JavaIO
1. 同步和异步的概念是什么
- 同步:同步就是发起一个调用后,被调用者未处理完请求之前,调用不返回
- 异步:异步就是发起一个调用后,立刻得到被调用者的回应表示已经接收到请求,但是被调用者并没有返回结果,此时线程可以处理其他的请求,被调用者通常依靠事件,回调等机制来通知调用者其返回结果。
同步和异步的最大区别在于异步的话调用者不需要等待处理结束,被调用者会通过回调等机制来通知调用者其返回结果。
2. 阻塞和非阻塞的概念是什么
- 阻塞:阻塞就是发起一个请求,调用者一直等待请求结果返回,也就是当前线程会被挂起,无法从事其他任务,只有当条件就绪才能继续。
- 非阻塞:非阻塞就是发起一个请求,调用者不用一直等着结果返回,可以先去干其他事情。
例子:你妈妈让你烧水,小时候你比较笨啊,在那里傻等着水开(同步阻塞)。等你稍微再长大一点,你知道每次烧水的空隙可以去干点其他事,然后只需要时不时来看看水开了没有(同步非阻塞)。后来,你们家用上了水开了会发出声音的壶,这样你就只需要听到响声后就知道水开了,在这期间你可以随便干自己的事情,你需要去倒水了(异步非阻塞)。
3. BIO,NIO,AIO区别
Java中BIO,NIO和AIO理解为是 Java 语言对操作系统的各种 IO 模型的封装。程序员在使用这些 API 的时候,不需要关心操作系统层面的知识,也不需要根据不同操作系统编写不同的代码。只需要使用Java的API就可以了。
BIO(Blocking I/O)
同步阻塞I/O模型,数据的读取写入必须阻塞在一个线程内等待其完成。
传统BIO
BIO通信(一请求一应答)模型图如下:
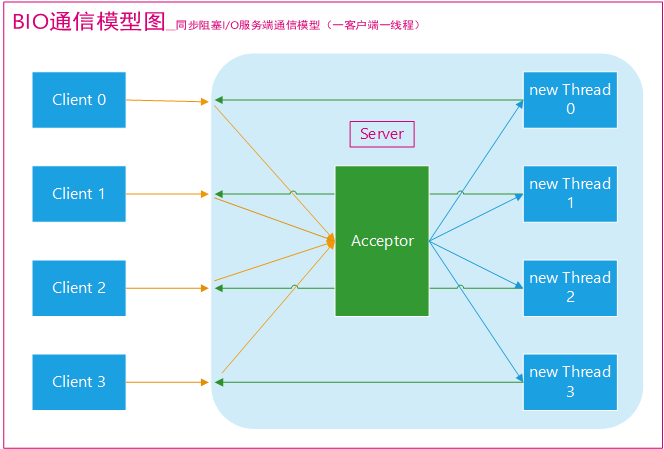
采用BIO通道模型的服务端,通常由一个独立的Acceptor线程负责监听客户端的连接。一般通过在while(true)循环中服务端会调用accept()方法等待接收客户端的连接的方式监听请求,请求一旦接收到一个连接请求,就可以建立通信套接字在这个通信套接字上进行读写操作,此时不能再接收其他客户端连接请求,只能等待同当前连接的客户端的操作执行完成,不过可以通过多线程来支持多个客户端的连接,如上图所示。
在 Java 虚拟机中,线程是宝贵的资源,线程的创建和销毁成本很高,除此之外,线程的切换成本也是很高的。尤其在 Linux 这样的操作系统中,线程本质上就是一个进程,创建和销毁线程都是重量级的系统函数。如果并发访问量增加会导致线程数急剧膨胀可能会导致线程堆栈溢出、创建新线程失败等问题,最终导致进程宕机或者僵死,不能对外提供服务。
如果要让BIO通信模型能够同时处理多个客户端请求,就必须使用多线程(主要原因是socket.accept()、socket.read()、socket.write()涉及的三个主要函数都是同步阻塞的),也就是说它在接收到客户端连接请求之后为每一个客户端创建一个新的线程进行链路处理,处理完成之后,通过输出流返回应答给客户端,线程销毁。这就是典型的一请求一应答通信模型。可以设想一下如果这个连接不做任何事情的话就会造成不必要的线程开销,不过可以通过线程池机制改善,线程池还可以让线程的创建和回收成本相对较低。使用FixedThreadPool可以有效的控制线程的最大数量,保证系统优先的资源的控制,实现N(客户端请求数量):M(处理客户端请求的线程数量)的伪异步I/O模型。(N可能远远大于M)。也就是伪异步IO。
伪异步IO
为了解决同步阻塞I/O面临的一个链路需要一个线程处理的问题,有人对它的线程模型进行了优化一一后端通过一个线程池来处理多个客户端的请求接入,形成客户端个数M:线程池最大线程数N的比例关系,其中M可以远远大于N.通过线程池可以灵活地调配线程资源,设置线程的最大值,防止由于海量并发接入导致线程耗尽。
伪异步IO模型图:
采用线程池和任务队列可以实现一种叫做伪异步的 I/O 通信框架,它的模型图如上图所示。当有新的客户端接入时,将客户端的Socket封装成一个Task(该任务实现java.lang.Runnable接口)投递到后端的线程池中进行处理,JDK 的线程池维护一个消息队列和 N 个活跃线程,对消息队列中的任务进行处理。由于线程池可以设置消息队列的大小和最大线程数,因此,它的资源占用是可控的,无论多少个客户端并发访问,都不会导致资源的耗尽和宕机。
伪异步I/O通信框架采用了线程池实现,因此避免了为每个请求都创建一个独立线程造成的线程资源耗尽问题。不过因为它的底层仍然是同步阻塞的BIO模型,因此无法从根本上解决问题。
代码示例
下面代码中演示了BIO通信(一请求一应答)模型。我们会在客户端创建多个线程依次连接服务端并向其发送”当前时间+:hello world”,服务端会为每个客户端线程创建一个线程来处理.
客户端:
public class IOClient {
public static void main(String[] args) {
// 创建一个socket对象,指定要连接的服务器
new Thread(() -> {
try {
Socket socket = new Socket("127.0.0.1", 3333);
while (true) {
try {
socket.getOutputStream().write((new Date() + ": hello world").getBytes());
Thread.sleep(2000);
} catch (Exception e) {
}
}
} catch (IOException e) {
}
}).start();
}
}
服务端端:
public class IOServer {
public static void main(String[] args) throws IOException {
// 创建一个Socket服务端处理客户端连接请求
ServerSocket serverSocket = new ServerSocket(3333);
// 接收到客户端连接请求之后为每个客户端创建一个新的线程进行链路处理
new Thread(() -> {
while (true) {
try {
//等待客户端连接,会造成阻塞,如果客户端连接成功,立即返回一个Socket对象
Socket socket = serverSocket.accept();
// 每一个新的连接都创建一个线程,负责读取数据
new Thread(() -> {
try {
int len;
byte[] data = new byte[1024];
InputStream inputStream = socket.getInputStream();
// 按字节流方式读取数据
while ((len = inputStream.read(data)) != -1) {
System.out.println(new String(data, 0, len));
}
} catch (IOException e) {
}
}).start();
} catch (IOException e) {
}
}
}).start();
}
}
总结
在活动连接数不是特别高(小于单机1000)的情况下,这种模型是比较不错的,可以让每一个连接专注于自己的 I/O 并且编程模型简单,也不用过多考虑系统的过载、限流等问题。线程池本身就是一个天然的漏斗,可以缓冲一些系统处理不了的连接或请求。但是,当面对十万甚至百万级连接的时候,传统的 BIO 模型是无能为力的。因此,需要一种更高效的 I/O 处理模型来应对更高的并发量。
NIO
NIO是一种同步非阻塞的I/O模型,在java1.4中引入了NIO框架,对应java.nio包,提供了Channel、Selector、Buffer等抽象。
NIO中的N可以理解为Non-blocking,不单纯是New。它支持面向缓冲的,基于通道的I/O操作方法。 NIO提供了与传统BIO模型中的Socket和ServerSocket相对应的SocketChannel和ServerSocketChannel两种不同的套接字通道实现,两种通道都支持阻塞和非阻塞两种模式。阻塞模式使用就像传统中的支持一样,比较简单,但是性能和可靠性都不好;非阻塞模式正好与之相反。对于低负载、低并发的应用程序,可以使用同步阻塞I/O来提升开发速率和更好的维护性;对于高负载、高并发的(网络)应用,应使用 NIO 的非阻塞模式来开发。
NIO的特性/与IO的区别
Non-Blocking IO(非阻塞IO)
IO流是阻塞的,NIO流是不阻塞的。
Java NIO使我们可以进行非阻塞IO操作。比如说,单线程中从通道读取数据到Buffer,同时可以继续做别的事情,当数据读取到buffer中后,线程再继续处理数据。写数据也是一样。另外,非阻塞写也是如此。一个线程请求写入一些数据到某通道,但不需要等待它完全写入,这个线程同时可以做别的事情。
Java IO的各种流是阻塞的。这意味着,当一个线程调用read()或write()时,该线程被阻塞,直到有一些数据被读取,或数据完全写入。该线程在此期间不能再干任何事情了。
Buffer(缓冲区)
IO面向流(Stream oriented),而NIO面向缓冲区(Buffer oriented)
Buffer是一个对象,它包含一些要写入或者读出的数据。在NIO类库中加入Buffer对象,体现了新库与原I/O的一个重要区别。在面向流的I/O中,可以将数据直接写入或者将数据直接读到Stream对象中。虽然Stream中也有Buffer开头的扩展类,但只是流的包装类,还是从流读到缓冲区,而NIO是直接读到Buffer中进行操作。
在NIO库中,所有数据都是用缓冲区处理的。在读取数据时,它是直接读到缓冲区中的;在写入数据时,写入到缓冲区中。任何时候访问NIO中的数据,都是通过缓冲区进行操作。
最常用的缓冲区是ByteBuffer,一个ByteBuffer提供了一组功能用于操作byte数组。除了ByteBuffer,还有其他一些缓冲区,事实上,每一种Java基本类型(除了Boolean)都有对应的一种缓冲区。
在Java NIO中使用的核心缓冲区如下:(涵盖了通过I/O发送的基本数据类型:byte,char,short,int,long,float,double):
- ByteBuffer
- CharBuffer
- ShortBuffer
- IntBuffer
- FloatBuffer
- DoubleBuffer
- LongBuffer
Channel(通道)
NIO通过Channel(通道)进行读写
通道是双向的,可读也可写,而流的读写是单向的。无论读写,通道只能和Buffer交互。因为Buffer,通道可以异步地读写。
在Java NIO中,主要使用的通道如下(涵盖了UDP和TCP网络IO,以及文件IO):
- DatagramChannel
- SocketChannel
- FileChannel
- ServerSocketChannel
Selector(选择器)
NIO有选择器,而IO没有
这是一个可以用于监听多个通道的对象,如数据到达,连接打开等等。因此,单线程可以监视多个通道中的数据。
选择器用于使用单个线程处理多个通道。因此,它需要较少的线程来处理这些通道。线程之间的切换对于操作系统来说是昂贵的。因此,为了提高系统效率选择器是有用的。
要使用Seclector的话,必须把Channel注册到Selector上,然后就可以调用Seclector的select()方法。这个方法会进入阻塞,直到有一个channel的状态符合条件,当方法返回时,线程可以处理这些时间。
NIO读数据和写数据的方式
通常来说NIO中的所有IO都是从Channel(通道)开始的。
- 从通道进行数据读取:创建一个缓冲区,然后请求通道读取数据
- 从通道进行数据写入:创建一个缓冲区,填充数据,并要求通道写入数据
NIO核心组件
NIO包含下面几个核心组件:
Channel(通道)Buffer(缓冲区)Selector(选择器)
NIO整个体系包含的类远远不止这三个,只能说这三个是NIO体系的“核心API”。
代码示例
上面客户端保持不变,服务端修改如下:
public class NIOServer {
public static void main(String[] args) throws IOException {
// 1. serverSelector负责轮询是否有新的连接,服务端监测到新的连接之后,不再创建一个新的线程,
// 而是直接将新连接绑定到clientSelector上,这样就不用 IO 模型中 1w 个 while 循环在死等
Selector serverSelector = Selector.open();
// 2. clientSelector负责轮询连接是否有数据可读
Selector clientSelector = Selector.open();
new Thread(() -> {
try {
// 对应IO编程中服务端启动
ServerSocketChannel listenerChannel = ServerSocketChannel.open();
listenerChannel.socket().bind(new InetSocketAddress(3333));
listenerChannel.configureBlocking(false);
listenerChannel.register(serverSelector, SelectionKey.OP_ACCEPT);
while (true) {
// 监测是否有新的连接,这里的1指的是阻塞的时间为 1ms
if (serverSelector.select(1) > 0) {
Set<SelectionKey> set = serverSelector.selectedKeys();
Iterator<SelectionKey> keyIterator = set.iterator();
while (keyIterator.hasNext()) {
SelectionKey key = keyIterator.next();
if (key.isAcceptable()) {
try {
// (1) 每来一个新连接,不需要创建一个线程,而是直接注册到clientSelector
SocketChannel clientChannel = ((ServerSocketChannel) key.channel()).accept();
clientChannel.configureBlocking(false);
clientChannel.register(clientSelector, SelectionKey.OP_READ);
} finally {
keyIterator.remove();
}
}
}
}
}
} catch (IOException ignored) {
}
}).start();
new Thread(() -> {
try {
while (true) {
// (2) 批量轮询是否有哪些连接有数据可读,这里的1指的是阻塞的时间为 1ms
if (clientSelector.select(1) > 0) {
Set<SelectionKey> set = clientSelector.selectedKeys();
Iterator<SelectionKey> keyIterator = set.iterator();
while (keyIterator.hasNext()) {
SelectionKey key = keyIterator.next();
if (key.isReadable()) {
try {
SocketChannel clientChannel = (SocketChannel) key.channel();
ByteBuffer byteBuffer = ByteBuffer.allocate(1024);
// (3) 面向 Buffer
clientChannel.read(byteBuffer);
byteBuffer.flip();
System.out.println(
Charset.defaultCharset().newDecoder().decode(byteBuffer).toString());
} finally {
keyIterator.remove();
key.interestOps(SelectionKey.OP_READ);
}
}
}
}
}
} catch (IOException ignored) {
}
}).start();
}
}
从上面的代码可以看出,JDK原生 NIO 有以下缺点:
- 编程复杂,编程模型难
- JDK的NIO底层由epoll实现,该实现饱受诟病的空轮询bug会导致cpu飙升100%
- 项目庞大之后,自行实现的NIO很容易出现各类bug,维护成本较高
AIO(Asynchronous I/O)
AIO也就是NIO2,在Java7引入了NIO的改进版NIO2,它是异步非阻塞的IO模型。异步IO是基于事件和回调机制实现的,也就是应用操作之后会直接返回,不会堵塞在那里,当后台处理完成,操作系统会通知相应的线程进行后续的操作。
AIO是异步IO的缩写,虽然NIO在网络操作中,提供了非阻塞的方法,但是NIO的IO行为还是同步的。对于NIO来说,我们的业务线程是在IO操作准备好时,得到通知,接着就由这个线程自行进行IO操作,IO操作本身是同步的。(除了AIO其他的IO类型都是同步的)
4. Java IO类型
按操作方式(类结构)
字节流和字符流
- 字节流:以字节为单位,每次次读入或读出是8位数据。可以读任何类型数据。
- 字符流:以字符为单位,每次次读入或读出是16位数据。其只能读取字符类型数据。
输出流和输入流:
- 输出流:从内存读出到文件。只能进行写操作。
- 输入流:从文件读入到内存。只能进行读操作。
注意: 这里的出和入,都是相对于系统内存而言的。
节点流和处理流:
- 节点流:直接与数据源相连,读入或读出。
- 处理流:与节点流一块使用,在节点流的基础上,再套接一层,套接在节点流上的就是处理流。
为什么要有处理流?直接使用节点流,读写不方便,为了更快的读写文件,才有了处理流。
分类说明
输入字节流InputStream
ByteArrayInputStream,StringBufferInputStream,FileInputStream是三种基本的介质流,它们分别从Byte数组、StringBuffer和本地文件中读取数据PipedInputStream是从与其他线程共用的管道中读取数据。PipedInputStream的一个实例要和PipedOutputStream的一个实例共同使用,共同完成管道的读取写入操作,主要用于线程操作。DataInputStream:将基础数据类型读取出来ObjectInputStream和所有FilterInputStream的子类都是装饰流(装饰器模式的主角)。
输出字节流OutputStream
ByteArrayOutputStream、FileOutputStream:是两种基本的介质流,它们分别从Byte数组、本地文件写入数据。PipedOutputStream是向与其它线程共用的管道中写入数据。DataOutputStream将基础数据类型写入到文件中ObjectOutputStream和所有FilterOutputStream的子类都是装饰流。
字符输入流Reader
FileReader,CharReader,StringReader是三种基本的介质流,它们分在本地文件、Char数组、String中读取数据。PipedReader是从与其他线程共用的管道中读取数据BufferedReader:加缓冲功能,避免频繁读写硬盘InputStreamReader:加一个连接字节流和字符流的桥梁,它将字节流转换成字符流。
字符输出流Writer
StringWriter:向String中写入数据CharArrayWriter:实现一个可用作字符输入流的字符缓冲区PipedWriter:是向与其它线程共用的管道中写入数据BufferedWriter:增加缓冲功能,避免频繁读写硬盘。PrintWriter和PrintStream将对象的格式表示打印到文本输出流。两者极其类似,功能和使用也类似。OutputStreamWriter:是OutputStream到writer转换的桥梁,它的子类FileWriter其实就是一个实现此功能的具体类。功能和使用和OutputStream类似
按操作对象
对文件进行操作(节点流)
FileInputStream(字节输入流)FileOutputStream(字节输出流)FileReader(字符输入流)FileWriter(字符输出流)
对管道进行操作(节点流)
PipedInputStream(字节输入流)PipedOutStream(字节输出流)PipedReader(字符输入流)PipedWriter(字符输出流)
PipedInputStream的一个实例要和PipedOutputStream的一个实例共同使用,共同完成管道的读取写入操作。主要用于线程操作。
字节/字符数组流(节点流):
ByteArrayInputStreamByteArrayOutputStreamCharArrayReaderCharArrayWriter
上面的三种是节点流,除此之外其它都是处理流,需要跟节点流配合使用。
Buffered缓冲流(处理流)
带缓冲区的处理流,缓冲区的作用的主要目的是:避免每次和硬盘打交道,提高数据访问的效率。
BufferedInputStreamBufferedOutputStreamBufferedReaderBufferedWriter
转化流(处理流):
InputStreamReader:把字节转化成字符OutputStreamWriter:把字符转化成字节
基本类型数据流(处理流)
用于操作基本数据类型值。
因为平时若是输出一个8个字节的long类型或4个字节的float类型,可以一个字节一个字节输出,也可以把转换成字符串输出,但是这样转换费时间,数据流就解决了输出数据类型的困难。数据流可以直接输出float类型或long类型,提高了数据读写的效率。
DataInputStreamDataOutputStream
打印流(处理流):
一般是打印到控制台,可以进行控制打印的地方。
PrintStreamPrintWriter
对象流(处理流):
把封装的对象直接输出,而不是一个个在转换成字符串再输出。
ObjectInputStream:对象反序列化ObjectOutputStream:对象序列化
合并流(处理流):
SequenceInputStream:可以认为是一个工具类,将两个或者多个输入流当成一个输入流依次读取。
其他类:File(已经被Java7的Path取代)
File类是对文件系统中文件以及文件夹进行封装的对象,可以通过对象的思想来操作文件和文件夹。 File类保存文件或目录的各种元数据信息,包括文件名、文件长度、最后修改时间、是否可读、获取当前文件的路径名,判断指定文件是否存在、获得当前目录中的文件列表,创建、删除文件和目录等方法。
其他类:RandomAccessFile
该对象并不是流体系中的一员,其封装了字节流,同时还封装了一个缓冲区(字符数组),通过内部的指针来操作字符数组中的数据。 该对象特点:
- 该对象只能操作文件,所以构造函数接收两种类型的参数:a.字符串文件路径;b.File对象。
- 该对象既可以对文件进行读操作,也能进行写操作,在进行对象实例化时可指定操作模式(r,rw)。
5. 什么是IO流
IO流是一种数据的流从源头流到目的地,比如文件拷贝,输入流和输出流都包括了。输入流从文件中读取数据存储到进程中,输出流从进程中读取数据然后写入到目标文件。
6. 字节流和字符流的区别
字节流在JDK1.0只被引进,用于操作包含ASCII字符的文件,JAVA也支持其它的字符如Unicode,为了读取包含Unicode字符的文件,JAVA语言设计者在JDK1.1中加入了字符流。ASCII作为Unicode的子集,对于英文字符的文件,可以使用字节流也可以使用字符流。
7. Java中流类的超类主要有哪些?
java.io.InputStreamjava.io.OutputStreamjava.io.Readerjava.io.Writer
8. FileInputStream和FileOutputStream是什么?
这是在拷贝文件操作的时候,经常用到的两个类。在处理小文件的时候,它们性能表现还不错,在大文件的时候,最好使用BufferedInputStream(或BufferedReader) 和BufferedOutputStream(或BufferedWriter)
9. 字节流和字符流,更倾向于用哪个
字符流。因为它们更新一些。许多在字符流中存在的特性,字节流中不存在。比如使用BufferedReader而不是BufferedInputStreams或DataInputStream,使用newLine()方法来读取下一行,但是在字节流中我们需要做额外的操作。
10. System.out.println()是什么?
System是一个java.lang包中的类,用于和底层的操作系统进行交互。
out是一个静态的PrintStream类型的成员变量。
println是PrintStream的一个方法
11. 什么是Filter流
Filter Stream是一种IO流主要作用是用来对存在的流增加一些额外的功能,像给目标文件增加源文件中不存在的行数,或者增加拷贝的性能。
12. 有哪些可用的Filter流
在java.io包中主要有4个可用的filter Stream。包括两个字节Filter Stream,两个字符Filter Stream。分别是:FilterInputStream,FilterOutputStream,FilterReader,FilterWriter。这些类是抽象类,不能被实例化。
有哪些Filter流的子类
LineNumberInputStream:给目标文件增加行号DataInputStream:有些特殊的方法如readInt(),readDouble()和readLine()等可以读取一个int,double和一个string等对应的基本数据类型的返回值。BufferedInputStream:增加性能PushbackInputStream:推送要求的字节到系统中
13. SequenceInputStream的作用
这个类的作用是将多个输入流合并成一个输入流,通过SequenceInputStream类包装后形成新的一个总的输入流。在拷贝多个文件到一个目标文件的时候非常有用。
14. 说说PrintStream和PrintWriter
它们两个功能相同,但是属于不同的类。字节流和字符流,它们都有println方法。
15. 在文件拷贝的时候,哪一种流可用于提升更多的性能?
在字节流的时候,使用BufferedInputStream和BufferedOutputStream
在字符流的时候,使用BufferedReader和BufferedWriter
16. 说说管道流(Piped Stream)
用于从与其他线程共用的管道中读取数据,有四种管道流,PipedInputStream,PipedOutputStream,PipedReader和PipedWtiter。在多个线程或进程中传递数据的时候管道流非常有用。
PipedInputStream 的一个实例要和 PipedOutputStream 的一个实例共同使用,共同完成管道的读取写入操作,主要用于线程操作。
17. 说说File类
它不属于IO流,也不是用于文件操作系统,它主要用于知道一个文件的属性,读写权限,大小等信息。
递归的列出一个目录下的所有文件:
public static void listAllFiles(File dir){
if(dir == null || !dir.exists()){
return;
}
if(dir.isFile()){
System.out.println(dir.getName());
return;
}
for(File file:dir.listFiles()){
listAllFiles(file);
}
}
从Java7开始,可以使用Paths和Files代替File。
18. 说说RandomAccessFile
它在java.io包中是一个特殊的类,既不是输入流也不是输出流,它两者都可以做到。它是Object的直接子类。通常来说,一个流只有一个功能,要么读,要么写。但是RandomAccessFile既可以读文件,也可以写文件。
DataInputStream和DataOutputStream有的方法,在RandomAccessFile中都存在。
19. Buffer(缓冲区)介绍
Buffer本质就是一块内存区,可以用来写入数据,并在稍后读取出来。这块内存被NIO Buffer包裹起来,对外提供一系列的读写方便开发的接口。
利用Buffer读写数据,通常遵循四个步骤:
- 把数据写入
buffer - 调用
flip - 从
Buffer中读取数据 - 调用
buffer.clear()或者buffer.compact()
当写入数据到buffer中时,buffer会记录已经写入的数据大小。当需要读数据时,通过flip()方法把buffer从写模式调整为读模式;在读模式下,可以读取所有已经写入的数据。
当读取完数据后,需要清空buffer,以满足后续写入操作。清空buffer有两种方式:调用clear()或compact()方法。clear会清空整个buffer,compact则只清空已读取的数据,未被读取的数据会被移动到buffer的开始位置,写入位置则近跟着未读数据之后。
Buffer缓冲区实质上就是一块内存,用于写入数据,也供后续再次读取数据。这块内存被NIO Buffer管理,并提供一系列的方法用于更简单的操作这块内存。
一个Buffer有三个属性,分别是:
capacity容量: 作为一块内存,buffer有一个固定的大小,这个大小就是capacity。也就是最多只能写入容量值得字节,整形等数据。一旦buffer写满了就需要清空已读数据以便下次继续写入新的数据。position位置: 当写入数据到Buffer的时候需要从一个确定的位置开始,默认初始化时这个位置position为0,一旦写入了数据比如一个字节,整形数据,那么position的值就会指向数据之后的一个单元,position最大可以到capacity-1;
当从Buffer读取数据时,也需要从一个确定的位置开始。buffer从写入模式变为读取模式时,position会归零,每次读取后,position向后移动。- limit限制: 在写模式,
limit的含义是我们所能写入的最大数据量,它等同于buffer的容量。
一旦切换到读模式,limit则代表我们所能读取的最大数据量,他的值等同于写模式下position的位置。换句话说,可以读取与写入数量相同的字节数(限制设置为写入的字节数,由位置标记)。
position和limit的具体含义取决于当前buffer的模式。capacity在两种模式下都表示容量。
Buffer的使用方式
分配缓冲区
为了获得缓冲区对象,必须首先分配一个缓冲区。在每个Buffer类中,allocate()方法用于分配缓冲区。
ByteBuffer buf = ByteBuffer.allocate(28); //分配容量为28字节
CharBUffer buf = CharBuffer.allocate(1024); //分配空间大小为1024个字符
写入数据到缓冲区
写数据到Buffer有两种方法:
- 从
Channel中写数据到Buffer - 手动写数据到
Buffer,调用put方法
int byteRead = inChannel.read(buf); //从通道写入数据
buf.put(27); //向buffer手动写入数据
翻转
flip()方法可以把Buffer从写模式切换到读模式。调用flip方法会把position归零,并设置limit为之前的position的值。也就是说,现在position代表的是读取位置,limit标示的是已写入的数据位置。
从Buffer读取数据
从Buffer读数据也有两种方式。
- 从
buffer读数据到channel - 从
buffer直接读取数据,调用get方法
int bytesWritten = inChannel.write(buf); //读入到channel
byte aByte = buf.get(); //直接读取
rewind
Buffer.rewind()方法将position置为0,这样我们可以重复读取buffer中的数据,limit保持不变。
clear() 和 compact()
一旦从buffer中读取完数据,需要复用buffer为下次写数据做准备。只需要调用clear()或compact()方法。
如果调用的是clear()方法,position将被设回0,limit被设置成capacity的值。换句话说,Buffer被清空了。Buffer中的数据并未清除,只是这些标记告诉我们可以从哪里开始往Buffer里写数据。
如果Buffer还有一些数据没有读取完,调用clear就会导致这部分数据被“遗忘”,因为没有标记这部分数据未读。针对这种情况,如果需要保留未读数据,那么可以使用compact。
compact()和clear()的区别就在于:对未读数据的处理,是保留这部分数据还是一起清空。
mark()与reset()方法
通过调用Buffer.mark()方法,可以标记Buffer中的一个特定position。之后可以通过调用Buffer.reset()方法恢复到这个position。
buffer.mark(); //call buffer.get() a couple of times, e.g. during parsing.
buffer.reset(); //set position back to mark.
equals() and compareTo()
可以用eqauls和compareTo比较两个buffer
equals():
判断两个buffer相对,需满足:
- 类型相同
buffer中剩余字节数相同- 所有剩余字节相等
从上面的三个条件可以看出,equals只比较buffer中的部分内容,并不会去比较每一个元素。
compareTo():
compareTo也是比较buffer中的剩余元素,只不过这个方法适用于比较排序的
20. Channel
通常来说NIO中的所有IO都是从Channel(通道)开始的。
- 从通道进行数据读取 :创建一个缓冲区,然后请求通道读取数据。
- 从通道进行数据写入 :创建一个缓冲区,填充数据,并要求通道写入数据。
通道和流的区别?
Java NIO Channel通道和流非常相似,主要有以下几点区别:
- 通道可以读也可以写,流一般来说是单向的(只能读或者写,所以用流进行IO操作的时候需要分别创建一个输入流和一个输出流)。
- 通道可以异步读写。
- 通道总是基于缓冲区Buffer来读写。
Java NIO中最重要的几个Channel的实现
FileChannel:用于文件的数据读写DatagramChannel:用于UDP的数据读写SocketChannel:用于TCP的数据读写,一般是客户端实现ServerSocketChannel:允许监听TCP链接请求,每个请求会创建会一个SocketChannel,一般是服务器实现
FileChannel的使用
使用FileChannel读取数据到Buffer(缓冲区)以及利用Buffer(缓冲区)写入数据到FileChannel
开启FileChannel
使用之前,FileChannel必须被打开,但是无法直接打开FileChannel(FileChannel是抽象类)。需要通过InputStream,OutputStream或RandomAccessFile获取FileChannel。
//1.创建一个RandomAccessFile(随机访问文件)对象,
RandomAccessFile raf=new RandomAccessFile("D:\\niodata.txt","rw");
//通过RandomAccessFile对象的getChannel()方法。FileChannel是抽象类。
FileChannel inChannel=raf.getChannel();
从FileChannel读取数据/写入数据
从FileChannel中读取数据/写入数据之前首先要创建一个Buffer(缓冲区)对象。
使用FileChannel的read()方法读取数据:
//2.创建一个读数据缓冲区对象
BytesBuffer buf = new BytesBuffer.allocate(48);
//3.从通道中读取数据写入缓冲区
int bytesRead = inChannel.read(buf);
使用FileChannel的write()方法从缓冲区读取数据写入到通道
//创建一个写数据缓冲区对象
ByteBuffer buf2 = ByteBuffer.allocate(48);
//写入数据
buf2.put("filechannel test".getBytes());
buf2.flip();
inChannel.write(buf2);
关闭FileChannel
channel.close();
示例
public class FileChannelTxt {
public static void main(String args[]) throws IOException {
//1.创建一个RandomAccessFile(随机访问文件)对象,
RandomAccessFile raf = new RandomAccessFile("D:\\niodata.txt", "rw");
//通过RandomAccessFile对象的getChannel()方法。FileChannel是抽象类。
FileChannel inChannel=raf.getChannel();
//2.创建一个读数据缓冲区对象
ByteBuffer buf=ByteBuffer.allocate(48);
//3.从通道中读取数据
int bytesRead = inChannel.read(buf);
//创建一个写数据缓冲区对象
ByteBuffer buf2=ByteBuffer.allocate(48);
//写入数据
buf2.put("filechannel test".getBytes());
buf2.flip();
inChannel.write(buf2);
while (bytesRead != -1) {
System.out.println("Read " + bytesRead);
//Buffer有两种模式,写模式和读模式。在写模式下调用flip()之后,Buffer从写模式变成读模式。
buf.flip();
//如果还有未读内容
while (buf.hasRemaining()) {
System.out.print((char) buf.get());
}
//清空缓存区
buf.clear();
bytesRead = inChannel.read(buf);
}
//关闭RandomAccessFile(随机访问文件)对象
raf.close();
}
}
通道之间数据传输
在Java NIO中,如果一个channel是FileChannel类型的,那么它可以直接把数据传输到另一个channel。
- transferFrom:把数据从通道源传输到
FileChannel - transferTo:把
FileChannel数据传输到另一个channel
SocketChannel和ServerSocketChannel的使用
利用SocketChannel和ServerSocketChannel实现客户端与服务器端简单通信:
SocketChannel用于创建基于tcp协议的客户端对象,因为SocketChannel中不存在accept()方法,所以,它不能成为一个服务端程序。通过connect()方法,SocketChannel对象可以连接到其他tcp服务器程序。
客户端:
public class WebClient {
public static void main(String[] args) throws IOException {
//1.通过SocketChannel的open()方法创建一个SocketChannel对象
SocketChannel socketChannel = SocketChannel.open();
//2. 连接到远程服务器(连接此通道的socket)
socketChannel.connect(new InetSocketAddress("127.0.0.1",3333));
//3. 创建写数据缓存区对象
ByteBuffer writeBuffer = ByteBuffer.allocate(128);
writeBuffer.put("hello WebServer,this is WebClient".getBytes());
writeBuffer.flip();
socketChannel.write(writeBuffer);
//创建读数据缓冲区对象
ByteBuffer readBuffer = ByteBuffer.allocate(128);
socketChannel.read(readBuffer);
StringBuffer stringBuffer = new StringBuffer();
//4. 将Buffer从写模式变为读模式
readBuffer.flip();
while (readBuffer.hasRemaining()){
stringBuffer.append((char) readBuffer.get());
}
System.out.println("从服务端接收的数据:"+stringBuffer);
socketChannel.close();
}
}
ServerSocketChannel允许监听TCP链接请求,通过ServerSocketChannelImpl的accept()方法可以创建一个SocketChannel对象用户从客户端读/写数据。
服务端:
public class WebServer {
public static void main(String[] args) throws IOException {
//1.通过ServerSocketChannel的open()方法创建一个ServerSocketChannel对象,open方法的作用:打开套接字通道
ServerSocketChannel ssc = ServerSocketChannel.open();
//2.通过ServerSocketChannel绑定ip地址和port(端口号)
ssc.socket().bind(new InetSocketAddress("127.0.0.1",3333));
//通过ServerSocketChannelImpl的accept()方法创建一个SocketChannel对象从客户端读/写
SocketChannel socketChannel = ssc.accept();
//3. 创建写数据的缓存区对象
ByteBuffer writeBuffer = ByteBuffer.allocate(128);
writeBuffer.put("hello WebClient,this is from WebServer".getBytes());
writeBuffer.flip();
socketChannel.write(writeBuffer);
//创建读数据的缓存区对象
ByteBuffer readBuffer = ByteBuffer.allocate(128);
socketChannel.read(readBuffer);
StringBuffer stringBuffer = new StringBuffer();
//4.将Buffer从写模式变为读模式
readBuffer.flip();
while (readBuffer.hasRemaining()) {
stringBuffer.append((char)readBuffer.get());
}
System.out.println("从客户端接受的数据:"+stringBuffer);
socketChannel.close();
ssc.close();
}
}
DatagramChannel的使用
DatagramChannel,类似于java网络编程的DatagramSocket类;使用UDP进行网络传输, UDP是无连接,面向数据报文段的协议,对传输的数据不保证安全与完整。
获取DatagramChannel
//1.通过DatagramChannel的open()方法创建一个DatagramChannel对象
DatagramChannel datagramChannel = DatagramChannel.open();
//绑定一个port端口
datagramChannel.bind(new InetSocketAddress(1234));//表示可以在1234端口接收数据报
接收/发送消息
接收消息:先创建一个缓存区对象,然后通过receive方法接收消息,这个方法返回一个SocketAddress对象,表示发送消息方的地址:
ByteBuffer buf = ByteBuffer.allocate(48);
buf.clear();
channel.receive(buf);
发送消息:由于UDP下,服务端和客户端通信并不需要建立连接,只需要知道对方地址即可发出消息,但是是否发送成功或者成功被接收到是没有保证的;发送消息通过send方法发出,该方法返回一个int值,表示成功发送的字节数:
ByteBuffer buf = ByteBuffer.allocate(48);
buf.clear();
buf.put("datagramchannel".getBytes());
buf.flip();
int send = channel.send(buf,new InetSocketAddress("localhost",1234));
Scatter/Gather
Channel提供了一种被称为Scatter/Gather的新功能,也称为本地矢量I/O。Scatter/Gather是指在多个缓冲区上实现一个简单的 I/O 操作。正确使用Scatter / Gather可以明显提高性能。
大多数现代操作系统都支持本地矢量I/O(native vectored I/O)操作。当在一个通道上请求一个Scatter/Gather操作时,该请求会被翻译为适当的本地调用来直接填充或抽取缓冲区,减少或避免了缓冲区拷贝和系统调用;
Scatter/Gather应该使用直接的ByteBuffers以从本地I/O获取最大性能优势。
Scatter/Gather功能是通道(Channel)提供的,并不是Buffer。
Scatter: 从一个Channel读取的信息分散到N个缓冲区中(Buufer).Gather: 将N个Buffer里面内容按照顺序发送到一个Channel.
Scattering Reads
scattering read是把数据从单个Channel写入到多个buffer
ByteBuffer header = ByteBuffer.allocate(128);
ByteBuffer body = ByteBuffer.allocate(1024);
ByteBuffer[] bufferArray = {header,body};
channel.read(bufferArray);
read()方法内部会负责把数据按顺序写进传入的buffer数组内。一个buffer写满后,接着写到下一个buffer中。
Gathering Writes
gathering write把多个buffer的数据写入到同一个channel中:
ByteBuffer header = ByteBuffer.allocate(128);
ByteBuffer body = ByteBuffer.allocate(1024);
Bytebuffer[] bufferArray = {header,body};
channel.write(bufferArray);
write()方法内部会负责把数据按顺序写入到channel中。
无论是
scatter还是gather操作,都是按照buffer在数组中的顺序来依次读取或写入的;另外,并不是所有数据都写入到通道,写入的数据要根据position和limit的值来判断,只有position和limit之间的数据才会被写入
21. Selector
Selector一般称为选择器 ,也可以翻译为多路复用器。它是Java NIO核心组件中的一个,用于检查一个或多个NIO Channel(通道)的状态是否处于可读、可写。如此可以实现单线程管理多个channel,也就是可以管理多个网络链接。
使用Selector的好处在于: 使用更少的线程就可以来处理通道了,相比使用多个线程,避免了线程上下文切换带来的开销。
使用方式
Selector的创建
通过调用Selector.open()方法创建一个Selector对象:
Selector selector = Selector.open();
注册Channel到Selector
channel.configureBlocking(false);
SelectionKey key = channel.register(selector,SelectionKey.OP_READ);
Channel必须是非阻塞的,所以FileChannel不适用于Selector,因为FileChannel不能切换为非阻塞模式,更准确的说是因为FileChannel没有继承SelectableChannel。SocketChannel可以正常使用。
SelectableChannel抽象类有一个configureBlocking()方法用于使通道处于阻塞模式或者非阻塞模式。
public abstract SelectableChannel configureBlocking(boolean block)
throws IOException;
SelectableChannel抽象类的configureBlocking()方法是由AbstractSelectableChannel抽象类实现的,SocketChannel,ServerSocketChannel,DatagramChannel都是直接继承了AbstractSelectableChannel抽象类。
register()方法的第二个参数是一个interest集合,意思是在通过Selector监听Channel时对什么事件感兴趣,可以监听四种不同类型的事件:
- Connect
- Accept
- Read
- Write
通道触发了一个事件意思是该事件已经就绪。比如某个Channel成功连接到另一个服务器称为连接就绪。一个Server Socket Channel准备好接收新进入的连接称为接收就绪。一个有数据可读的通道可以说是读就绪。等待写数据的通道可以说是写就绪。
这四种事件用SelectionKey的四个常量来表示
SelectionKey.OP_CONNECT
SelectionKey.OP_ACCEPT
SelectionKey.OP_READ
SelectionKey.OP_WRITE
它们在SelectionKey的定义如下:
public static final int OP_READ = 1 << 0;
public static final int OP_WRITE = 1 << 2;
public static final int OP_CONNECT = 1 << 3;
public static final int OP_ACCEPT = 1 << 4;
可以看出每个事件可以被当成一个位域,如果要监听多个事件,可以用或运算法:
int interestSet = SelectionKey.OP_READ | SelectionKey.OP_WRITE;
SelectionKey
一个SelectionKey键表示一个特定的通道对象和一个特定的选择器对象之间的注册关系。
key.attachment(); //返回SelectionKey的attachment,attachment可以在注册channel的时候指定。
key.channel(); // 返回该SelectionKey对应的channel。
key.selector(); // 返回该SelectionKey对应的Selector。
key.interestOps(); //返回代表需要Selector监控的IO操作的bit mask(位掩码)
key.readyOps();// 返回一个bit mask,代表在相应channel上可以进行的IO操作。
可以通过以下方法来判断Selector是否对Channel的某种事件感兴趣:
int interestSet = selectionKey.interestOps();
boolean isInterestedInAccept = (interestSet & SelectionKey.OP_ACCEPT) == SelectionKey.OP_ACCEPT
boolean isInterestedInConnect = interestSet & SelectionKey.OP_CONNECT;
boolean isInterestedInRead = interestSet & SelectionKey.OP_READ;
boolean isInterestedInWrite = interestSet & SelectionKey.OP_WRITE;
key.readyOps()
ready集合是通道已经准备就绪的操作的集合。JAVA中定义以下几个方法用来检查这些操作是否就绪
//创建ready集合的方法
int readySet = selectionKey.readyOps();
//检查这些操作是否就绪的方法
key.isAcceptable();//是否可读,是返回
trueboolean isWritable()://是否可写,是返回 true
boolean isConnectable()://是否可连接,是返回 true
boolean isAcceptable()://是否可接收,是返回 true
从SelectionKey访问Channel和Selector:
Channel channel = key.channel();
Selctor selector = key.selector();
可以将一个对象或者更多信息附到SelectionKey上,这样就能方便的识别某个给定的通道。例如,可以附加与通道一起使用的Buffer,或是包含聚集数据的某个对象。使用方法如下:
key.attach(theObject);
Object attachedObj = key.attachment();
还可以在用register()方法向Selector注册Channel的时候附加对象。如:
SelectionKey key = channel.register(selector,SelectionKey.OP_READ,theObject);
从Selector中选择channel
选择器维护注册过的通道的集合,并且这种注册关系都被封装在SelectionKey当中。
Selector维护的三种类型的SelectionKey集合:
- 已注册的键的集合:所有与选择器关联的通道所生成的键的集合称为已经注册的键的集合。并不是所有注册过的键都仍然有效。这个集合通过
keys()方法返回,并且可能是空的。这个已注册的键的集合不是可以直接修改的;试图这么做的话将引发java.lang.UnsupportedOperationException。 - 已选择的键的集合:已注册的键的集合的子集。这个集合的每个成员都是相关的通道被选择器(在前一个选择操作中)判断为已经准备好的,并且包含于键的
interest集合中的操作。这个集合通过selectedKeys()方法返回(并有可能是空的)。不要将已选择的键的集合与ready集合弄混了。这是一个键的集合,每个键都关联一个已经准备好至少一种操作的通道。每个键都有一个内嵌的ready集合,指示了所关联的通道已经准备好的操作。键可以直接从这个集合中移除,但不能添加。试图向已选择的键的集合中添加元素将抛出java.lang.UnsupportedOperationException。 - 已取消的键的集合:已注册的键的集合的子集,这个集合包含了
cancel()方法被调用过的键(这个键已经被无效化),但它们还没有被注销。这个集合是选择器对象的私有成员,因而无法直接访问。
当键被取消(可以通过
isValid()方法来判断)时,它将被放在相关的选择器的已取消的键的集合里。注册不会立即被取消,但键会立即失效。当再次调用select()方法时(或者一个正在进行的select()调用结束时),已取消的键的集合中的被取消的键将被清理掉,并且相应的注销也将完成。通道会被注销,而新的SelectionKey将被返回。当通道关闭时,所有相关的键会自动取消(一个通道可以被注册到多个选择器上)。当选择器关闭时,所有被注册到该选择器的通道都将被注销,并且相关的键将立即被无效化(取消)。一旦键被无效化,调用它的与选择相关的方法就将抛出CancelledKeyException。
select()方法介绍
在刚初始化的Selector对象中,上面的三个集合都是空的。通过Selector的select()方法可以选择已经准备就绪的通道(这些通道包含感兴趣的事件)。比如对读就绪的通道感兴趣,那么select()方法就会返回读事件已经就绪的那些通道。
Selector重载的几个select()方法:
int select():阻塞到至少有一个通道在你注册的事件上就绪了。int select(long timeout):和select()一样,但最长阻塞时间为timeout毫秒。int selectNow():非阻塞,只要有通道就绪就立刻返回。
select()方法返回的int值表示有多少通道已经就绪,是自上次调用select()方法后有多少通道变成就绪状态。之前在select()调用时进入就绪的通道不会在本次调用中被记入,而在前一次select()调用进入就绪但现在已经不在处于就绪的通道也不会被记入。例如:首次调用select()方法,如果有一个通道变成就绪状态,返回了1,若再次调用select()方法,如果另一个通道就绪了,它会再次返回1。如果对第一个就绪的channel没有做任何操作,现在就有两个就绪的通道,但在每次select()方法调用之间,只有一个通道就绪了。
一旦调用select()方法,并且返回值不为0时,则可以通过调用Selector的selectedKeys()方法来访问已选择键集合 。如下:
Set selectedKeys=selector.selectedKeys();
进而可以拿到和某SelectionKey关联的Selector和Channel。如下所示:
Set selectedKeys = selector.selectedKeys();
Iterator keyIterator = selectedKeys.iterator();
while(keyIterator.hasNext()) {
SelectionKey key = keyIterator.next();
if(key.isAcceptable()) {
//...
}else if(key.isConnectable()){
//...
}else if(key.isReadable()){
//...
}else if(key.isWritable()){
//...
}
keyIterator.remove();
}
停止选择的方法
选择器执行选择的过程,系统底层会依次询问每个通道是否已经就绪,这个过程可能会造成调用线程进入阻塞状态,有以下三种方式可以唤醒在select()方法中阻塞的线程。
wakeup()方法 :通过调用Selector对象的wakeup()方法让处在阻塞状态的select()方法立刻返回。该方法使得选择器上的第一个还没有返回的选择操作立即返回。如果当前没有进行中的选择操作,那么下一次对select()方法的一次调用将立即返回。close()方法 :通过close()方法关闭Selector,该方法使得任何一个在选择操作中阻塞的线程都被唤醒(类似wakeup()),同时使得注册到该Selector的所有Channel被注销,所有的键将被取消,但是Channel本身并不会关闭。
模版代码
ServerSocketChannel ssc = ServerSocketChannel.open();
ssc.socket().bind(new InetSocketAddress("localhost",8080));
ssc.configureBlocking(false);
Selector selector = Selector.open();
ssc.register(selector, SelectionKey.OP_ACCEPT);
while (true){
int readyNum = selector.select();
if(readyNum == 0){
continue;
}
Set<SelectionKey> selectionKeys = selector.selectedKeys();
Iterator<SelectionKey> it = selectionKeys.iterator();
while (it.hasNext()) {
SelectionKey key = it.next();
if (key.isAcceptable()) {
//接受连接
} else if (key.isReadable()) {
//通道可读
} else if (key.isWritable()) {
//通道可写
}
it.remove();
}
}
应用实例:
服务端:
import java.io.IOException;
import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.*;
import java.util.Iterator;
import java.util.Set;
public class SelectorWebServer {
public static void main(String[] args) {
try {
ServerSocketChannel ssc = ServerSocketChannel.open();
ssc.socket().bind(new InetSocketAddress("127.0.0.1",8080));
ssc.configureBlocking(false);
Selector selector = Selector.open();
//注册channel,并且指定感兴趣的事件是Accept
ssc.register(selector, SelectionKey.OP_ACCEPT);
ByteBuffer readBuffer = ByteBuffer.allocate(1024);
ByteBuffer writeBuffer = ByteBuffer.allocate(128);
writeBuffer.put("received".getBytes());
writeBuffer.flip();
while (true){
int nReady = selector.select();
Set<SelectionKey> keys = selector.selectedKeys();
Iterator<SelectionKey> it = keys.iterator();
while(it.hasNext()){
SelectionKey key = it.next();
it.remove();
if(key.isAcceptable()){
//创建新的连接,并且把连接注册到selector上,而且,声明这个channel只对读操作感兴趣
SocketChannel socketChannel = ssc.accept();
socketChannel.configureBlocking(false);
socketChannel.register(selector,SelectionKey.OP_READ);
}else if(key.isReadable()){
SocketChannel socketChannel = (SocketChannel) key.channel();
readBuffer.clear();
socketChannel.read(readBuffer);
readBuffer.flip();
System.out.println("received: "+new String(readBuffer.array()));
key.interestOps(SelectionKey.OP_WRITE);
}else if(key.isWritable()){
writeBuffer.rewind();
SocketChannel socketChannel = (SocketChannel)key.channel();
socketChannel.write(writeBuffer);
key.interestOps(SelectionKey.OP_READ);
}
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
客户端:
import java.io.IOException;
import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.SocketChannel;
public class SelectorWebClient {
public static void main(String[] args) {
try {
SocketChannel socketChannel = SocketChannel.open();
socketChannel.connect(new InetSocketAddress("127.0.0.1",8080));
ByteBuffer writeBuffer = ByteBuffer.allocate(32);
ByteBuffer readBuffer = ByteBuffer.allocate(32);
writeBuffer.put("hello".getBytes());
writeBuffer.flip();
while(true){
writeBuffer.rewind();
socketChannel.write(writeBuffer);
readBuffer.clear();
socketChannel.read(readBuffer);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
22.文件IO的Path
Java7中文件IO发生了很大的变化,专门引入了很多新的类来取代原来的基于java.io.File的文件IO操作方式
创建一个Path
创建一个Path示例可以通过Paths工具类的get()方法
//使用绝对路径
Path path = Paths.get("c:\\data\\myfile.txt");
//使用相对路径
Path path = Pahts.get("/home/xiaoming/myfile.txt");
上面的创建方式等效于下面这种:
Path path = FileSystems.getDefault().getPath("c:\\data\\myfile.txt");
File和Path之间的转换,File和URI之间的转换
File file = new File("C:/my.ini");
Path p = file.toPath();
p.toFile();
file.toURI();
获取Path的相关信息
//使用Paths工具类的get()方法创建
Path path = Paths.get("D:\\XMind\\bcl-java.txt");
//使用FileSystems工具类创建
Path path2 = FileSystems.getDefault().getPath("c:\\data\\myfile.txt");
System.out.println("文件名:" + path.getFileName());
System.out.println("名称元素的数量:" + path.getNameCount());
System.out.println("父路径:" + path.getParent());
System.out.println("根路径:" + path.getRoot());
System.out.println("是否是绝对路径:" + path.isAbsolute());
//startsWith()方法的参数既可以是字符串也可以是Path对象
System.out.println("是否是以为给定的路径D:开始:" + path.startsWith("D:\\") );
System.out.println("该路径的字符串形式:" + path.toString());
移除冗余项
某些时候需要处理的Path路径中可能会有一个或两个点
.表示的是当前目录..表示父目录或者说是上一级目录:
使用Path类的normalize()和toRealPath()方法可以把.和..去除。
normalize(): 返回一个路径,该路径是冗余名称元素的消除。toRealPath(): 融合了toAbsolutePath()方法和normalize()方法
//.表示的是当前目录
Path currentDir = Paths.get(".");
System.out.println(currentDir.toAbsolutePath()); //输出C:\Users\Administrator\NIODemo\.
Path currentDir2 = Paths.get(".\\NIODemo.iml");
System.out.println("原始路径格式:"+currentDir2.toAbsolutePath());
System.out.println("执行normalize()方法之后:"+currentDir2.toAbsolutePath().normalize());
System.out.println("执行toRealPath()方法之后:"+currentDir2.toRealPath());
//..表示父目录或者说是上一级目录:
Path currentDir3 = Paths.get("..");
System.out.println("原始路径格式:"+currentDir3.toAbsolutePath());
System.out.println("执行normalize()方法之后:"+currentDir3.toAbsolutePath().normalize());
System.out.println("执行toRealPath()方法之后:"+currentDir3.toRealPath());
输出:
C:\Users\Administrator\NIODemo\.
原始路径格式:C:\Users\Administrator\NIODemo\.\NIODemo.iml
执行normalize()方法之后:C:\Users\Administrator\NIODemo\NIODemo.iml
执行toRealPath()方法之后:C:\Users\Administrator\NIODemo\NIODemo.iml
原始路径格式:C:\Users\Administrator\NIODemo\..
执行normalize()方法之后:C:\Users\Administrator
执行toRealPath()方法之后:C:\Users\Administrator
23. Files类
Java NIO中的Files类(java.nio.file.Files)提供了多种操作文件系统中文件的方法。
java.nio.file.Files类和java.nio.file.Path相结合使用的
检查给定的Path在文件系统中是否存在
通过Files.exists()检测文件路径是否存在
Paht path = Paths.get("D:\\...");
boolean pathExists = Files.exists(path,new LinkOption[]{LinkOption.NOFOLLOW_LINKS});
System.out.println(pathExists);
Files.exists()的第二个参数是一个数组,这个参数直接影响到Files.exists()如何确定一个路径是否存在。在本例中,这个数组内包含了LinkOptions.NOFOLLOW_LINKS,表示检测时不包含符号链接文件。
创建文件/文件夹
创建文件:通过Files.createFile()创建文件
Path target = Paths.get("C:\\mystuff.txt");
try{
if(!Files.exists(target))
Files.createFile(target);
} catch (IOException e) {
e.printStackTrace();
}
创建文件夹:有两种方式
- 通过
Files.createDirectory()创建 - 通过
Files.createDirectories()创建
区别:Files.createDirectories()会首先创建所有不存在的父目录来创建目录,而Files.createDirectory()方法只是创建目录,如果它的上级目录不存在就会报错。
删除文件或目录
通过Files.delete()可以删除一个文件或目录
把一个文件从一个地址复制到另一个位置
通过Files.copy()方法可以吧一个文件从一个地址复制到另一个位置
Path sourcePath = Paths.get("data/logging.properties");
Path destinationPath = Paths.get("data/logging-copy.properties");
try {
Files.copy(sourcePath, destinationPath);
} catch(FileAlreadyExistsException e) {
//destination file already exists
} catch (IOException e) {
//something else went wrong
e.printStackTrace();
}
copy操作还可可以强制覆盖已经存在的目标文件:
Files.copy(sourcePath,destinationPath,StandardCopyOption.REPLACE_EXISTING);
获取文件的属性
Path path = Paths.get("D:\\XMind\\bcl-java.txt");
System.out.println(Files.getLastModifiedTime(path));
System.out.println(Files.size(path));
System.out.println(Files.isSymbolicLink(path));
System.out.println(Files.isDirectory(path));
System.out.println(Files.readAttributes(path,"*"));
遍历一个文件夹
Path dir = Paths.get("D:\\Java");
try(DirectoryStream<Path> stream = Files.newDirectoryStream(dir)){
for(Path e : stream){
System.out.println(e.getFileName());
}
} catch(IOException e){
}
newDirectoryStream只会遍历单个目录,不会遍历整个目录。遍历整个目录需要使用:Files.walkfileTree()。这个方法具有递归遍历目录的功能。
walkFileTree接受一个Path和FileVisitor作为参数。Path对象是需要遍历的目录,FileVistor则会在每次遍历中被调用。
FileVisitor需要调用方自行实现,然后作为参数传入walkFileTree().FileVisitor的每个方法会在遍历过程中被调用多次。如果不需要处理每个方法,那么可以继承它的默认实现类SimpleFileVisitor,它将所有的接口做了空实现。
public class WorkFileTree {
public static void main(String[] args) throws IOException {
Path startingDir = Paths.get("D:\\apache-tomcat-9.0.0.M17");
List<Path> result = new LinkedList<Path>();
Files.walkFileTree(startingDir, new FindJavaVisitor(result));
System.out.println("result.size()=" + result.size());
}
private static class FindJavaVisitor extends SimpleFileVisitor<Path>{
private List<Path> result;
public FindJavaVisitor(List<Path> result){
this.result = result;
}
@Override
public FileVisitResult visitFile(Path file, BasicFileAttributes attrs){
if(file.toString().endsWith(".java")){
result.add(file.getFileName());
}
return FileVisitResult.CONTINUE;
}
}
}
24. NIO用到哪些新技术
NIO在基础的IO流上发展处新的特点,分别是:内存映射技术,字符及编码,非阻塞I/O和文件锁定。
内存映射技术
这个功能主要是为了提高大文件的读写速度而设计的。内存映射文件能创建文件和修改那些大到无法读入内存的文件。有了内存映射文件,就可以认为文件已经全部读进了内存,然后把它当成一个非常大的数组来访问。将文件的一段区域映射到内存中,比传统的文件处理速度要快很多。内存映射文件虽然最终也要从磁盘读取数据,但是它并不需要将数据读取到OS内核缓冲区,而是直接将进程的用户私有地址空间中的一部分区域与文件对象建立起映射关系,就好像直接从内存中读、写文件一样,速度快了很多。
NIO中内存映射主要用到以下两个类:
java.nio.MappedByteBufferjava.nio.channels.FileChannel
FileChannel主要通过类中的map方法实现内存映射:
public abstract MappedByteBuffer map(MapMode mode, long position, long size) throws IOException;
第一个参数设置映射模式,支持三种模式:
FileChannel.MapMode.READ_ONLY:只读缓冲区,在缓冲区中如果发生写操作则会产生ReadOnlyBufferException;FileChannel.MapMode.READ_WRITE:读写缓冲区,任何时刻如果通过内存映射的方式修改了文件则立刻会对磁盘上的文件执行相应的修改操作。别的进程如果也共享了同一个映射,则也会同步看到变化。而不是像标准IO那样每个进程有各自的内核缓冲区,比如JAVA代码中,没有执行IO输出流的flush()或者close()操作,那么对文件的修改不会更新到磁盘去,除非进程运行结束;FileChannel.MapMode.PRIVATE:可写缓冲区,但任何修改是缓冲区私有的,不会回到文件中。
内存映射一旦有效建立,就会一直保持有效,直到MappedByteBuffer对象被回收,并没有相应的办法提前卸载掉映射内存。此外,映射缓冲区不会绑定到创建它们的通道,关闭相关的FileChannel不会破坏映射,只有缓冲对象本身的处理打破了映射。
内存映射文件的优点:
- 用户进程将文件数据视为内存,因此不需要发出
read()或write()系统调用。 - 当用户进程触摸映射的内存空间时,将自动生成页面错误,以从磁盘引入文件数据。 如果用户修改映射的内存空间,受影响的页面将自动标记为脏,并随后刷新到磁盘以更新文件。
- 操作系统的虚拟内存子系统将执行页面的智能缓存,根据系统负载自动管理内存。
- 数据始终是页面对齐的,不需要缓冲区复制。
- 可以映射非常大的文件,而不消耗大量内存来复制数据。
字符及编码
编码就是把字符转换为字节,而解码就是把字节重新转化为字符。
字符编码方案定义了如何把字符编码的序列表达为字节序列。字符编码的数值不需要与编码字节相同,也不需要是一对一或一对多个的关系。原则上,把字符集编码和解码近似视为对象的序列化和反序列化。
常字符数据编码是用于网络传输或文件存储。编码方案不是字符集,它是映射;但是因为它们之间的紧密联系,大部分编码都与一个独立的字符集相关联。例如,UTF-8,仅用来编码Unicode字符集。尽管如此,用一个编码方案处理多个字符集还是可能发生的。例如,EUC可以对几个亚洲语言的字符进行编码。
目前字符编码方案有US-ASCII,UTF-8,GB2312, BIG5,GBK,GB18030,UTF-16BE, UTF-16LE, UTF-16,UNICODE。其中Unicode试图把全世界所有语言的字符集统一到全面的映射之中。大部分的操作系统在I/O与文件存储方面仍是以字节为导向的,所以无论使用何种编码,Unicode或其他编码,在字节序列和字符集编码之间仍需要进行转化。
- GBK编码中,中文字符占2个字节,英文字符占1个字节
- UTF-8编码中,中文字符占3个字节,英文字符占1个字节
- UTF-16BE编码中,中文字符和英文字符都占2个字节
UTF-16be中的be指的是Big Endian,也就是大端。相应地也有UTF-16le,le指的是Little Endian,也就是小端。
Java的内存编码使用双字节编码UTF-16be,这不是指Java只支持这一种编码方式,而是说char这种类型使用UTF-16be进行编码。char类型占16位,也就是两个字节,Java 使用这种双字节编码是为了让一个中文或者一个英文都能使用一个char来存储。
String编码方式:
String可以看成一个字符序列,可以指定一个编码方式将它编码为字节序列,也可以指定一个编码方式将一个字节序列解码为String。
String str1 = "中文";
byte[] bytes = str1.getBytes("UTF-8");
String str2 = new String(bytes, "UTF-8");
System.out.println(str2);
在调用无参数getBytes()方法时,默认的编码方式不是 UTF-16be。双字节编码的好处是可以使用一个char存储中文和英文,而将String转为bytes[]字节数组就不再需要这个好处,因此也就不再需要双字节编码。getBytes()的默认编码方式与平台有关,一般为UTF-8。
byte[] bytes = str1.getBytes();
java.nio.charset包组成的类就是用于字符编码。
字符的编码和解码是使用很频繁的,如果使用UTF-8字符集进行编码,但是却是用UTF-16字符集进行解码,那么这条信息对于用户来说其实是无用的。因为没人能看得懂。在NIO中提供了两个类CharsetEncoder和CharsetDecoder来实现编码转换方案。
CharsetEncoder类是一个状态编码引擎。实际上,编码器有状态意味着它们不是线程安全的:CharsetEncoder对象不应该在线程中共享。CharsetEncoder对象是一个状态转换引擎:字符进去,字节出来。一些编码器的调用可能需要完成转换。编码器存储在调用之间转换的状态。
字符集解码器是编码器的逆转。通过特殊的编码方案把字节编码转化成16-位Unicode字符的序列。与CharsetEncoder类似的, CharsetDecoder也是状态转换引擎。
非阻塞IO
一般来说IO模型分为:同步同步阻塞,同步非阻塞,异步阻塞,异步非阻塞四种IO模型。
NIO中用到了同步非阻塞IO模型,同时还用到了多路复用IO模型。
NIO的非阻塞 I/O 机制是围绕选择器和通道构建的。Channel类表示服务器和客户机之间的一种通信机制。Selector类是Channel的多路复用器。Selector类将传入客户机请求多路分用并将它们分派到各自的请求处理程序。
利用多路复用机制避免了线程的阻塞,提高了连接的数量。一个线程就可以管理多个socket,只有当socket真正有读写事件发生才会占用资源来进行实际的读写操作。虽然多线程+阻塞IO达到类似的效果,但是由于在多线程+阻塞IO中,每个socket对应一个线程,这样会造成很大的资源占用,并且尤其是对于长连接来说,线程的资源一直不会释放,如果后面陆续有很多连接的话,就会造成性能上的瓶颈。
另外多路复用IO为何比非阻塞IO模型的效率高是因为在非阻塞IO中,不断地询问socket状态时通过用户线程去进行的,而在多路复用IO中,轮询每个socket状态是内核在进行的,这个效率要比用户线程要高的多。
文件锁定
NIO中的文件通道(FileChannel)在读写数据的时候主要使用了阻塞模式,它不能支持非阻塞模式的读写,而且FileChannel的对象是不能够直接实例化的,它的实例只能通过getChannel()从一个打开的文件对象上边读取(RandomAccessFile、FileInputStream、FileOutputStream),并且通过调用getChannel()方法返回一个Channel对象去连接同一个文件,也就是针对同一个文件进行读写操作。
文件锁的出现解决了很多Java应用程序和非Java程序之间共享文件数据的问题,在以前的JDK版本中,没有文件锁机制使得Java应用程序和其他非Java进程程序之间不能够针对同一个文件共享数据,有可能造成很多问题,JDK1.4里面有了FileChannel,它的锁机制使得文件能够针对很多非Java应用程序以及其他Java应用程序可见。但是Java里面的文件锁机制主要是基于共享锁模型,在不支持共享锁模型的操作系统上,文件锁本身也起不了作用,JDK1.4使用文件通道读写方式可以向一些文件发送锁请求,FileChannel的锁模型主要针对的是每一个文件,并不是每一个线程和每一个读写通道,也就是以文件为中心进行共享以及独占,也就是文件锁本身并不适合于同一个JVM的不同线程之间。
FileChannel关于文件锁的方法:
public final FileLock lock() throws IOException {
return lock(0L, Long.MAX_VALUE, false);
}
public final FileLock tryLock() throws IOException {
return tryLock(0L, Long.MAX_VALUE, false);
}
/**
* @position 要锁定区域的起始位置
* @size 要锁定区域的尺寸
* @shared true为共享锁,false为独占锁
**/
public abstract FileLock lock(long position, long size, boolean shared) throws IOException;
public abstract FileLock tryLock(long position, long size, boolean shared) throws IOException;
锁定区域的范围不一定要限制在文件的size值以内,锁可以扩展从而超出文件尾。因此,可以提前把待写入数据的区域锁定,也可以锁定一个不包含任何文件内容的区域,比如文件最后一个字节以外的区域。如果之后文件增长到达那块区域,那么文件锁就可以保护该区域的文件内容了。相反地,如果锁定了文件的某一块区域,然后文件增长超出了那块区域,那么新增加的文件内容将不会受到文件锁的保护。
public class NIOLock {
public static void main(String[] args) throws IOException {
FileChannel fileChannel = new RandomAccessFile("c://1.txt", "rw").getChannel();
// 写入4个字节
fileChannel.write(ByteBuffer.wrap("abcd".getBytes()));
// 将前2个字节区域锁定(共享锁)
FileLock lock1 = fileChannel.lock(0, 2, true);
// 当前锁持有锁的类型(共享锁/独占锁)
lock1.isShared();
// IOException 不能修改只读的共享区域
// fileChannel.write(ByteBuffer.wrap("a".getBytes()));
// 可以修改共享锁之外的区域,从第三个字节开始写入
fileChannel.write(ByteBuffer.wrap("ef".getBytes()), 2);
// OverlappingFileLockException 重叠的文件锁异常
// FileLock lock2 = fileChannel.lock(0, 3, true);
// FileLock lock3 = fileChannel.lock(0, 3, false);
//得到创建锁的通道
lock1.channel();
//锁的起始位置
long position = lock1.position();
//锁的范围
long size = lock1.size();
//判断锁是否与指定文件区域有重叠
lock1.overlaps(position, size);
// 记得用try/catch/finally{release()}方法释放锁
lock1.release();
}
}
25. Java NIO AsynchronousFileChannel异步文件通道
Java7中新增了AsynchronousFileChannel作为nio的一部分。AsynchronousFileChannel使得数据可以进行异步读写。
创建AsynchronousFileChannel
Path path = Paths.get("data/test.xml");
AsynchronousFileChannel fileChannel = AsynchronousFileChannel.open(path,StandardOpenOption.READ);
open()的第一个参数是一个Path实体,指向需要操作的文件。第二个参数是操作类型。上述示例用的是StandardOpenOption.READ表示以读的形式操作文件。
读取数据(Reading Data)
读取AsynchronousFileChannel的数据有两种方式。每种方法都会调用AsynchronousFileChannel的一个read()接口。
通过Future读取数据
Future<Integer> operation = fileChannel.read(buffer,0);
这种方式中,read()接受一个ByteBuffer作为第一个参数,数据会被读取到ByteBuffer中。第二个参数是开始读取数据的位置。
read()方法会立刻返回,即使读操作没有完成。我们可以通过isDone()方法检查操作是否完成。
AsynchronousFileChannel fileChannel =
AsynchronousFileChannel.open(path, StandardOpenOption.READ);
ByteBuffer buffer = ByteBuffer.allocate(1024);
long position = 0;
Future<Integer> operation = fileChannel.read(buffer, position);
while(!operation.isDone());
buffer.flip();
byte[] data = new byte[buffer.limit()];
buffer.get(data);
System.out.println(new String(data));
buffer.clear();
CompletionHandler读取数据
fileChannel.read(buffer, position, buffer, new CompletionHandler<Integer, ByteBuffer>() {
@Override
public void completed(Integer result, ByteBuffer attachment) {
System.out.println("result = " + result);
attachment.flip();
byte[] data = new byte[attachment.limit()];
attachment.get(data);
System.out.println(new String(data));
attachment.clear();
}
@Override
public void failed(Throwable exc, ByteBuffer attachment) {
}
});
这里,一旦读取完成,将会触发CompletionHandler的completed()方法,并传入一个Integer和ByteBuffer。前面的整形表示的是读取到的字节数大小。第二个ByteBuffer也可以换成其他合适的对象方便数据写入。如果读取操作失败了,那么会触发failed()方法。
写数据
和读数据一样,写数据也有两种不同方式,调用不同的write()方法
通过Future写数据
Path path = Paths.get("data/test-write.txt");
AsynchronousFileChannel fileChannel =
AsynchronousFileChannel.open(path, StandardOpenOption.WRITE);
ByteBuffer buffer = ByteBuffer.allocate(1024);
long position = 0;
buffer.put("test data".getBytes());
buffer.flip();
Future<Integer> operation = fileChannel.write(buffer, position);
buffer.clear();
while(!operation.isDone());
System.out.println("Write done");
首先把文件已写方式打开,接着创建一个ByteBuffer作为写入数据的目的地。再把数据进ByteBuffer。最后检查一下是否写入完成。需要注意的是,这里的文件必须是已经存在的,否者在尝试write数据是会抛出一个java.nio.file.NoSuchFileException。
可以通过以下方法检查文件是否存在:
if(!Files.exists(path)){
Files.createFile(path);
}
通过CompletionHandler写数据
Path path = Paths.get("data/test-write.txt");
if(!Files.exists(path)){
Files.createFile(path);
}
AsynchronousfileChannel fileChannel = AsynchronousFileChannel.open(path,StandardOpenOption.WRITE);
ByteBuffer buffer = ByteBuffer.allocate(1024);
long position = 0;
buffer.put("test data".getBytes());
buffer.flip();
fileChannel.write(buffer, position, buffer, new CompletionHandler<Integer, ByteBuffer>() {
@Override
public void completed(Integer result, ByteBuffer attachment) {
System.out.println("bytes written: " + result);
}
@Override
public void failed(Throwable exc, ByteBuffer attachment) {
System.out.println("Write failed");
exc.printStackTrace();
}
});
26 Java I/O用到了什么设计模式
Java I/O使用了装饰者设计模式。以InputStream为例:
InputStream是抽象组件FileInputStream是InputStream的子类,属于具体组件,提供了字节流的输入操作FilterInputStream属于抽象装饰者,装饰者用于装饰组件,为组件提供额外的功能。例如BufferedInputStream为FileInputStream提供了缓存功能。
实例化一个具有缓存功能的字节流对象时,只需要在FileInputStream对象上再套一层BufferedInputStream对象即可。
FileInputStream fileInputStream = new FileInputStream(filePath);
BufferedInputStream bufferedInputStream = new BufferedInputStream(fileInputStream);
27. 对象序列化
序列化就是将一个对象转换成字节序列,方便存储和传输。
- 序列化:
ObjectOutputStream.writeObject() - 反序列化:
ObjectInputStream.readObject()
不会对静态变量进行序列化,因为序列化只是保存对象的状态,静态变量属于类的状态
序列化的类需要实现Serializable接口,它只是一个标准,没有任何方法需要实现,但必须标记上。
public static void main(String[] args) throws IOException, ClassNotFoundException {
A a1 = new A(123, "abc");
String objectFile = "file/a1";
ObjectOutputStream objectOutputStream = new ObjectOutputStream(new FileOutputStream(objectFile));
objectOutputStream.writeObject(a1);
objectOutputStream.close();
ObjectInputStream objectInputStream = new ObjectInputStream(new FileInputStream(objectFile));
A a2 = (A) objectInputStream.readObject();
objectInputStream.close();
System.out.println(a2);
}
private static class A implements Serializable {
private int x;
private String y;
A(int x, String y) {
this.x = x;
this.y = y;
}
@Override
public String toString() {
return "x = " + x + " " + "y = " + y;
}
}
transient关键字可以使一些属性不会被序列化。
ArrayList中存储数据的数组elementData是用transient修饰的,因为这个数组是动态扩展的,并不是所有的空间都被使用,因此就不需要所有的内容都被序列化。通过重写序列化和反序列化方法,使得可以只序列化数组中有内容的那部分数据。
private transient Object[] elementData;
28. 网络操作
Java中支持的网络操作:
InetAddress:用于表示网络上的硬件资源,即IP地址URL:统一资源定位符Sockets:使用TCP协议实现网络通信Datagram:使用UDP协议实现网络通信
InetAddress
没有公有的构造函数,只能通过静态方法来创建实例
InetAddress.getByName(String host);
InetAddress.getByAddress(byte[] address);
URL
可以直接从URL中读取字节流数据
public static void main(String[] args) throws IOException {
URL url = new URL("http://www.baidu.com");
/* 字节流 */
InputStream is = url.openStream();
/* 字符流 */
InputStreamReader isr = new InputStreamReader(is, "utf-8");
/* 提供缓存功能 */
BufferedReader br = new BufferedReader(isr);
String line;
while ((line = br.readLine()) != null) {
System.out.println(line);
}
br.close();
}
Sockets
ServerSocket:服务器端类Socket:客户端类- 服务器和客户端通过
InputStream和OutputStream进行输入输出。
Datagram
DatagramSocket:通信类DatagramPacket:数据包类
参考内容
主要参考以来两篇博客以及相关博客推荐,因找的博客比较多,没注意记录,最后好多忘了在哪2333,如果有侵权,请及时联系我,非常抱歉。
https://github.com/Snailclimb/JavaGuide
https://github.com/CyC2018/CS-Notes