加位数组大小或者调整哈希函数。
综上,可以得出:布隆过滤器说某个元素存在,小概率会误判。布隆过滤器说某个元素不在,那么这个元素一定不在
使用场景
- 判断给定数据是否存在:比如判断一个数字是否在于包含大量数字的数字集中(数字集很大,5亿以上!)、 防止缓存穿透(判断请求的数据是否有效避免直接绕过缓存请求数据库)等等、邮箱的垃圾邮件过滤、黑名单功能等等。
- 去重:比如爬给定网址的时候对已经爬取过的 URL 去重。
通过 Java 编程手动实现布隆过滤器
如果想要手动实现一个的话,需要:
- 一个合适大小的位数组保存数据
- 几个不同的哈希函数
- 添加元素到位数组(布隆过滤器)的方法实现
- 判断给定元素是否存在于位数组(布隆过滤器)的方法实现。
import java.util.BitSet;
public class MyBloomFilter {
/**
* 数组的大小
*/
private static final int DEFAULT_SIZE = 2 << 24;
/**
* 通过这个数组创建6个不同的hash函数
*/
private static final int[] SEEDS = new int[] {3, 13, 46, 71, 91, 134};
/**
* 位数组
*/
private BitSet bits = new BitSet(DEFAULT_SIZE);
/**
* 包含哈希函数类的数组
*/
private SimplHash[] funcs = new SimplHash[SEEDS.length];
/**
* 静态内部类,用于 hash 操作
*/
public static class SimplHash {
int cap;
int seed;
public SimplHash(int cap,int seed) {
this.cap = cap;
this.seed = seed;
}
/**
* 计算 hash 值
*/
public int hash(Object value) {
int h;
return (value == null) ? 0 : Math.abs(seed * (cap-1) & ((h = value.hashCode()) ^ (h >>> 16)));
}
}
/**
* 初始化包含多个 hash 函数的类的数组,每个类中的 hash 函数不一样
*/
public MyBloomFilter() {
for(int i = 0; i < SEEDS.length; i++) {
funcs[i] = new SimplHash(DEFAULT_SIZE,SEEDS[i]);
}
}
/**
* 添加元素到位数组
*/
public void add(Object value) {
for(SimplHash func : funcs) {
int hash = func.hash(value);
bits.set(hash,true);
}
}
/**
* 判断指定值是否位于位数组中
*/
public boolean contain(Object value) {
boolean ret = true;
for(SimplHash func :funcs) {
ret = ret && bits.get(func.hash(value));
}
return ret;
}
}
也可以利用Google开源的 Guava 中自带的布隆过滤器。Guava 提供的布隆过滤器的实现还是很不错的但是它有一个重大的缺陷就是只能单机使用(另外,容量扩展也不容易),而现在互联网一般都是分布式的场景。为了解决这个问题,就需要用到 Redis 中的布隆过滤器了。
Redis中的布隆过滤器
Redis v4.0 之后有了 Module(模块/插件) 功能,Redis Modules 让 Redis 可以使用外部模块扩展其功能 。布隆过滤器就是其中的 Module。官网推荐了一个 RedisBloom 作为 Redis 布隆过滤器的 Module
使用 Docker 安装 RedisBloom后运行,
常用命令一览:
注意: key:布隆过滤器的名称,item : 添加的元素。
BF.ADD:将元素添加到布隆过滤器中,如果该过滤器尚不存在,则创建该过滤器。格式:BF.ADD {key} {item}。BF.MADD: 将一个或多个元素添加到“布隆过滤器”中,并创建一个尚不存在的过滤器。该命令的操作方式BF.ADD与之相同,只不过它允许多个输入并返回多个值。格式:BF.MADD {key} {item} [item ...]。BF.EXISTS: 确定元素是否在布隆过滤器中存在。格式:BF.EXISTS {key} {item}。BF.MEXISTS: 确定一个或者多个元素是否在布隆过滤器中存在格式:BF.MEXISTS {key} {item} [item ...]。
另外,BF.RESERVE 命令需要单独介绍一下:
这个命令的格式如下:
BF.RESERVE {key} {error_rate} {capacity} [EXPANSION expansion] 。
下面简单介绍一下每个参数的具体含义:
key:布隆过滤器的名称error_rate:误报的期望概率。这应该是介于 0 到 1 之间的十进制值。例如,对于期望的误报率0.1%(1000中为1),error_rate应该设置为0.001。该数字越接近零,则每个项目的内存消耗越大,并且每个操作的CPU使用率越高。capacity: 过滤器的容量。当实际存储的元素个数超过这个值之后,性能将开始下降。实际的降级将取决于超出限制的程度。随着过滤器元素数量呈指数增长,性能将线性下降。
可选参数:
expansion:如果创建了一个新的子过滤器,则其大小将是当前过滤器的大小乘以expansion。默认扩展值为2。这意味着每个后续子过滤器将是前一个子过滤器的两倍。
127.0.0.1:6379> BF.ADD myFilter java
(integer) 1
127.0.0.1:6379> BF.ADD myFilter javaguide
(integer) 1
127.0.0.1:6379> BF.EXISTS myFilter java
(integer) 1
127.0.0.1:6379> BF.EXISTS myFilter javaguide
(integer) 1
127.0.0.1:6379> BF.EXISTS myFilter github
(integer) 0
布谷鸟过滤器
布谷鸟哈希算法
布谷鸟过滤器源于布谷鸟哈希算法,布谷鸟哈希算法源于生活 —— 鸠占鹊巢的布谷鸟。布谷鸟喜欢滥交(自由),从来不自己筑巢。它将自己的蛋产在别人的巢里,让别人来帮忙孵化。待小布谷鸟破壳而出之后,因为布谷鸟的体型相对较大,它又将养母的其它孩子(还是蛋)从巢里挤走 —— 从高空摔下夭折了。
最简单的布谷鸟哈希结构是一维数组结构,会有两个 hash 算法将新来的元素映射到数组的两个位置。如果两个位置中有一个位置为空,那么就可以将元素直接放进去。但是如果这两个位置都满了,它就不得不鸠占鹊巢,随机踢走一个,然后自己霸占了这个位置。
不同于布谷鸟的是,布谷鸟哈希算法会帮这些受害者(被挤走的蛋)寻找其它的窝。因为每一个元素都可以放在两个位置,只要任意一个有空位置,就可以塞进去。所以这个被挤走的元素会看看自己的另一个位置有没有空,如果空了,就把自己挪过去。但是如果这个位置也被别人占了,那么它会再来一次鸠占鹊巢,将受害者的角色转嫁给别人。然后这个新的受害者还会重复这个过程直到所有的元素都找到了自己的位置为止。
但是会遇到一个问题,那就是如果数组太拥挤了,连续踢来踢去几百次还没有停下来,这时候会严重影响插入效率。这时候布谷鸟哈希会设置一个阈值,当连续占巢行为超出了某个阈值,就认为这个数组已经几乎满了。这时候就需要对它进行扩容,重新放置所有元素。
还会有另一个问题,那就是可能会存在挤兑循环。比如两个不同的元素,hash 之后的两个位置正好相同,这时候它们一人一个位置没有问题。但是这时候来了第三个元素,它 hash 之后的位置也和它们一样,很明显,这时候会出现挤兑的循环。不过让三个不同的元素经过两次 hash 后位置还一样,这样的概率并不是很高,除非 hash 算法太过简单。布谷鸟哈希算法对待这种挤兑循环的态度就是认为数组太拥挤了,需要扩容(实际上并不是这样)。
优化
上面的布谷鸟哈希算法的平均空间利用率并不高,大概只有 50%。到了这个百分比,就会很快出现连续挤兑次数超出阈值。这样的哈希算法价值并不明显,所以需要对它进行改良。
改良的方案之一是增加 hash 函数,让每个元素不止有两个巢,而是三个巢、四个巢。这样可以大大降低碰撞的概率,将空间利用率提高到 95%左右。
另一个改良方案是在数组的每个位置上挂上多个座位,类似于使用多维数组,这样即使两个元素被 hash 在了同一个位置,也不必立即鸠占鹊巢,因为这里有多个座位,可以随意坐一个。除非这多个座位都被占了,才需要进行挤兑。很明显这也会显著降低挤兑次数。这种方案的空间利用率只有 85%左右,但是查询效率会很高,同一个位置上的多个座位在内存空间上是连续的,可以有效利用 CPU 高速缓存。
所以更加高效的方案是将上面的两个改良方案融合起来,比如使用 4 个 hash 函数,每个位置上放 2 个座位。这样既可以得到时间效率,又可以得到空间效率。这样的组合甚至可以将空间利用率提到高 99%,这是非常了不起的空间效率。这也是布谷鸟过滤器的核心原理。
原理
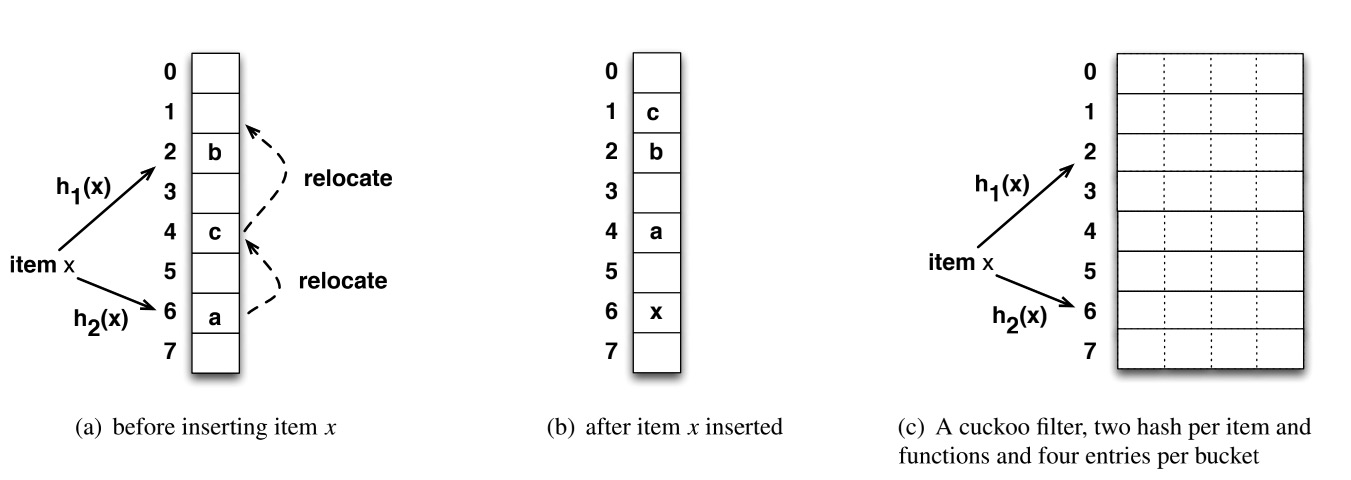
布谷鸟过滤器是由很多桶组成的,每个桶存储经过哈希计算后的值,该值只会存储固定位数。
过滤器中有 n 个桶,桶的数量是根据要存储的项的数量计算得来的。通过哈希算法可以计算出一个项应该存储在哪个桶中,此外每增加一个哈希算法,就可以对一个项产生一个候选桶,当重复插入时,会把当前存储的项踢到候选桶中去。理论上哈希算法越多,空间利用率越高,但在实际测试使用 k=2 个哈希函数就可以达到 98% 的利用率了。
这里不同于布谷鸟哈希的是,布谷鸟哈希会存储整个元素,而布谷鸟过滤器中只会存储元素的指纹信息(几个bit,类似于布隆过滤器)。这里过滤器牺牲了数据的精确性换取了空间效率。正是因为存储的是元素的指纹信息,所以会存在误判率,这点和布隆过滤器如出一辙。
每一个桶会存储多个指纹,这受制于桶的大小,不同的指纹可能映射到同一个桶中。桶越大,空间利用率越高,但同时每次查询扫描同一桶中指纹数越多,因此产生假阳性的概率越高,此时就需要提高存储的指纹位数,用以降低冲突率,维持假阳性率。
首先布谷鸟过滤器会选用两个 hash 函数,但是每个位置可以放置多个座位。这两个 hash 函数选择的比较特殊,因为过滤器中只能存储指纹信息。当这个位置上的指纹被挤兑之后,它需要计算出另一个对偶位置。而计算这个对偶位置是需要元素本身的,如果使用下面这种 hash 方式:
fp = fingerprint(x)
p1 = hash1(x) % l
p2 = hash2(x) % l
我们知道了 p1 和 x 的指纹,是没办法直接计算出 p2 的。
特殊的 hash 函数
布谷鸟过滤器巧妙的地方就在于设计了一个独特的 hash 函数,使得可以根据 p1 和元素指纹直接计算出 p2,而不需要完整的 x 元素。
fp = fingerprint(x)
p1 = hash(x)
p2 = p1 ^ hash(fp) // 异或
从上面的公式中可以看出,当知道 fp 和 p1,就可以直接算出 p2。同样如果知道 p2 和 fp,也可以直接算出 p1 —— 对偶性。
p1 = p2 ^ hash(fp)
所以根本不需要知道当前的位置是 p1 还是 p2,只需要将当前的位置和 hash(fp) 进行异或计算就可以得到对偶位置。而且只需要确保 hash(fp) != 0 就可以确保 p1 != p2,如此就不会出现自己踢自己导致死循环的问题。
为什么这里的 hash 函数不需要对数组的长度取模呢?实际上是需要的,但是布谷鸟过滤器强制数组的长度必须是 2 的指数,所以对数组的长度取模等价于取 hash 值的最后 n 位。在进行异或运算时,忽略掉低 n 位之外的其它位就行。将计算出来的位置 p 保留低 n 位就是最终的对偶位置。
在布谷鸟过滤器的论文中提到了实现布谷鸟过滤器所需的几个参数,主要是
- 哈希函数个数(k):哈希个数,取 2 就足够
- 桶大小(b):每个桶存储多少个指纹
- 指纹大小(f):每个指纹存储键的哈希值的多少位
布谷鸟过滤器的作者依靠试验数据告诉了我们如何选择最合适的构建参数,可以得到如下结论:
- 过滤器无法 100% 填满,存在最大负载因子 α,那么均摊到每个项上的存储占用空间就是 f/α
- 当保持过滤器总大小不变时,桶越大负载因子越高,即空间利用率越高,但每个桶存储的指纹越多,查询时可能发生冲突的概率也越高,为了维持假阳性率不变,桶越大,就需要越大的指纹。
根据上述的理论依据,得出的相关实验数据有:
- 使用 k=2 个哈希函数时,当桶大小 b=1(即直接映射哈希表)时,负载因子 α 为 50%,但使用桶大小 b=2、4 或 8 时则分别会增加到 84%、95% 和 98%
- 为了保证假阳性率 r,需要保证
2b/2f(f是指数)≤r,那么指纹 f 大小约为f≥log2(2b/r)=log2(1/r)+log2(2b),那每个项的均摊成本即为C≤[log2(1/r)+log2(2b)]/α - 实验数据表明,当 r>0.002 时。每桶有两个条目比每桶使用四个条目产生的结果略好;当 r 减小到 0.00001<r≤0.002 时,每个桶四个条目可以最小化空间
- 如果使用半排序桶,可以对每一个存储项减少 1bit 的存储空间,但其仅作用于 b=4 的过滤器
这样一来我们便可以确定如何选择参数来构建布谷鸟过滤器了:
首先哈希函数使用两个就足够了,这可以达到足够的空间利用率。根据需要的假阳性率,可以确定使用多大的桶大小,当然 b 的选择并不绝对,即使 r>0.002,也可以使用 b=4 来启用半排序桶。之后可以根据 b 来计算为了达到目标假阳性率,需要的 f 的大小,这样所有的过滤器参数就确定了。
将上面的结论与布隆过滤器的每项 1.44log2(1/r) 对比,可以发现启用半排序时,当 r<0.03 左右,布谷鸟过滤器空间更小,若不启用半排序,则退化到 r<0.003 左右。
查找
布谷鸟过滤器的查找过程很简单。给定一个项x,算法首先根据公式计算 x 的指纹和两个候选桶。然后读取这两个桶:如果两个桶中的任何现有指纹匹配,则布谷鸟过滤器返回 true,否则过滤器返回 false。请注意,只要不发生桶溢出,就可以确保没有假阴性。
Algorithm 3: Delete(x)
f = fingerprint(x);
i1 = hash(x);
i2 = i1 ⊕ hash(f);
if bucket[i1] or bucket[i2] has f then
remove a copy of f from this bucket;
return True;
return False;
删除
布隆过滤器检查给定项的两个候选桶,如果任何桶中的指纹匹配,则从该桶中删除匹配指纹的一份副本。
删除不需要在删除项后清除条目。它还避免了两个项共享一个候选桶并具有相同指纹时的“错误删除”问题。 例如,如果项 x 和 y 都驻留在桶 1 中并在指纹 f 上碰撞,部分键布谷鸟哈希确保它们也可以驻留在桶 2 中,因为 i2=i1⊕hash(f)。 删除 x 时,进程是否删除插入 x 或 y 时添加的 f 的副本并不重要。 x 删除后, y 仍被视为集合成员,因为在任何一个桶1 和 2 中都留下了相应的指纹。这样做的一个重要结果是,删除后过滤器的假阳性行为保持不变。
请注意,要安全地删除项 x,必须事先插入它。否则删除非插入项可能会无意中删除碰巧共享相同指纹的真实、不同的项。这一要求也适用于所有其他支持删除的过滤器。
但是布谷鸟过滤器的删除操作并不完美,想要让布谷鸟过滤器支持删除操作,那么就必须不能允许插入操作多次插入同一个元素,确保每一个元素不会被插入多次(kb+1)。这里的 k 是指 hash 函数的个数 2,b 是指单个位置上的座位数,这里我们是 4。
在现实世界的应用中,确保一个元素不被插入指定的次数那几乎是不可能做到的。因为不能完美的支持删除操作,所以也就无法较为准确地估计内部的元素数量。
布谷鸟过滤器与布隆过滤器的比较
布谷鸟过滤器的优点:
- 由于布谷鸟哈希表更加紧凑,因此可以更加节省空间。
- 在查询时,布隆过滤器要采用多种哈希函数进行多次哈希,而布谷鸟过滤器只需一次哈希,因此查询效率很高
- 三是布谷鸟过滤器支持删除,而布隆过滤器不支持删除
布谷鸟过滤器的缺点:
- 布谷鸟过滤器采用一种备用候选桶的方案,候选桶与首选桶可以通过位置和存储值互相异或得出,这种对应关系要求桶的大小必须是 2 的指数倍
- 布隆过滤器插入时计算好哈希直接写入位即可,而布谷鸟过滤器在计算后可能会出现当前位置上已经存储了指纹,这时候就需要将已存储的项踢到候选桶,随着桶越来越满,产生冲突的可能性越来越大,插入耗时越来越高,因此其插入性能相比布隆过滤器很差
- 插入重复元素:布隆过滤器在插入重复元素时并没有影响,只是对已存在的位再置一遍。而布谷鸟过滤器对已存在的值会做踢出操作,因此重复元素的插入存在上限
- 布谷鸟过滤器的删除并不完美:有上述重复插入的限制,删除时也会出现相关的问题:删除仅在相同哈希值被插入一次时是完美的,如果元素没有插入便进行删除,可能会出现误删除,这和假阳性率的原因相同;如果元素插入了多次,那么每次删除仅会删除一个值,需要知道元素插入了多少次才能删除干净,或者循环运行删除直到删除失败为止。
Bitmap
BitMap的基本思想就是用bit位来标记某个元素对应的value,而key就是这个元素。
例如,在下图中,是一个字节代表的8位,下标为1,2,4,6的bit位的值为1,则该字节表示{1,2,4,6}这几个数。

在Java中,1个int占用4个字节,如果用int来存储这四个数字的话,那么将需要4 * 4 = 16字节。
BitMap可以用于快速排序,查找,及去重等操作。优点是占用内存少(相较于数组)和运算效率高,但是缺点也非常明显,无法存储重复的数据,并且在存储较为稀疏的数据时,浪费存储空间较多。
假设我们需要用 Bitmap 快速判断数字 [0, 7] 是否存在于集合中。
Bitmap 的存储结构:
若使用1字节(8位)的变量(如
uint8_t类型),而非数组,则每个位直接对应一个数字。例如:位序号(从右到左): 7 6 5 4 3 2 1 0 二进制值 : 0 0 0 0 0 0 0 0- 第
0位表示数字0,第3位表示数字3,依此类推。
- 第
插入数字3的操作
定位到第3位(从右向左,从0开始计数)。
将第3位设为 1:
二进制值变为:0b00001000(十进制8)- 此时,变量(如
b)的值是8,而非设置数组的某个索引。
- 此时,变量(如
若使用数组存储 Bitmap
假设我们使用 整数数组(如 uint32_t b[])存储 Bitmap,每个整数包含32位。
例如:要表示数字 0~31,只需一个 uint32_t 变量;若要表示 0~63,则需要两个 uint32_t 变量。
插入数字3的操作
计算数组索引和位偏移:
- 数组索引:
3 / 32 = 0(第一个整数)。 - 位偏移:
3 % 32 = 3(第3位)。
- 数组索引:
设置第0个数组元素的第3位为1:
b[0] |= (1 << 3); // b[0] 的二进制变为 0b00000000 00000000 00000000 00001000关键点:操作的是数组
b的第 0 个元素的第 3 位,而非数组的第3个元素!
RoaringBitmap
Roaring Bitmaps 是一种十分优秀的压缩位图索引,简称 RBM。RBM 的主要设计思路分为两点:
RBM 将 32 位无符号整数按照高 16 位分桶,即最多可能有 2^16=65536 个桶,论文内称为 container。存储数据时,按照数据的高 16 位找到 container(找不到就会新建一个),再将低 16 位放入 container 中。也就是说,一个 RBM 就是很多 container 的集合。
RBM 的容器采用三种数据结构:
Array Container,Bitmap Container和RunContainer。Array Container存放稀疏的数据,Bitmap Container存放稠密的数据。即,若一个 Container 里面的 Integer 数量小于 4096,就用 Short 类型的有序数组来存储值。若大于 4096,就用 Bitmap 来存储值。RunContainer在初始的 RBM 实现中并没有它,而是在后来才实现的,它使用可变长度的 unsigned short 数组存储用行程长度编码(RLE)压缩后的数据。举个例子,连续的整数序列11, 12, 13, 14, 15, 27, 28, 29会被 RLE 压缩为两个二元组11, 4, 27, 2,表示 11 后面紧跟着 4 个连续递增的值,27 后面跟着 2 个连续递增的值。由此可见,RunContainer 的压缩效果可好可坏。考虑极端情况:如果所有数据都是连续的,那么最终只需要 4 字节;如果所有数据都不连续(比如全是奇数或全是偶数),那么不仅不会压缩,还会膨胀成原来的两倍大。所以, RBM 引入 RunContainer 是作为其他两种 container 的折衷方案。
使用例子
假设现在要将 821697800 这个 32 bit 的整数插入 RBM 中,整个算法流程是这样的:
- 821697800 对应的 16 进制数为 30FA1D08, 其中高 16 位为 30FA, 低16位为 1D08。
- 先用二分查找从一级索引(即 Container Array)中找到数值为 30FA 的容器(如果该容器不存在,则新建一个),从图中可以看到,该容器是一个 Bitmap 容器。
- 找到了相应的容器后,看一下低 16 位的数值 1D08,它相当于是 7432,因此在 Bitmap 中找到相应的位置,将其置为 1 即可。
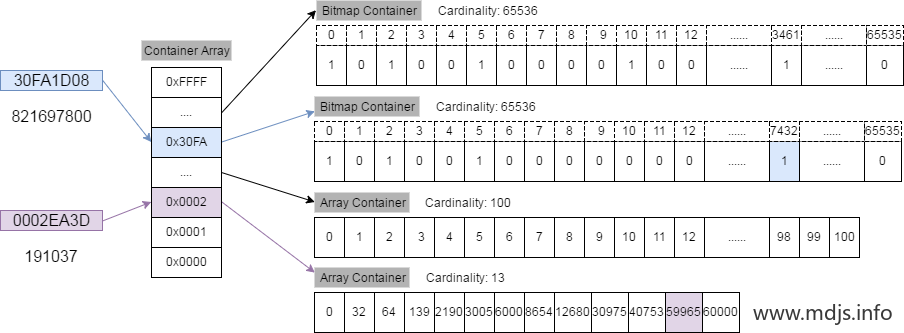
如果换一个数值插入,比如说 191037,它的 16 进制的数值是 0002EA3D ,插入流程和前面的例子一样,不同的就在于, 高 16 位对应的容器是一个 Array Container,仍然用二分查找找到相应的位置再插入即可。
原理
数据结构
前面说古,RBM 的容器采用三种数据结构:Array Container ,Bitmap Container 和 RunContainer。
ArrayContainer
当桶内数据的基数不大于 4096 时,会采用它来存储,其本质上是一个 unsigned short 类型的有序数组。数组初始长度为 4,随着数据的增多会自动扩容(但最大长度就是4096)。另外还维护有一个计数器,用来实时记录基数,当ArrayContainer 的容量超过 4096 后,会自动转成 BitmapContainer 存储。由于一个 short 为 2 字节,因此 ArrayContainer 最大的数据量为 4096 * 2b = 8kb
BitmapContainer
当桶内数据的基数大于 4096 时,会采用它来存储,其本质就是普通位图,用长度固定为 1024 的 unsigned long 型数组表示,由于每个container需要存储2^16 = 65536个数据,如果通过BitMap进行存储的话,需要使用2^16个bit进行存储,即8kb的数据空间。它同样有一个计数器。
用 4096 作为分割的原因:
可以从下图中看出 ArrayContainer 和 BitMapContainer 的内存空间使用关系,当数据量小于 4096 时,使用ArrayContainer比较合适,当数据量大于等于4096时,使用BitMapContainer更佳:
RunContainer
RunContainer是后续加入折中方案,它使用可变长度的unsigned short数组存储,基于 Run Length Encoding 压缩算法的容器,其压缩原理是对于连续的数字只记录初始数字以及连续的长度,比如有一串数字 2,3,4,5,6 那么经过压缩后便只剩下2,5。从压缩原理也可以看出,这种算法对于数据的紧凑程度非常敏感,连续程度越高压缩率也越高。通过 optimize 从 BitmapContainer 转化 RunContainer 之前需要判断是否占用内存更小。
时空分析
增删改查的时间复杂度方面,BitmapContainer 只涉及到位运算,显然为 O(1)。而 ArrayContainer 和 RunContainer 都需要用二分查找在有序数组中定位元素,故为 O(logN)。
空间占用(即序列化时写出的字节流长度)方面,BitmapContainer 是恒定为 8192B 的。ArrayContainer 的空间占用与基数(c)有关,为 (2 + 2c) B;RunContainer 的则与它存储的连续序列数(r)有关,为 (2 + 4r)B。
Container的创建与转换
在创建一个新 container 时,如果只插入一个元素,RBM 默认会用 ArrayContainer 来存储。如果插入的是元素序列的话,则会先根据上面的方法计算 ArrayContainer 和 RunContainer 的空间占用大小,并选择较小的那一种进行存储。
当 ArrayContainer 的容量超过 4096 后,会自动转成 BitmapContainer 存储。4096 这个阈值很聪明,低于它时 ArrayContainer 比较省空间,高于它时 BitmapContainer 比较省空间。也就是说 ArrayContainer 存储稀疏数据,BitmapContainer 存储稠密数据,可以最大限度地避免内存浪费。
RBM 还可以通过调用特定的 API(名为optimize)比较 ArrayContainer/BitmapContainer 与等价的 RunContainer 的内存占用情况,一旦 RunContainer 占用较小,就转换之。
平衡二叉树
AVL 树是最早被发明的自平衡二叉查找树。在 AVL 树中,任一节点对应的两棵子树的最大高度差为 1,因此它也被称为高度平衡树。查找、插入和删除在平均和最坏情况下的时间复杂度都是 O(logn)。增加和删除元素的操作则可能需要借由一次或多次树旋转,以实现树的重新平衡。
二叉搜索树的查找效率取决于树的高度,因此保持树的高度最小,即可保证树的查找效率。
平衡二叉查找树,简称平衡二叉树,它具有如下几个性质:
- 可以是空树。
- 假如不是空树,任何一个结点的左子树与右子树都是平衡二叉树,并且高度之差的绝对值不超过 1。
平衡二叉树的节点结构如下:
typedef struct AVLNode *Tree;
typedef int ElementType;
struct AVLNode{
int depth; //深度,这里计算每个结点的深度,通过深度的比较可得出是否平衡
Tree parent; //该结点的父节点
ElementType val; //结点值
Tree lchild;
Tree rchild;
AVLNode(int val=0) {
parent = NULL;
depth = 0;
lchild = rchild = NULL;
this->val=val;
}
};
平衡因子
定义:某节点的左子树与右子树的高度(深度)差即为该节点的平衡因子(BF,Balance Factor),平衡二叉树中不存在平衡因子大于 1 的节点。在一棵平衡二叉树中,节点的平衡因子只能取 0 、1 或者 -1 ,分别对应着左右子树等高,左子树比较高,右子树比较高。
最小失衡子树
在新插入的结点向上查找,以第一个平衡因子的绝对值超过 1 的结点为根的子树称为最小不平衡子树。也就是说,一棵失衡的树,是有可能有多棵子树同时失衡的。而这个时候,我们只要调整最小的不平衡子树,就能够将不平衡的树调整为平衡的树。
平衡二叉树的失衡调整主要是通过旋转最小失衡子树来实现的。根据旋转的方向有两种处理方式,左旋与右旋。
旋转的目的就是减少高度,通过降低整棵树的高度来平衡。哪边的树高,就把那边的树向上旋转。
AVL树的四种插入节点方式
假设一颗 AVL 树的某个节点为 A,有四种操作会使 A 的左右子树高度差大于 1,从而破坏了原有 AVL 树的平衡性。平衡二叉树插入节点的情况分为以下四种:
| 插入方式 | 描述 | 旋转方式 |
|---|---|---|
| LL | 在 A 的左子树根节点的左子树上插入节点而破坏平衡 | 右旋转 |
| RR | 在 A 的右子树根节点的右子树上插入节点而破坏平衡 | 左旋转 |
| LR | 在 A 的左子树根节点的右子树上插入节点而破坏平衡 | 先左旋后右旋 |
| RL | 在 A 的右子树根节点的左子树上插入节点而破坏平衡 | 先右旋后左旋 |
AVL树的四种删除节点方式
AVL 树和二叉查找树的删除操作情况一致,都分为四种情况:
- 删除叶子节点
- 删除的节点只有左子树
- 删除的节点只有右子树
- 删除的节点既有左子树又有右子树
只不过 AVL 树在删除节点后需要重新检查平衡性并修正,同时,删除操作与插入操作后的平衡修正区别在于,插入操作后只需要对插入栈中的弹出的第一个非平衡节点进行修正,而删除操作需要修正栈中的所有非平衡节点。
删除操作的大致步骤如下:
- 以前三种情况为基础尝试删除节点,并将访问节点入栈。
- 如果尝试删除成功,则依次检查栈顶节点的平衡状态,遇到非平衡节点,即进行旋转平衡,直到栈空。
- 如果尝试删除失败,证明是第四种情况。这时先找到被删除节点的右子树最小节点并删除它,将访问节点继续入栈。
- 再依次检查栈顶节点的平衡状态和修正直到栈空。
对于删除操作造成的非平衡状态的修正,可以这样理解:对左或者右子树的删除操作相当于对右或者左子树的插入操作,然后再对应上插入的四种情况选择相应的旋转就好了。
hash 冲突怎么解决
开放定址法(再散列法)
这种方法也称再散列法,其基本思想是:当关键字 key 的哈希地址 p=hash(key) 出现冲突时,以 p 为基础,产生另一个哈希地址 p1,如果 p1 仍然冲突,再以 p 为基础,产生另一个哈希地址 p2,…,直到找出一个不冲突的哈希地址 pi ,将相应元素存入其中。这种方法有一个通用的再散列函数形式:
Hi = (hash(key)+di) % m i=1,2,…,n
其中 hash(key) 为哈希函数,m 为表长,di 称为增量序列。增量序列的取值方式不同,相应的再散列方式也不同。主要有以下三种:
线性探测再散列
dii = 1,2,3,…,m-1
这种方法的特点是:冲突发生时,顺序查看表中下一单元,直到找出一个空单元或查遍全表。
例如,已知哈希表长度 m=11,哈希函数为:hash(key)= key % 11,则 hash(47) = 3,hash(36) = 4,hash(60) = 5,假设下一个关键字为 69,则 hash(69) = 3,与 47 冲突。
如果用线性探测再散列处理冲突,下一个哈希地址为 H1=(3 + 1)% 11 = 4,仍然冲突,再找下一个哈希地址为 H2=(3 + 2)% 11 = 5,还是冲突,继续找下一个哈希地址为 H3=(3 + 3)% 11 = 6,此时不再冲突,将 69 填入 5 号单元。
二次探测再散列
di=12,-12,22,-22,…,k2,-k2 ( k<=m/2 )
这种方法的特点是:冲突发生时,在表的左右进行跳跃式探测,比较灵活。
对于上面的例子,如果用二次探测再散列处理冲突,下一个哈希地址为 H1 =(3 + 12)% 11 = 4,仍然冲突,再找下一个哈希地址为 H2 =(3 - 12)% 11 = 2,此时不再冲突,将69填入2号单元。
伪随机探测再散列
di=伪随机数序列。
具体实现时,应建立一个伪随机数发生器,(如i=(i+p) % m),并给定一个随机数做起点。
对于上面的例子,如果用伪随机探测再散列处理冲突,且伪随机数序列为:2,5,9,……..,则下一个哈希地址为 H1=(3 + 2)% 11 = 5,仍然冲突,再找下一个哈希地址为 H2=(3 + 5)% 11 = 8,此时不再冲突,将 69 填入 8 号单元。
再哈希法
这种方法是同时构造多个不同的哈希函数:
Hi = RH1(key) i=1,2,…,k
当哈希地址 Hi=RH1(key)发生冲突时,再计算 Hi=RH2(key)……,直到冲突不再产生。这种方法不易产生聚集,但增加了计算时间。
链地址法
这种方法的基本思想是将所有哈希地址为 i 的元素构成一个称为同义词链的单链表,并将单链表的头指针存在哈希表的第 i 个单元中,因而查找、插入和删除主要在同义词链中进行。链地址法适用于经常进行插入和删除的情况。
建立公共溢出区
这种方法的基本思想是:将哈希表分为基本表和溢出表两部分,凡是和基本表发生冲突的元素,一律填入溢出表。
对比
拉链法的优点
与开放定址法相比,拉链法有如下几个优点:
- 拉链法处理冲突简单,且无堆积现象,即非同义词决不会发生冲突,因此平均查找长度较短;
- 由于拉链法中各链表上的结点空间是动态申请的,故它更适合于造表前无法确定表长的情况;
- 开放定址法为减少冲突,要求装填因子 α 较小,故当结点规模较大时会浪费很多空间。而拉链法中可取α≥1,且结点较大时,拉链法中增加的指针域可忽略不计,因此节省空间;
- 在用拉链法构造的散列表中,删除结点的操作易于实现。只要简单地删去链表上相应的结点即可。而对开放地址法构造的散列表,删除结点不能简单地将被删结点的空间置为空,否则将截断在它之后填人散列表的同义词结点的查找路径。这是因为各种开放地址法中,空地址单元(即开放地址)都是查找失败的条件。因此在用开放地址法处理冲突的散列表上执行删除操作,只能在被删结点上做删除标记,而不能真正删除结点。
拉链法的缺点
拉链法的缺点是:指针需要额外的空间,故当结点规模较小时,开放定址法较为节省空间,而若将节省的指针空间用来扩大散列表的规模,可使装填因子变小,这又减少了开放定址法中的冲突,从而提高平均查找速度。
参考内容
主要参考以来两篇博客以及相关博客推荐,因找的博客比较多,没注意记录,最后好多忘了在哪2333,如果有侵权,请及时联系我,非常抱歉。
https://github.com/Snailclimb/JavaGuide